mysql与缓存数据不一致解决-canal+mq方案
mysql与缓存数据不一致解决-canal+mq方案
实际项目中,经常有遇到缓存与mysql数据不一致处理问题,本质上解决并发操作对同一份数据,如何控制mysql 和 redis读和写的有序性,例如在数据库更新完数据前读了旧值并写了缓存就会存在缓存的值不正确的问题。一般的解决方案都是写完数据库后删除缓存(延迟双删)或者重新写入缓存。相对于删除,更新后重新写入会存在更多的并发的问题,而对于删除的缓存为了防止删除失败,会在缓存删除失败时加入消息队列或者定时任务重试删除缓存,防止数据不一致。
用canal来解决缓存不一致的问题的思路也是删除缓存的思路,就是监听主库中binlog某个业务表,即相关的缓存数据。若业务表发生变化,canal客户端监听到数据变动,并且对数据变动做出判断,即可以删除缓存。该方案的优点利用canal可以在多个不同微服务系统之间管理缓存,统一管控缓存不一致,引入公共包,减少重复代码。
缺点是这个过程缓存数据的失效是具有一定的延迟性的,延迟的,对于对缓存数据一致性要求较高的,例如实时的促销秒杀活动,涉及到价格的敏感数据,还是需要一定的业务辅助手段去校验,防止缓存短暂的延时性带来经济损失。
另外,为了解决系统的并发性、解耦性和稳定性,将canal的订阅binlog发送到mq中,可以监听不同数据库,分队列发送给服务端消费者,提高系统吞吐量。当redis删除失败时,可以利用消息机制重试或者加入重试表进行重试。下面是具体代码实现。

统一缓存管理
定义统一的缓存对象,统一缓存管理。并且加初始化的缓存对象加入全局缓存管理对象中。
@Getter
public class RedisKeyDefine {
@Getter
@AllArgsConstructor
public enum KeyTypeEnum {
STRING("String"),
LIST("List"),
HASH("Hash"),
SET("Set"),
ZSET("Sorted Set"),
STREAM("Stream"),
PUBSUB("Pub/Sub");
/**
* 类型
*/
@JsonValue
private final String type;
}
@Getter
@AllArgsConstructor
public enum TimeoutTypeEnum {
FOREVER(1), // 永不超时
DYNAMIC(2), // 动态超时
FIXED(3); // 固定超时
/**
* 类型
*/
@JsonValue
private final Integer type;
}
/**
* Key 模板
*/
private final String keyTemplate;
/**
* Key 类型的枚举
*/
private final KeyTypeEnum keyType;
/**
* Value 类型
*
* 如果是使用分布式锁,设置为 {@link java.util.concurrent.locks.Lock} 类型
*/
private final Class<?> valueType;
/**
* 超时类型
*/
private final TimeoutTypeEnum timeoutType;
/**
* 过期时间
*/
private final Duration timeout;
/**
* 备注
*/
private final String memo;
/**
* 对应的表 分库分表的话对应表前缀
*/
private final String table;
/**
* key对应的表字段 可以对应多字段
*/
private final List<String> tableColumnList;
}
全局缓存对象,是一个map,key值是缓存对应的mysql表字段。
@Slf4j
public class RedisKeyRegistry {
/**
* Redis RedisKeyDefine 数组
*/
private static final Map<String, RedisKeyDefine> definesMap = new HashMap<>();
public static void add(RedisKeyDefine define) {
log.info("redisKeyDefine add {}", JsonUtils.toJsonString(define));
definesMap.put(define.getTable(), define);
}
public static Map<String, RedisKeyDefine> getDefines() {
return definesMap;
}
public static int size() {
return definesMap.size();
}
}
canal的mq队列监听
这里用的rabbitmq,在管理台中添加了canal对应的echange和队列,就可以监听canal指定的数据变化,canal支持到不同实例不同库以及不同表级别的监听。rabbitmq没有试过不同表对应到不同队列的监听,官网上rocketmq是支持的,并且有相应的配置,感兴趣可以自己尝试下。如果不想,可以修改canal的instance监听的表,也可以达到相同的效果。
mq队列监听代码,监听到对应的表数据变化后,先去全局缓存管理处拿到缓存类,然后判断变化数据,并且删除对应缓存。如果是分库分表的表结构,只需要拿表的前缀即可。
@Component
@Slf4j
public class CanalMQListener {
private AtomicInteger messageCount = new AtomicInteger(0);
private AtomicInteger sqlCount = new AtomicInteger(0);;
@Resource
private StringRedisTemplate stringRedisTemplate;
@RabbitListener(queues = "canal.test.queue")
public void CanalMessageHandler(Message mqMessage, Channel channel) {
try {
//获取指定数量的数据,但是不做确认标记,下一次取还会取到这些信息。 注:不会阻塞,若不够100,则有多少返回多少
CanalMessage message = JsonUtils.parseObject(new String(mqMessage.getBody(), StandardCharsets.UTF_8),
CanalMessage.class);
//获取消息id
assert message != null;
printEnity(message);
} catch (Exception e) {
log.error("canal消息处理失败: {}, error info {}", new String(mqMessage.getBody(), StandardCharsets.UTF_8), e.getMessage());
throw new RuntimeException(e);
}
}
private void printEnity(CanalMessage message) {
if (EventType.QUERY.getTypeName().equals(message.getType()) || message.getIsDdl()) {
log.info("sql ------------>{}" ,message.getSql());
}
log.info(String.format("================>; message id [%s], name[%s,%s] , eventType : %s, messageCount : %d",
message.getId(),
message.getDatabase(), message.getTable(),
message.getType(), messageCount.addAndGet(1)));
EventType type = EventType.getEventByTypeName(message.getType());
if (type == null) {
log.info ("unknown type {}", message.getType());
return;
}
for (int i = 0; i < message.getData().size(); i++) {
switch (type){
//如果希望监听多种事件,可以手动增加case
case UPDATE:
printColumn(message.getData().get(i), message.getOld().get(i));
handleRedisCache(message.getTable(), message.getData().get(i));
break;
case INSERT:
printColumn(message.getData().get(i), message.getOld().get(i));
handleRedisCache(message.getTable(), message.getData().get(i));
break;
case DELETE:
printColumn(message.getData().get(i), message.getOld().get(i));
handleRedisCache(message.getTable(), message.getData().get(i));
break;
default:
}
}
}
private void printColumn(Object changeData, Object oldData) {
String sb =
"count" + sqlCount.addAndGet(1) + " " +
"old data:" + JsonUtils.toJsonString(oldData) +
"==>" +
"new data" + JsonUtils.toJsonString(changeData);
log.info(sb);
}
private void handleRedisCache(String tableName, Object changeData) {
// 分库分表,需要抽取表前缀
RedisKeyDefine redisKeyDefine = RedisKeyRegistry.getDefines().get(tableName.substring(0,tableName.length()-2));
if (redisKeyDefine != null) {
JsonNode jsonNode = JsonUtils.readTree(JsonUtils.toJsonString(changeData));
List<String> keyColumns = new ArrayList<>();
Iterator<Map.Entry<String,JsonNode>> it =jsonNode.fields();
while(it.hasNext()){
Map.Entry<String,JsonNode> entry=it.next();
if (redisKeyDefine.getTableColumnList().contains(entry.getKey())) {
keyColumns.add(entry.getValue().asText());
}
}
String key = String.format(redisKeyDefine.getKeyTemplate(), keyColumns.toArray());
log.info("delete cache, key is {}", key);
stringRedisTemplate.delete(key);
}
}
}
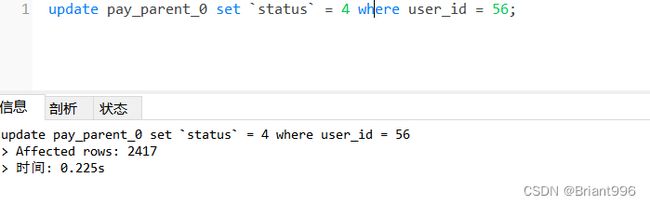
监听效果,这里我修改了2417条数据
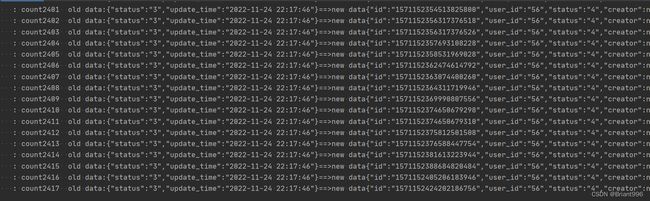
日志打印如下,同样是也是2417条,在200ms内消费完,官网统计是至少有5000的吞吐量,简单的配置就可以达到,可见性能一斑,延迟一般控制在500ms内。
如果没有配置队列的话,canal自由的监听也是可以的,代码如下
@Component
@Slf4j
public class MysqlDataListening {
private static final ThreadFactory springThreadFactory = new CustomizableThreadFactory("canal-pool-");
private static final ExecutorService executors = Executors.newFixedThreadPool(1, springThreadFactory);
@Autowired
private CanalInstanceProperties canalInstanceProperties;
@Resource
private StringRedisTemplate stringRedisTemplate;
@PostConstruct
private void startListening() {
canalInstanceProperties.getInstance().forEach(
instanceName -> {
executors.submit(() -> {
connector(instanceName);
});
}
);
}
/**
* 消费canal的线程池
*/
public void connector(String instance){
CanalConnector canalConnector = CanalConnectors.newSingleConnector(
new InetSocketAddress(canalInstanceProperties.getServerAddress(), canalInstanceProperties.getServerPort()),
instance, "", "");
canalConnector.connect();
//订阅所有消息
canalConnector.subscribe(".*\\..*");
// canalConnector.subscribe("test1.*"); 只订阅test1数据库下的所有表
//恢复到之前同步的那个位置
canalConnector.rollback();
for(;;){
//获取指定数量的数据,但是不做确认标记,下一次取还会取到这些信息。 注:不会阻塞,若不够100,则有多少返回多少
Message message = canalConnector.getWithoutAck(100);
//获取消息id
long batchId = message.getId();
int size = message.getEntries().size();
if (size == 0 || batchId == -1) {
try{
Thread.sleep(1000);
} catch (InterruptedException ignored) {
}
}
if(batchId != -1){
log.info("instance -> {}, msgId -> {}", instance, batchId);
printEnity(message.getEntries());
//提交确认
canalConnector.ack(batchId);
//处理失败,回滚数据
//canalConnector.rollback(batchId);
}
}
}
private void printEnity(List<CanalEntry.Entry> entries) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChange = null;
try{
// 序列化数据
rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
assert rowChange != null;
CanalEntry.EventType eventType = rowChange.getEventType();
log.info(String.format("================>; binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
if (rowChange.getEventType() == CanalEntry.EventType.QUERY || rowChange.getIsDdl()) {
log.info("sql ------------>{}" ,rowChange.getSql());
}
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
switch (rowChange.getEventType()){
//如果希望监听多种事件,可以手动增加case
case UPDATE:
printColumn(rowData.getAfterColumnsList());
printColumn(rowData.getBeforeColumnsList());
handleRedisCache(entry.getHeader().getTableName(), rowData.getAfterColumnsList());
break;
case INSERT:
printColumn(rowData.getAfterColumnsList());
handleRedisCache(entry.getHeader().getTableName(), rowData.getAfterColumnsList());
break;
case DELETE:
printColumn(rowData.getBeforeColumnsList());
handleRedisCache(entry.getHeader().getTableName(), rowData.getAfterColumnsList());
break;
default:
}
}
}
}
private void printColumn(List<CanalEntry.Column> columns) {
StringBuilder sb = new StringBuilder();
for (CanalEntry.Column column : columns) {
sb.append("[");
sb.append(column.getName()).append(":").append(column.getValue()).append(",update=").append(column.getUpdated());
sb.append("]");
sb.append(" ");
}
log.info(sb.toString());
}
private void handleRedisCache(String tableName, List<CanalEntry.Column> columns) {
// 分库分表,需要抽取表前缀
RedisKeyDefine redisKeyDefine = RedisKeyRegistry.getDefines().get(tableName.substring(0,tableName.length()-2));
if (redisKeyDefine != null) {
List<String> keyColumns = new ArrayList<>();
for (CanalEntry.Column column : columns) {
if (redisKeyDefine.getTableColumnList().contains(column.getName())) {
keyColumns.add(column.getValue());
}
}
String key = String.format(redisKeyDefine.getKeyTemplate(), keyColumns.toArray());
log.info("delete cache, key is {}", key);
stringRedisTemplate.delete(key);
}
}
}
总结
利用canal+mq的解决业务上缓存不一致的方案,对于一些常用场景、跨多系统还是很方便的,吞吐量和延时性指标均不错,适用于高并发项目。并且能够做一次统一的缓存控制,有利于整理系统内无效代码,提高代码精简度。同时,缓存一致性方便基本不能够达到强一致,在考虑时需要将实际业务代入,思考一个全面的方案。