论文阅读_大模型_ToolLLM
英文名称: ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
中文名称: TOOLLLM:帮助大语言模型掌握16000多个真实世界的API
文章: http://arxiv.org/abs/2307.16789
代码: https://github.com/OpenBMB/ToolBench
作者: Yujia Qin
日期: 2023-07-31
1 读后感
论文致力于让大模型学习使用工具,以实现复杂的任务。目前使用工具能力最强的还是 ChatGPT,但不清楚它是如何实现的。文中提出的 ToolLLM 主要用于构建针对 引导调优(instruction-tuning)的训练数据集 ToolBench ,最终通过数据对开源的LLaMA调优,训练的模型ToolLLaMA,对工具的使用能力与 ChatGPT 相当。
为了使路径搜索过程更加高效,提出了基于深度优先搜索的决策树(depth-first search-based decision tree:DFSDT);训练了 API 检索器来为每条指令推荐适当的 API。
最终发布了用于评价的工具 ToolEval,以及使用 ToolBench 调优的模型 ToolLLaMA,可支持复杂的引导和没见过的 API。优化了通过大模型与调用 API 的协作,生成最终答案的功能。
2 介绍
对于大模型和工具协作问题,之前工具有以下的局限性:
- 使用有限的非真实或少量的 API 训练
- 受限的场景:只涉及单个工具,未考虑到工具交互关系
- 计划和归因效果差,只使用提示方式,难以处理复杂的指令
- 开源的大模型效果不好
表-1对比了 ToolBench 和之前的数据集:

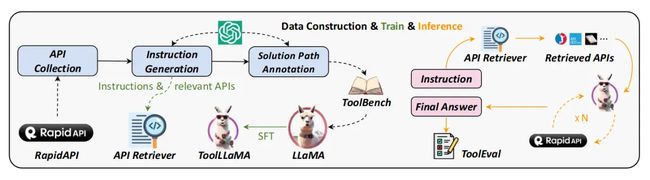
图-1 展示了整体架构设计,左侧为训练,右侧为推理(使用模型预测)。
在训练阶段,首先从 RapidAPI 收集 API,然后利用ChatGPT,一方面生成引导数据,用于训练神经网络的 API Retriever(API 检索器),另一方面实现路径标注,生成引导学习的数据 ToolBench,将数据代入 LLaMA 精调模型生成 ToolLLaMA。
在推理阶段,用户输入指令 Instruction,利用 API Retriever 检索可能调用的 API,然后将这些 API 输入ToolLLaMA模型,ToolLLaMA 执行多轮 API 调用以得出最终答案,最后再由 ToolEval 对结果进行评价。
通过评测,得到以下结论:
- ToolLLaMA 具有处理单工具和复杂多工具指令的能力。它对以前未见过的 API 具有泛化能力,只需要 API 文档即可有效地适应新的 API。ToolLLaMA 在工具使用方面与 ChatGPT 性能相当。
- DFSDT 方法考虑多条路径,可作为增强 LLM 推理能力的通用决策策略。比 ReACT 性能更好。
- 训练 API 检索器神经网络表现出卓越的检索精度,返回的 API 与真实情况密切相关。
3 构造数据
构造 ToolBench 分为以下三个阶段:
3.1 收集API
RapidAPI Hub 是一个 API 市场,提供数千个现实世界的 API,涵盖 49 个不同的类别 categories,如体育、金融和天气等;每个类别又含子类 collections,如中文API、人工智能API、数据库API;总共上万个API。对于每个API,收集其描述、所需参数、API调用的代码片段等。训练 LLM 理解API与文本描述的关系,以便泛化到未见过的API。
在实现过程中需要对 API 进行筛选,丢弃无法实现功能及返回延时过长的 API,最终保留了 3451 个高质量工具,共 16464 个 API。
另外,描述信息可能过长,包含一些冗余信息,这里使用 ChatGPT 对其进行精减,通过输入为工具的文档描述以及所需输出格式的示例,以此将文档压缩在 2048 tokens 之内。
3.2 指令生成
生成高质量的指令需要关注两个关键点:支持工具多样性和多工具协同解决复杂任务。具体方法是从整个集合中采样 API,然后提示 ChatGPT 为这些 API 生成不同的指令。
具体方法是:
为所有 API 及其组合生成指令,将 API 的总集定义为 SAPI,每次从 SAPI 中采样一些 API:Ssub N = {API1, · · ·, APIN};通过提示让 ChatGPT 了解这些 API 的功能及其相互作用,然后生成涉及 Ssub N 中 API 的可能指令 (Inst*),以及每个指令的相关 API (Srel * ⊂ Ssub N ) (Inst*),即{[Srel 1 , Inst1],···,[Srel N′ , InstN′ ]},其中N′表示每次生成实例的数量。用这些指令和相关 API 对训练 API 检索器。
与 ChatGPT 对话时,提示由以下部分组成:
- 指令对应的任务的描述
- Ssub N 中每个 API 的综合文档,
- 三个种子示例,每个种子示例都是由人类专家编写的理想指令。以规范 ChatGPT 的行为。为单工具/多工具分别编写了 12 / 36 个不同的种子示例,每次随机采样三个示例。
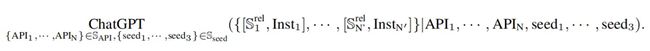
简言之,就是通过 API 描述和种子,生成可能的 API集合S/指令Inst 对。
API组合非常多,由常识可知,多数工具不会组合在一起使用,对于这种稀疏问题,通过 RapidAPI 中的层次过滤出更有效的组合,具体方法是:从同一类别/集合中选择 2-5 个工具,并从每个工具中采样最多 3 个 API 以生成指令。最后又去掉了一些幻觉产生的API,生成数据对:单个工具相关87413个、同类别工具84815个 ,同子类别工具25251个。
3.3 路径标注
路径指的是工具和模型交互的过程,这里涉及多轮与 ChatGPT 的对话。给定指令 Inst*,提示 ChatGPT 搜索有效的操作序列:{a1, ···, aN}。在每个时间步 t,模型根据之前的交互生成一个动作 at,即 ChatGPT(at|{a1, r1, · · · , at−1, rt−1}, Inst*),其中 r* 表示真实的 API 响应。at 的格式如下:“想法:···,API 名称:···,参数:····”。
对于每条指令,将所有采样的 API Ssub N 作为可用函数提供给 ChatGPT,而不是仅将其相关的 API Srel* 提供给 ChatGPT。以访问更广泛的 API 并扩展操作空间。另外,还定义了两个附加函数,即“完成最终答案”和“完成放弃”。
DFSDT
传统的CoT 或 ReACT 对于决策有固有的局限性:(1)错误传播:一步错步步错;(2)有限的探索:CoT或ReACT只探索一种可能的方向,导致对整个动作空间的探索有限,如图所示。因此,即使是 GPT-4 也常常无法找到有效的解决方案路径。
本文提出:基于深度优先搜索的决策树 DFSDT,具体如:图-4所示。
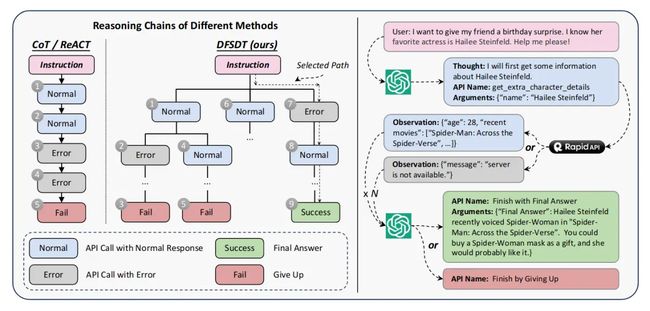
当对于某一条路径搜索失败时,退回上一个节点的其它路径继续搜索。
具体方法使用深度优先搜索(DFS)而不是广度优先搜索(BFS),因为只要找到一条有效路径就可以完成注释,这样花费更少的 token 调用成本。最终,生成 12657 个指令-解决方案对,用于训练 ToolLLaMA。实验证明这个量集的实例已实现了满意的泛化的需要。
4 实验
4.1 TOOLEVAL
评测工具 TOOLEVAL 涉及两个评测标准。
- 通过率(能否找到答案):有限数量的操作(本文中为 200 个)内成功完成指令的比例。计算其百分比视为通过率。另外,还处理了答案是“未找到答案”的"假正例"。
- 优胜率(答案好不好):通过比较两个解决方案路径来测量答案质量。具体方法是:先让人注释人类偏好;对比 ChatGPT 评估器与人类注释者的相关性高达 75.8%,因此可将其作为可信评估器。且当对同一指令进行多次注释时,该评估结果比人类更加一致。
4.2 初步实验
4.2.1 API 检索器
API 检索器通过 Sentence-BERT 实现,模型将指令和 API 文档分别编码为两个嵌入,然后计算两个嵌入的相关性,以训练模型。
对比文中方法与 BM25,以及ChatGPT 提供的文本Embedding,文中方法明显更好(毕竟它是通过有监督数据训练过的模型),当然应用时效果也会更好。

4.2.2 对比 DFSDT 和 ReACT
对比 DFSDT 和 ReACT 的通过率,其中还加入了比较多次 ReACT@N 的操作。几个实验都证明 DFSDT 更好,尤其在相对复杂的场景中,DFSDT 对性能改进更明显。

4.3 主实验
使用指令-解决方案对 LLaMA 7B 模型进行调优,得到模型 ToolLLaMA。对比其它模型结果如下:

- 这里表现最好的是 ChatGPT-DFSDT,也就是训练本文中模型的老师模型,这很正常,而且证明了 DFSDT 的有效性;
- 文中模型明显优于其它方法,通过率略低于其老师模型,优胜率相似,这证明了可以通过调优本地模型替代 ChatGPT 的可行性。
- Vicuna 和 Alpaca 是 LLaMA 的自然语言精调版本,实验证明它无法支持工具预测。
消融实验

这里对比文中几种方法各自对模型的影响:
- 用 API 检索器推荐的 API 替换真实 API,模型效果略有降低,说明重要的 API 基本都被检索器识别到了。
- 将推理方法从 DFSDT 降级为 ReACT,效果明显降低;主实验也证明了 DFSDT 的重要性。这也说明,使用一些外部的方法也能提升模型性能。
- 使用 LoRA 作为增补模型以替代全模型调参,效果略有降低。
5 启发
5.1 大模型
- 大模型分成:理解力,知识力
- 在调优模型之外,可有很多方法提升模型效果
- 利用工具调优的网络,可实现更复杂的功能
- 目前多数网络学习决策能力,外接网络,实现分类回归;文中学习生成能力,推荐一系列操作。
- 证明了本地模型替代 ChatGPT 的解决方案,可以泛化到其它定制功能。
- 用 ChatGPT构造各种训练数据,评测……
5.2 具体工作
- 先用工具自动给Code写说明文档
- 学习本地 API(不是开放域):Android的,自己的程序,用 ChatGPT 建立相关引导
- 不一定每次都调模型,2/8原则中的大部分功能有稳定的路径,用 Sentence-BERT可能又快又好地解决大部分问题。
- ToolBench 开源了训练数据集,可以直接用。
- 至少可以把文中功能作为代码生成器使用,选择 API 用。
- 使用工具也有多个层级:使用什么API/组合完成任务,代码具体怎么写。
- API 检索器 可以做,(机器看有什么工具可以使用),应该比普通的 code 生成器好用。
- DFSDT 有效解决了一步错步步错的问题。
- 也是一大模型加一小模型的结构,用的是 Sentence-BERT。
- 有效利用了数据中的层级,一步一步定位这个方法很好,不是把所有数据喂进去。
5.3 其它想法
- 我们要做的是工具/平台,不是具体代码,支持后面更多功能插进来。
- 在指令生成部分,反向用 ChatGPT,这个挺有意思的