Oracle jdbc读取为UTF-8字符 (ojdbc8中代码bug)导致乱码问题-下
首先我们在获取返回的数据 首先初始化一系列数据
为每一列的列属性进行配置 如列名等

然后是对Oracle返回的数据进行获取,我们对ojdbc6和ojdbc8进行比较
Ojdbc6中在此处,获取到数据库返回的byte[]数组,为GBK类型
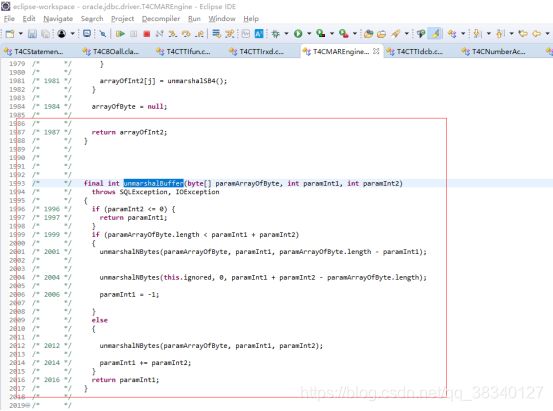
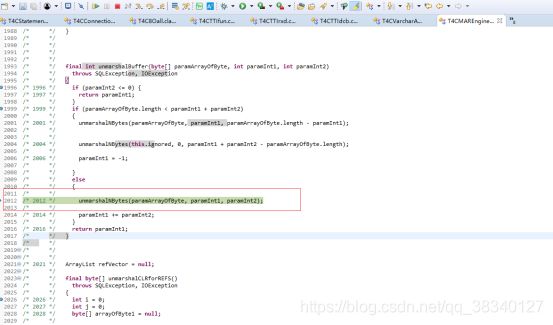
这一步 获取 byte[]数组
接着将获取到的byte数组 变为java中的char 放置在rowspacehchar中 再getString时候调用,(rowspacehchar存放返回数据的所有内容)
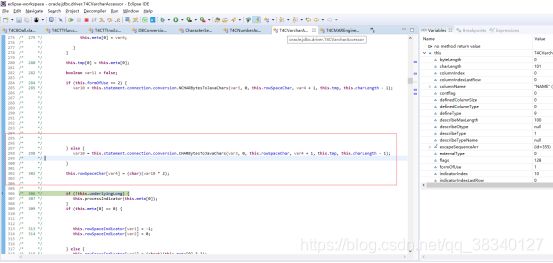
将ascii码转换为java的chars ,ojdbc6中获取到的为GBK的byte[]

Ojdbc8中
该方法 获取数据库的byte[]数组也为gbk类型(张三的gbk byte)

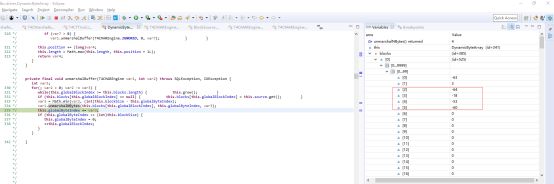
下列方法为 获取到Oracle 的返回数组方法(readRxd()方法)
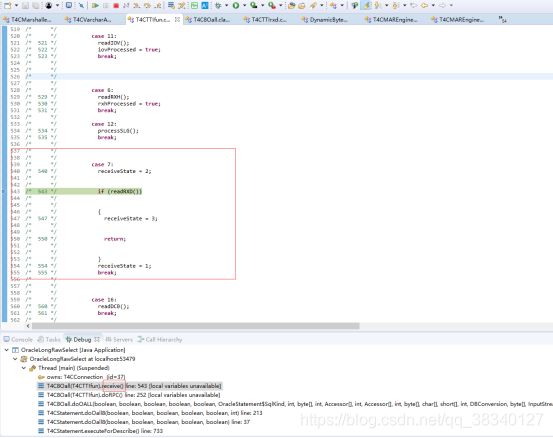
Ojbc8为在getString时候对byte[]数组生成新的String 与Ojbc6中不同

currentRow 表示当前行数 paramInt表示第几列

列数减1 从0计算
String所在的方法
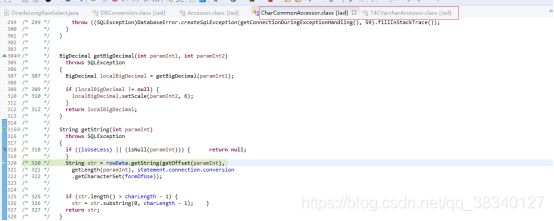
根据字符类型等进行专义
paramLong表示数据 所在byte[]内的开始位置 如2 表示第二位开始
paramInt 表示该数据所在byte[]中的长度 如4 表示 第二位开始共占有4位
以上两个参数与用于获取对应数据在byte[]中的起始位置 从而去除String的byte数组
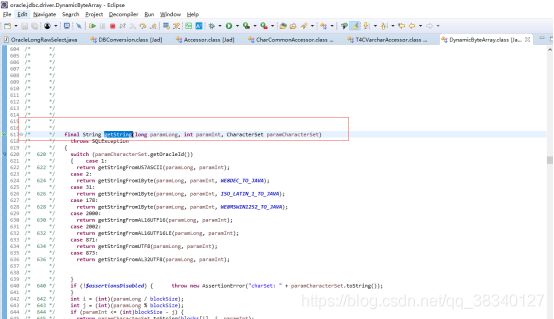
源库为ascii故用方法一
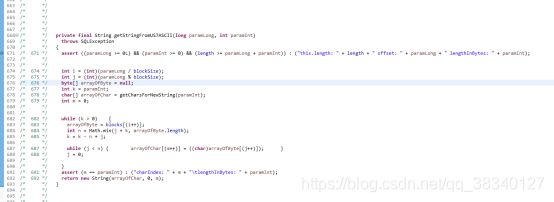
发现转换的方法有错(第一个为ojdbc6的方法)
public static final int convertASCIIBytesToJavaChars(byte[] paramArrayOfByte, int paramInt1,
char[] paramArrayOfChar, int paramInt2, int paramInt3)
{
int k = paramInt2 + paramInt3;
int i = paramInt2;
for (int j = paramInt1; i < k; j++) {
paramArrayOfChar[i] = ((char) (0xFF & paramArrayOfByte[j]));
i++;
}
return paramInt3;
}
下列为ojdbc8的装换方法中所采用的的转换 并未进行0xFF
public static final int convertASCIIBytesToJavaChars2(byte[] paramArrayOfByte, int paramInt1,
char[] paramArrayOfChar, int paramInt2, int paramInt3)
{
int k = paramInt2 + paramInt3;
int i = paramInt2;
for (int j = paramInt1; i < k; j++) {
paramArrayOfChar[i] = ((char) (paramArrayOfByte[j]));
i++;
}
return paramInt3;
}
为什么要用0XFF :在转char时候 先获取该char 对呀的ascii值 即byte转为int
首先: java中的二进制采用的是补码形式
其次:byte占8位,int占32位,将byte强制转换为int型时,如果没有做 & 0xff运算,且byte对应的值为负数的话,就会对高位3个字节进行补位,这样就有可能出现补位误差的错误。
举例来说,byte型的-1,其二进制(补码)为11111111(即0xff),转换成int型,值也应该为-1,但经过补位后,得到的二进制为11111111111111111111111111111111(即0xffffffff),这就不是-1了,对吧?
而0xff默认是int型,所以,一个byte跟0xff相与,会先将那个byte转化成int型运算,这样,结果中的高位3个字节就总会被清0。