java八股文面试[数据库]——自适应哈希索引
自适应Hash索引(Adatptive Hash Index,内部简称AHI)是InnoDB的三大特性之一,还有两个是 Buffer Pool简称BP、双写缓冲区(Doublewrite Buffer)。
1、自适应即我们不需要自己处理,当InnoDB引擎根据查询统计发现某一查询满足hash索引的数据结构特点,就会给其建立一个hash索引;
2、hash索引底层的数据结构是散列表(Hash表),其数据特点就是比较适合在内存中使用,自适应Hash索引存在于InnoDB架构中的缓存中(不存在于磁盘架构中),见下面的InnoDB架构图。
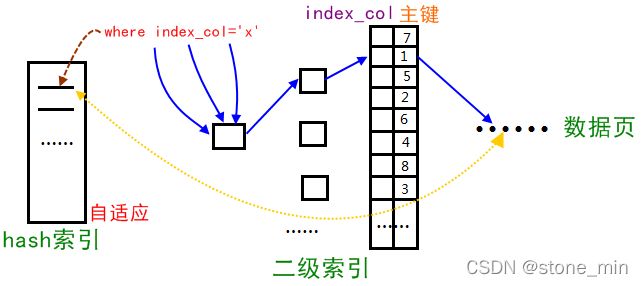
3、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
![java八股文面试[数据库]——自适应哈希索引_第1张图片](http://img.e-com-net.com/image/info8/845bd661cef14e49989b73bdd1d67f3e.jpg)
Adaptive Hash Index是针对B+树Search Path的优化,因此所有会涉及到Search Path的操作,均可使用此Hash索引进行优化.
![java八股文面试[数据库]——自适应哈希索引_第2张图片](http://img.e-com-net.com/image/info8/7d98cb26644740bc9d9a22807448f35e.jpg)
根据索引键值(前缀)快速定位到叶子节点满足条件记录的Offset,减少了B+树Search Path的代价,将B+树从Root节点至Leaf节点的路径定位,优化为Hash Index的快速查询。
InnoDB的自适应Hash索引是默认开启的,可以通过配置下面的参数设置进行关闭。
innodb_adaptive_hash_index = off
自适应Hash索引使用分片进行实现的,分片数可以使用配置参数设置:
innodb_adaptive_hash_index_parts = 8
索引的资源消耗分析
1、索引三大特点
小:只在一个到多个列建立索引
有序:可以快速定位终点
有棵树:可以定位起点,树高一般小于等于3
2、索引的资源消耗点
树的高度,顺序访问索引的数据页,索引就是在列上建立的,数据量非常小,在内存中;
数据之间跳着访问
索引往表上跳,可能需要访问表的数据页很多;
通过索引访问表,主键列和索引的有序度出现严重的不一致时,可能就会产生大量物理读;
资源消耗最厉害:通过索引访问多行,需要从表中取多行数据,如果无序的话,来回跳着找,跳着访问,物理读会很严重。
自适应hash索引原理
1、原理过程
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升
经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
特点
1、无序,没有树高
2、降低对二级索引树的频繁访问资源
索引树高<=4,访问索引:访问树、根节点、叶子节点
3、自适应
缺陷
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询 例如=, <=>,in,如 select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读。
4、无法用于排序
5、有冲突可能
6、MySQL自动管理,人为无法干预。
自适应hash索引原理
InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立自适应哈希索引,实现本质上就是一个哈希表:从某个检索条件到某个数据页的哈希表。
索引使用大于17次
AHI是为某个索引树建立的(当该索引树层数过多时,AHI才能发挥效用)。如果某索引只被使用一两次,就为之建立AHI,会导致AHI太多,维护成本高于收益。当某一索引使用次数大于17次时,即通过筛选。
hash info使用次数大于100
对使用次数大于17次的索引建立hash info,hash info是用来描述一次检索的条件与索引匹配程度。建立AHI时,就可以根据匹配程度,抽取数据中匹配的部分,作为AHI的键。当hash info使用次数大于100代表该hash info为经常使用的hash info。
hash info结构:匹配索引列数,下一列匹配字节数,是否从左匹配。
hash info命中页数据大于1/16
果我们为表中所有数据建立AHI,那AHI就失去了缓存的意义,所以要找出该索引树上经常使用的数据页,通过该步骤筛选后就可以开始建立hash 索引。
知识来源:马士兵教育
【MySQL】Innodb三大特性之(自适应hash索引)_提供自适应hash 索引_redstone618的博客-CSDN博客
Adaptive Hash Index(自适应hash索引)_自适应哈希索引__梓杰_的博客-CSDN博客