【系统设计系列】延迟吞吐和一致性
系统设计系列初衷
System Design Primer: 英文文档 GitHub - donnemartin/system-design-primer: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
中文版: https://github.com/donnemartin/system-design-primer/blob/master/README-zh-Hans.md
初衷主要还是为了学习系统设计,但是这个中文版看起来就像机器翻译的一样,所以还是手动做一些简单的笔记,并且在难以理解的地方对照英文版,根据自己的理解在AI的帮助下进行翻译和知识扩展。
延迟和吞吐量
1. 简单地说
延迟是执行操作或运算结果所花费的时间。
吞吐量是单位时间内(执行)此类操作或运算的数量。
通常,应该以可接受级延迟下最大化吞吐量为目标。
2.复杂地说
延迟(Latency):延迟是指服务从接收请求到给出响应的时间。换句话说,延迟是服务处理请求的速度。延迟越低,表示系统处理请求的速度越快。延迟可以从不同的角度进行划分,如网络延迟、处理延迟等。
吞吐量(Throughput):吞吐量是指系统在单位时间内处理请求的数量。换句话说,吞吐量是衡量系统处理能力大小的指标。吞吐量越高,表示系统在单位时间内能够处理更多的请求。
3. 延迟和吞吐量之间的关系:
一般来讲,在一台机器的情况下,如果请求响应越低,也就是延迟越低,那么单位时间能处理的请求数量不就更高了吗?那么低延迟和高吞吐量是匹配的上的。
实际上,在很多场景下,低延迟和高吞吐量之间存在一种权衡关系。
降低延迟可以提高系统的响应速度,使得在单位时间内能够处理更多的请求。然而,为了实现低延迟,系统可能需要采用更复杂的算法、增加服务器数量或使用更快的通信协议等方法,这些优化可能会导致系统吞吐量降低。
相反,追求高吞吐量可能会导致延迟增加。例如,在高吞吐量的情况下,系统可能需要使用更复杂的算法或者增加服务器数量,但这些优化可能会导致请求处理时间增加,从而使延迟变高。
因此,在实际系统设计和优化过程中,需要根据具体的应用场景和需求综合考虑延迟和吞吐量,以达到最佳的性能表现。在某些情况下,适当地平衡延迟和吞吐量,可能会使得系统整体性能更优。
可用性与一致性
CAP 理论
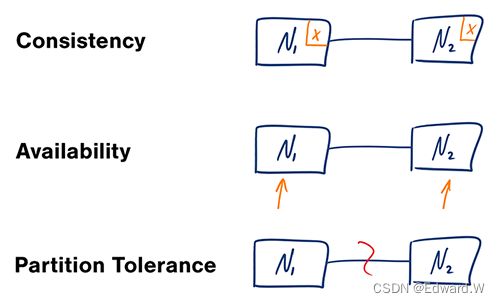
在一个分布式计算系统中,只能同时满足下列的两点:
- 一致性 ─ 每次访问都能获得最新数据但可能会收到错误响应
- 可用性 ─ 每次访问都能收到非错响应,但不保证获取到最新数据
- 分区容错性 ─ 在任意分区网络故障的情况下系统仍能继续运行
网络并不可靠,所以你应要支持分区容错性,并需要在软件可用性和一致性间做出取舍。
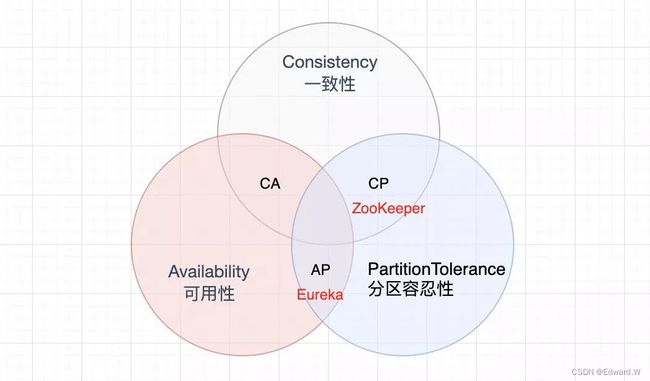
CP ─ 一致性和分区容错性
等待分区节点的响应可能会导致延时错误。如果你的业务需求需要原子读写,CP 是一个不错的选择。
AP ─ 可用性与分区容错性
响应节点上可用数据的最近版本可能并不是最新的。当分区解析完后,写入(操作)可能需要一些时间来传播。
如果业务需求允许最终一致性,或当有外部故障时要求系统继续运行,AP 是一个不错的选择。
一致性模式
有同一份数据的多份副本,我们面临着怎样同步它们的选择,以便让客户端有一致的显示数据。回想 CAP 理论中的一致性定义 ─ 每次访问都能获得最新数据但可能会收到错误响应
弱一致性
在写入之后,访问可能看到,也可能看不到(写入数据)。尽力优化之让其能访问最新数据。
这种方式可以 memcached 等系统中看到。弱一致性在 VoIP,视频聊天和实时多人游戏等真实用例中表现不错。打个比方,如果你在通话中丢失信号几秒钟时间,当重新连接时你是听不到这几秒钟所说的话的。
最终一致性
在写入后,访问最终能看到写入数据(通常在数毫秒内)。数据被异步复制。
DNS 和 email 等系统使用的是此种方式。最终一致性在高可用性系统中效果不错。
强一致性
在写入后,访问立即可见。数据被同步复制。
文件系统和关系型数据库(RDBMS)中使用的是此种方式。强一致性在需要记录的系统中运作良好。
可用性模式
有两种支持高可用性的模式: 故障切换(fail-over)和复制(replication)。
故障切换
工作到备用切换(Active-passive)
关于工作到备用的故障切换流程是,工作服务器发送周期信号给待机中的备用服务器。如果周期信号中断,备用服务器切换成工作服务器的 IP 地址并恢复服务。
宕机时间取决于备用服务器处于“热”待机状态还是需要从“冷”待机状态进行启动。只有工作服务器处理流量。
工作到备用的故障切换也被称为主从切换。
双工作切换(Active-active)
在双工作切换中,双方都在管控流量,在它们之间分散负载。
如果是外网服务器,DNS 将需要对两方都了解。如果是内网服务器,应用程序逻辑将需要对两方都了解。
双工作切换也可以称为主主切换。
缺陷:故障切换
- 故障切换需要添加额外硬件并增加复杂性。
- 如果新写入数据在能被复制到备用系统之前,工作系统出现了故障,则有可能会丢失数据。
复制
主─从复制
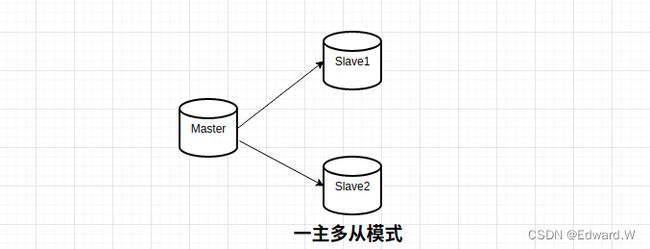
在主从复制中,一台服务器充当主服务器(master),负责处理写入和更新操作,而一个或多个其他服务器充当从服务器(slave),只负责读取操作。主服务器将自己的数据变更同步到从服务器,从而实现数据的一致性。
主从复制有以下几个优点:
提高性能:通过增加从服务器来分担主服务器的压力,提高数据库的处理能力。在主服务器上执行写入和更新操作,在从服务器上提供读功能,可以根据需求动态调整从服务器的数量。
提高稳定性:当主服务器出现问题时,从服务器可以接管数据访问,避免业务中断。同时,主从复制可以实现数据在不同服务器之间的同步,防止数据丢失。
容易维护和管理:通过主从复制,可以将数据分散在不同的服务器上,降低单点故障的风险,提高系统的可维护性和可扩展性。
主从复制可以应用于多种数据库系统,如 MySQL、RocketMQ 等。在这些系统中,主从复制技术有着不同的实现方式和参数配置,但基本原理都是一样的。
主─主复制
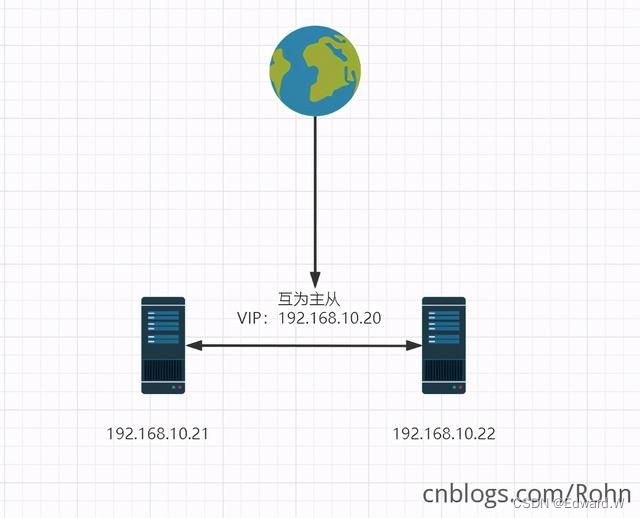
主主复制中的两个服务器都具有读写权限,可以同时进行读写操作。当一个服务器发生故障时,另一个服务器可以接管数据访问,从而实现高可用性和故障切换。
主主复制的优点包括:
高可用性:当一个数据库服务器发生故障时,另一个服务器可以接管数据访问,避免业务中断。
负载均衡:通过将数据分散在两个服务器上,可以提高数据库的处理能力,实现负载均衡。
数据分布:将数据分布在两个服务器上,可以降低单点故障的风险,提高系统的可维护性和可扩展性。
然而,主主复制也有一些缺点,如数据冲突和复杂性。在主主复制中,由于两个服务器都可以进行写操作,可能会出现数据冲突的情况。为了解决这个问题,可以采用一些策略,如将写操作限制在某个服务器上,或者使用分布式事务来确保数据的一致性。此外,主主复制的配置和管理相对较为复杂。