【项目实战】SpringBoot整合Kafka消息队列(基于KafkaTemplate和@KafkaListener实现)
一、Kafka是什么?
Apache Kafka是分布式发布-订阅消息系统。
它最初由LinkedIn公司开发,之后成为Apache项目的一部分。
Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
二、Kafka的特点
Apache Kafka与传统消息系统相比,有以下不同:
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
- 它被设计为一个分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
三、Kafka几个主要的概念
| 概念 | 解释 |
|---|---|
| Broker | 节点,一个Broker代表是一个Kafka实例节点,多个Broker可以组成Kafka集群 |
| Topic | 主题,等同于消息系统中的队列(queue),一个Topic中存在多个Partition |
| Partition | 分区,构成Kafka存储结构的最小单位 |
| Partition offset | offset为消息偏移量,以Partition为单位,即使在同一个Topic中,不同Partition的offset也是重新开始计算(也就是会重复) |
| Group | 消费者组,一个Group里面包含多个消费者 |
| Message | 消息,是队列中消息的承载体,也就是通信的基本单位,Producer可以向Topic中发送Message |
四、Kafka环境准备
windows下安装kafka可以参考这一篇博客:https://blog.csdn.net/w546097639/article/details/88578635
五、SpringBoot整合Kafka消息队列
(1) 消息生产者端
Step1、引入POM文件
在spring boot环境中使用,引入需要依赖的jar包,引入POM文件
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
dependency>
Step2、新增生产者端的配置文件
spring:
kafka:
bootstrap-servers: ${KAFKA_SERVER:IP地址:端口号,IP地址:端口号,IP地址:端口号,IP地址:端口号}
consumer:
auto-commit-interval: ${KAFKA_CONSUMER_AUTO_COMMIT_INTERVAL:5000}
auto-offset-reset: ${KAFKA_CONSUMER_AUTO_OFFSET_RESET:earliest}
enable-auto-commit: ${KAFKA_CONSUMER_ENABLE_AUTO_COMMIT:true}
group-id: ${KAFKA_CONSUMER_GROUPID:default_kafka_group}
producer:
acks: ${KAFKA_PRODUCER_ACKS:all}
batch-size: ${KAFKA_PRODUCER_BATCH:16384}
buffer-memory: ${KAFKA_PRODUCER_BUFFER_MEMORY:33554432}
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: ${KAFKA_PRODUCER_RETRIES:0}
Step3、定义Kafka生产者
@RestController
@RequestMapping(value = "/kafka/v1")
@Slf4j
public class KafkaProducerController {
public static final String Upstream_C2S_Topic = "Upstream_C2S_Topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@ResponseBody
@PostMapping(value = "/serviceListChanges", produces = "application/json")
public JSONObject serviceListChanges(@RequestBody JSONObject jsonData) {
log.info("URL = {},vin={}, 请求的jsonObject的值 = {}",
"serviceListChanges", jsonData.getStr("vin"), jsonData);
try {
kafkaTemplate.send(Upstream_C2S_Topic, jsonData.toString());
jsonData.set("success", true);
return jsonData;
} catch (Exception e) {
log.error("KafkaProducerController serviceListChanges error = {}", e.getMessage());
}
return new JSONObject();
}
}
(2) 消息消费者端
Step1、引入POM文件
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
dependency>
Step2、 新增消费者的配置文件
spring:
kafka:
bootstrap-servers: ${KAFKA_SERVER:IP地址:端口号,IP地址:端口号,IP地址:端口号,IP地址:端口号}
consumer:
auto-commit-interval: ${KAFKA_CONSUMER_AUTO_COMMIT_INTERVAL:5000}
auto-offset-reset: ${KAFKA_CONSUMER_AUTO_OFFSET_RESET:earliest}
enable-auto-commit: ${KAFKA_CONSUMER_ENABLE_AUTO_COMMIT:true}
group-id: ${KAFKA_CONSUMER_GROUPID:default_kafka_group}
max-poll-records: ${KAFKA_CONSUMER_MAX_POLL_RECORDS:100}
properties:
session:
timeout:
ms: ${KAFKA_CONSUMER_PROPERTIES_SESSION_TIMEOUT_MS:10000}
listener:
concurrency: ${KAFKA_LISTENER_CONCURRENCY:4}
producer:
acks: ${KAFKA_PRODUCER_ACKS:all}
retries: ${KAFKA_PRODUCER_RETRIES:0}
batch-size: ${KAFKA_PRODUCER_BATCH:16384}
buffer-memory: ${KAFKA_PRODUCER_BUFFER_MEMORY:33554432}
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
autoCommitInterval: ${KAFKA_PRODUCER_PROPERTIES_AUTO_COMMIT_INTERVAL:100}
autoOffsetReset: ${KAFKA_PRODUCER_PROPERTIES_AUTO_OFFSET_RESET:latest}
concurrency: ${KAFKA_PRODUCER_PROPERTIES_CONCURRENCY:10}
enableAutoCommit: ${KAFKA_PRODUCER_PROPERTIES_ENABLE_AUTO_COMMIT:true}
groupId: ${KAFKA_PRODUCER_PROPERTIES_GROUPID:default_kafka_group}
linger: ${KAFKA_PRODUCER_PROPERTIES_LINGER:0}
maxPollRecords: ${KAFKA_PRODUCER_PROPERTIES_MAX_POLL_RECORDS:100}
sessionTimeout: ${KAFKA_PRODUCER_PROPERTIES_SESSION_TIMEOUT:60000}
见底部:配置文件的参数详解
Step3、 定义抽象类 Consumer
@Slf4j
public abstract class Consumer {
public void listenTopic(ConsumerRecord<String, String> record) {
String topic = record.topic();
String value = record.value();
log.info("kafka的key:{},value:{} ", topic, value);
if (JSONUtil.isJson(value)) {
consumerTopic(topic, value);
}
}
public void add(String value) {
this.consumerTopic(null, value);
}
//执行消费逻辑
public abstract void consumerTopic(String topic, String value);
}
Step4、 定义实现类 XXXConsumer
@Component
@Slf4j
public class ServiceListChangesConsumer extends Consumer {
public static final String Upstream_C2S_Topic = "Upstream_C2S_Topic";
@Override
@KafkaListener(topicPattern = Upstream_C2S_Topic)
public void listenTopic(ConsumerRecord<String, String> record) {
super.listenTopic(record);
}
// 执行消费逻辑
@Override
public void consumerTopic(String topic, String value) {
JSONObject jsonObject = JSONUtil.parseObj(value);
String vin = jsonObject.getStr("vin");
log.info("VIN={},ServiceListChangesConsumer消费成功,消息id={} ", vin, jsonObject.getStr("eventID"));
}
}
(3)业务测试验证
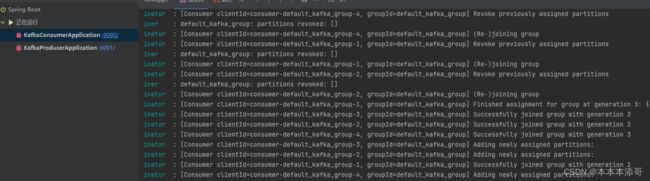
将两个服务正常运行,看到控制台中输出一些Kafka配置的相关参数
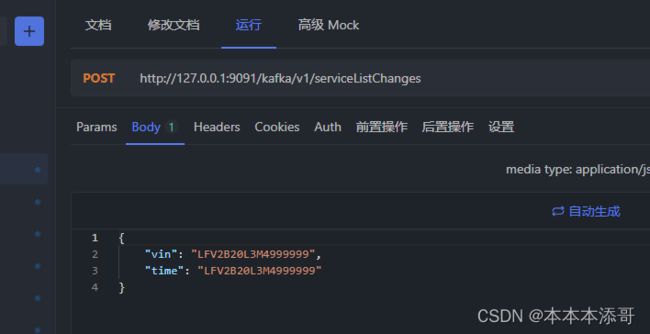
 配置如下的ApiFox用于接口调试
配置如下的ApiFox用于接口调试
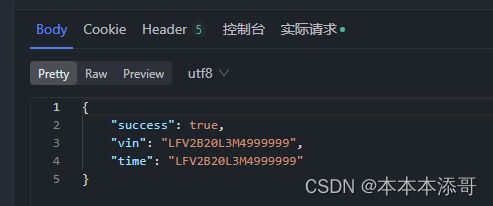
点击发送之后,能正常收到后台反馈的业务响应
查看控制台输出(生产者的数据)
2023-01-04 22:42:51.805 INFO 10132 — [nio-9091-exec-6] c.d.t.l.g.c.KafkaProducerController : URL = serviceListChanges,vin=LFV2B20L3M4999999, 请求的jsonObject的值 = {“vin”:“LFV2B20L3M4999999”,“time”:“LFV2B20L3M4999999”}

查看控制台输出(消费者的数据)
2023-01-04 22:42:51.818 INFO 13800 — [ntainer#0-2-C-1] c.d.tsp.logic.analyze.kafka.Consumer : kafka的key:Upstream_C2S_Topic,value:{“vin”:“LFV2B20L3M4999999”,“time”:“LFV2B20L3M4999999”}
2023-01-04 22:42:51.818 INFO 13800 — [ntainer#0-2-C-1] c.d.t.l.a.c.ServiceListChangesConsumer : VIN=LFV2B20L3M4999999,ServiceListChangesConsumer消费成功,消息id=null

六、KafkaUtils, Kafka的工具类
@Component
public class KafkaUtils {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
//发送消息到kafka
public boolean sendMsg(String topic, String json) {
if (StrUtil.isBlank(topic) || StrUtil.isBlank(json)) {
return false;
}
kafkaTemplate.send(topic, json);
return true;
}
//发送消息到kafka
public boolean sendMsg(String topic, String key, String json) {
if (StrUtil.isBlank(topic) || StrUtil.isBlank(json)) {
return false;
}
kafkaTemplate.send(topic, key, json);
return true;
}
//批量存储
public boolean sendBatchMsg(String topic, List<KafkaMsgBean> msgs) {
if (CollUtil.isEmpty(msgs)) {
return false;
}
msgs.forEach(msg -> {
sendMsg(topic, msg.getDeviceId(), msg.getMsgContent());
});
return true;
}
}
七、配置文件的参数详解
(1)入门了解
| 序号 | 内容 | 解释 |
|---|---|---|
| 1 | bootstrap-servers | 指定kafka 代理地址,可以多个 |
| 2 | producer | 定义生产者 |
| 3 | batch-size | 每次批量发送消息的数量 |
| 4 | key-serializer | 指定消息key的编解码方式 |
| 5 | value-serializer | 指定消息体的编解码方式 |
(2)详细了解
spring:
#重要提示:kafka配置,该配置属性将直接注入到KafkaTemplate中
kafka:
bootstrap-servers: 10.200.8.29:9092
#https://kafka.apache.org/documentation/#producerconfigs
producer:
bootstrap-servers: 10.200.8.29:9092
# 可重试错误的重试次数,例如“连接错误”、“无主且未选举出新Leader”
retries: 1 #生产者发送消息失败重试次数
# 多条消息放同一批次,达到多达就让Sender线程发送
batch-size: 16384 # 同一批次内存大小(默认16K)
# 发送消息的速度超过发送到服务器的速度,会导致空间不足。send方法要么被阻塞,要么抛异常
# 取决于如何设置max.block.ms,表示抛出异常前可以阻塞一段时间
buffer-memory: 314572800 #生产者内存缓存区大小(300M = 300*1024*1024)
#acks=0:无论成功还是失败,只发送一次。无需确认
#acks=1:即只需要确认leader收到消息
#acks=all或-1:ISR + Leader都确定收到
acks: 1
key-serializer: org.apache.kafka.common.serialization.StringSerializer #key的编解码方法
value-serializer: org.apache.kafka.common.serialization.StringSerializer #value的编解码方法
#开启事务,但是要求ack为all,否则无法保证幂等性
#transaction-id-prefix: "COLA_TX"
#额外的,没有直接有properties对应的参数,将存放到下面这个Map对象中,一并初始化
properties:
#自定义拦截器,注意,这里结尾时classes(先于分区器,快递先贴了标签再指定地址)
interceptor.classes: cn.com.controller.TimeInterceptor
#自定义分区器
#partitioner.class: com.alibaba.cola.kafka.test.customer.inteceptor.MyPartitioner
#即使达不到batch-size设定的大小,只要超过这个毫秒的时间,一样会发送消息出去
linger.ms: 1000
#最大请求大小,200M = 200*1024*1024,与服务器broker的message.max.bytes最好匹配一致
max.request.size: 209715200
#Producer.send()方法的最大阻塞时间(115秒)
# 发送消息的速度超过发送到服务器的速度,会导致空间不足。send方法要么被阻塞,要么抛异常
# 取决于如何设置max.block.ms,表示抛出异常前可以阻塞一段时间
max.block.ms: 115000
#该配置控制客户端等待服务器的响应的最长时间。
#如果超时之前仍未收到响应,则客户端将在必要时重新发送请求,如果重试次数(retries)已用尽,则会使请求失败。
#此值应大于replica.lag.time.max.ms(broker配置),以减少由于不必要的生产者重试而导致消息重复的可能性。
request.timeout.ms: 115000
#等待send回调的最大时间。常用语重试,如果一定要发送,retries则配Integer.MAX
#如果超过该时间:TimeoutException: Expiring 1 record(s) .. has passed since batch creation
delivery.timeout.ms: 120000
# 生产者在服务器响应之前能发多少个消息,若对消息顺序有严格限制,需要配置为1
# max.in.flight.requests.per.connection: 1
spring:
kafka:
#https://kafka.apache.org/documentation/#consumerconfigs
consumer:
bootstrap-servers: 10.200.8.29:9092
group-id: auto-dev #消费者组
#消费方式: 在有提交记录的时候,earliest与latest是一样的,从提交记录的下一条开始消费
# earliest:无提交记录,从头开始消费
#latest:无提交记录,从最新的消息的下一条开始消费
auto-offset-reset: earliest
enable-auto-commit: false #是否自动提交偏移量offset
auto-commit-interval: 1S #前提是 enable-auto-commit=true。自动提交的频率
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 2
properties:
#如果在这个时间内没有收到心跳,该消费者会被踢出组并触发{组再平衡 rebalance}
session.timeout.ms: 120000
#最大消费时间。此决定了获取消息后提交偏移量的最大时间,超过设定的时间(默认5分钟),服务端也会认为该消费者失效。踢出并再平衡
max.poll.interval.ms: 300000
#配置控制客户端等待请求响应的最长时间。
#如果在超时之前没有收到响应,客户端将在必要时重新发送请求,
#或者如果重试次数用尽,则请求失败。
request.timeout.ms: 60000
#订阅或分配主题时,允许自动创建主题。0.11之前,必须设置false
allow.auto.create.topics: true
#poll方法向协调器发送心跳的频率,为session.timeout.ms的三分之一
heartbeat.interval.ms: 40000
#每个分区里返回的记录最多不超max.partitions.fetch.bytes 指定的字节
#0.10.1版本后 如果 fetch 的第一个非空分区中的第一条消息大于这个限制
#仍然会返回该消息,以确保消费者可以进行
#max.partition.fetch.bytes=1048576 #1M
listener:
#当enable.auto.commit的值设置为false时,该值会生效;为true时不会生效
#manual_immediate:需要手动调用Acknowledgment.acknowledge()后立即提交
ack-mode: manual_immediate
missing-topics-fatal: true #如果至少有一个topic不存在,true启动失败。false忽略
#type: single #单条消费?批量消费? #批量消费需要配合 consumer.max-poll-records
type: batch
concurrency: 2 #配置多少,就为为每个消费者实例创建多少个线程。多出分区的线程空闲
template:
default-topic: "COLA"