Python基础
一、hello world
python文件:文件名.py
运行方式:windows中可以直接在cmd中运行命令:python 文件名.py
例子:helloworld.py
print("helloo owrd")运行结果:

运行发生了什么:运行文件helloworld.py时,末尾的.py指出这是一个Python程序,因此编辑器将使用Python解释器 来运行它。Python解释器读取整个程序,确定其中每个单词的含义。例如,看到单词print 时,解释器就会将括号中的内容打印到屏幕,而不会管括号中的内容是什么。
二、变量和简单数据类型
1、变量
命名规则:
a、变量名只能包含字母、数字和下划线。变量名可以字母或下划线打头。
b、变量名不能包含空格。
c、不能将python中的关键字或函数名用作变量名。
d、变量名应简短又具有描述性。
e、慎用小写字母l和大写字母O,因为它们可能被人错看成数字1和0。
#变量 变量名称:msg;变量值:变量
msg="变量"
print(msg)
2、字符串
概念
在python中用引号括起来的就是字符串。其中包括双引号和单引号。
单双引号都可以嵌套使用
# 此时a的值为:11‘’1
a="11''1"
#此时b的值为:11""2
b='11""2'拼接字符串
字符串a+字符串b=最终拼接的字符串
# 此时a的值为:11‘’1
a="11''1"
#此时b的值为:11""2
b='11""2'
#打印:11''111""2
print(a+b)特殊字符
\t:制表符
\n:换行符
删除空格函数
c=" ab cd "
#去除字符串前后空格
print(c.strip())
#去除字符串后空格
print(c.rstrip())
#去除字符串前空格
print(c.lstrip())3、数字
整数
在python中,可对整数执行 加(+)、减(-)、乘(*)、除(/) 运算
Python使用两个乘号表示乘方运算
Python还支持运算次序,因此你可在同一个表达式中使用多种运算。你还可以使用括号来修改运算次序,让Python按你指定的次序执行运算
d=2+2
e=2-2
f=2*2
g=2/2
h=2**2
print(d)
print(e)
print(f)
print(g)
print(h)

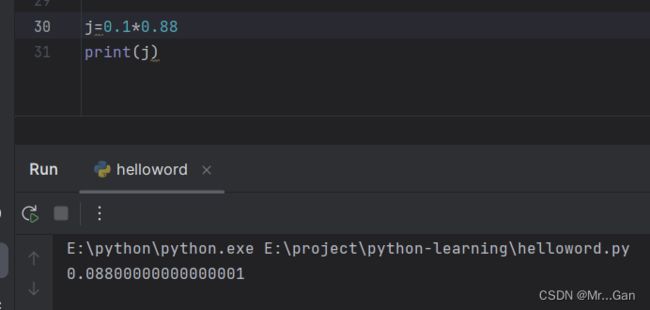
浮点数
Python将带小数点的数字都称为浮点数。
与整数一样都可以进行算术运算
但是浮点数的小数位数可能不确定
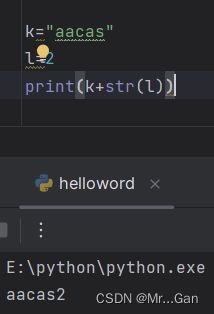
类型转换str()
例子:当使用字符串拼接时,如果字符串拼接中包含数字类型的数据会报错,此时需要使用str()这个函数来将数字转为字符串类型。

三、列表
1、概念
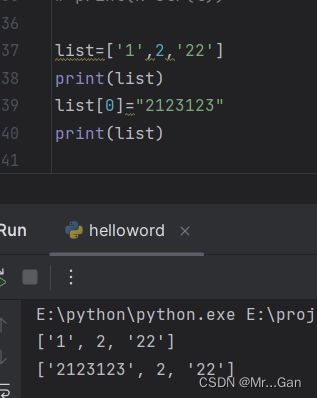
列表 由一系列按特定顺序排列的元素组成。在Python中,用方括号([] )来表示列表,并用逗号来分隔其中的元素。列表是有序集合,因此要访问列表的任何元素,只需将该元素的位置或索引告诉Python即可。
注意索引是从0开始。
list=['1',2,'22']
#打印1
print(list[0])2、修改、添加、删除元素
修改
修改列表元素的语法与访问列表元素的语法类似。要修改列表元素,可指定列表名和要修改的元素的索引,再指定该元素的新值。
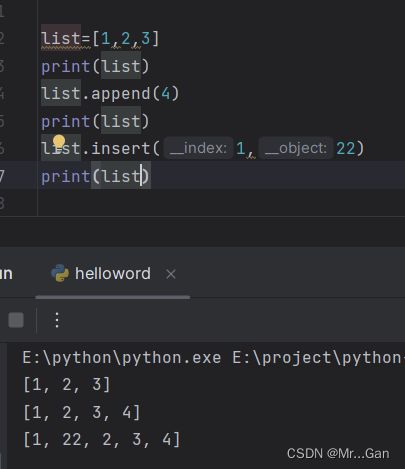
添加元素
在末尾添加:列表.append("元素")
在固定位置添加:列表.insert(下标,"元素")
删除元素
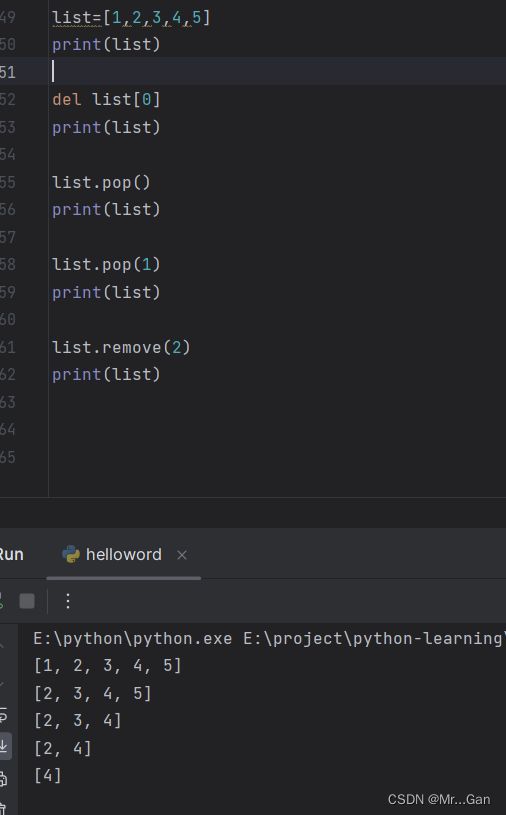
根据下标删除:del 列表[下标]
删除最后一个(不带参数)或指定下标(带参数(下标)),并且返回删除的元素:列表.pop()
根据值删除:列表.remove("值")
3、组织列表
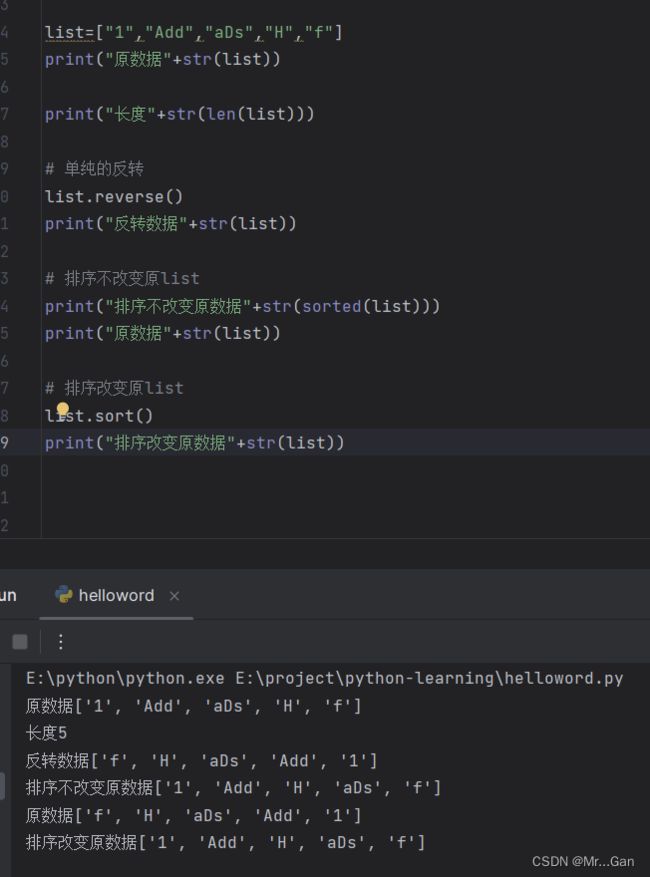
sort():此方法会永久修改列表中元素的顺序,按照字母进行排序。
参数(可无):reverse=True,表示顺序为反的
排序顺序:数字>大写字母>小写字母
sorted():此方法与sort作用一致,但是不会永久更改list中的顺序。
reverse():此方法会反转列表中的元素,不会进行排序,只是单纯的反转
len():此方法获得列表中的长度。
四、操作列表
1、遍历
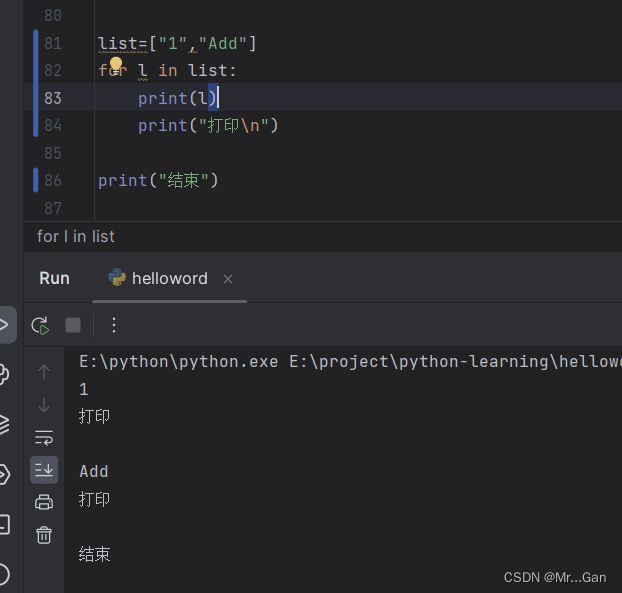
在python中遍历会使用for循环,
语法格式:for 每次循环的值 in 总值 :
缩进 执行的语句
不缩进,结束语句
注意:for循环以不缩进的语句结束
2、数值列表
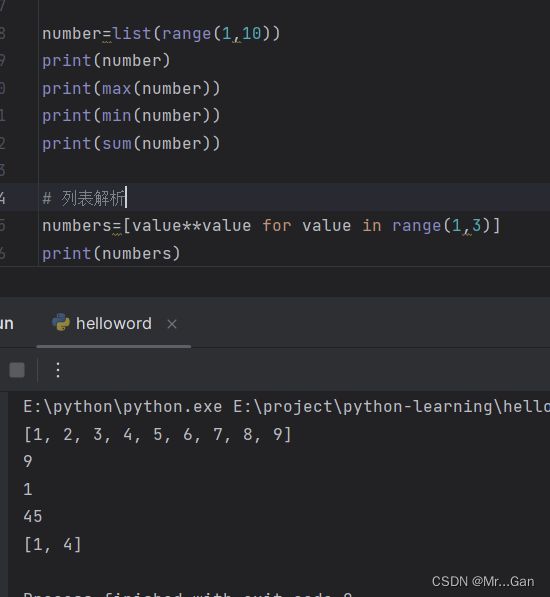
range(参数1,参数2):生成从参数1到参数2之间的数值,不包含参数2。
range可以直接赋值给列表:number=list(range(1,3))
max(列表):获取列表中最大值
min(列表):获取列表最小值
sum(列表):列表所有值之和。
列表解析:一种写法,在下列实例中的意思,去取值1、2,把他们的乘方转为列表
3、使用列表的一部分
切片
与range函数类似,在列表后跟数字来访问列表中的一部分数据。
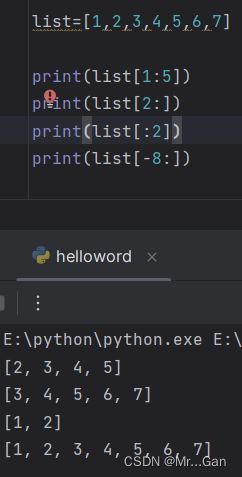
列表[2:4]:访问列表下标为2、3的元素
列表[:3]:访问列表下标0~2的元素
列表[2:]:访问列表下标2到最后的所有元素
列表[-2:]:访问列表最后2个元素。参数如果超过列表元素个数则打印所有元素。
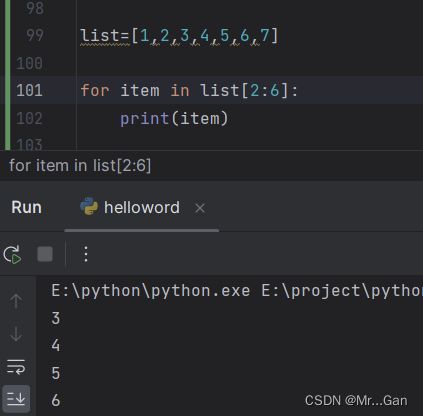
遍历切片
针对切片可以使用for循环,遍历所有元素。
for item in list[1:3]
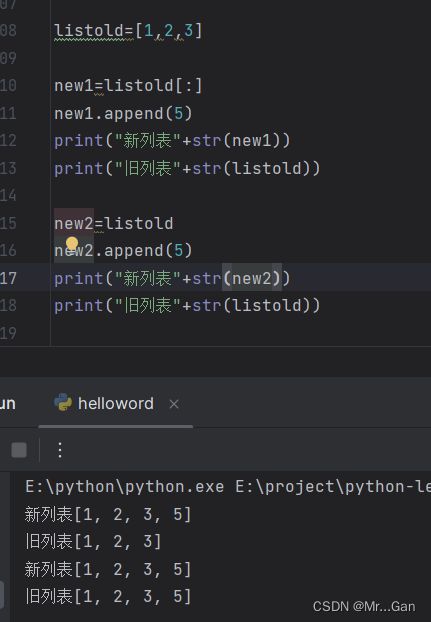
复制列表
完全复制:新列表=老列表[:],新列表与老列表是两个独立的数据。
地址复制:新列表=老列表,新列表与老列表是同一个数据。
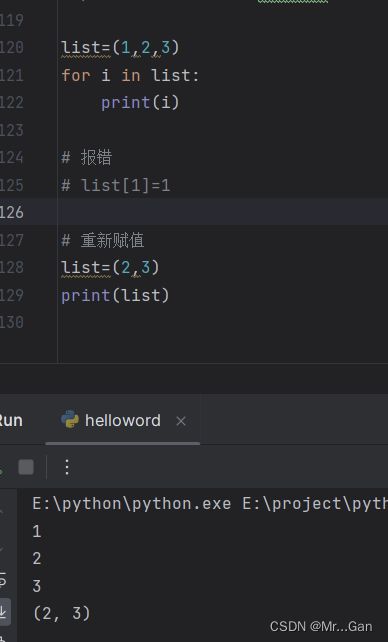
4、元组
元组:不可变的列表
定义:与列表一样,只是吧方括号改为圆括号。元组=(值1,值2)
修改:不能根据下标修改单独的值,只能进行重新赋值
五、if
1、概念
每条if 语句的核心都是一个值为True 或False 的表达式,这种表达式被称为条件测试 。Python根据条件测的值为True 还是False 来决定是否执行if 语句中的代码。如果条件测试的值为True ,Python就执行紧跟在if 语句后面的代码;如果为False ,Python就忽略这些代码。
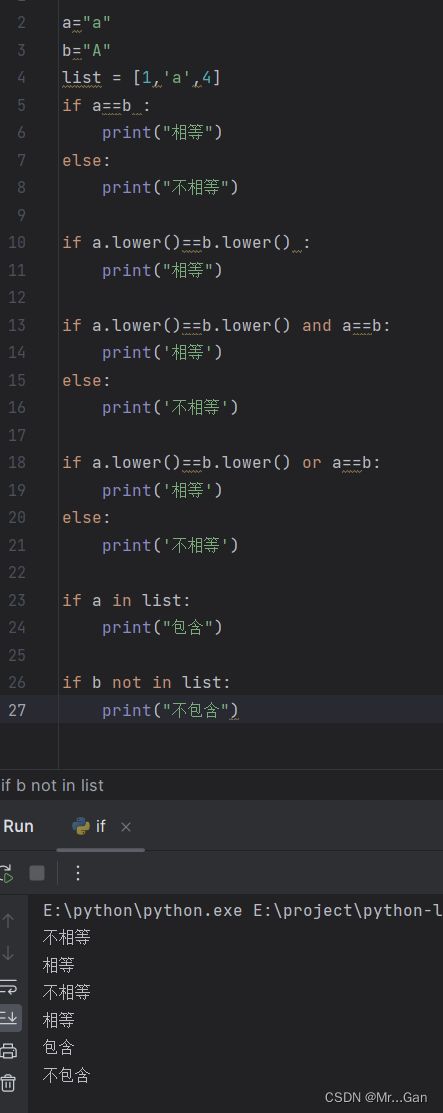
条件的比较:使用==号进行比较。区分大小写( 可用lower()进行小写转换 )
其他比较符号:!=、>、<、>=、<=
多个条件:and:前后条件都为true才返回true,其他情况返回false
or:前后条件一个为true就会返回true,两个都为false才返回false
是否在列表中:in:判断特定值是否在列表中。
not in:判断特定值是否不在列表中。
2、语句格式
if:if 布尔表达式 :
缩进 执行的语句
if else:if 布尔表达式 :
缩进 为true执行的语句
else:
缩进 为false执行的语句
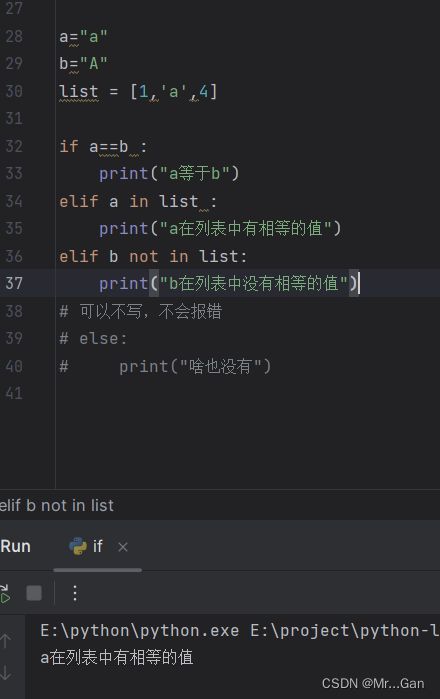
if elif else:if 布尔表达式 :
缩进 为true执行的语句
elif 布尔表达式 :
缩进 上一个布尔表达式为true执行的语句
else :
缩进 以上所有布尔表达式都不满足执行的语句
注意:if elif else中可以有多个elif,并且最后的else可以省略。
在多个elif中,只要前面一个满足后面的就不会执行。
六、字典
1、概念
字典 是一系列键—值对 。每个键 都与一个值相关联,你可以使用键来访问与之相关联的值。
与键相关联的值可以是数字、字符串、列表乃至字典。
字典用放在花括号{} 中的一系列键—值对表示
dirct={"name":"坤坤","age":2.5}键值对是两个相关联的值。指定键时,Python将返回与之相关联的值。键和值之间用冒号分隔,而键值对之间用逗号分隔。
2、操作字典
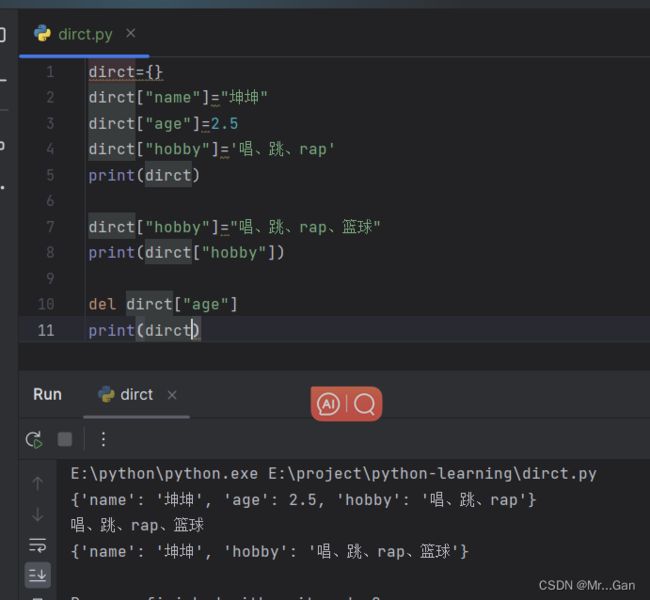
定义空字典:字典名={}
获取值:字典名["键名"]
添加键值对:字典名["新键名"]=新值
修改值:字典名["键名"]=新值
删除键值对:del 字典名["键名"]
3、遍历字典
遍历所有键值对:for key,value in 字典名.item() (key、value只是名称,可改)
遍历所有键:for key in 字典名.keys()
按照顺序遍历所有键:for key in sorted(字典名.keys())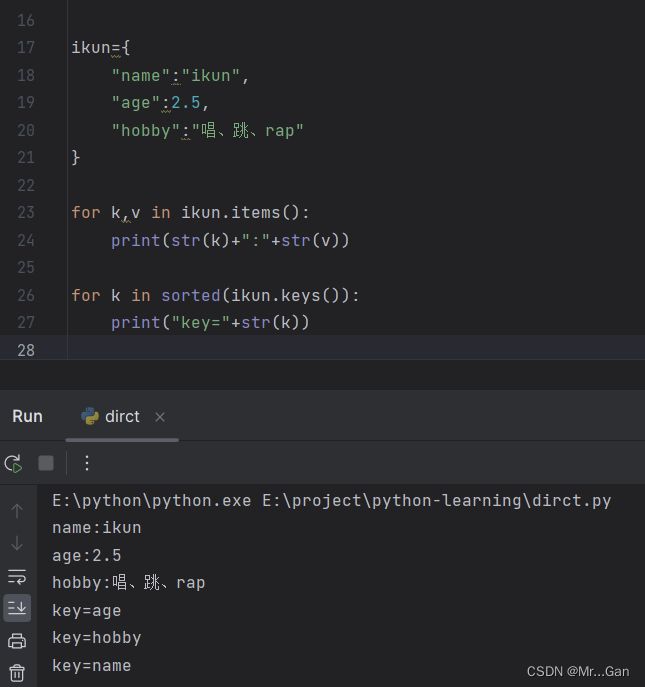
4、嵌套
需要将一系列字典存储在列表中,或将列表作为值存储在字典中,这称为嵌套。
字典列表:列表名=[字典1,字典2...]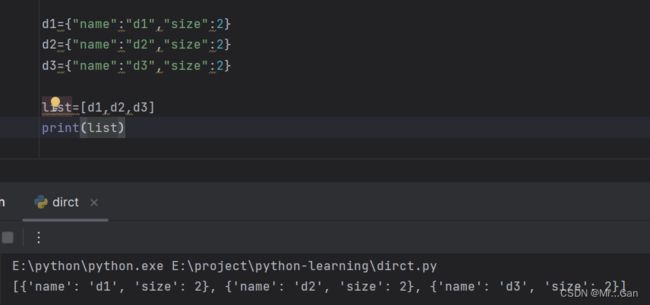
字典套列表:字典吗={"name":列表1,"name2":列表2...}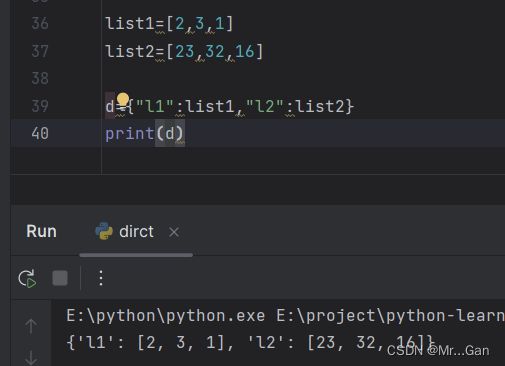
字典套字典:字典名={"name":字典1,"name2":字典2...}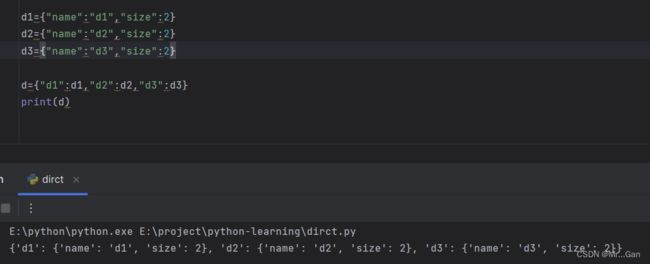
七、用户输入和while循环
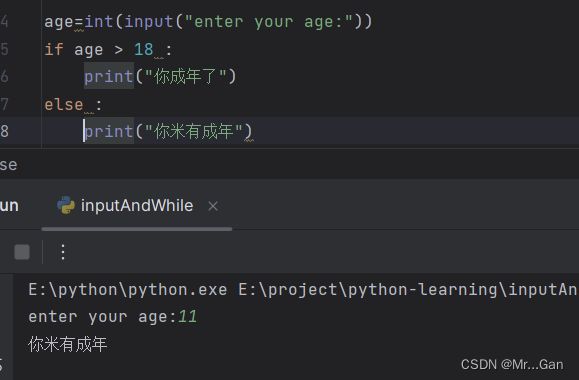
1、input
1、函数input() 让程序暂停运行,等待用户输入一些文本。获取用户输入后,Python将其存储在一个变量中
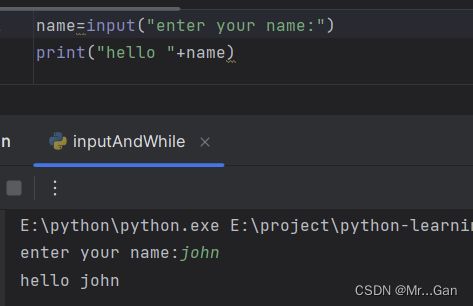
2、int()。转换字符串为数字类型
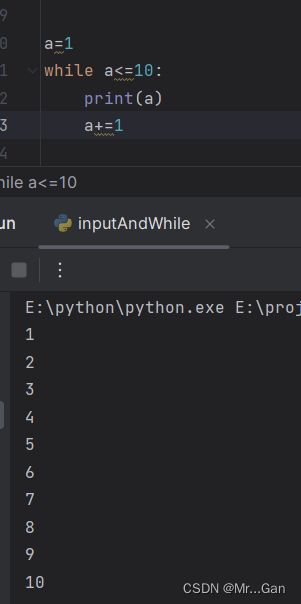
2、while循环
1、 基本语法
for 循环用于针对集合中的每个元素都一个代码块,而while 循环不断地运行,直到指定的条件不满 足为止。
例子:打印1-10
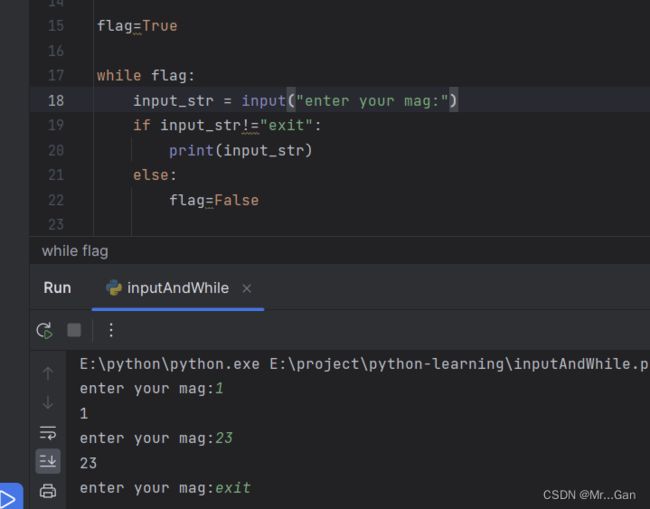
2、使用标志停止执行
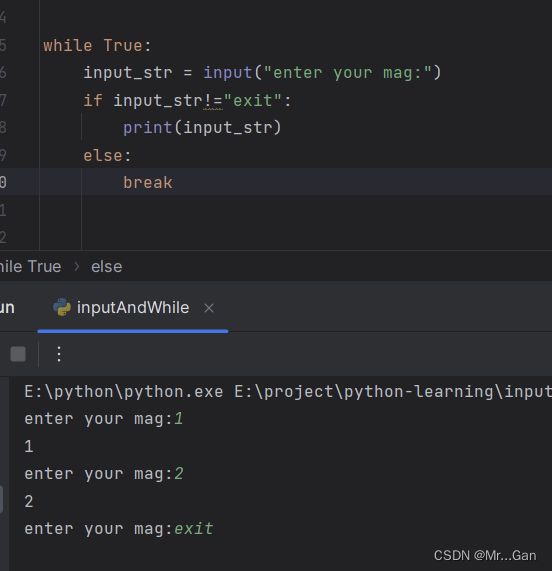
3、使用break退出循环
4、使用continue跳过本次循环

3、使用while处理字典与列表
1、将一个列表中的数据放大另一个中。
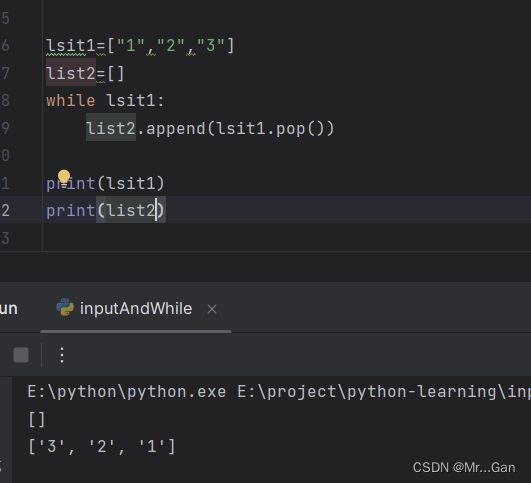
2、删除列表特定元素
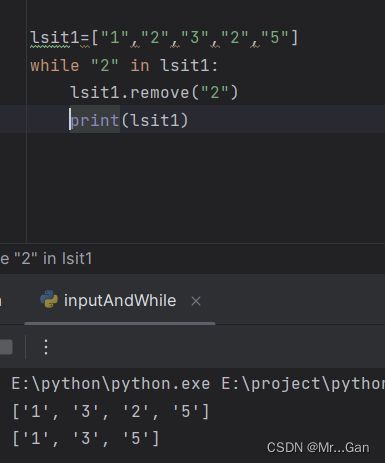
3、用户输入填充字典
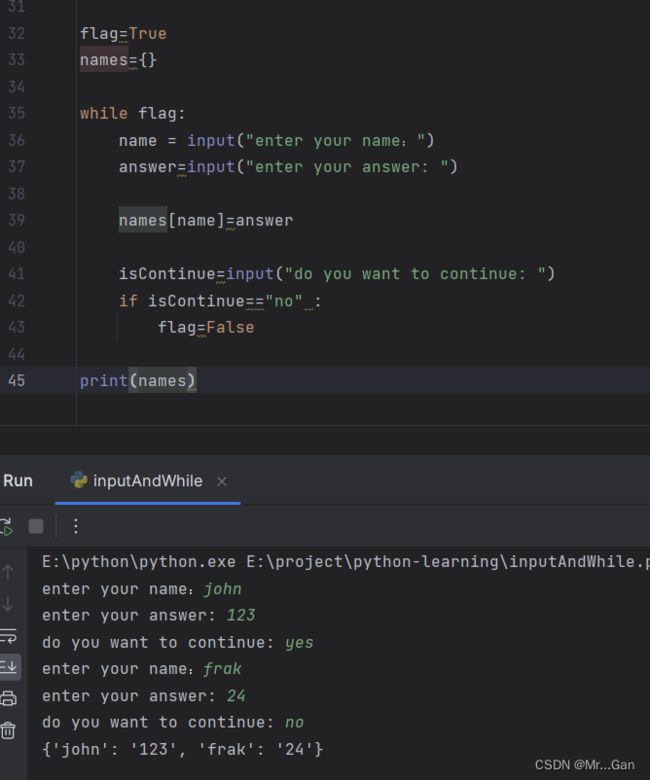
八、函数
1、定义函数
def outName(name):
print(name)
outName('111') 关键字def:告诉python要定义一个函数。
outName(name):定义函数名称+形参
print(name):函数体,作用:打印传入的形参
outName('111'):调用函数并传入实参
2、传递实参
1、实参位置
函数调用中的每个实参都关联到函数定义中的一个形参。为此,最简单的关
联方式是基于实参的顺序。这种关联方式被称为位置实参。
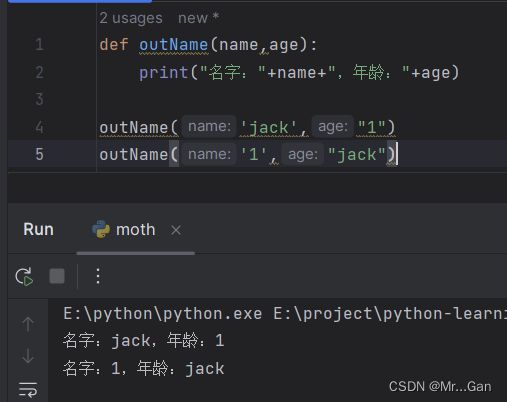
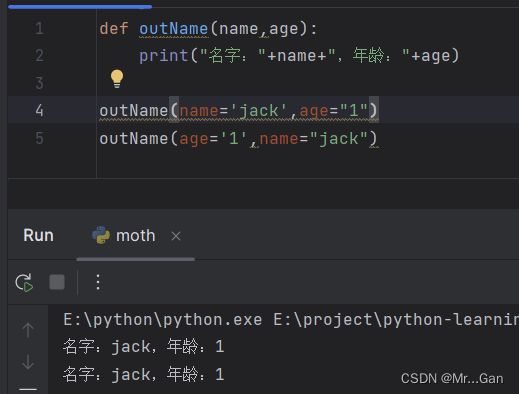
2、关键字实参
关键字实参 是传递给函数的名称—值对。你直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆。关键字实参让你无需考虑函数调用中的实参顺序。
3、默认值
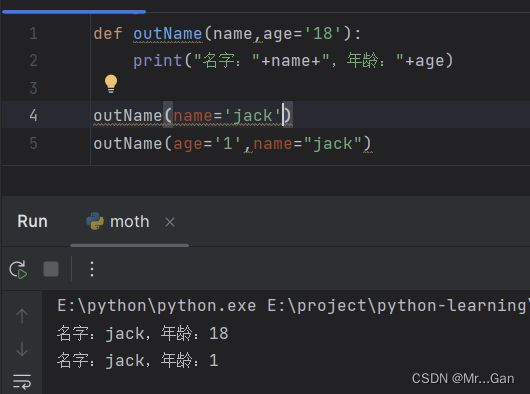
编写函数时,可给每个形参指定默认值 。在调用函数中给形参提供了实参时,Python将使用指定的实参值;否则,将使用形参的默认值。因此,给形参指定默认值后,可在函数调用中省略相应的实参。
3、返回值
在函数中,可使用return 语句将值返回到调用函数的代码行。
注意:如果函数形参中赋予了默认值就可以不传。
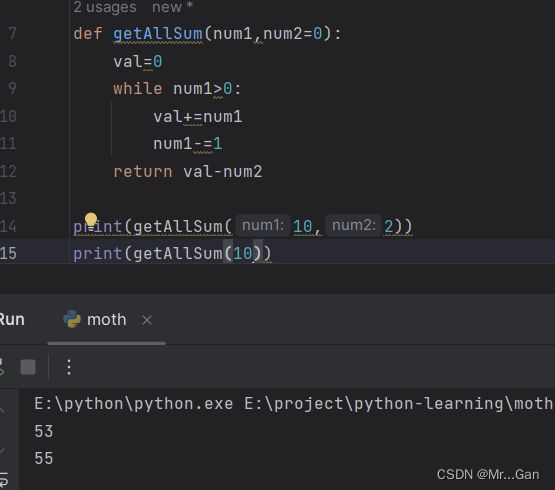
4、传递列表
传递的列表可以修改传入的列表。将列表传递给函数后,函数就可对其进行修改。在函数中对这个列表所做的任何修改都是永久性的
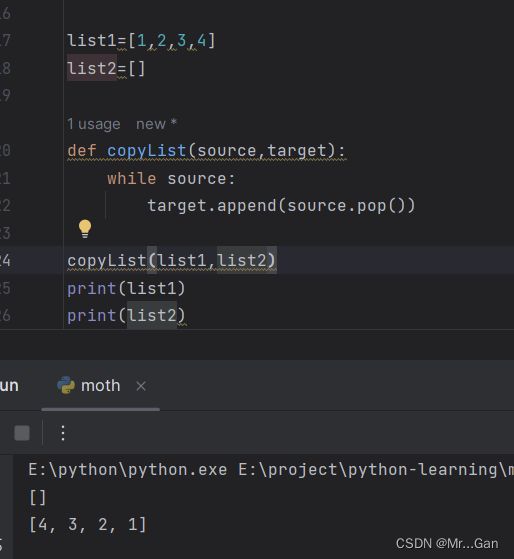
禁止函数修改列表。切片表示法[:] 创建列表的副本。
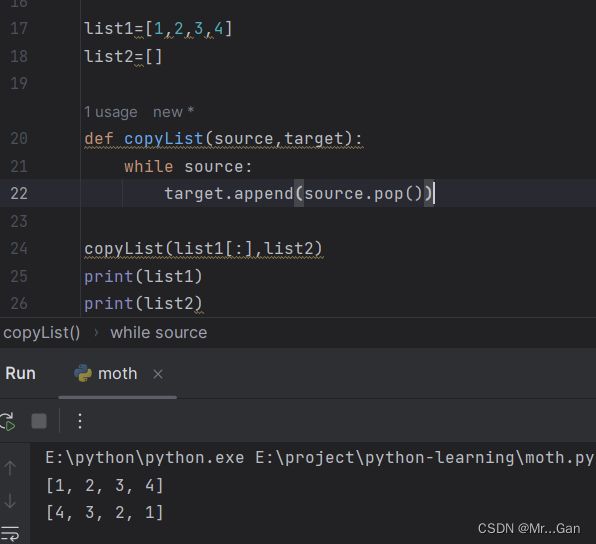
5、传递任意数量的实参
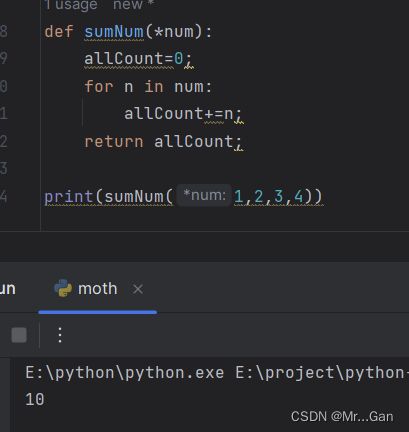
当函数需要传递数量不定的参数时,可以使用星号+形参名。形参名(*toppings )中的星号让Python创建一个名为toppings 的空元组,并将收到的所有值都封装到这个元组中。
1、结合位置实参和任意数量实参
函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后。
Python先匹配位置实参和关键字实参,再将余下的实参都收集到最后一个形参中。
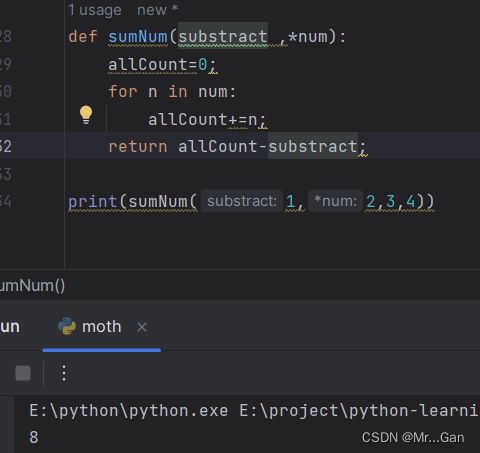
2、使用任意数量的关键字实参(传递字典)
有时候,需要接受任意数量的实参,但预先不知道传递给函数的会是什么样的信息。在
这种情况下,可将函数编写成能够接受任意数量的键—值对——调用语句提供了多少就接受
多少。 
6、将函数存储在模块中
函数的优点之一是,使用它们可将代码块与主程序分离。通过给函数指定描述性名称,可让主程序容易理解得多。你还可以更进一步,将函数存储在被称为模块 的独立文件中,再将模块导入 到主程序中。import语句允许在当前运行的程序文件中使用模块中的代码。
通过将函数存储在独立的文件中,可隐藏程序代码的细节,将重点放在程序的高层逻辑上。这还能让你在众多不同的程序中重用函数。将函数存储在独立文件中后,可与其他程序员共享这些文件而不是整个程序。知道如何导入函数还能让你使用其他程序员编写的函数库。
1、导入整个模块
在一个文件中可以使用import导入其他文件中的函数。
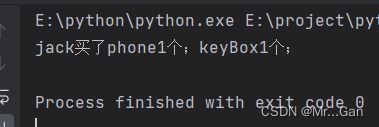
moth.py:
def buySomthing(name,**things):
strs=""
for key,val in things.items():
strs=strs+str(key)+str(val)+"个;"
print(name+"买了"+strs)
importFile.py:
import moth
moth.buySomthing("jack",phone=1,keyBox=1)运行结果:
2、其他导入方式
导入特定的函数:form 文件名 import 函数名1,函数名2...
调用方式:函数名()
导入全部函数:from 文件名 import *
调用方式:同上
3、别名
在导入函数时可以使用as给函数名或文件名取别名
例子:
from moth as m import sum as s,count as c
s(1,23,5)
c(1,2,3,4,5)
九、类
1、类的创建和使用
1、创建
class Person():
def __init__(self,name,age):
self.name=name
self.age=age
def msg(self):
print("我的名字是:"+self.name+";我的年龄:"+self.age)
def favrit(self,holb):
print(self.name+"的爱好是:"+holb)解释:
方法__init__() 是一个特殊的方法,每当你根据Person类创建新实例时,Python都会自动
运行它。在这个方法的名称中,开头和末尾各有两个下划线,这是一种约定,旨在避免Python默认方法与普通方法发生名称冲突。
方法__init__() 定义成了包含三个形参:self 、name 和age 。在这个方法的定义中,形参self 必不可少,还必须位于其他形参的前面。
两个变量都有前缀self 。以self 为前缀的变量都可供类中的所有方法使用,我们还可以通过类
的任何实例来访问这些变量。self.name = name 获取存储在形参name 中的值,并将其存储到变量name 中,然后该变量被关联到当前创建的实例。self.age = age 的作用与此类似。像这样可通过实例访问的变量称为属性 。
在msg和favrit两个方法中,self作为固定的参数,如果需要其他参数在self后面添加即可,在调用方法的时候不用传递self参数。
2、使用
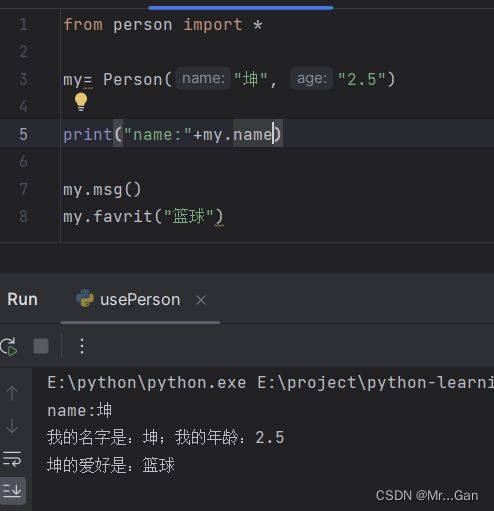
Person("坤", "2.5"):创建对象,name为:坤,age为:2.5。并且把创建好的对象赋值给my
获取属性:my.XX。
调用Person中的方法:my.方法名
2、继承
一个类继承 另一个类时,它将自动获得另一个类的所有属性和方法;原有的类称为父类 ,而新类称为子类 。子类继承了其父类的所有属性和方法,同时还可以定义自己的属性和方法。
1、子类的方法__init__()
创建子类的实例时,Python首先需要完成的任务是给父类的所有属性赋值。为此,子类的方法__init__()需要父类施以援手。
创建子类方法:
a、父类必须包含在当前文件中,且位于子类前面。
b、定义子类时,必须在括号内指定父类的名称。
c、super() 是一个特殊函数,帮助Python将父类和子类关联起来。这行代码让Python调
用ElectricCar 的父类的方法__init__() ,让ElectricCar 实例包含父类的所有属性。父
类也称为超类 (superclass),名称super因此而得名。
class Person():
def __init__(self,name,age):
self.name=name
self.age=age
def msg(self):
print("我的名字是:"+self.name+";我的年龄:"+self.age)
def favrit(self,holb):
print(self.name+"的爱好是:"+holb)
class SuperPerson(Person):
def __int__(self,name,age):
super().__init__(name,age)
self.skill = ""
def setSikll(self,skill):
self.skill=skill
print(self.name+"技能是"+self.skill)2、重写父类方法
对于父类的方法,只要它不符合子类模拟的实物的行为,都可对其进行重写。为此,可在子类中定义一个这样的方法,即它与要重写的父类方法同名。这样,Python将不会考虑这个父类方法,而只关注你在子类中定义的相应方法。
例子:基于上方的代码,在SuperPerson中复写Person中的msg方法。
# 结果为:名字是:超人;年龄:100;技能:飞
def msg(self):
print("名字是:" + self.name + ";年龄:" + self.age + ";技能:" + self.skill)3、提取公共代码
当一个方法在多个类中使用到时,可以把这些方法提取出来。
class Person():
def __init__(self,name,age):
self.name=name
self.age=age
def msg(self):
print("我的名字是:"+self.name+";我的年龄:"+self.age)
def favrit(self,holb):
print(self.name+"的爱好是:"+holb)
class Sikllw():
def __init__(self,skill=""):
self.skill=skill
def msg(self):
print("技能:"+self.skill)
class SuperPerson(Person):
def __init__(self,name,age):
super().__init__(name,age)
self.skill = Sikllw("飞")
解释:在SuperPerson中使用了Skillw类。创建了Skillw类并且赋值给SuperPerson中的skill。
测试:

3、导入类
随着你不断地给类添加功能,文件可能变得很长,即便你妥善地使用了继承亦如此。为遵循Python的总体理念,应让文件尽可能整洁。为在这方面提供帮助,Python允许你将类存储在模块中,然后在主程序中导入所需的模块。
1、导入类
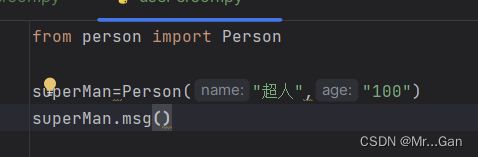
引入指定类:from 文件名 import 类名1,类名2
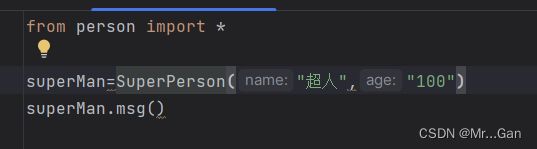
引入全部类:from 文件名 import *
调用:类名1.xxx;类名2.xxx
2、导入整个模块
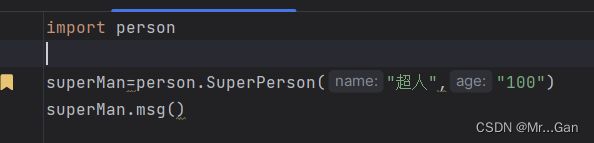
引入:import 文件名
调用:文件名.类名
4、Python标准库
python标准库 是一组模块,安装的Python都包含它。你现在对类的工作原理已有大致的了解,可以开始使用其他程序员编写好的模块了。可使用标准库中的任何函数和类,为此只需在程序开头包含一条简单的import 语句。
十、文件
1、读取文件
1、示例
with open("C:\\Users\\18068\Desktop\\11.txt") as file:
print(file.read()) 函数open() 接受一个参数:要打开的文件的名称。
关键字with 在不再需要访问文件后将其关闭。在这个程序中,注意到我们调用了open() ,但没有调用close() ;你也可以调用open() 和close() 来打开和关闭文件,但这样做时,如果程序存在bug,导致close() 语句未执行,文件将不会关闭。这看似微不足道,但未妥善地关闭文件可能会导致数据丢失或受损。如果在程序中过早地调用close() ,你会发现需要使用文件时它已关闭 (无法访问),这会导致更多的错误。并非在任何情况下都能轻松确定关闭文件的恰当时机,但通过使用前面所示的结构,可让Python去确定:你只管打开文件,并在需要时使用它,Python自会在合适的时候自动将其关闭。
相比于原始文件,该输出唯一不同的地方是末尾多了一个空行。为何会多出这个空行呢?因为read() 到达文件末尾时返回一个空字符串,而将这个空字符串显示出来时就是一个空行。要删除多出来的空行,可在print 语句中使用rstrip() :
2、读取全部内容
strs=""
#读取文件,使用UTF-8编码
with open("C:\\Users\\18068\Desktop\\11.txt",'r', encoding='utf-8') as file:
#把读取到的行保存为一个列表
lines =file.readlines()
# 把读取到的内容去除空格,并且保存为一整个字符串
for str in lines:
strs+=str.strip()
#根据用户输入的内容,判断在是否存在于文件中。
while True:
numb = input("输入一个数字:")
if numb in strs:
print("在文件中存在")
elif numb=='exit':
break
else:
print("不存在")
上述代码作用:打开文件,让用户输入内容,查看在文件中是否包含此内容。
2、写入文件
# #读取文件
with open("C:\\Users\\18068\Desktop\\11.txt",'w', encoding='utf-8') as file:
file.write("坤!") 调用open() 时提供了三个实参。
第一个实参也是要打开的文件的名称;
第二个实参('w' )告诉Python,我们要以写入模式 打开这个文件。打开文件时,可指
定读取模式 ('r' )、写入模式 ('w' )、附加模式 ('a' )或让你能够读取和写入文
件的模式('r+' )。如果你省略了模式实参,Python将以默认的只读模式打开文
件。如果你要写入的文件不存在,函数open() 将自动创建它。然而,以写入('w'
)模式打开文件时千万要小心,因为如果指定的文件已经存在,Python将在返回文
件对象前清空该文件;
第三个参数是编码格式,针对中文。
如果想一次写入多行需要在添加内容的最后添加换行符(\n)。
3、附加到文件
如果你要给文件添加内容,而不是覆盖原有的内容,可以附加模式 打开文件。你以附加模式打开文件时,Python不会在返回文件对象前清空文件,而你写入到文件的行都将添加到文件末尾。如果指定的文件不存在,Python将为你创建一个空文件。
主要代码:open的第二个函数更改为"a"
with open("C:\\Users\\18068\Desktop\\11.txt",'a', encoding='utf-8') as file:
file.write("\n小黑子!\n才是真爱")十一、异常
Python使用被称为异常的特殊对象来管理程序执行期间发生的错误。每当发生让Python不知所措的错误时,它都会创建一个异常对象。如果你编写了处理该异常的代码,程序将继续运行;如果你未对异常进行处理,程序将停止,并显示一个traceback,其中包含有关异常的报告。
异常是使用try-except 代码块处理的。try-except 代码块让Python执行指定的操作,同时告诉
Python发生异常时怎么办。使用了try-except 代码块时,即便出现异常,程序也将继续运行:显示你编写的友好的错误消息,而不是令用户迷惑的traceback。
1、处理异常
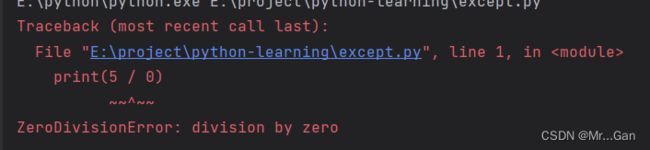
在程序中执行以下代码
print(5 / 0)会产生错误:ZeroDivisionError
处理上述异常:
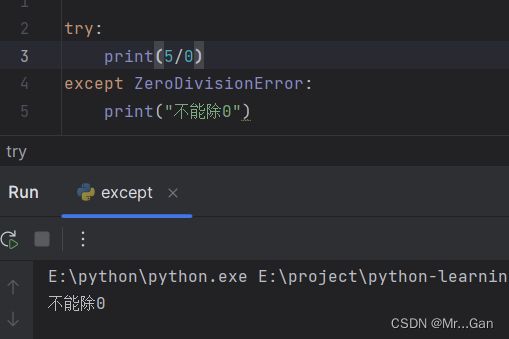
当你认为可能发生了错误时,可编写一个try-except 代码块来处理可能引发的异常。你让Python尝试运行一些代码,并告诉它如果这些代码引发了指定的异常,该怎么办 。
我们将导致错误的代码行print(5/0) 放在了一个try 代码块中。如果try 代码块中的代码运行起来没有问题,Python将跳过except 代码块;如果try 代码块中的代码导致了错误,Python将查找这样的except 代码块,并运行其中的代码,即其中指定的错误与引发的错误相同。在这个示例中,try 代码块中的代码引发了ZeroDivisionError 异常,因此Python指出了该如何解决问题的except 代码块,并运行其中的代码。
2、失败时一声不吭
并非每次捕获到异常时都需要告诉用户,有时候你希望程序在发生异常时一声不吭,就像什么都没有发生一样继续运行。要让程序在失败时一声不吭,可像通常那样编写try 代码块,但在except 代码块中明确地告诉Python什么都不要做。Python有一个pass 语句,可在代码块中使用它来让Python什么都不要做。

十二、存储数据
模块json 让你能够将简单的Python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。你还可以使用json 在Python程序之间分享数据。更重要的是,JSON数据格式并非Python专用的,这让你能够将以JSON格式存储的数据与使用其他编程语言的人分享。
1、使用json.dump()和json.load()
函数json.dump() 接受两个实参:要存储的数据以及可用于存储数据的文件对象。
import json
nums=[1,2,3,4,5,6]
file="C:\\Users\\18068\Desktop\\11.txt"
with open(file,"w") as f:
json.dump(nums,f)函数json.dump() 接受一个实参:用于把文件中的内容读取到内存中。
import json
file="C:\\Users\\18068\Desktop\\11.txt"
with open(file,"r") as f:
nu=json.load(f)
print(nu)