YMIR-从源代码部署到页面实操
YMIR是一个无代码即可实现视觉AI任务的一站式模型生产和部署平台,新颖的理念、完善的教程、不错的结果驱使我对该平台进行了试用。这篇文档详细记录了从github上的官方源码到GUI界面的部署步骤并展示了使用该平台便捷地同时进行多种动物(羊、马、猫等)检测的过程。
Part 1. YMIR部署
写在前头:整个部署流程可以参考官方资料YMIR-github和YMIR部署教程,前者有介绍YMIR所需的软硬件环境和部署过程,后者则是部署的视频教程。
下面介绍我部署YMIR的过程(GPU版本)、遇到的一些报错及解决方法。
Step 1. 环境准备
根据官方文档介绍,部署YMIR需要:
1)docker-compose >= 1.29.2,docker >= 20.10
2)NVIDIA GeForce RTX 2080 Ti 或更高版本
3)主机支持的最大 CUDA 版本 >= 11.2
不具备以上三项的小伙伴可在浏览器搜索对应安装教程和使用符合要求的服务器。推荐docker和docker-compose安装教程,安装时注意版本要求!以下是我安装时遇到的一些报错和解决方案,可供参考:
1)安装docker-compose时报错: “fatal error: Python.h: No such file or directory”
解决方案:https://www.cnblogs.com/qq952693358/p/9170638.html
2)成功安装docker-compose后,仍报错“command not found”
解决方案:https://blog.csdn.net/u014229742/article/details/103314774
Step 2. 源码克隆
登录本地服务器后,在命令行键入下方命令克隆YMIR的源码到本地:
git clone https://github.com/IndustryEssentials/ymir.git
Step 3. 配置参数
修改.env文件中第31行和第32行的参数分别指定当前部署label free标注平台的IP地址和端口:
LABEL_TOOL_HOST_IP=set_your_label_tool_HOST_IP
LABEL_TOOL_HOST_PORT=set_your_label_tool_HOST_PORT
另外,通过修改.env文件第6行的NGINX_PORT可以指定登录YIMIR GUI界面的端口
Step 4. 正式部署
输入以下命令进行YMIR的正式部署:
bash ymir.sh start
部署时出现选择标注工具的提示,我们选择2. Label Free即可:

标注工具选择
部署过程中出现如下关于拉取镜像超时的报错:

部署中的超时报错
解决方案:https://blog.csdn.net/qq_43479628/article/details/113756473

部署完成
在浏览器输入“本地服务器IP:.env文件中NGINX_PORT/login”(如“123.456.789.10:2222/login”)进入YMIR的GUI界面,可直接注册

可以修改或直接使用.env文件下对应的管理员用户名和密码登录平台:
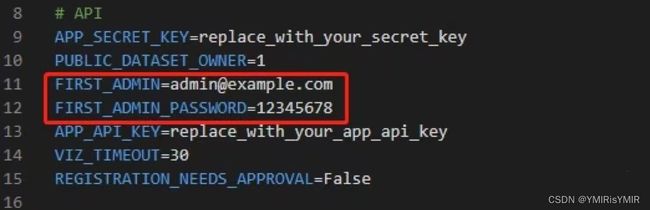
.env中的管理员登录信息
Part 2. YMIR使用
Step 1. 项目创建:
训练类别输入想要检测的物体,比如我希望检测动物:bird, cat, cow, dog, horse, sheep

Step 2. 数据集创建
本次实验使用VOC2007数据集,导入时注意按照平台要求预先组织文件夹下的内容

本地创建的数据集
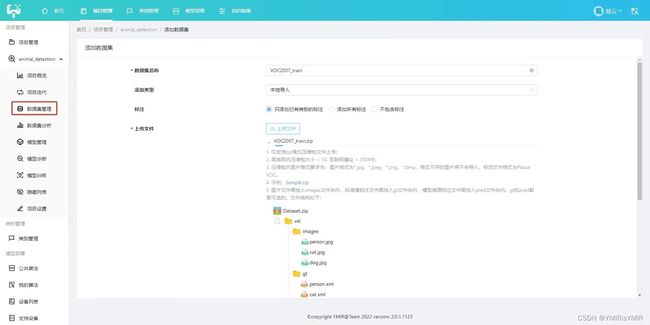
根据格式要求导入数据集
Step 3. 模型训练
选择上传好的训练集和验证集,根据自己希望使用的模型选择对应的训练镜像,如有需要的话也可以按需修改超参数。如此处我选择的是yolov7模型对应的镜像进行训练,使用默认超参数:

模型训练的参数配置

在本地服务器可看到GPU正在被用于训练
训练完成
Step 4 . 模型推理和验证
训练完成后,可以在 模型管理 条目下使用模型的验证和推理功能:

(1)模型推理
可以对整个选定的测试集用所训练的模型进行推理:

推理配置

推理完成
(2)模型验证
也可以方便地直接对指定的图片进行验证,输出结果图像:
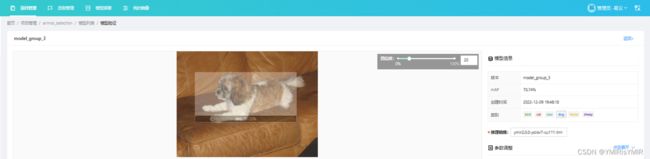

多物体、多类别的检测结果也不错
Part 3. 其他功能
YMIR平台还提供了许多其他实用的功能模块,包括
1. 数据集分析
可以给出指定数据集的整体信息和分布信息,使用者可以方便、清晰地了解到数据集的情况,可指导后续数据集的优化。
2. 数据挖掘和模型迭代
对于结果有更高要求的项目,YMIR提供了一套模型迭代流程
1)数据挖掘:YMIR的数据挖掘功能在给定的数据集中挖掘有利于模型训练的数据,用户可以使用平台工具对于挖掘出来的数据方便地进行标注
2)数据集合并:可以将挖掘到的数据合并到现有的训练集中
3)模型训练:由上一步训练的模型作为初始化模型,使用更新后的数据集,重新训练模型
4)模型迭代:重复上述三步可以不断扩充数据集、训练得到更好的模型
3. 模型部署和发布
YMIR还支持将模型一键部署到指定硬件设备和发布到公共算法库,解决实际应用问题和充实社区资源。
4. 其他隐藏的优秀功能...
