揭秘最领先的Llama2中文大模型!
导语
国内最大的开源社区:Llama中文社区率先完成了国内首个真正意义上的中文版Llama2-13B大模型,从模型底层实现了Llama2中文能力的大幅优化和提升。毋庸置疑,中文版Llama2一经发布开启了国内大模型新时代!
| 全球最强,但中文短板
Llama2是当前全球范围内最强的开源大模型,但其中文能力亟待提升
作为AI领域最强大的开源大模型,Llama2基于2万亿token数据预训练,并在100万人类标记数据上微调得到对话模型。在包括推理、编程、对话和知识测试等许多基准测试中效果显著优于MPT、Falcon以及第一代LLaMA等开源大语言模型,也第一次媲美商用GPT-3.5,在一众开源模型中独树一帜。


虽然Llama2的预训练数据相对于第一代扩大了一倍,但是中文预训练数据的比例依然非常少,仅占0.13%,这也导致了原版Llama2的中文能力较弱。
我们对于一些中文问题进行提问,发现大多数情况下Llama2都不能以中文回答,或者以中英文混杂的形式回答问题。因此,需要基于大规模中文数据对Llama2进行优化,使Llama2具备更好的中文能力。

为此国内顶尖高校大模型博士团队创办了Llama中文社区,开启了Llama2中文大模型训练征程。
| 最领先的Llama中文社区
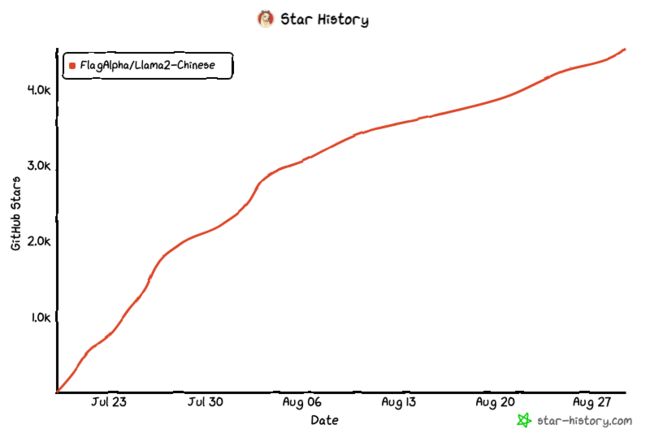
Llama中文社区是国内最领先的开源大模型中文社区,Github达到 4.7k star,由清华、交大以及浙大博士团队领衔,汇聚了60+AI领域高级工程师以及各行业2000+顶级人才。
社区链接:
https://github.com/FlagAlpha/Llama2-Chinese
| 国内首个预训练中文版Llama2大模型!
不是微调!而是基于200B中文语料从头训练!
Llama中文社区是国内首个完成真正意义上的中文版13B Llama2模型:Llama2-Chinese-13B,从模型底层实现了Llama2中文能力的大幅优化和提升。
Llama2的中文化可以采用大致两种路线:
1. 基于已有的中文指令数据集,对预训练模型进行指令微调,使得基座模型能够对齐中文问答能力。这种路线的优势在于成本较低,指令微调数据量小,需要的算力资源少,能够快速实现一个中文Llama的雏形。
但缺点也显而易见,微调只能激发基座模型已有的中文能力,但由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本,从根本上增强Llama2模型的中文能力还是需要从预训练做起。
2. 基于大规模中文语料进行预训练。这种路线的缺点在于成本高!不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力!
为了从内核实现一个彻底的中文大模型,我们选择了第二条路线!我们汇集了一批高质量的中文语料数据集,从预训练开始优化Llama2大模型。部分预训练数据数据如下:
类型 |
描述 |
网络数据 |
互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据 |
Wikipedia |
中文Wikipedia的数据 |
悟道 |
中文悟道开源的200G数据 |
Clue |
Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 |
竞赛数据集 |
近年来中文自然语言处理多任务竞赛数据集,约150个 |
MNBVC |
MNBVC 中清洗出来的部分数据集 |
首期 Llama2-Chinese-13B 模型的预训练数据包含 200B token,未来,我们将持续不断地迭代更新 Llama2-Chinese,逐步将预训练数据提升到1T token。除此以外,我们也将逐步开放70B模型的中文预训练版本,敬请期待!

我们从通用知识、语言理解、创作能力、逻辑推理、代码编程、工作技能等不同方面提问大模型,得到了令人满意的效果!
部分效果展示如下:
通用知识

语言理解

创作能力

逻辑推理
代码编程

工作技能

Llama中文社区领航计划
着眼于社区的长远发展与快速迭代,一方面为每一个有热情有志向投入到大模型浪潮中的AI爱好者提供专业的技术服务,另一方面,让每一个社区的参与者都能在极速发展的AI时代抢先领跑,获取各方面的资源对接,我们限时推出首期Llama中文社区领航计划!领航计划的每一位成员将获得以下
“7TOP” 权益:
1、模型TOP
加入可获取国内首个预训练中文版Llama2-Chinese-13B模型使用权(非微调版本),并且在未来,我们将持续基于更大规模的数据,不断增强模型内核的中文能力,也将优先为领航计划的每位成员提供最领先的模型版本。
2、技术TOP
国内顶尖高校博士团队领衔,最专业的大模型技术团队。无论是最前沿的技术问题还是深入的理论剖析,我们都将为您提供最前沿的解决方案。
3、服务TOP
在领航计划中,您将获得个性化的1V1指导,无论何时何地,只要您有疑问,我们将及时解答。我们致力于提供全方位的支持,帮助你快速实现Llama2大模型应用,确保您顺利实现技术突破。您的企业遇到大模型相关问题我们也会帮您分析解决。
4、教学TOP
理论与实战相结合的教学模式,将带您领略大模型的奥秘。从大模型的技术剖析到关键算法和论文讲解,从零开始搭建私有化大模型,再到行业大模型的训练,我们将手把手教您一步步实现技术进阶。课程大纲如下:

5、资源TOP
我们有国内最大的Llama中文社区,Github达到 4.7k star,汇聚了2000+顶级人才。在这里,您将与AI投资人、企业家CEO、各行业领军人物相互交流,寻求合作、投资、推广、招聘等一站式服务。找工作/合伙人/投资/销售产品,都可以满足你的需求。这里是技术人才互通有无的黄金平台,您可以找到各行各业的顶尖专家,共同交流与探讨。
6、活动TOP
我们不仅在线上举办定期活动,更有线下活动提供技术宣讲和交流,旨在基于Llama2大模型为各行业赋能。为您提供与顶尖专家直接互动的机会,让您与行业领先者并肩前行。无论您是技术新秀还是经验丰富的大牛,我们都将为您提供绝佳机会,与世界顶尖技术人才共谋未来!
7、算力TOP
社区为学员提供算力资源渠道,让您低于市场价使用。我们了解算力对于技术发展的重要性,为您提供高效、稳定的算力支持,助您在技术领域尽显风采。
领航计划第一期同学反馈

优秀学员证书

领航计划第二期参与方式
为了感谢社区伙伴的支持,我们为前1000名领航员提供早鸟价格,仅需2399元,即可抢先使用国内首个真正意义上的13B中文Llama模型并享受领航计划 ”7TOP“权益所有服务与资源。后续将恢复至4399元原价,可以持续享有社区未来发展的优先体验权益。

如果你是:
正在学习 AI 大模型的研发工程师、项目经理、产品经理等互联网岗位人员
来自工业制造业、金融、医疗和农业等传统行业的,正在关注大模型落地的技术研发人员及工程师
在自身研究和学习中需要使用大模型的科研人员、老师和学生
……
那么,请不要再犹豫,即刻报名领航计划!以更高效的方式,完成大模型技术升级!