ICCV 2023 | 腾讯优图实验室16篇论文入选,含掌纹生成,人脸隐私保护,图像和谐化等研究方向...
关注公众号,发现CV技术之美
本文转自腾讯优图实验室。
作为全球计算机领域顶级的学术会议之一,ICCV2023(International Conference on Computer Vision)国际计算机视觉大会将于今年10月在法国巴黎举行。近日,ICCV公布了论文录用结果,本届会议共有8068篇投稿,接收率为26.8%。
今年, 腾讯优图实验室共有16篇论文入选,研究方向含轻量化模型结构设计、文档理解、深度伪造溯源、掌纹生成、人脸隐私保护、无监督异常检测、图像和谐化、小样本扩散模型领域自适应、增量识别、3D形状生成 等研究方向。
以下为腾讯优图实验室入选论文概览:
01重新思考基于注意力机制的高效模型中的移动模块设计
Rethinking Mobile Block for Efficient Attention-based Models
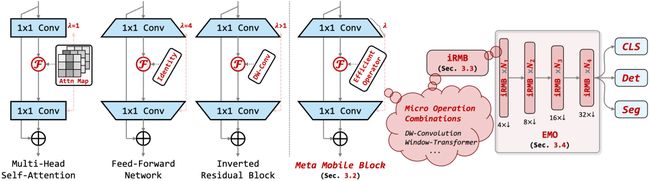
本文专注于开发现代化、高效且轻量级的模型以用于密集预测,同时在参数量、计算量和性能之间进行权衡。轻量级CNN模型有倒残差模块(Inverted Residual Block,IRB)作为基础结构,但基于注意力的对应基础模块研究尚未得到认可。
本文从统一的角度重新思考了高效的IRB模块和Transformer中的有效组件,将基于CNN的IRB扩展到基于注意力的模型,并抽象出一个残差元移动块(Meta Mobile Block,MMB)用于轻量级模型设计。遵循简单但有效的设计准则,我们推导出一个现代的倒残差移动模块(Inverted Residual Mobile Block,iRMB),并仅使用iRMB构建一个类似ResNet的高效模型(EMO)用于下游任务。在ImageNet-1K、COCO2017和ADE20K基准测试上的大量实验证明了提出方法的优越性。例如,EMO-1M/2M/5M在ImageNet-1K上达到了71.5、75.1和78.4的Top-1,超过了同时代基于CNN/Attention的模型,同时在参数、效率和准确性上得到了良好的权衡。
论文下载地址:https://arxiv.org/pdf/2301.01146.pdf
02一种选择性区域关注的端到端文档理解模型
Attention Where It Matters: Rethinking Visual Document Understandingwith Selective Region Concentration
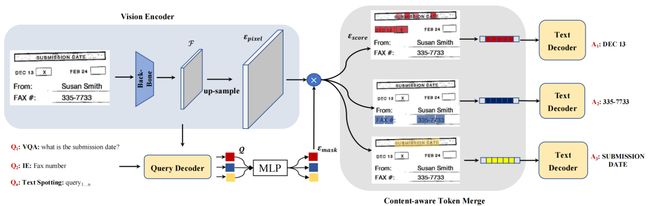
本文提出了一种新颖的端到端文档理解模型SeRum,用于从文档图像中提取有价值的关键信息,可用于文档分析、检索和办公自动化等场景。不同于常规的多阶段技术方案,SeRum将文档图像理解和图像文字识别任务统一转换为对感兴趣区域视觉Token集合的局部解码过程,并提出内容感知的Token-Merge模块。
这种机制使模型能够更加关注由查询解码器生成的感兴趣区域,提高了模型识别的准确性,并加快生成模型的解码速度。文章中还设计了多个针对性的预训练任务,以增强模型对图片内容理解和区域感知能力。实验结果表明,SeRum在文档理解任务上实现了sota性能,并在文本识别任务上取得了有竞争力的结果。
03从粗到细:一种学习紧凑型判别表征的单阶段图像检索
Coarse-to-Fine: Learning Compact Discriminative Representation for Single-Stage Image Retrieval
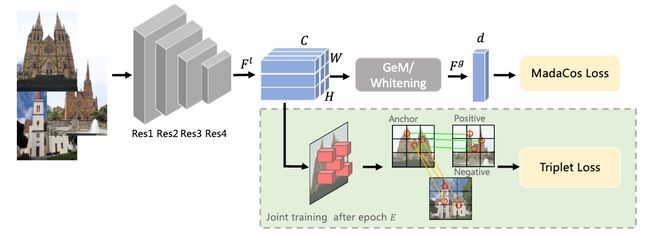
图像检索是从数据库中找到与查询图像视觉相似的图像,基于检索-排序范式的两阶段方法取得了优越的性能,但其需要额外的局部和全局模块,在实际应用中效率低下。为了更好地权衡检索效率和准确性,现有的方法将全局和局部特征融合为一个联合表征以执行单阶段图像检索。然而,受到复杂的环境影响如背景、遮挡和视角等,这些方法仍具有挑战性。
在这项工作中,我们设计了一个由粗到细的框架CFCD来学习紧凑的特征,用于端到端的单阶段图像检索--只需要图像级标签。本文首先设计了一种新颖的自适应损失函数,可在每个小批量样本内动态调整其特征的尺度和角度,通过由小到大逐步增加来加强训练过程中的监督和类内紧凑性。此外,我们还提出了一种对比学习机制,通过困难负采样策略以及选择突出的局部描述符来将细粒度语义关系注入全局表示,从而优化全局范围内的类间显著性。广泛的实验结果证明了我们方法的有效性,我们的方法在 Revisited Oxford 和 Revisited Oxford 等基准测试中实现了最先进的单阶段图像检索性能。
0D3G:基于单帧标注探索高斯先验用于视频片段定位
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with GlanceAnnotation
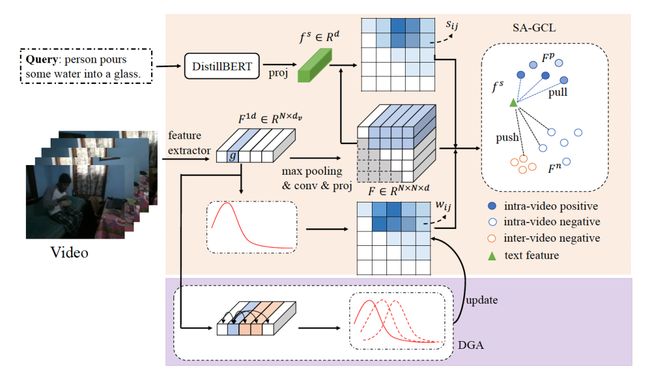
基于文本的视频片段定位任务(Temporal sentence grounding, TSG)旨在给定自然语言查询从未经过修剪的视频中定位出对应的特定片段。最近,弱监督方法与全监督方法相比仍有较大性能差距,而后者需要费力的时间戳标注。在本研究,我们致力于减少TSG任务的标注成本并与全监督方法相比仍保持具有竞争力的性能。为了实现这个目标,我们研究了最近提出的基于单帧标注的TSG任务,其对于每个文本查询,只需要对应的单帧标注信息。
在此设定下,我们提出了基于单帧标注和动态高斯先验的视频片段定位框架(D3G),其主要由语义对齐组对比学习模块 (SA-GCL) 和动态高斯先验调整模块(DGA)组成。具体来说,SA-GCL模块通过联合利用高斯先验和语义一致性从2D时序图中采样可靠的正样本片段,这有助于对齐文本-视频片段对在联合嵌入空间的表征。此外,为了缓解由单帧标注带来的标注偏置问题并有效建模由多个事件组成的复杂文本查询,我们进一步提出了DGA模块,其主要负责动态调整高斯先验分布来逼近真实目标片段。我们在三个具有挑战性的基准上广泛的实验验证所提出的D3G的有效性。D3G的性能明显优于最先进的弱监督方法并缩小与完全监督的方法相比的性能差距。
05基于对比式伪标签学习的开放场景深伪溯源方法
Contrastive Pseudo Learning for Open-world Deepfake Attribution
*本文由腾讯优图实验室、上海交通学共同完成
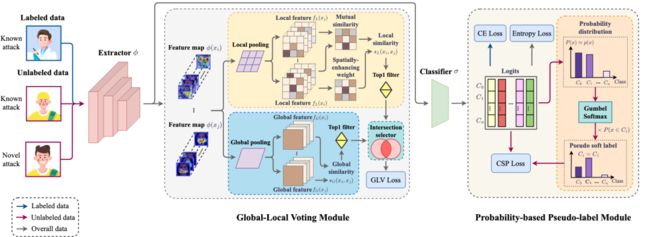
随着生成技术的快速发展,对于深度伪造人脸的攻击类型溯源问题已经引起了广泛关注。现有的诸多研究在GAN溯源任务上有了一些进展,但忽略了更具威胁性的人脸替换或表情驱动等攻击类型。此外,开放场景下存在着大量没有攻击类型标注的伪造人脸数据,这部分数据也尚未被充分利用起来。为了应对这些挑战,本文构建了一个名为“开放场景下深度伪造溯源”(OpenWorld-DeepFake Attribution,OW-DFA)的新基准,涵盖了人脸替换、表情驱动、属性编辑、人脸替换等20多种主流伪造技术,以评估开放场景下不同伪造人脸类型的溯源性能。
同时,本文针对OW-DFA任务提出了一个对比式伪标签学习(Contrastive Pseudo Learning,CPL)算法,包括以下两个部分:1)引入全局-局部投票模块,以修正不同攻击类型产生的伪造区域大小差异;2)设计基于概率的伪标签策略,以缓解在利用无标签数据时相似攻击方法所引起的噪声。此外,本文还将CPL算法进一步与目前广泛使用的预训练和迭代学习技术结合在一起,进一步提高了溯源性能。本文通过大量的实验证明了所提出的CPL方法在OW-DFA基准测试上的优越性,有效促进了深度伪造溯源任务的可解释性和安全性,并对深度伪造检测领域有着积极影响。
06面向掌纹识别的拟真掌纹生成
RPG-Palm: Realistic Pseudo-data Generation for Palmprint Recognition
*本文由腾讯优图实验室、腾讯微信支付33号实验室、合肥工业大学共同完成
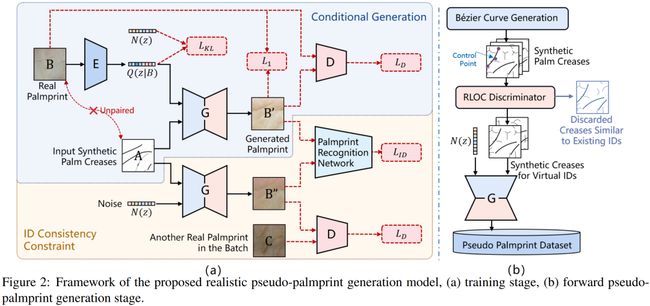
掌纹作为一种稳定且隐私友好的生物特征识别技术,最近在识别应用中显示出巨大的潜力。然而,大规模公开掌纹数据集的缺乏限制了掌纹识别技术的进一步研究和发展。在本文中,我们提出了一种ID可控的拟真掌纹生成模型。第一,我们引入条件调制模块来提高类内多样性;第二,提出身份感知损失,以确保不配对训练下生成样本的身份一致性。
同时, 我们进一步改进了Bezier掌纹线生成策略以保证身份间可区分性。大量的实验结果表明,使用生成掌纹数据预训练可以显着提高识别模型的性能。例如,我们的模型在训练/测试 1:1 和 1:3设定下,相较最先进的 BezierPalm通过率提高了 5% 和 14% @FAR=1e-6。当仅使用 10% 的真实数据训练时,我们的方法仍优于基于ArcFace使用100% 真实数据训练的模型,这表明我们的方法向无需使用真实数据进行模型训练的掌纹识别更进了一步。
论文下载地址:https://github.com/RayshenSL/RPG-PALM
07PartialFace:基于随机频率分量的人脸识别隐私保护方法
Privacy-Preserving Face Recognition Using Random Frequency Components
*本文由腾讯优图实验室、复旦大学共同完成
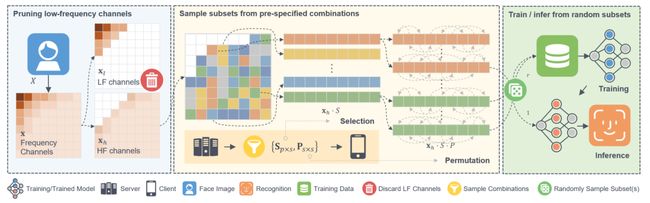
本文对隐藏人脸图像视觉特征和改善抗重建攻击能力进行了探讨,并提出一种可提供训练、推理阶段隐私保护的人脸识别方法PartialFace。本文首先利用人类和模型对不同频域分量的感知差异,通过修剪肉眼可感知的低频分量隐藏图像视觉信息。其次,本文注意到同类方法的隐私保护缺陷,即识别模型精度依赖较大规模的高频分量,而这些分量搭载的冗余信息可能使模型暴露于重建攻击。
为应对这一问题,本文观察到模型注意力在不同频域分量上存在差异,提出在随机选择的分量组合上训练模型,使模型建立从局部频域信息到整体人脸信息的映射。从而,本文在维持识别精度的同时,将所需高频分量规模降低到同类方法的1/6,提高了隐私保护性能。经广泛实验验证,本文所提方法可提供显著优于当前先进方法的抗重建能力,同时保持有竞争力的任务性能。
08记住正常性:记忆力机制扩充的知识蒸馏无监督异常检测
Remembering Normality: Memory-guided Knowledge Distillation for Unsupervised Anomaly Detection
*本文由腾讯优图实验室、上海交通大学共同完成
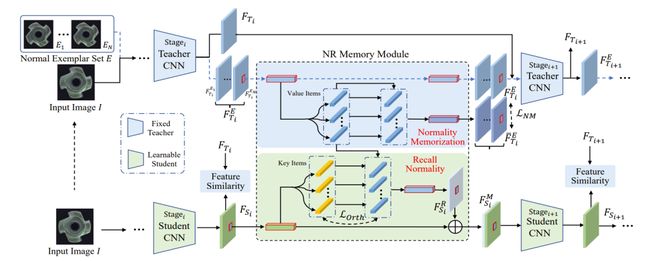
本文提出了一种新的无监督异常检测方法,称为Memory-guided Knowledge Distillation (MemKD)。传统基于知识蒸馏的异常检测方法在学习过程中会出现“正常性遗忘”问题,即在仅使用正常数据训练前提下,学生模型却会重构异常特征,且对正常数据中包含的纹理细节很敏感。
为了解决这个问题,MemKD引入了一种新的记忆机制,即正常知识召回模块 (NRM),通过存储正常数据的信息来加强学生模型生成的特征的正常性。同时,MemKD还采用了正常性表示学习策略,构建了一个正常样本集,使NRM能够记忆无异常数据的先验知识,并在后续的查询中进行回忆。实验结果表明,MemKD在MVTec AD、VisA、MPDD、MVTec 3D-AD和Eyecandies等五个数据集上取得了良好的效果。
09学习全局感知核的图像和谐化
Learning Global-aware Kernel for Image Harmonization
*本文由腾讯优图实验室、浙江大学共同完成
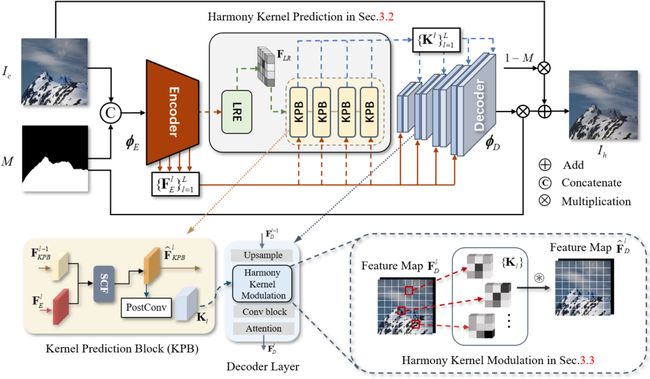
图像和谐化旨在通过以背景为参考自适应调整前景色彩来解决合成图像中的视觉不连续问题。现有方法采用前景和背景之间的局部颜色变换或区域匹配策略,忽略邻近先验并将前景/背景独立区分以实现和谐化。由此在多样化的前景物体和复杂场景中仍然表现有限性能。为解决这个问题,我们提出了一种新颖的全局感知内核网络(GKNet)实现综合考虑远距离背景信息的局部区域和谐化。
具体来说,GKNet包括和谐化核预测和和谐化调制两部分。前者包括用于获取长距离参考提取器(LRE)和用于融合全局信息与局部特征的多层级和谐化核预测模块(KPB);为了实现更好地选择相关的长距离背景参考以进行局部和谐化这一目标,我们在其中还提出了一种新颖的选择性相关融合(SCF)模块。后者利用预测得到的和谐化核进行前景区域和谐化。大量实验证明了我们的图像和谐化方法相对于最先进方法的优越性,例如,实现了 39.53dB PSNR,比相关最佳方法提升+0.78dB;并与 SoTA 方法相比,fMSE/MSE 降低了 11.5%和6.7%。
论文下载地址:https://arxiv.org/pdf/2305.11676.pdf
10基于分段内容融合与有向分布一致性的小样本扩散模型领域自适应
Phasic Content Fusing Diffusion Model with Directional Distribution Consistency for Few-Shot Model Adaption
*本文由腾讯优图实验室、上海交通大学共同完成
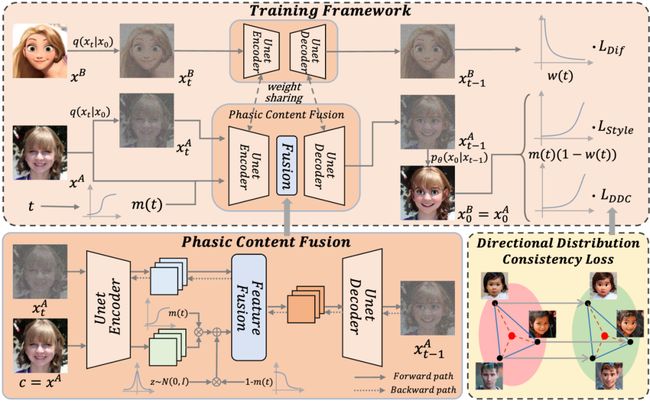
在有限样本下训练生成模型是一项具有挑战性的任务,现有的方法主要利用小样本模型领域自适应来训练网络。然而,在数据极度稀缺的场景下(少于10个样本),生成模型很容易出现过拟合与内容退化的现象。
为了解决这些问题,我们提出了一种新颖的基于分段内容融合的小样本扩散模型,并提出有向分布一致性损失,使得扩散模型在不同训练阶段学习到不同的目标域信息。具体而言,我们设计了一种分段训练策略,通过分段的内容融合帮助模型在加噪步数较大时保持源域的内容并学习目标域的风格信息,在加噪步数较小时学习目标域的局部细节信息,从而提高模型对内容、风格和局部细节的把控能力。
此外,我们引入了一种新的有向分布一致性损失,能够高效、稳定地保证生成域分布和源域分布的一致性,避免模型过拟合。最后,我们还提出了一种跨域结构引导策略,在域适应过程中增强生成图像与原图像结构的一致性。我们从理论分析、定性和定量的实验三个方面,有效地证明了所提出方法相较于以往小样本模型自适应方法的优越性。
11基于实例及类别监督交替学习的增量识别
Instance and Category Supervision are Alternate Learners for Continual Learning
*本文由腾讯优图实验室、华东师范大学共同完成
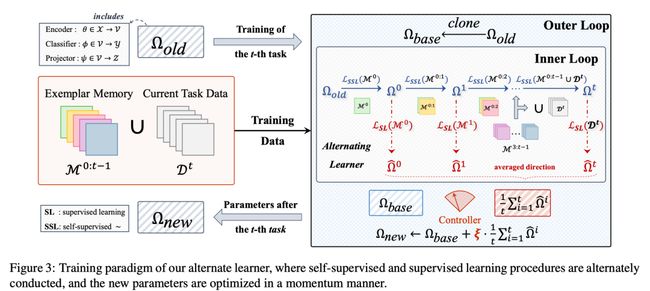
持续学习CL(增量学习)是在先前习得的基础上不断发展复杂行为技能。然而,当前的CL算法往往会导致类级遗忘,因为标签信息经常被新知识快速覆盖。这促使人们试图通过最近的自我监督学习(SSL)技术来挖掘实例级别的歧视。然而,先前的工作指出,自监督学习目标本质上是在对失真的不变性和保留样本信息之间的权衡,这严重阻碍了效果提升,我们从信息论的角度重新表述了SSL,通过解开实例级区分的目标,并解决了这种权衡,以促进对失真具有最大程度不变的紧凑表示。
在此基础上,我们开发了一种新的交替学习范式,以享受实例级和类别级监督的互补优势,从而提高了对遗忘的鲁棒性,并更好地适应每项任务。为了验证所提出的方法,我们使用类增量和任务增量设置在四个不同的基准上进行了广泛的实验,其中性能的飞跃和彻底的消融研究证明了我们建模策略的有效性和效率。
12基于改进自回归模型的多样3D形状生成模型
Learning Versatile 3D Shape Generation with Improved AR Models
*本文由腾讯优图实验室、清华大学、复旦大学共同完成
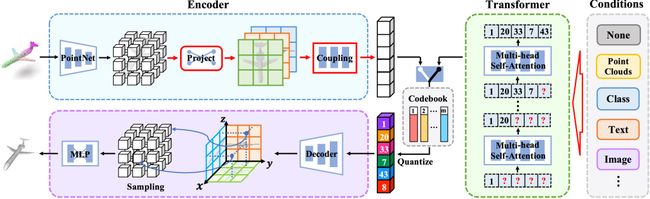
我自回归(Auto-Regressive,AR)模型通过对网格空间中的联合分布进行建模,在2D图像生成方面取得了令人瞩目的成果。虽然这种方法已经扩展到3D领域以实现强大的形状生成,但仍存在两个限制:在体积网格上进行昂贵的计算和网格维度上的模糊自回归顺序。
为了克服这些限制,我们提出了改进的自回归模型(Improved Auto-regressive Model,ImAM)用于3D形状生成,该模型应用基于潜在向量的离散表示学习,而不是使用体积网格。我们的方法不仅降低了计算成本,还通过在更易处理的顺序中学习联合分布来保留基本的几何细节。此外,由于我们模型架构的简单性,我们可以通过连接各种条件输入(如点云、类别、图像和文本)将其自然地从无条件生成扩展为条件生成。大量实验证明,ImAM能够合成多个类别的多样化且真实的形状,并达到了最先进的性能水平。
论文下载地址:https://arxiv.org/pdf/2303.14700.pdf
13用于弱监督目标定位的类别感知分配变换器
Category-aware Allocation Transformer for Weakly Supervised Object Localization
*本文由腾讯优图实验室、厦门大学共同完成
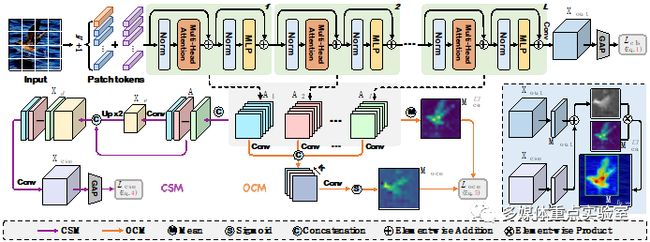
弱监督目标定位(WSOL)旨在实现,仅给定图像级标签的前提下学习一个目标定位器。最近,基于自注意力机制和多层感知器结构的变换神经网络(Transformer)因其可以捕获长距离特征依赖而在WSOL中崭露头角。美中不足的是,基于Transformer的方法使用类别不可知的注意力图来预测边界框,从而容易导致混乱和嘈杂的目标定位。
本文提出了一个基于Transformer的新颖框架——CATR(类别感知Transformer),该框架在Transformer中学习特定目标的类别感知表示,并为目标定位生成相应的类别感知注意力映射。具体来说,本文提出了一个类别感知模块来引导自注意力特征图学习类别偏差,并且提供类别监督信息来指导其学习更有效的特征表示。此外,本文还设计了一个目标约束模块,以自我监督的方式细化类别感知注意力图的目标区域。最后,在两大公开数据集CUB-200-2011和ILSVRC上进行了充分的实验,验证了本文方法的有效性。
14SLAN: 用于视觉语言理解的自定位辅助网络
SLAN: Self-Locator Aided Network for Vision-language Understanding
*本文由腾讯优图实验室、南开大学共同完成
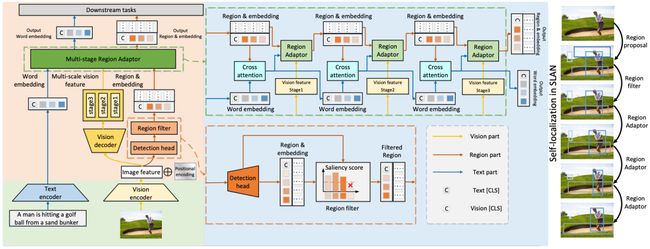
学习视觉和语言之间的细粒度交互有助于模型更准确地理解视觉语言任务。然而,根据文本提取关键图像区域进行语义对齐仍然具有挑战性。大多数现有工作要么使用冻结检测器获得冗余区的目标区域,且提取到的目标区域大多与文本的语义信息无关,要么由于严重依赖标注数据来预训练检测器而无法进一步扩展。
为了解决这些问题,我们提出了自定位辅助网络(SLAN),用于视觉语言理解任务,无需任何额外的目标数据。SLAN 由区域过滤器和区域适配器组成,用于根据不同文本定位感兴趣的区域。通过聚合视觉语言信息,区域过滤器选择关键区域,区域适配器通过文本指导更新其坐标。通过细粒度的区域-文本对齐,SLAN 可以轻松推广到许多下游任务。它在五个视觉语言理解任务上取得了相当有竞争力的结果(例如,在 COCO 图像到文本和文本到图像检索上分别为 85.7% 和 69.2%,超越了之前的 SOTA 方法)。SLAM 还展示了对两个目标定位任务的强大的零样本和微调可迁移性。
15掩码自编码器是高效的类增量学习器
Masked Autoencoders are Efficient Class Incremental Learners
*本文由腾讯优图实验室、南开大学共同完成
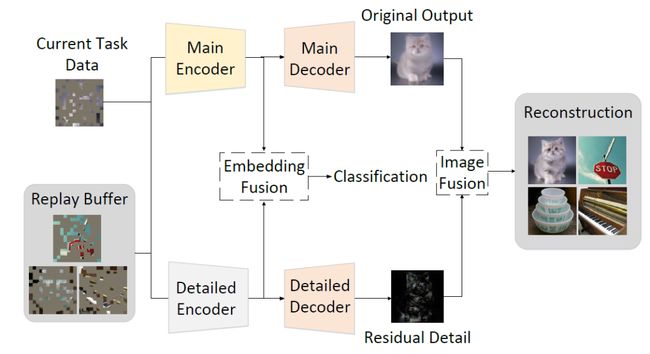
类增量学习(CIL)旨在顺序学习新类别,同时避免对之前知识的灾难性遗忘。在本研究中,我们提出使用掩码自编码器(MAEs)作为CIL的高效学习器。MAEs最初是为了通过重构无监督学习来学习有用的表示,它们可以很容易地与监督损失集成以进行分类。此外,MAEs可以可靠地从随机选择的补丁中重建原始输入图像,我们利用这一点更有效地存储过去任务的样本以供CIL使用。我们还提出了双边MAE框架,以从图像级别和嵌入级别融合中学习,从而产生更好的重建图像和更稳定的表示。我们的实验证实,与CIFAR-100、ImageNet-Subset和ImageNet-Full的最新技术相比,我们的方法实现了更优越的性能。
16SMMix:视觉 Transformer 的自驱动图像混合
SMMix: Self-Motivated Image Mixing for Vision Transformers
*本文由腾讯优图实验室、南开大学共同完成
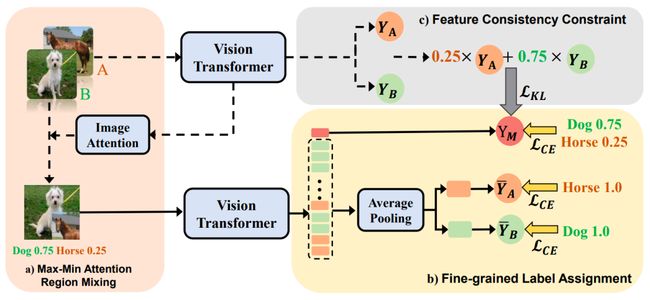
CutMix 是一种重要的增强策略,决定了视觉变换器 (ViT) 的性能和泛化能力。然而,混合图像与相应标签之间的不一致损害了其效果。现有的 CutMix 变体通过生成更一致的混合图像或更精确的混合标签来解决这个问题,但不可避免地会带来繁重的训练开销或需要额外的信息,从而破坏了易用性。为此,我们提出了一种新颖且有效的自激励图像混合方法(SMMix),该方法通过训练本身的模型来激励图像和标签增强。具体来说,我们提出了一种最大-最小注意力区域混合方法,该方法丰富了混合图像中的注意力集中对象。然后,我们引入了一种细粒度的标签分配技术,该技术通过细粒度的监督来共同训练混合图像的输出标记。此外,我们设计了一种新颖的特征一致性约束来对齐混合和非混合图像的特征。由于自我激励范例的微妙设计,我们的 SMMix 的显着特点是比其他 CutMix 变体具有更小的训练开销和更好的性能。特别是,SMMix 在 ImageNet-1k 上将 DeiT-T/S/B、CaiT-XXS-24/36 和 PVT-T/S/M/L 的准确率提高了 +1% 以上。我们的方法的泛化能力也在下游任务和分布外数据集上得到了证明。
论文链接:https://arxiv.org/abs/2212.12977
更多 ICCV 2023 论文持续更新在:https://github.com/52CV/ICCV-2023-Papers

END
欢迎加入「ICCV」交流群备注:ICCV
