机器人中的数值优化(十)——线性共轭梯度法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例

十二、线性共轭梯度法
1、基础知识
(1)设G是n ×n对称正定矩阵.若 R n R^n Rn中两个非零向量 d i , d j , ( i ≠ j ) d_i,d_j ,(i≠j) di,dj,(i=j)满足下式,则称 d i , d j d_i,d_j di,dj是(G)的共轭方向。
d i T G d j = 0 , d_i^\mathrm{T}G d_j=0, diTGdj=0,
(2)若 R n R^n Rn中n个非零向量 d 0 、 d 1 、 . . . . . . . d n − 1 ( i ≠ j ) d_0、d_1 、.......d_{n-1}(i≠j) d0、d1、.......dn−1(i=j)满足下式,则称它们为G的两两共轭方向,或称这个向量组是(G)共轭的,由定义可以看出正交方向是共轭方向的特殊情况。
d i T G d j = 0 , i , j = 0 , ⋯ , n − 1 , i ≠ j , d_i^\mathrm{T}Gd_j=0,\quad i,j=0,\cdots,n-1,i\neq j, diTGdj=0,i,j=0,⋯,n−1,i=j,
(3)设G为n x n对称正定矩阵.若存在对称正定矩阵T,使得 T 2 = G T^2=G T2=G,则称T为G的平方根矩阵,记为T=√G,若G为n x n对称正定矩阵,则其平方根矩阵存在且唯一
(4)二次终止性:二次终止性是指对于严格凸的二次函数,算法能在有限迭代步内达到最优值点。
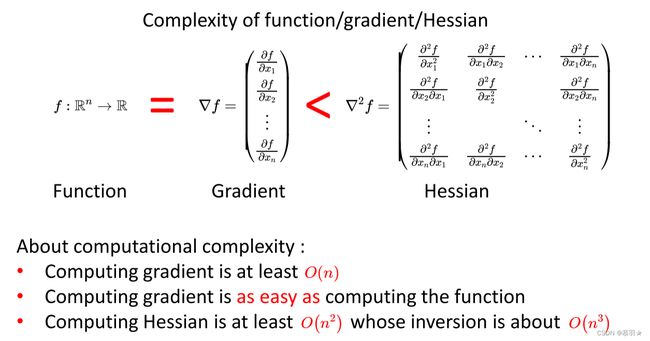
(5)算一个函数的复杂度跟算它的梯度的复杂度是类似的,之间差一个常数的关系,可以认为都是O(n)的,但是求Hessian矩阵的话,其复杂度是显著高于求函数本身或者求梯度的,认为至少是 O ( n 2 ) O(n^2) O(n2)的,求Hessian矩阵的逆认为是 O ( n 3 ) O(n^3) O(n3)
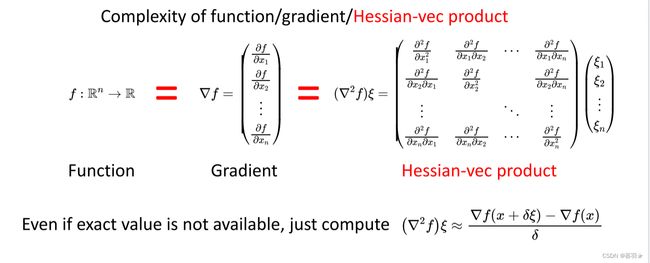
我们可以通过计算如下的Hessian-vec product来代替计算Hessian,使其复杂度降为类似O(n)的
2、线性共轭梯度法
线性共轭梯度方法(Conjugate Gradient Method,CG算法)是解线性方程组的一种迭代方法。该算法是针对对称正定矩阵而设计的,通常应用于解大型的稀疏线性方程组。相较于传统的高斯消元法等直接解法,CG算法具有更快的收敛速度和更小的存储空间要求。

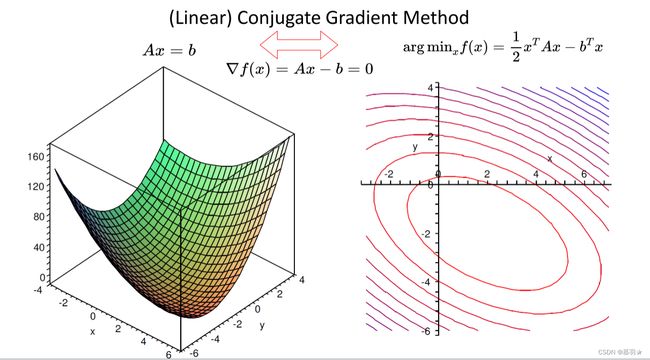
线性共轭梯度法把Ax=b看做一个函数的梯度,以Ax-b为梯度的函数其实就是二次函数 1 2 x T A x − b T x \dfrac{1}{2}x^TAx-b^Tx 21xTAx−bTx,也就是把求Ax=b这个线性方程组转换成求函数 1 2 x T A x − b T x \dfrac{1}{2}x^TAx-b^Tx 21xTAx−bTx的极小值问题。
–
若我们使用传统的最速下降法迭代求该二次函数的极小值,其收敛较慢,如下面左图所示,若使用牛顿法还是要求A的逆。那么有没有一种介于两者之间的方法,在理想的情况下得到精确解,而不需要求逆呢?这就是线性共轭梯度法要做的事。

对于n维超球面来说,进行n次垂直方向上的精确线搜索就可以到达最小值处,且不需要对A求逆

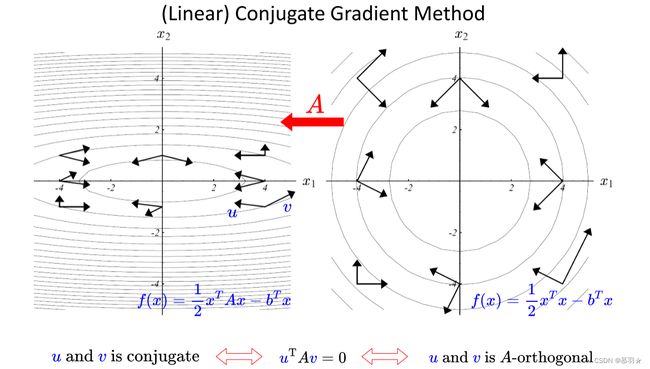
对于一般的二次函数,它的等高面是一系列的同心椭球,我们可以找到一个线性变换,把这一系列的椭球变成一些超球面,在这个球面空间上可以找n个互相垂直的方向,在这n个垂直方向上进行n次精确线搜索,走n步就能到达最小点,即下面右图中的原点,同理,对变换前的一般的二次函数,可以找n个互相共轭的方向,在这n个方向上进行n次精确线搜索,走n步就能到达最小点,如下面的左图所示:
将一般的二次函数 1 2 x T A x − b T x \dfrac{1}{2}x^TAx-b^Tx 21xTAx−bTx中的x用 x k + a u k x^k+au^k xk+auk替换后,得到的表达式对a求导使其等于0,得到步长a的表达式如下图所示,其构成元素中每个A后面都跟着一个 u k u^k uk,即只需要知道A u k u^k uk的整体结果。
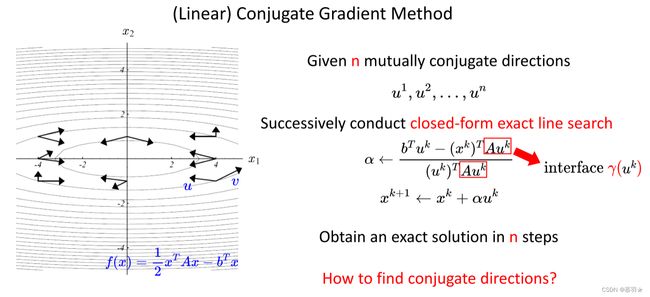
那么如何获取这n个互相共轭的向量呢? 我们可以去k个线性无关的向量,如下图所示,其中 p r o j u 1 ( v 2 ) , \mathrm{proj}_{\mathbf{u}^{1}}\big(\mathbf{v}^{2}\big), proju1(v2),表示,向量v2在向量u1上的投影。(补充:任意两个非零向量v1、v2,有v2减去v2在v1上的投影 一定 垂直于 v1),这其实是针对垂直的史密斯正交化,那么针对共轭的史密斯正交化就是把投影里面的范数改成关于A的范数,把投影替换成共轭投影。

那么这v1~vk个线性无关的向量又是怎么来的呢? ,此外,计算如上的共轭的史密斯正交化过程复杂度也不低
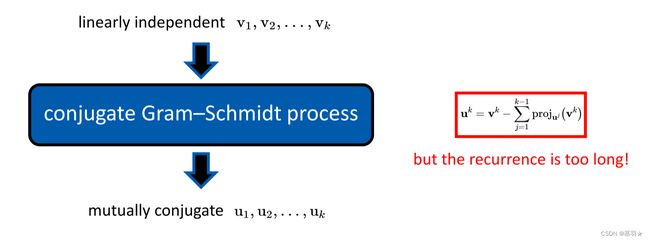
线性共轭梯度法巧妙的采用增量的方式选取v1~vk,且其仅需要计算有限长度的共轭的史密斯正交化


利用上述方式,我们可以得到如下的线性共轭梯度方法,首先取一个初值x1,然后计算x1的残差b-Ax1视为一个线性无关向量v1,因为现在只有一个,所以他本身就是共轭方向u1,迭代变量k初始化为1,当残差vk不等于0时(对于浮点计算,可以取vk>ε作为迭代继续的判断条件),说明没有精确的解完,继续利用共轭梯度进行迭代,计算迭代步长a,更新x到x(k+1),计算k+1的残差v(k+1),(注:b-Ax(k+1)与vk-aAuk等价,然后进行共轭施密特正交化,得到向量u(k+1),以此循环迭代。
如果使用精确算法,线性共轭梯度法总是在n步中找到精确解。
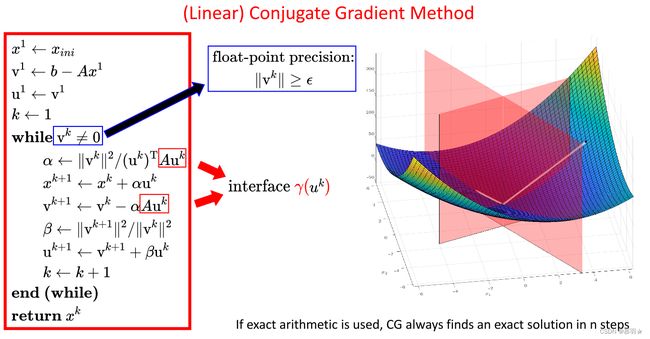

线性共轭梯度法(CG算法)的基本步骤可概括如下:
1、初始化:首先,我们需要给定一个初始解 x 1 x_1 x1 和一个初始残差 v 1 = b − A x 1 v_1 = b - Ax_1 v1=b−Ax1,其中 A A A 是对称正定矩阵, b b b 是右侧的向量。然后,令 u 1 = v 1 u_1 = v_1 u1=v1。
2、迭代:从 x 1 x_1 x1 开始,CG算法通过不断迭代来逼近线性方程组的解。具体来说,算法的第 k k k 步迭代包括以下四个步骤:
2-①:计算当前搜索方向 u k u_k uk 的步长 α k \alpha_k αk: α k = v k T v k u k T A u k \alpha_k=\frac{v_k^T v_k}{u_k^TAu_k} αk=ukTAukvkTvk
2-②:更新当前的解 x k x_k xk: x k + 1 = x k + α k u k x_{k+1}=x_{k}+\alpha_k u_k xk+1=xk+αkuk
2-③:计算当前的残差 v k v_k vk: v k + 1 = v k − α k A u k v_{k+1}=v_{k}-\alpha_kAu_k vk+1=vk−αkAuk
2-④:计算当前迭代的搜索方向 u k u_k uk: β = ∥ v k + 1 ∥ 2 / ∥ v k ∥ 2 \beta=\|\mathbf{v}^{k+1}\|^2/\|\mathbf{v}^k\|^2 β=∥vk+1∥2/∥vk∥2、 u k + 1 = v k + 1 + β u k u_{k+1}=v_{k+1}+\beta u_{k} uk+1=vk+1+βuk,并将迭代变量k加1。
迭代会一直进行下去,直到满足一定的停止条件为止。常见的停止条件包括残差的大小(比如残差小于某个较小量)和迭代次数的限制。
需要注意的是,当矩阵 A A A 不是对称正定矩阵时,CG算法的收敛性可能会受到影响。此时,可以使用预处理技术来提高算法的收敛性能。
十三、牛顿共轭梯度法
在牛顿法中,我们要求解下图所示的表达式,很多时候我们并不想求Hessian矩阵,且想要更快的求解出该问题,前文介绍过求 ( ∇ 2 f ) ξ (\nabla^2f)\xi (∇2f)ξ点积的复杂度跟求函数和梯度是类似的,可以较快的计算出来,因此,我们把共轭梯度的思想应用到牛顿法中,将 ( ∇ 2 f ) ξ (\nabla^2f)\xi (∇2f)ξ看作整体,而不必求出Hessian矩阵具体的值。此外,在牛顿法中我们不一定要求很精确的解,只要满足 l i m g → 0 d ∗ − d ˙ ∣ ∣ g ∣ ∣ = 0 lim_{g→0}\dfrac{d^*- \dot d}{||g||}=0 limg→0∣∣g∣∣d∗−d˙=0时,收敛就可以很快,跟精确求解的收敛速度差不多,其中, d ∗ d^* d∗是最优解, d ˙ \dot d d˙是求出的解,g是梯度。

因此,我们可以把牛顿法中求解以上线性方程组的部分换成下图中蓝色框内的内容,其中,ε始终比 ∇ 2 f \nabla^{2}f ∇2f小一个量级,它表示一个相对精度,里面有些不同之处,比如以0作为 d i d_i di的初值,如果遇上 ( u j ) T ∇ 2 f ( x k ) u j ≤ 0 (\mathbf{u}^{j})^{\mathrm{T}}\nabla^{2}f(x^{k})\mathbf{u}^{j}\leq0 (uj)T∇2f(xk)uj≤0,即当前x的Hessian是不定的或半正定的时候,若当前为第一次迭代,则直接采用最速下降法求本次迭代方向,否则直接退出,本次迭代不更新下降方向,采用上一次的下降方向。这样做的大体思想是遇到负曲率是就不管了,直接拿现有最好的下降方向进行迭代

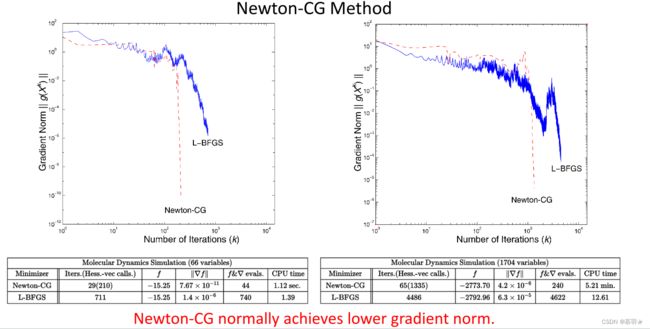
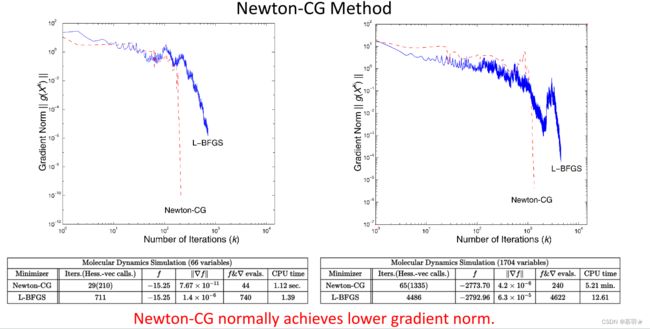
下图对比了牛顿共轭梯度法和L-BFGS方法,从下面两个例子中的场景比较来看牛顿共轭梯度法的收敛速度更快,且可以达到的精度更高
十四、非线性共轭梯度法
1、FR和PRP方法
FR和PRP都是共轭梯度法的变种,分别称为Fletcher-Reeves共轭梯度法和Polak-Ribiere-Polyak共轭梯度法。这两种方法都是在CG算法的搜索方向上做出了改进,以提高算法的收敛速度和稳定性。
FR和PRP共轭梯度法的搜索方向由以下公式确定:
d k = − g k + β k − 1 d k − 1 , d_k=-g_k+\beta_{k-1}d_{k-1}, dk=−gk+βk−1dk−1,
其中, g k g_k gk 是函数 f f f 在当前点 x k x_k xk 的梯度, d k − 1 d_{k-1} dk−1 是上一次迭代的搜索方向,选取不同的 β k − 1 \beta_{k-1} βk−1,便得到不同的共轭梯度公式。FR和PRP是其中两个著名的非线性共轭梯度公式:
①、FR (Flecther-Reeves)公式
β k − 1 F R = g k T g k g k − 1 T g k − 1 ; \beta_{k-1}^{\mathrm{FR}}=\dfrac{g_k^{\mathrm T}g_k}{g_{k-1}^{\mathrm T}g_{k-1}}; βk−1FR=gk−1Tgk−1gkTgk;
②、PRP (Polak-Ribiere-Polyak)公式
β k − 1 P R P = g k T ( g k − g k − 1 ) g k − 1 T g k − 1 T . \beta_{k-1}^{\mathrm{PRP}}=\dfrac{g_k^{\mathrm{T}}(g_k-g_{k-1})}{g_{k-1}^{\mathrm{T}}g_{k-1}^{\mathrm{T}}}. βk−1PRP=gk−1Tgk−1TgkT(gk−gk−1).
我们分别称其为FR共轭梯度方法(简称FR方法)和PRP共轭梯度方法(简称PRP方法).对正定二次函数,有 g k T g k − 1 = 0 g_{k}^{\mathrm{T}}g_{k-1}=0 gkTgk−1=0,此时FR公式与PRP公式等价。
FR共轭梯度法要求函数 f f f 是二次凸函数或具有类似性质,才能保证算法的收敛性。PRP共轭梯度法对函数 f f f 的要求比较宽松,只需要函数的梯度不变号即可保证收敛性。在实践中,PRP通常比FR更稳定,收敛速度也更快。
无论是FR还是PRP共轭梯度法,它们都是针对特定类型的函数而设计的。因此,在具体应用中需要根据问题的特点选择合适的算法。
2、非线性共轭梯度法流程

以FR方法为例介绍非线性共轭梯度法流程:
(1)初始化,选择一个初始点 x 0 x_0 x0,计算函数 f f f在 x 0 x_0 x0处的梯度 g 0 \ g_0 g0,设搜索方向 d 0 = − g 0 d_0=- g_0 d0=−g0,以及迭代次数 k = 0 k=0 k=0。
(2)判断是否满足终止条件,若满足则停止迭代。
(3)根据选定的步长搜索策略,计算出步长 α k \alpha_k αk。
(4)更新函数值 x k + 1 = x k + α k d k {x}_{k+1}={x}_{k}+\alpha_{k}d_{k} xk+1=xk+αkdk,并计算出函数 f f f在 x k + 1 x_{k+1} xk+1处的梯度 g k + 1 g_{k+1} gk+1。
(5)计算 β k \beta_{k} βk: β k = g k + 1 T g k + 1 g k 1 T g k 1 ; \beta_{k}=\dfrac{g_{k+1}^{\mathrm T}g_{k+1}}{g_{k1}^{\mathrm T}g_{k1}}; βk=gk1Tgk1gk+1Tgk+1;
(6)更新搜索方向和迭代次数,计算出下一个搜索方向 d k + 1 d_{k+1} dk+1,并将迭代次数加1,即 k = k + 1 k=k+1 k=k+1。转第(2)步。
d k + 1 = − g k + 1 + β k d k , d_{k+1}=-g_{k+1}+\beta_{k}d_{k}, dk+1=−gk+1+βkdk,
补充:可以使用以下终止条件:
(1) ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ,其中 ϵ \epsilon ϵ是一个较小的正数。
(2) ∣ ∣ d k ∣ ∣ < ϵ ||d_k||<\epsilon ∣∣dk∣∣<ϵ,其中 ϵ \epsilon ϵ是一个较小的正数。
(3) ∣ Δ f k ∣ < ϵ |\Delta f_k|<\epsilon ∣Δfk∣<ϵ,其中 Δ f k = f k − f k − 1 \Delta f_k=f_k-f_{k-1} Δfk=fk−fk−1。
(4)达到预设的最大迭代次数。
3、其他共轭梯度公式
Fletcher和 Revees提出在共轭梯度方法中使用非精确线搜索,从而将求解线性方程组的共轭梯度方法推广至求解一般最优化问题.该方法是最早提出的非线性共轭梯度方法。因而在共轭梯度方法中占有非常重要的地位.。
在非线性共轭梯度方法中,使用精确线搜索与非精确线搜索是有差别的.使用精确线搜索,可以保证迭代方向的下降性.这是因为对精确线搜索,有 g k T d k − 1 = 0 g_{k}^{\mathrm{T}}d_{k-1}=0 gkTdk−1=0,从而有下式成立
g k T d k = − g k T g k + β k − 1 g k T d k − 1 < 0. g_k^\mathrm{T}d_k=-g_k^\mathrm{T}g_k+\beta_{k-1}g_k^\mathrm{T}d_{k-1}<0. gkTdk=−gkTgk+βk−1gkTdk−1<0.
而若采用非精确线搜索,FR方法和 PRP方法都有可能产生上升的方向.对FR方法而言,只有当使用强 Wolfe 线搜索并保证0<σ<1/2时,得到的方向是下降方向。
其他共轭梯度公式
①、 P R P + PRP^+ PRP+公式
β k − 1 P R P \beta_{k-1}^{\mathrm{PRP}} βk−1PRP会出现取负值的情形,为避免此种情形的发生, Powell建议 β k − 1 P R P \beta_{k-1}^{\mathrm{PRP}} βk−1PRP取为
β k − 1 P R P + = max { β k − 1 P R P , 0 } . \beta_{k-1}^{\mathrm{PRP}^+}=\max\{\beta_{k-1}^{\mathrm{PRP}},0\}. βk−1PRP+=max{βk−1PRP,0}.
当|| d k d_k dk||很大时,这种做法可以避免相邻的两个搜索方向趋于相反的方向.在适当的线搜索条件下,对一般非凸函数,该方法具有全局收敛性.
–
②、共轭下降(Conjugate Descent,CD)公式
β k − 1 C D = − g k T g k d k − 1 T g k − 1 . \beta_{k-1}^{\mathrm{CD}}=-\dfrac{g_k^{\mathrm{T}}g_k}{d_{k-1}^{\mathrm{T}}g_{k-1}}. βk−1CD=−dk−1Tgk−1gkTgk.
采用该公式的好处是:当使用强 Wolfe线搜索准则并且σ<1时,共轭下降方法得到的方向为下降方向。
–
③、DY (Dai-Yuan)公式
β k − 1 D Y = g k T g k d k − 1 T ( g k − g k − 1 ) . \beta_{k-1}^{\mathrm{DY}}=\dfrac{g_k^{\mathrm{T}}g_k}{d_{k-1}^{\mathrm{T}}(g_k-g_{k-1})}. βk−1DY=dk−1T(gk−gk−1)gkTgk.
该公式可以保证采用Wolfe线搜索准则的共轭梯度方法每一步产生下降的迭代方向,并且方法具有全局收敛性.
4、n步重新开始策略
对一般函数而言,目标函数的Hessian矩阵不再是常数矩阵,用共轭梯度方法产生的方向不再具有共轭性质,PRP方法与FR方法亦不再等价.只有采用精确线搜索时,共辄梯度方法仍是下降算法.在将共辄梯度方法用于一般函数时,我们可以考虑以下策略:
当迭代点接近极小点时,在极小点的邻域中目标函数可以较好地被正定二次函数近似.考虑到共瓴梯度方法对正定二次函数的二次终止性,需要在初始点处取负梯度方向.故对一般函数采用共轭梯度方法时,可以用n步重新开始策略,即每隔n步,迭代方向就取为负梯度方向.具体的取法是
d k = { − g k , k = c n , c = 0 , 1 , 2 , ⋯ , − g k + β k − 1 d k − 1 , k ≠ c n , c = 0 , 1 , 2 , ⋯ . d_k=\begin{cases}-g_k,&k=cn,c=0,1,2,\cdots,\\ -g_k+\beta_{k-1}d_{k-1},&k\neq cn,c=0,1,2,\cdots.\end{cases} dk={−gk,−gk+βk−1dk−1,k=cn,c=0,1,2,⋯,k=cn,c=0,1,2,⋯.
参考资料:
1、数值最优化方法(高立 编著)
2、机器人中的数值优化