pyspark学习42-43:删除重复行、删除有空值的行、填充空值、filter过滤数据
对应笔记3.3,视频42-43
1、删除重复行
df = spark.read.csv('/sql/customers.csv',header=True)
>>> from pyspark.sql import Row
>>> df = sc.parallelize([
... Row(name='regan', age=27, height=170),
... Row(name='regan', age=27, height=170),
... Row(name='regan', age=27, height=155)],3).toDF()
>>> df.show()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 27| 170|regan|
| 27| 170|regan|
| 27| 155|regan|
+---+------+-----+
>>> df.dropDuplicates().show() #效果等于用distinct()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 27| 155|regan|
| 27| 170|regan|
+---+------+-----+
>>> df.dropDuplicates(subset=['age','name']).show() #subset用于指定在删除重复行的时候考
虑哪几列记录是重复的。
+---+------+-----+
|age|height| name|
+---+------+-----+
| 27| 170|regan|
+---+------+-----+
2、删除有空值的行dropna()
dropna(how='any', thresh=None, subset=None)删除DataFrame中的na数据,关键字参数how指定如何删,有“any”(有一个空值就删除整行)和‘all’两种选项,thresh指定行中na数据有多少个时删除整行数据,这个设置将覆盖how关键字参数的设置,subset指定在哪几列中删除na数据。
>>> import numpy as np
>>> df = spark.createDataFrame([(np.nan,27.,170.),(44.,27.,170.),
... (np.nan,np.nan,170.)],schema=['luck','age','weight'])
>>> df.show()
+----+----+------+
|luck| age|weight|
+----+----+------+
| NaN|27.0| 170.0|
|44.0|27.0| 170.0|
| NaN| NaN| 170.0|
+----+----+------+
>>> df.dropna(how='any').show( )
+----+----+------+
|luck| age|weight|
+----+----+------+
|44.0|27.0| 170.0|
+----+----+------+
>>> df.dropna(how='all').show()
+----+----+------+
|luck| age|weight|
+----+----+------+
| NaN|27.0| 170.0|
|44.0|27.0| 170.0|
| NaN| NaN| 170.0|
>>> df.dropna(thresh=2).show()
+----+----+------+
|luck| age|weight|
+----+----+------+
| NaN|27.0| 170.0|
|44.0|27.0| 170.0|
+----+----+------+
3、填充空值
fillna(value, subset=None)用value去填充df的空值。
import numpy as np
df = spark.createDataFrame([(np.nan,27.,170.),(44.,27.,170.),
(np.nan,np.nan,170.)],schema=['luck','age','weight'])
df.na.fill(0.0).show()
df.fillna(0.0).show() #左边两句是等价的

也可以给fill方法传递False参数,从而不填充
df.na.fill(False).show()

或者给fill传入一个字典,指定每个列的填充形式
df.na.fill({'luck':0.0,'age':50.0}).show()

4、.filter(condition)按照传入的条件进行过滤,
其实where方法就是filter方法的一个别名而已。
import numpy as np
df = spark.createDataFrame([(np.nan,27.,170.),(44.,27.,170.),
(np.nan,np.nan,170.)],schema=['luck','age','weight'])
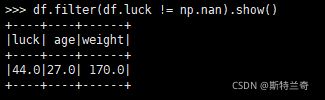
df.filter(df.luck != np.nan).show()
除了通过指定布尔表达式的方式之外,还有一种方法就是直接把条件以字符串的方式传入
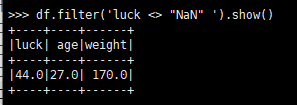
>>> df.where('luck <> "NaN" ').show()
