机器学习的练功心法(一)——机器学习概述
1 机器学习概述
文章目录
- 1 机器学习概述
-
- 1.1 学习方法
- 1.2 什么是机器学习
- 1.3 监督学习
- 1.4 无监督学习
- 1.5 强化学习
- 1.6 机器学习的开发流程
1.1 学习方法
引入:对于机器学习来说,我们需要有一个大局观,什么是大局观?你站的比别人高,掌握的就比别人快,对于这门课程,你要掌握的学习方法和你在学数据结构那样类似,理解其算法思想并且能用代码敲出来。当然,代码并不是一定要和例子上的一模一样,但是实现的功能要一样。
应用场景:让我们来看看机器学习在生活上的例子,当你使用Google搜索引擎上网查找资料的时候,你搜索前面的几个关键词它就能显示后面的关键词,这实际上和机器学习分不开的。

同样地,在苹果相机自拍后,相册能够根据照片识别你和你的朋友,并且将不同的照片放置到不同的照片中,这也是机器学习的一种应用。

还有一种应用是:你打开手机,有时候会发现有很多垃圾信息,而这些信息一般都会放在垃圾信息的分组中,这也是机器学习的功劳,它能够过滤大量的垃圾信息。

说明:机器学习近年来之所以这么火的原因是因为网络和自动化技术的发展,这也意味着我们拥有大量的数据集,通过机器学习对这些大量的数据集进行分析,可以挖掘出有用的信息为我们所用。
还有一个原因是:一些应用程序不能人为编写,这样的话利用机器学习就能让其为我们编写。如手写数据集、自然语言处理、计算机视觉。
最后一个原因是:私人定制程序的发展。比如亚马逊,淘宝的推送商品。通过你购物或者浏览过的商品,程序可以推送一些你可能感兴趣的内容。
1.2 什么是机器学习
说明:让我们看一下在1959年Arthur Samuel给出的机器学习的概念,它将机器学习定义为在没有明确设置的情况下,是计算机具有学习能力的计算领域。
这一切都来源于一个叫Samuel的人,它本身不是很会玩跳棋这种游戏,但是它通过让机器和自己对弈上万次,使得机器知道什么布局容易赢什么布局容易输,到最后机器玩跳棋的水平甚至比Samuel还要高。
让我们再看一下Mitchell在1998年提出的机器学习的定义,它说从计算机程序从经验E中学习,解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
让我们拿上面的跳棋游戏来举例:对于跳棋游戏来说经验E就是程序和自己上万次的下棋,任务T就是玩跳棋,性能度量P就是与新对手玩跳棋的概率。
对于机器学习来说有很多分类,最主要的两类是监督学习和无监督学习,在后面我们会多次提到这些莫名其妙的术语。但简单来说,监督学习就是我们有某种准则,可以让机器依照我们的准则去学习;然而在无监督学习中,我们没有提供任何准则,机器会从海量的数据中自动总结出某种准则。
还有一种是强化学习,这类机器学习常用于计算机视觉,据我所知很多人喜欢拿来做游戏对象捕捉外挂(比如原神钓鱼外挂)。
1.3 监督学习
说明:机器学习中最常用的类型即监督学习(supervised learning)。让我们来体会一个比较简单的例子:
有一个学生在俄勒冈的波特兰市收集了一批数据用作房价预测。

其中横轴的房屋的平方数,竖轴是房屋的价格。如果此时这个学生想要卖掉他在波特兰的房子,比如是500平方,那么它大概能卖多少钱。
一种比较简单的思维是,根据收集来的数据,我们认为这些数据可能是线性关系,当然也可以是类如二次函数或二次多项式。当然我们考虑最简单的,其可能存在一种线性关系即一次函数,那么这个房子卖出的价格y很有可能是500在函数上的映射。
综上所述,监督学习就是给定算法一个数据集,其中可能包含了正确答案,根据这些数据集我们通过已有的模型训练出模型对应的函数。以后用这个函数预测更多未知的数据,体现在预测房价问题上就是给出一个房子面积来预测房价。
预测某个价格,这如果用更专业的术语来讲,这实际上叫做回归问题。所谓的回归问题是指我们想要预测连续的数值输出,比如我们有了一堆数据集,根据数据集和既定的模型训练出来的函数可以预测任何一个数值,这个数值可以是标量可以是连续值。
让我们再看一个例子。

假设你想看医疗记录,然后设法预测肿瘤是良性的还是恶性的。我们把这种好结果或坏结果给出一个术语叫做标签。
现在我们现在已经拥有了医疗记录的往年记录,那么根据这些往年的记录来选择一个既定的模型例如线性模型,然后训练出一个对应的函数。当一个新的病例出现,这个算法根据肿瘤的大小来判断肿瘤属于哪种标签。
当然了你不能思考的那么死,我们标签不一定只有两个对吧。如我们设定0号标签为良性,没有癌症;设定1号标签为第一种癌症;设定2号标签为第二种癌症。但是当我们标签只有两个的时候,我们把这类分类问题叫做二分类问题。
当然上述可以发现我们仅仅根据一个肿瘤大小来判定肿瘤的良恶。实际上这是不够准确的。在实际开发中,我们会选取多个特征,比如病人的年纪、病人患病的时间长短、肿块的厚度、肿块的平均大小。
1.4 无监督学习
说明:让我们在这一小节探讨一下第二种主要的机器学习问题——无监督学习。无监督学习实际上通常用聚类算法来实现。在下面,我们来看看无监督学习的含义是什么。
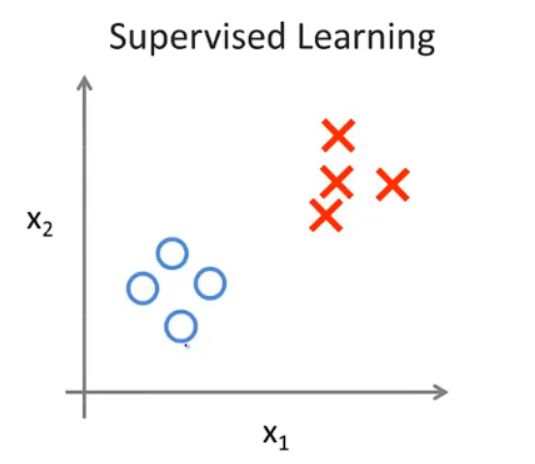
在上一小节中,我们说过特征可以有多个,当上一小节我们举的肿瘤例子拥有两个特征时,我们用 x 1 和 x 2 x_1和x_2 x1和x2来分别表示两个特征,其中圈和叉表示肿瘤的良性或恶性。
而在无监督学习中,机器仅仅收到一团数据集,却没有被告知要干嘛,如下所示:
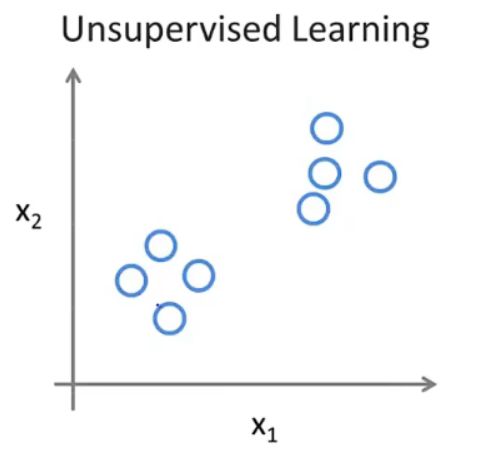
通过无监督学习,机器可能判定在数据集中存在两个簇,并且机器对其自动划分。对这类应用比较一个显著的例子是谷歌搜索引擎。
谷歌搜索引擎做了这么一件事,它收集了成千上万的新闻,然后根据无监督学习让机器自己总结出某种合适的主题,然后对新闻进行划分。
让我们来看看无监督学习在其他方面的应用。

无监督学习可以用于组织大型的计算机集群,其可以试图找出哪些机器可以更好地进行协同工作。
无监督学习还可以用于社交软件,通过相同的习性和其他某些特征,社交软件可以向你推送一些你感兴趣的人或者你身边的人。
无监督学习还可以用于市场分析。许多公司拥有庞大的客户信息数数据库,对于一个客户数据集,大公司常常会让聚类算法划分不同的人群,使其归为不同的市场消费人群。用无监督学习的原因是,我们并不知道实现市场的分类是什么,这个具体的分类是机器帮我们做的事。
最后无监督学习还可以用于天文分析。
1.5 强化学习
最后一个机器学习是强化学习。强化学习类似于激素。为什么这么说呢。强化学习可以通过对环境的交互来提高其预测性能。当前所在的环境状态通常包含奖励信息。当机器对某个环境中的内容交互时,奖励信息会强化机器的学习,这也是为什么它称为强化学习的原因。

当然,我们这里不会过多讲述关于强化学习的知识,因为它实际上不利于新手了解机器学习。
1.6 机器学习的开发流程
说明:机器学习一般是先获取数据,这些数据一般是公司给你,如果是自己练习的话一般是下载或爬取。
第二步我们要做的是数据处理,对于一些不规则或异常数据我们会做一些简单的处理,其中删除或置0比较常见。
第三步是特征工程,这个我们会在第三章细讲。
第四步是训练模型,训练出来后的模型需要评估其效果。
第五步是将训练出来的模型应用于开发中。