Mybatis源码分析(十一)Mybatis的一级缓存与二级缓存
目录
- 一 一级缓存与二级缓存
- 二 源码分析
-
- 2.1 CacheKey
- 2.2 一级缓存
- 2.3 二级缓存
-
- 总结
- 2.3.1 为何只有SqlSession提交或关闭之后二级缓存才会生效?

系列文章:
| 文章 | 状态 | 时间 | 描述 |
|---|---|---|---|
| (一)Mybatis 基本使用 | 已复习 | 2022-12-14 | 对Mybtais的基本使用,能够开发 |
| (二)Mybatis-config.xml的初始化 | 已复习 | 2023-02-10 | 对我们编写的mybatis配置文件的解析 |
| (三)SqlSessionFactory的初始化 | 已复习 | 2023-02-11 | SqlSession会话工厂的初始化 |
| (四)Mapper文件的解析 | 已复习 | 2023-02-12 | 主要对我们编写的Mapper.xml进行解析 |
| (五)SqlSession的创建 | 已复习 | 2023-02-13 | 主要介绍构建DefaultSqlSessionFactory |
| (六)Mapper的接口代理 | 已复习 | 2023-02-14 | 如何通过动态代理来执行我们编写的方法 |
| (七)MapperMethod的INSERT分析 | 已复习 | 2023-02-15 | 通过代理对象来执行Insert语句,返回结果 |
| (八)MapperMethod的Select分析 | 已复习 | 2023-02-16 | 通过代理对象来执行Select语句,返回结果 |
| (九)Mybatis的PreparedStatement | 已复习 | 2023-02-17 | 预处理语句的常见,以及与数据库打交道 |
| (十)Mybatis的结果隐射 | 已复习 | 2023-02-18 | 数据库结果与实体类对象的转换 |
| (十一)Mybatis中的缓存 | 计划中 | 2023-02-24 | Mybatis中一级缓存与二级缓存 |
| (十二)Mybatis中的插件开发 | 计划中 | – | Mybatis中的插件运行机制与开发 |
| (十三)Mybatis中的四大组件梳理 | 计划中 | – | Mybatis中的四大组件的梳理 |
| (十四)Mybatis中的设计模式梳理 | 计划中 | – | Mybatis中设计模式的整理 |
| (十五)Spring-Mybatis整理 | 计划中 | – | Spring与Mybatis整合 |
| (十六)Mybatis疑惑总结 | 计划中 | – | 我遇到的疑惑与问题 |
- 官网:mybatis – MyBatis 3 | 简介
- 文章:| 一级缓存和二级缓存源码分析
前面的文章我们把数据的查询,结果封装的基本流程都已经走通了,下面我们来讲讲Mybatis的以及缓存与二级缓存是使用以及代码原理

缓存介绍:
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
基本上就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
一 一级缓存与二级缓存
一级缓存
- 一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。
- 不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
二级缓存
- 二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
- 二级缓存底层还是个HashMap去实现。
区别
- 一级缓存是每个sqlsession私有的缓存区域,默认开启。
- 二级缓存是多个sqlsession共有的缓存区域,默认关闭,放在二级缓存中的对象必须实现序列化接口,且二级缓存可以使用第三方的。
使用
- 一级缓存是默认开启的,其作用域是SqlSession,MyBatis 默认一级查询缓存是开启状态,且不能关闭。
- 二级缓存开启,不同在于其存储作用域为 Mapper(Namespace),每个Mapper中有一个Cache对象,存放在Configration中,并且将其放进当前Mapper的所有MappedStatement当中,并且可自定义存储源,如 Ehcache。
二 源码分析
案例
@Test
public void SelectById(){
// 第一阶段:MyBatis的初始化阶段
String resource = "mybatis-config.xml";
// 得到配置文件的输入流
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
// 得到SqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 第二阶段:数据读写阶段
try (SqlSession session = sqlSessionFactory.openSession()) {
// 找到接口对应的实现
UserMapper userMapper = session.getMapper(UserMapper.class);
// 调用接口展开数据库操作
User user = userMapper.queryById(1);
System.out.println(user);
}
}
我们从前面可知,只有查询方法会去缓存,更新,删除,插入,等会更新缓存,所以我们以上面的案例来分析,我们来到关键代码
MapperMethod
/**
* 执行映射接口中的方法
* @param sqlSession sqlSession接口的实例,通过它可以进行数据库的操作
* @param args 执行接口方法时传入的参数
* @return 数据库操作结果
*/
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // 根据SQL语句类型,执行不同操作
case INSERT: { // 如果是插入语句
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: { // 如果是更新语句
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: { // 如果是删除语句MappedStatement
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT: // 如果是查询语句
if (method.returnsVoid() && method.hasResultHandler()) { // 方法返回值为void,且有结果处理器
// 使用结果处理器执行查询
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) { // 多条结果查询
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) { // Map结果查询
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) { // 游标类型结果查询
result = executeForCursor(sqlSession, args);
} else { // 单条结果查询
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH: // 清空缓存语句
result = sqlSession.flushStatements();
break;
default: // 未知语句类型,抛出异常
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
// 查询结果为null,但返回类型为基本类型。因此返回变量无法接收查询结果,抛出异常。
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
CachingExecutor
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建缓存key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
这里我们只关注缓存,其余的逻辑请参考前面的代码,这里我们来看一下CacheKey这个对象的构造
2.1 CacheKey
在cache中唯一确定一个缓存项需要使用缓存项的key,Mybatis中因为涉及到动态SQL等多方面因素,其缓存项的key不等仅仅通过一个String表示,所以MyBatis 提供了CacheKey类来表示缓存项的key,在一个CacheKey对象中可以封装多个影响缓存项的因素。
CacheKey
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
private static final int DEFAULT_MULTIPLYER = 37;
private static final int DEFAULT_HASHCODE = 17;
// 乘数,用来计算hashcode时使用
private final int multiplier;
// 哈希值,整个CacheKey的哈希值。如果两个CacheKey该值不同,则两个CacheKey一定不同
private int hashcode;
// 求和校验值,整个CacheKey的求和校验值。如果两个CacheKey该值不同,则两个CacheKey一定不同
private long checksum;
// 更新次数,整个CacheKey的更新次数
private int count;
// 更新历史
private List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLYER;
this.count = 0;
this.updateList = new ArrayList<>();
}
}
为啥选择17和37?
- 17是质子数中一个“不大不小”的存在,如果你使用的是一个如2的较小质数,那么得出的乘积会在一个很小的范围,很容易造成哈希值的冲突。
- 而如果选择一个100以上的质数,得出的哈希值会超出int的最大范围,这两种都不合适。
- 而如果对超过 50,000 个英文单词(由两个不同版本的 Unix 字典合并而成)进行 hash code 运算,并使用常数 31, 33, 37, 39 和 41 作为乘子(cachekey使用37),每个常数算出的哈希值冲突数都小于7个(国外大神做的测试),
- 那么这几个数就被作为生成hashCode值得备选乘数了?
CacheKey
/**
* 更新CacheKey
* @param object 此次更新的参数
*/
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
public void updateAll(Object[] objects) {
for (Object o : objects) {
update(o);
}
}
/**
* 比较当前对象和入参对象(通常也是CacheKey对象)是否相等
* @param object 入参对象
* @return 是否相等
*/
@Override
public boolean equals(Object object) {
// 如果地址一样,是一个对象,肯定相等
if (this == object) {
return true;
}
// 如果入参不是CacheKey对象,肯定不相等
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
// 依次通过hashcode、checksum、count判断。必须完全一致才相等
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
// 详细比较变更历史中的每次变更
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
@Override
public String toString() {
StringJoiner returnValue = new StringJoiner(":");
returnValue.add(String.valueOf(hashcode));
returnValue.add(String.valueOf(checksum));
updateList.stream().map(ArrayUtil::toString).forEach(returnValue::add);
return returnValue.toString();
}
@Override
public CacheKey clone() throws CloneNotSupportedException {
CacheKey clonedCacheKey = (CacheKey) super.clone();
clonedCacheKey.updateList = new ArrayList<>(updateList);
return clonedCacheKey;
}
当不断有新的影响因子参与计算时,hashcode 和 checksum 将会变得愈发复杂和随机。这样可降低冲突率,使 CacheKey 可在缓存中更均匀的分布。CacheKey 最终要作为键存入 HashMap,因此它需要覆盖 equals 和 hashCode 方法。
2.2 一级缓存
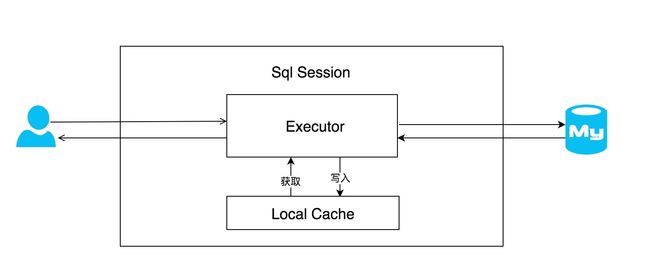
每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。当用户发起查询时,MyBatis根据当前执行的语句生成MappedStatement,在Local Cache进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入Local Cache,最后返回结果给用户。
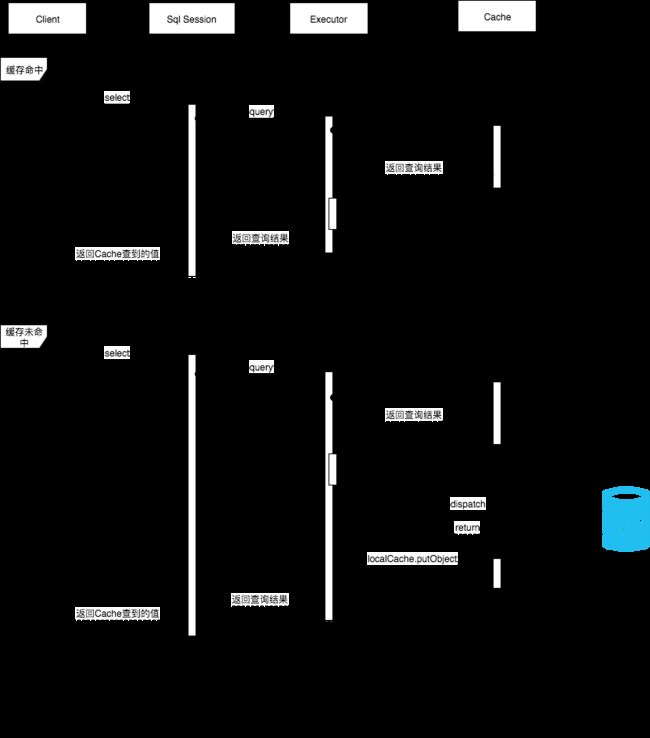
回到我们执行器中对于缓存的创建
BaseExecutor
/**
* 生成查询的缓存的键
* @param ms 映射语句对象
* @param parameterObject 参数对象
* @param rowBounds 翻页限制
* @param boundSql 解析结束后的SQL语句
* @return 生成的键值
*/
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 创建CacheKey,并将所有查询参数依次更新写入
CacheKey cacheKey = new CacheKey();
// 隐射语句id
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
// sql
cacheKey.update(boundSql.getSql());
// 参数
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 更新
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
从上面的代码我们可以看到,利用了sql和执行的参数生成一个key,如果同一sql不同的执行参数的话,将会生成不同的key,CacheKey 生成完毕后,我们来看下一步,执行具体的查询
CachingExecutor
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameterObject 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param 结果类型
* @return 结果列表
* @throws SQLException
*/
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取MappedStatement对应的缓存,
// 可能的结果有:该命名空间的缓存、共享的其它命名空间的缓存、无缓存,
// 注意这里是二级缓存,后面再看
Cache cache = ms.getCache();
// 如果映射文件未设置或则,此处cache变量为null
if (cache != null) { // 存在缓存
// 根据要求判断语句执行前是否要清除二级缓存,如果需要,清除二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) { // 该语句使用缓存且没有输出结果处理器
// 二级缓存不支持含有输出参数的CALLABLE语句,故在这里进行判断
ensureNoOutParams(ms, boundSql);
// 从缓存中读取结果
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) { // 缓存中没有结果
// 交给被包装的执行器执行
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 缓存被包装执行器返回的结果
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 交由被包装的实际执行器执行
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
上面的代码涉及到二级缓存,我们的目标先看看一级缓存,从本地缓存中进行记载
BaseExecutor
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameter 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param 结果类型
* @return 结果列表
* @throws SQLException
*/
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) { // 新的查询栈且要求清除缓存
// 清除一级缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试从本地缓存获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 本地缓存中有结果,则对于CALLABLE语句还需要绑定到IN/INOUT参数上
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 本地缓存没有结果,故需要查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 懒加载操作的处理
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 如果本地缓存的作用域为STATEMENT,则立刻清除本地缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
我们来看看关键代码:localCache.getObject(key),实际上他的底层维护了一个HashMap
PerpetualCache
package org.apache.ibatis.cache.impl;
import java.util.HashMap;
import java.util.Map;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.cache.CacheException;
/**
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
// Cache的id,一般为所在的namespace
private final String id;
// 用来存储要缓存的信息
private Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
接下里的逻辑就是缓存中有的话,会直接返回结果,如果没有的话,就查询数据库,并将结果设置到一级缓存之中
BaseExecutor
/**
* 从数据库中查询结果
* @param ms 映射语句
* @param parameter 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param 结果类型
* @return 结果列表
* @throws SQLException
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 向缓存中增加占位符,表示正在查询
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 删除占位符
localCache.removeObject(key);
}
// 将查询结果写入缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
以上就是一级缓存的基本过程,从代码来看其实就很简单,维护了一个内部的HashMap,注意在更新,删除,插入,是会刷掉缓存
CachingExecutor
/**
* 更新数据库数据,INSERT/UPDATE/DELETE三种操作都会调用该方法
* @param ms 映射语句
* @param parameterObject 参数对象
* @return 数据库操作结果
* @throws SQLException
*/
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 根据要求判断语句执行前是否要清除二级缓存,如果需要,清除二级缓存
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
BaseExecutor
/**
* 更新数据库数据,INSERT/UPDATE/DELETE三种操作都会调用该方法
* @param ms 映射语句
* @param parameter 参数对象
* @return 数据库操作结果
* @throws SQLException
*/
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
// 清理本地缓存
clearLocalCache();
// 返回调用子类进行操作
return doUpdate(ms, parameter);
}
总结
- MyBatis一级缓存的生命周期和SqlSession一致。
- MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
- MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
2.3 二级缓存
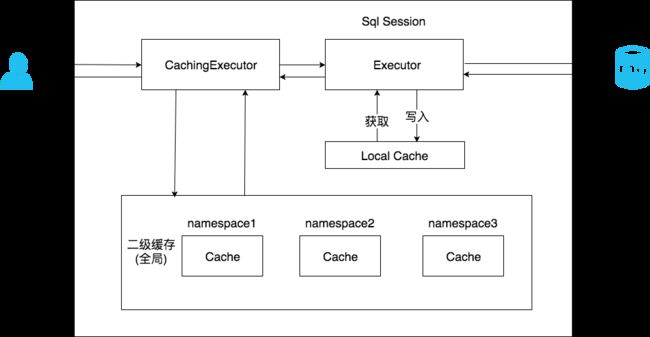
- 二级缓存构建在一级缓存之上,在收到查询请求时,MyBatis 首先会查询二级缓存。若二级缓存未命中,再去查询一级缓存。
- 与一级缓存不同,二级缓存和具体的命名空间绑定,一个Mapper中有一个Cache,相同Mapper中的MappedStatement公用一个Cache,一级缓存则是和 SqlSession 绑定。
- 一级缓存不存在并发问题二级缓存可在多个命名空间间共享,这种情况下,会存在并发问题,比喻多个不同的SqlSession 会同时执行相同的SQL语句,参数也相同,那么CacheKey是相同的,就会造成多个线程并发访问相同CacheKey的值,下面首先来看一下访问二级缓存的逻辑。
开启二级缓存
Mapper.xml文件中添加
<cache/>
我们首先来复习下对cache标签的解析
XMLMapperBuilder
/**
* 解析Mapper文件的下层节点
* @param context Mapper文件的根节点
*/
private void configurationElement(XNode context) {
try {
// 读取当前Mapper文件的命名空间
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// mapper文件中其他配置节点的解析
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
// 处理各个数据库操作语句
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
我们可以看到对于cache的解析在初始化的时候就已经完成了,我们来复习详细的过程吧,具体的配置信息可以参考官网的配置信息
//
// eviction="FIFO"
// flushInterval="60000"
// size="512"
// readOnly="true"/>
//
// select * from `user` where id = #{id}
//
//
// 这里处理其中的节点
private void cacheElement(XNode context) {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.Cache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
我们可以看到解析我们的配置信息,最终利用建造者模式构建Cache对象,返回给Configuration
MapperBuilderAssistant
/**
* 创建一个新的缓存
* @param typeClass 缓存的实现类
* @param evictionClass 缓存的清理类,即使用哪种包装类来清理缓存
* @param flushInterval 缓存清理时间间隔
* @param size 缓存大小
* @param readWrite 缓存是否支持读写
* @param blocking 缓存是否支持阻塞
* @param props 缓存配置属性
* @return 缓存
*/
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
上面我们向configuration增加了缓存,下面在对Sql语句进行具体解析时,通过命名空间取出缓存
MapperBuilderAssistant
/**
* 使用其他namespace的缓存
* @param namespace 其他的namespace
* @return 其他namespace的缓存
*/
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
unresolvedCacheRef = true;
// 获取其他namespace的缓存
Cache cache = configuration.getCache(namespace);
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
// 修改当前缓存为其他namespace的缓存,从而实现缓存共享
currentCache = cache;
unresolvedCacheRef = false;
return cache;
} catch (IllegalArgumentException e) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}
上面介绍了是如何解析cache标签的,我们回到上一步执行器执行查询的时候
CachingExecutor
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameterObject 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param 结果类型
* @return 结果列表
* @throws SQLException
*/
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取MappedStatement对应的缓存,
// 可能的结果有:该命名空间的缓存、共享的其它命名空间的缓存、无缓存,
// 注意这里是二级缓存,后面再看
Cache cache = ms.getCache();
// 如果映射文件未设置或则,此处cache变量为null
if (cache != null) { // 存在缓存
// 根据要求判断语句执行前是否要清除二级缓存,如果需要,清除二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) { // 该语句使用缓存且没有输出结果处理器
// 二级缓存不支持含有输出参数的CALLABLE语句,故在这里进行判断
ensureNoOutParams(ms, boundSql);
// 从缓存中读取结果
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) { // 缓存中没有结果
// 交给被包装的执行器执行
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 缓存被包装执行器返回的结果
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 交由被包装的实际执行器执行
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
关键代码 ms.getCache(),我们通过上面对Sql的解析,如果配置了二级缓存,在他们的Mapper隐射语句中会存在一个Cache对象。
如上,注意二级缓存是从 MappedStatement 中获取的。由于MappedStatement 存在于全局配置中,可以多个 CachingExecutor 获取到,这样就会出现线程安全问题。除此之外,若不加以控制,多个事务共用一个缓存实例,会导致脏读问题。至于脏读问题,需要借助其他类来处理,也就是上面代码中 tcm 变量对应的类型,我们来看看TransactionalCacheManager
TransactionalCacheManager
public class {
// 管理多个缓存的映射
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
// 清除缓存
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
// 从缓存中获取
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
// 向缓存中添加
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
/**
* 事务提交
*/
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
/**
* 事务回滚
*/
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
这里的方法很简单,我们来看看他的装饰者类TransactionalCache,这才是真正的缓存对象,首先我们来看看成员变量与构造方法
TransactionalCache
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
// 被装饰的对象
private final Cache delegate;
// 事务提交后是否直接清理缓存
private boolean clearOnCommit;
// 事务提交时需要写入缓存的数据
private final Map<Object, Object> entriesToAddOnCommit;
// 缓存查询未命中的数据
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
}
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 从缓存中读取对应的数据
Object object = delegate.getObject(key);
if (object == null) { // 缓存未命中
// 记录该缓存未命中
entriesMissedInCache.add(key);
}
if (clearOnCommit) { // 如果设置了提交时立马清除,则直接返回null
return null;
} else {
// 返回查询的结果
return object;
}
}
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param object 信息的值
*/
@Override
public void putObject(Object key, Object object) {
// 先放入到entriesToAddOnCommit列表中暂存
entriesToAddOnCommit.put(key, object);
}
/**
* 提交事务
*/
public void commit() {
if (clearOnCommit) { // 如果设置了事务提交后清理缓存
// 清理缓存
delegate.clear();
}
// 将为写入缓存的操作写入缓存
flushPendingEntries();
// 清理环境
reset();
}
/**
* 回滚事务
*/
public void rollback() {
// 删除缓存未命中的数据
unlockMissedEntries();
reset();
}
/**
* 清理环境
*/
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
/**
* 将未写入缓存的数据写入缓存
*/
private void flushPendingEntries() {
// 将entriesToAddOnCommit中的数据写入缓存
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 将entriesMissedInCache中的数据写入缓存
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
/**
* 删除缓存未命中的数据
*/
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
注意
存储二级缓存对象的时候是放到TransactionalCache.entriesToAddOnCommit这个map中,但是每次查询的时候是直接从TransactionalCache.delegate中去查询的,所以这个二级缓存查询数据库后,设置缓存值是没有立刻生效的,主要是因为直接存到 delegate 会导致脏数据问题。
文章参考:一级缓存和二级缓存源码分析
总结
总结
- MyBatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。
- MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- 在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
2.3.1 为何只有SqlSession提交或关闭之后二级缓存才会生效?
@Override
public void commit(boolean force) {
try {
// 主要是这句
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
// CachingExecutor.commit()
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();// 在这里
}
// TransactionalCacheManager.commit()
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();// 在这里
}
}
// TransactionalCache.commit()
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();//这一句
reset();
}
// TransactionalCache.flushPendingEntries()
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
// 在这里真正的将entriesToAddOnCommit的对象逐个添加到delegate中,只有这时,二级缓存才真正的生效
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}

如上图,时刻2,事务 A 对记录 A 进行了更新。时刻3,事务 A 从数据库查询记录 A,并将记录 A 写入缓存中。时刻4,事务 B 查询记录 A,由于缓存中存在记录 A,事务 B 直接从缓存中取数据。这个时候,脏数据问题就发生了。事务 B 在事务 A 未提交情况下,读取到了事务 A 所修改的记录。为了解决这个问题,我们可以为每个事务引入一个独立的缓存。查询数据时,仍从 delegate 缓存(以下统称为共享缓存)中查询。若缓存未命中,则查询数据库。存储查询结果时,并不直接存储查询结果到共享缓存中,而是先存储到事务缓存中,也就是 entriesToAddOnCommit 集合。当事务提交时,再将事务缓存中的缓存项转存到共享缓存中。这样,事务 B 只能在事务 A 提交后,才能读取到事务 A 所做的修改,解决了脏读问题。