6、HIVE JDBC开发、UDF、体系结构、Thrift服务器、Driver、元数据库Metastore、数据库连接模式、单/多用户模式、远程服务模式、Hive技术原理解析、优化等(整理的笔记)
目录:
5 HIVE开发
5.1 Hive JDBC开发
5.2 Hive UDF
6 Hive的体系结构
6.2 Thrift服务器
6.3 Driver
6.4 元数据库Metastore
6.5 数据库连接模式
6.5.1 单用户模式
6.5.2 多用户模式
6.5.3 远程服务模式
7 Hive技术原理解析
7.1 Hive工作原理
7.2.1 Hive编译器的组成
7.2.2 Query Compiler
7.2.3新版本Hive也支持Tez或Spark作为执行引擎
8 Hive优化
5 HIVE开发
5.1 Hive JDBC开发
若想进行Hive JDBC的开发,需要开启HiveServer2服务,这里要参考第二章节的”连接方式”中的HiveServer2/beeline章节。
其中一个Hive JDBC的案例如下:
启动完HiveServer2服务,就提供JDBC服务了,类似:
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
//replace "hive" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "hive", "");
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
String filepath = "/tmp/a.txt";
sql = "load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
stmt.execute(sql);
// select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
}
// regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
5.2 Hive UDF
简单UDF示例
前期准备,要把hive的lib包导入到工程中,其中UDF依赖的是hive-exec-2.3.4.jar(针对hive2.3.4版本)。也就是说要把$HIVE_HOME\lib中的内容引入到工程中。若用到hadoop中的一些api,也把hadoop的相关的jar包也引入进去。
1、先开发一个java类,继承UDF,并重载evaluate方法。
package hiveudf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class ToLowerCase extends UDF {
public Text evaluate(final Text s) {
if(s == null) {returnnull;}
returnnew Text(s.toString().toLowerCase());
}
}
2、打成jar包上传到服务器
3、将jar包添加到hive的classpath
4、hive> add jar /home/udf/hivedata/udf.jar;
5、hive>创建临时函数与开发好的java class关联
hive> create temporary function toLowercase as 'hiveudf.ToLowerCase';
OK
Time taken: 0.039 seconds
hive>
6、即可在HiveQL中使用自定义的函数toLowercase
hive> select toLowercase("ZHANGSAN") from dual;
OK
zhangsan
Time taken: 0.122 seconds, Fetched: 1 row(s)
hive>
再如判断身份证的一个UDF函数:
package com.xxx.xxx.udf;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 身份证校验UDF
*
* @author xxx
* @date 2019年5月29日
*
* 1.身份证号码构成:6位地址编码+8位生日+3位顺序码+1位校验码
* 2.验证15位,18位证件号码是否有效;
* 3.15位号码将直接转为18位;【这一步不做转化】
* 4.校验身份证号码除了校验位是否为数值,校验省份、出生日期
* 省份编码[11, 12, 13, 14, 15, 21, 22, 23, 31, 32, 33, 34, 35, 36, 37, 41, 42, 43,
44, 45, 46, 50, 51, 52, 53, 54, 61, 62, 63, 64, 65, 71, 81, 82, 91]
* 5.校验位不正确的会被正确的替代.【最后1位是根据前面17位生成的,如果不正确,会生成正确的检验码进行修正.】
* 6.出生日期逻辑有效性,即是否1864年前出生,是否当前日期后出生已校验。
* 7.1984年4月6日国务院发布《中华人民共和国居民身份证试行条例》,并且开始颁发第一代居民身份证,按寿命120岁验证,年龄区间是1864年至今。
* 8.15位证件号码转换未考虑1900年前出生的人【这一步不做转化】
* 9.去除null,去除空串,去除非15位和18位
* 10.判断前17位是否含非数字字符.
* 11.判断非法日期,如生日所在日期(2019年2月29日)不存在.
*
* add jar hdfs://tqHadoopCluster/xxx/udf/idCardUdf.jar;
* create temporary function cheakIdCardNumber as 'com.xxx.xxx.udf.IdNumber';
* 这这就可以使用cheakIdCardNumber(String idCardNumber)进行校验身份证了
*/
public class IdNumber extends UDF {
private final static int NEW_CARD_NUMBER_LENGTH = 18;
private final static int OLD_CARD_NUMBER_LENGTH = 15;
/** 开始年份 */
private final static int YEAR_BEGIN = 1864;
/** 18位身份证中最后一位校验码 */
private final static char[] VERIFY_CODE = {'1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'};
/** 18位身份证中,各个数字的生成校验码时的权值 */
private final static int[] VERIFY_CODE_WEIGHT = {7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2};
/** 省份编码集合 */
private final static int[] PROVINCE_CODE = {11, 12, 13, 14, 15, 21, 22, 23, 31, 32, 33, 34, 35, 36, 37, 41, 42, 43,
44, 45, 46, 50, 51, 52, 53, 54, 61, 62, 63, 64, 65, 71, 81, 82, 91};
private final static Pattern PATTERN = Pattern.compile("[0-9]*");
private final static ThreadLocal<SimpleDateFormat> THREADLOCAL = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
// 直接返回null
return null;
}
};
/*
public static void main(String[] args) {
IdNumber idNumber = new IdNumber();
//String evaluate = idNumber.evaluate("125197791116622");
// 125197 791116622
// 12519719791116622X
// 330304198705234817
String evaluate = idNumber.evaluate("330304201902284815");
System.out.println(evaluate);
}
*/
public String evaluate(String cardNumber) {
// 1.去除NULL
if (cardNumber == null) {
return null;
}
Date dNow = new Date();
SimpleDateFormat ft = new SimpleDateFormat("yyyy");
int yearEnd = Integer.parseInt(ft.format(dNow));
cardNumber = cardNumber.trim();
// 2.去除空字符串
if (cardNumber.length() == 0) {
return null;
}
// 3.去除长度不正确的,非15或18位
if (NEW_CARD_NUMBER_LENGTH != cardNumber.length() & OLD_CARD_NUMBER_LENGTH != cardNumber.length()) {
return null;
}
// 4.如果是18位
if (NEW_CARD_NUMBER_LENGTH == cardNumber.length()) {
// 4.1.前17位不为数值,返回null
if (isNumeric(cardNumber.substring(0, 17)) == false) {
return null;
}
// 校验位修正,判断最后一位是否正确
if (IdNumber.calculateVerifyCode(cardNumber) != cardNumber.charAt(17)) {
//如果最后一位校验码不会,则修正校验码.
cardNumber = contertToNewCardNumber(cardNumber, NEW_CARD_NUMBER_LENGTH);
}
// 身份证前2位是省份编码, 如果编码不在已知集合中, 返回null.
if (isProvince(cardNumber.substring(0, 2)) == false) {
return null;
}
// 非法日期转换前后不一致, 如当前年份不存在2月29日, 返回null
if (isDate(cardNumber.substring(6, 14)) == false) {
return null;
}
// 1984年4月6日国务院发布《中华人民共和国居民身份证试行条例》,并且开始颁发第一代居民身份证,按寿命120岁验证,年龄区间是1864年至今。 小于1984的为非法.
int birthdayYear = Integer.parseInt(cardNumber.substring(6, 10));
if (birthdayYear < YEAR_BEGIN) {
return null;
}
// 如果出生年月大于当前日期, 返回null
if (birthdayYear > yearEnd) {
return null;
}
}
// 5.如果是15位:15位身份证号码不转换为18位.
if (OLD_CARD_NUMBER_LENGTH == cardNumber.length()) {
// 前15位中含非数字字符, 返回null
if (isNumeric(cardNumber) == false) {
return null;
}
// 省份编码不在在已知集合中, 返回null
if (isProvince(cardNumber.substring(0, 2)) == false) {
return null;
}
// 非法日期转换前后不一致, 返回null
if (isDate("19" + cardNumber.substring(6, 12)) == false) {
return null;
}
//将15位身份证转化为18位,考虑1900年前出生的人。
//cardNumber = contertToNewCardNumber(cardNumber, OLD_CARD_NUMBER_LENGTH);
}
return cardNumber;
}
/**
* 校验码(第十八位数):
*
* 十七位数字本体码加权求和公式 S = Sum(Ai * Wi), i = 0...16 ,先对前17位数字的权求和;
* Ai:表示第i位置上的身份证号码数字值
* Wi:表示第i位置上的加权因子
* Wi: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2;
* 计算模 Y = mod(S, 11) 通过模得到对应的校验码
* Y: 0 1 2 3 4 5 6 7 8 9 10
* 校验码: 1 0 X 9 8 7 6 5 4 3 2
*
* @param cardNumber
* @return
*/
private static char calculateVerifyCode(CharSequence cardNumber) {
int sum = 0;
for (int i = 0; i < NEW_CARD_NUMBER_LENGTH - 1; i++) {
char ch = cardNumber.charAt(i);
sum += ((int)(ch - '0')) * VERIFY_CODE_WEIGHT[i];
}
//VERIFY_CODE = {'1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'};
return VERIFY_CODE[sum % 11];
}
/**
* A-把15位身份证号码转换到18位身份证号码 15位身份证号码与18位身份证号码的区别为:
* 1. 15位身份证号码中,"出生年份"字段是2位,转换时需要补入"19",表示20世纪
* 2. 15位身份证无最后一位校验码。18位身份证中,校验码根据根据前17位生成 B-18位身份证号码校验位修复
*
* @param cardNumber
* @return
*/
private static String contertToNewCardNumber(String idCardNumber, int cardNumberLength) {
StringBuilder buf = new StringBuilder(NEW_CARD_NUMBER_LENGTH);
if (cardNumberLength == NEW_CARD_NUMBER_LENGTH) {
buf.append(idCardNumber.substring(0, 17));
buf.append(IdNumber.calculateVerifyCode(buf));
} else if (cardNumberLength == OLD_CARD_NUMBER_LENGTH) {
buf.append(idCardNumber.substring(0, 6));
buf.append("19");
buf.append(idCardNumber.substring(6));
buf.append(IdNumber.calculateVerifyCode(buf));
}
return buf.toString();
}
/**
* 功能:判断字符串是否为数字
*
* @param str
* @return
*/
private static boolean isNumeric(String str) {
Matcher isNum = PATTERN.matcher(str);
if (isNum.matches()) {
return true;
} else {
return false;
}
}
/**
* 功能:判断前两位是在省份编码集合内
* @param province
* @return
*/
private static boolean isProvince(String province) {
int prov = Integer.parseInt(province);
for (int i = 0; i < PROVINCE_CODE.length; i++) {
if (PROVINCE_CODE[i] == prov) {
return true;
}
}
return false;
}
public static SimpleDateFormat getDateFormat() {
SimpleDateFormat df = (SimpleDateFormat)THREADLOCAL.get();
if (df == null) {
df = new SimpleDateFormat("yyyyMMdd");
df.setLenient(false);
THREADLOCAL.set(df);
}
return df;
}
/**
* 功能:判断出生日期字段是否为日期
*
* @param str
* @return
*/
private static boolean isDate(String birthDate) {
try {
SimpleDateFormat sdf = getDateFormat();
//如果不合法,会抛异常, Unparseable date: "20190229"
Date cacheBirthDate = sdf.parse(birthDate);
if (sdf.format(cacheBirthDate).equals(birthDate) == false) {
// 非法日期转换前后不一致
return false;
}
} catch (Exception e) {
//e.printStackTrace();
return false;
}
return true;
}
}
6 Hive的体系结构
下面是Hive的架构图:
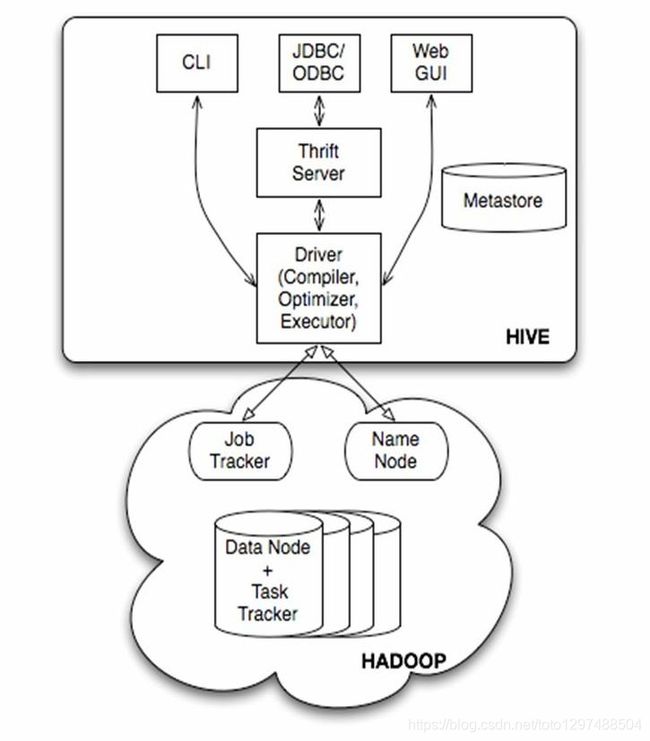
图 1 Hive体系结构
6.1用户接口
(1)、CLI:CLI启动的时候,会同时启动一个Hive副本。
(2)、JDBC客户端:封装了Thrift,java应用程序,可以通过指定的主机和端口连接到在另外一个进程中运行的hive服务器。
(3)、ODBC客户端:ODBC驱动允许支持ODBC协议的应用程序连接到Hive
(4)、WUI接口:通过浏览器访问Hive
6.2Thrift服务器
基于socket通讯,支持跨语言。Hive Thrift服务简化了在多编程语言中运行hive的命令。绑定支持C++,Java,PHP,Python和Ruby语言。
6.3 Driver
核心组件,整个Hive的核心,该组件包括Complier、Optimizer和Executor; 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
6.4 元数据库Metastore
Hive的数据由两部分组成:数据文件和元数据。元数据用于存放Hive库的基础信息,它存储在关系数据库中,例如mysql、Oracle、derby。元数据包括:数据库信息、表达的名字,表的列和分区及其属性,表的属性,表的数据所在目录等。
Hadoop
Hive的数据文件存储在HDFS中,大部分的查询由MapReduce完成。(对于包含*的查询,比如select * from tbl不会生成MapReduce作业)
6.5数据库连接模式
6.5.1 单用户模式
此模式连接到一个In-memory的数据库Derby,Derby数据是Hive自带的数据库,默认只能有一个连接,用户连接到Hive后,会在当前目录生成一个metastore文件来存放元数据信息,不同的用户连接到Hive看到的信息不一致。
6.5.2多用户模式
通过网络连接到一个关系型数据库中,如MySQL,是最进程使用到的模式。这样多个用户操作的元数据信息统一放到关系型数据库,这样不同用户可以操作相同的对象。
6.5.3 远程服务模式
用于非Java客户端访问元数据,在服务器启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据。
7 Hive技术原理解析
7.1 Hive工作原理
如下图所示:

流程大致步骤为:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
创建表时:
1、解析用户提交的Hive语句对其进行解析分解为表、字段、分区等Hive对象。根据解析到的信息构建对应的表、字段、分区等对象,从SEQUENCE_TABLE中获取构建对象的最新的ID,与构建对象信息(名称、类型等等)一同通过DAO方法写入元数据库的表中,成功后将SEQUENCE_TABLE中对应的最新ID+5.实际上常见的RDBMS都是通过这种方法进行组织的,其系统表中和Hive元素一样显示了这些ID信息。通过这些元数据可以很容易的读取到数据。
工作原理的另外一种说法是:
接收到一个sql,后面做的事情包括:
1.词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产
生成逻辑计划-算子树
4.逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成
将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行
将DAG发送到Hadoop集群进行执行
7.将查询结果返回
流程如下图:

7.2 Hive编译过程
转化过程:
基本流程为:将HiveQL转化为”抽象语法树”—>”查询块”—>”逻辑查询计划””物理查询计划”最终选择最佳决策的过程。
优化器的主要功能:
- 将多Multiple join 合并为一个Muti-way join
- 对join、group-by和自定义的MapReduce操作重新进行划分。
- 消减不必要的列。
- 在表的扫描操作中推行使用断言。
- 对于已分区的表,消减不必要的分区。
- 在抽样查询中,消减不必要的桶。
- 优化器还增加了局部聚合操作用于处理大分组聚合和增加再分区操作用于处理不对称的分组聚合。
7.2.1 Hive编译器的组成

对于此的说明,网络上的另外一种说明:


7.2.2 Query Compiler
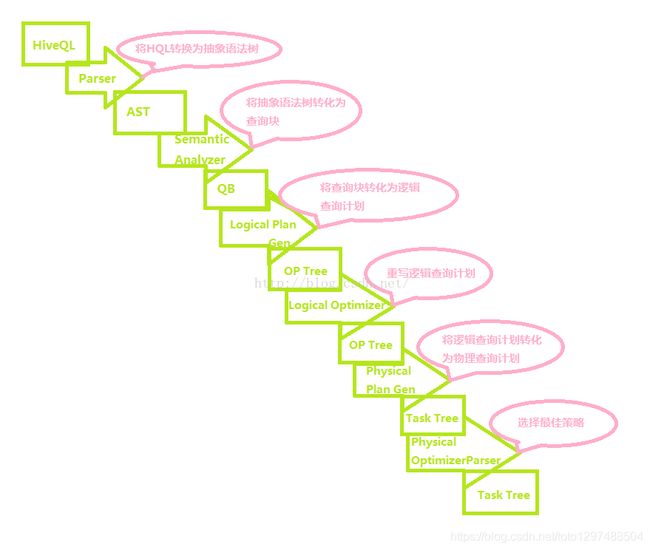
网络上描述上述过程的另外一张图(同样是Query Compiler过程的另外一种画法):

为了说明上述执行流程,需要辅助一个简单的Hive查询例子:
案例1-1:Hive执行以下语句:
INSERT OVERWRITE TABLE access_log_temp2
SELECT a.user, a.prono, a.maker, a.price FROM access_log_hbase a JOIN product_hbase p
ON (a.prono = p.prono)
具体执行流程:
(1)Parser生成AST
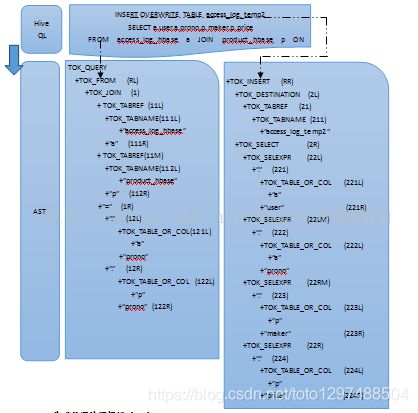
HQL生成的语法解析树(AST):
HIVE主要是利用UNDERLER处理得到上面的抽象语法树(这棵抽象语法树主要是根据underller的分词规则来确定根结点和左右孩子的,Hive的这部分处理是利用underller进行的)。
(2)Semantic Analyzer生成Query Block(QB)
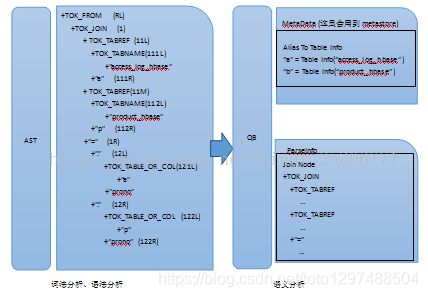
Tip:
第二步会将抽象语法树按照QB的方式转换为由QB组成的树。通常情况下,每一个From子句会生成一个QB(Query Block)。通过查看具体有多少个QB就可查看Hive sql语句最终优化成多少个MapReduce的作业。
QB是由两个子数据结构组成即MetaData(元数据信息)和ParseInfo。语义分析的主要过程是向QB中填充元数据,另一个过程则是摘取AST的子节点,存储在ParseInfo中。Semantic Analyzer过程主要是经过以上两个过程,然后把QB关联起来形成一个由QB构成的图.
Logical Plan generator会将上一步生成的Query Block按照前文讲的几种的Operator,转换为Operator Tree。

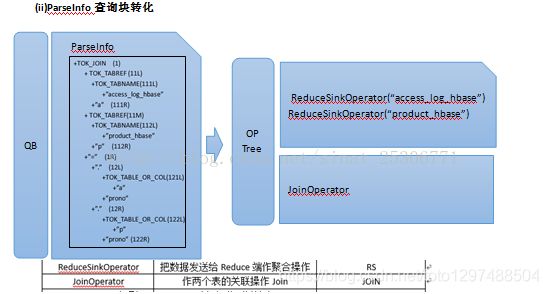

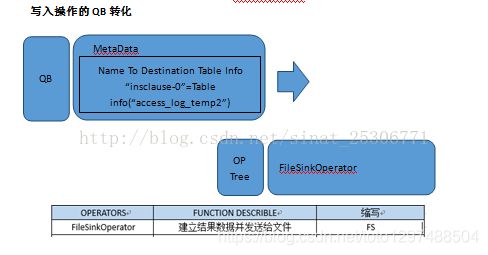
由于Hive查询语句会将最后的查询结果写入到表access_log_temp2中,所以QB的MetaData中的Name To Destination…会转化为Operator Tree中的FileSinkOperator(文件下沉)。
最后会生成如下的OP Tree:
Logical Plan Generator (Result)
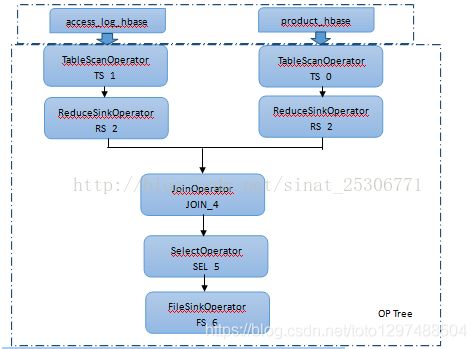
这里就得到了一个有向无环图(DAG),当在传统数据库中会对上图进行优化然后执行;而在Hadoop集群中这张图是不行的,因为在集群中执行需要对这张图进行优化、切片,分布式化转化为MapReduce作业然后执行。
7.2.3新版本Hive也支持Tez或Spark作为执行引擎:
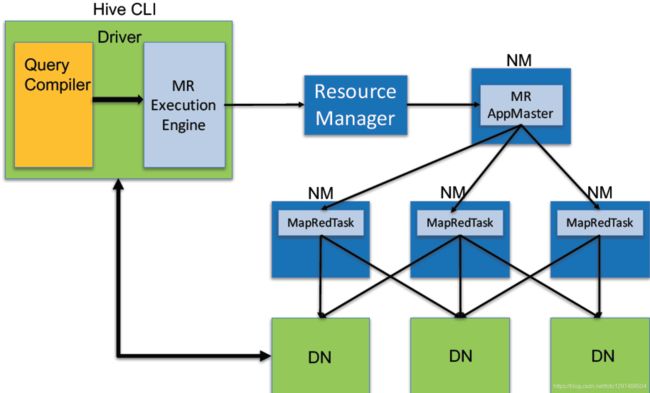

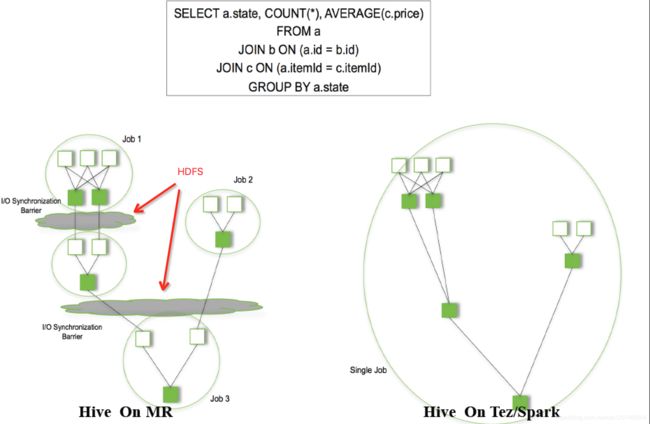
物理计划可以通过hive的Explain命令输出:
例如:
0: jdbc:hive2://master:10000/dbmfz> explain select count(*) from record_dimension;
+------------------------------------------------------------------------------------------------------+--+
| Explain |
+------------------------------------------------------------------------------------------------------+--+
| STAGE DEPENDENCIES: |
| Stage-1 is a root stage |
| Stage-0 depends on stages: Stage-1 |
| |
| STAGE PLANS: |
| Stage: Stage-1 |
| Map Reduce |
| Map Operator Tree: |
| TableScan |
| alias: record_dimension |
| Statistics: Num rows: 1 Data size: 543 Basic stats: COMPLETE Column stats: COMPLETE |
| Select Operator |
| Statistics: Num rows: 1 Data size: 543 Basic stats: COMPLETE Column stats: COMPLETE |
| Group By Operator |
| aggregations: count() |
| mode: hash |
| outputColumnNames: _col0 |
| Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE |
| Reduce Output Operator |
| sort order: |
| Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE |
| value expressions: _col0 (type: bigint) |
| Reduce Operator Tree: |
| Group By Operator |
| aggregations: count(VALUE._col0) |
| mode: mergepartial |
| outputColumnNames: _col0 |
| Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE |
| File Output Operator |
| compressed: false |
| Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE |
| table: |
| input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
| output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
| serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| |
| Stage: Stage-0 |
| Fetch Operator |
| limit: -1 |
| Processor Tree: |
| ListSink |
| |
+------------------------------------------------------------------------------------------------------+--+
rows selected (0.844 seconds)
8 Hive优化
1、join连接时的优化:当三个或多个以上的表进行join操作时,如果每个on使用相同的字段连接时只会产生一个mapreduce。
2、join连接时的优化:当多个表进行查询时,从左到右表的大小顺序应该是从小到大。原因:hive在对每行记录操作时会把其他表先缓存起来,直到扫描最后的表进行计算
3、在where字句中增加分区过滤器。
4、当可以使用left semi join 语法时不要使用inner join,前者效率更高。原因:对于左表中指定的一条记录,一旦在右表中找到立即停止扫描。
5、如果所有表中有一张表足够小,则可置于内存中,这样在和其他表进行连接的时候就能完成匹配,省略掉reduce过程。设置属性即可实现,set hive.auto.covert.join=true; 用户可以配置希望被优化的小表的大小 set hive.mapjoin.smalltable.size=2500000; 如果需要使用这两个配置可置入$HOME/.hiverc文件中。
6、同一种数据的多种处理:从一个数据源产生的多个数据聚合,无需每次聚合都需要重新扫描一次。
例如:insert overwrite table student select * from employee; insert overwrite table person select * from employee;
可以优化成:from employee insert overwrite table student select * insert overwrite table person select *
7、limit调优:limit语句通常是执行整个语句后返回部分结果。set hive.limit.optimize.enable=true;
8、开启并发执行。某个job任务中可能包含众多的阶段,其中某些阶段没有依赖关系可以并发执行,开启并发执行后job任务可以更快的完成。设置属性:set hive.exec.parallel=true;
9、hive提供的严格模式,禁止3种情况下的查询模式。
a:当表为分区表时,where字句后没有分区字段和限制时,不允许执行。
b:当使用order by语句时,必须使用limit字段,因为order by 只会产生一个reduce任务。
c:限制笛卡尔积的查询。
10、合理的设置map和reduce数量。
11、jvm重用。可在hadoop的mapred-site.xml中设置jvm被重用的次数。
打个赏呗,您的支持是我坚持写好博文的动力
