基于yolov5模型的目标检测蒸馏(LD+KD)
文章目录
- 前言
- 一、Distillation理解
-
- 1、Knowlege distillation
- 2、Feature distillation
- 3、Location distillation
- 4、其它蒸馏
- 二、yolov5蒸馏模型构建
-
- 1、构建teacher预测模型
- 2、构建蒸馏loss
- 3、蒸馏模型代码图示
-
- 模型初始化
- 模型蒸馏
- 三、蒸馏模型实验
-
- 1、工程数据测试
- 2、voc2012开源数据测试
前言
最近在看有关蒸馏(Distillation)相关的内容,也就是需要大量的计算资源及庞大的数据集去支撑大模型,以蒸馏方式转为小模型,加速推理时间与降低模型内存,有利于部署。为此,我基于yolov5模型框架,修改代码,构建一个LD+KD的蒸馏模型,并公开源码于github,供读者学习。同时,我也正在构建多头蒸馏,后期将公开源码与文章解读。
源码链接:点击这里
一、Distillation理解
蒸馏是模型压缩方法,是通过教师模型知识传授学生模型的方法。一般教师模型是较大模型,效果较好,学生模型是较小模型,直接训练效果较差,
使用蒸馏模型传授教师知识,帮助提高学生模型性能。
1、Knowlege distillation
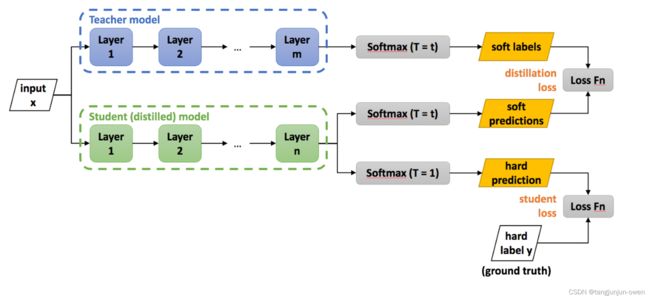
知识蒸馏(Knowledge Distillation,简记为 KD)是一种经典的模型压缩方法,分类模型论文较多,实际是蒸馏类型信息,通过teacher模型给出软标签给学生更多信息。如下图示意:
2、Feature distillation
特征蒸馏也是一种经典的模型压缩方法,实际是特征图的知识传递,通过teacher模型给出特征图给学生更多特征提取约束或信息量。如下图示意:

3、Location distillation
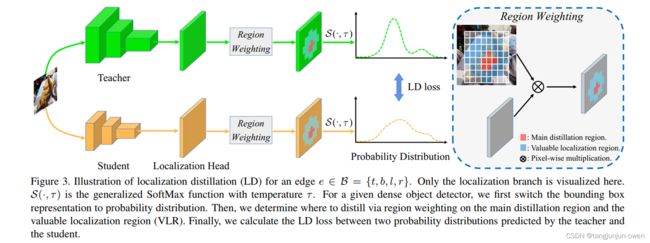
位置蒸馏也是一种经典的模型压缩方法,实际是位置点(如box)的知识传递,通过teacher模型给出预测位置给学生位置信息。该方法学术不多,比较新,如下图示意:
4、其它蒸馏
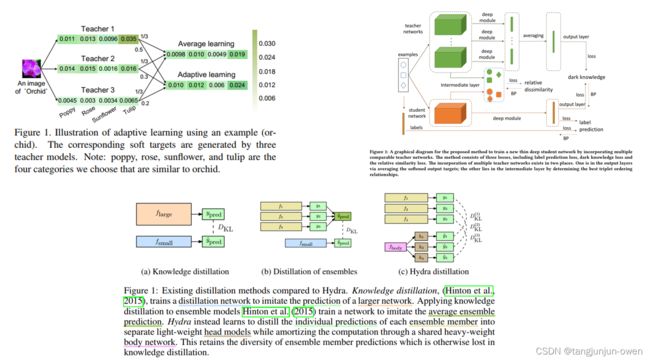
也有很多其它蒸馏方式,如通道蒸馏、无监督、对比等蒸馏方式,或最近bert蒸馏等。当然,介于我后期会出多头蒸馏文章,我引入论文图,如下:
二、yolov5蒸馏模型构建
我是基于yolov5模型蒸馏的,教师模型使用大尺寸模型m,学生模型使用小尺寸模型s。同时,我修改源码构建蒸馏模型结构,接下来我介绍如何构建基于yolov5模型构建蒸馏模型。其结构如下:

1、构建teacher预测模型
yolov5只需使用训练后的best.pt文件,通过attempt_load即可加载完预测模型初始化,至于attempt_load函数解析,相信很多博客已有说明,我不在解释,其teacher模型构建如下:
def create_teacher_model(weights,device):
# device = torch.device('cuda:0')
model=attempt_load(weights, map_location=device).eval()
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
teacher_model={'model':model,
'stride':stride,
'names':names
}
return teacher_model
2、构建蒸馏loss
我基于yolov5模型构建LD+KD的蒸馏方式,借用yolov5原始模型loss计算方法,teacher模型输出为类的一个序列作为target类别,而原始yolov5模型
gt的target为类别数字非序列。为此,我们修改类别表示方式,使用序列替换数字,该位置在build_targets函数中,我做了大量修改,也将对应解释写在对应代码
中,其详情如下代码:
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image_id,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # 每个点anchor数量(3), targets(每个batch中的标签个数)
tcls, tbox, indices, anch ,tconf = [], [], [], [], [] # tcls表示类别,tbox表示box的坐标(x,y,w,h),indices表示图像索引,anch表示选取的anchor的索引
gain = torch.ones(targets.shape[-1]+1, device=targets.device) # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # [na,nt] same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
# targets[image_id,x,y,w,h,conf,...cls,anchor_id]
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl): # 循环3个特征层
anchors, shape = self.anchors[i], p[i].shape
gain[1:5] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain # shape(3,n,7),在特征图中恢复gt尺寸,[img_id,x,y,w,h,conf,...cls,anchor_id]
if nt:
# Matches,选择正负样本方法,通过gt与anchor的wh比列筛选
r = t[..., 3:5] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter,通过筛除后获得正样本
# Offsets 获取选择完成的box的*中心点*坐标-gxy(以图像左上角为坐标原点),并转换为以特征图右下角为坐标原点的坐标-gxi
gxy = t[:, 1:3] # grid xy
gxi = gain[[1, 2]] - gxy # inverse 特征图右下角为坐标原点
# 分别判断box的(x,y)坐标是否大于1,并距离网格左上角的距离(准确的说是y距离网格上边或x距离网格左边的距离)小于0.5,
# 如果(x,y)中满足上述两个条件,则选中.gxy.shape=[182,2],包含x,y,所以判别后转置得到j,k,2个结果
# 对转换之后的box的(x,y)坐标分别进行判断是否大于1,并距离网格右下角的距离(准确的说是y距离网格下边或x距离网格右边的距离)距离小于0.5,
# 如果(x,y)中满足上述两个条件,为Ture,
j, k = ((gxy % 1 < g) & (gxy > 1)).T # gxy>1,以左上角为坐标原点,表示排除上边与左边边缘格子
l, m = ((gxi % 1 < g) & (gxi > 1)).T # gxi>1同理,以右下角为坐标原点,排除右边与下边边缘格子
j = torch.stack((torch.ones_like(j), j, k, l, m)) # 第一行为自己本身正样本值
t = t.repeat((5, 1, 1))[j] # 根据j挑选正样本,但未移动相邻网格
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # 根据j处理对应正样本偏置(确定移动相邻网格)
else:
t = targets[0]
offsets = 0
# Define b=img_id,c=[...cls],conf=conf-->预测置信度 gxy=grid xy, gwh=grid wh, a=anchors_id
b=t[:,0].long()
c=t[:,6:-1]
conf=t[:,5]
gxy= t[:,1:3]
gwh=t[:,3:5]
a=t[:,-1].long()
gij = (gxy - offsets).long() # xy与offsets对应
gi, gj = gij.T # grid indices
# Append
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image_id, anchor_id,与网格坐标grid_x,grid_y
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box 获取(x,y)相对于网格点的偏置,以及box的宽高
anch.append(anchors[a]) # anchors 获得对应的anchor
tcls.append(c) # class 获得对应类别
tconf.append(conf)
return tcls, tbox, indices, anch,tconf
同时,我们也修改计算类别loss位置的one shot方式,yolov5原模型的target为数字需要转换one shot编码,而teacher模型给的target本身为序列标签,无需转换,因此修改内容如下:
原代码:
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp # 这里将其one-short编码-->也说明类从0开始
lcls += self.BCEcls(ps[:, 5:], t) # BCE
修改代码:
lcls += self.BCEcls(ps[:, 5:], tcls[i]) # BCE
3、蒸馏模型代码图示
模型初始化
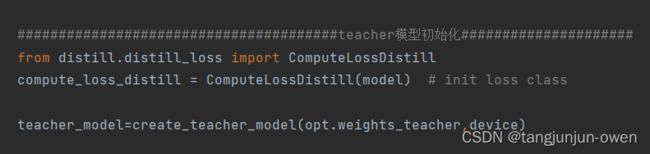
模型与loss的初始化,如下图示:
模型蒸馏
学生模型硬标签loss计算、teacher-student的软标签loss计算,如此实现yolov5的KD+LD蒸馏方式,如下图示列:
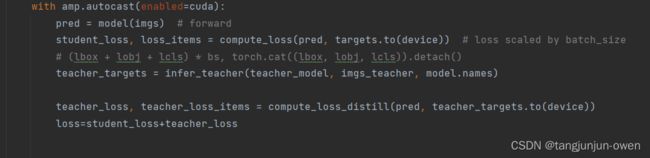
三、蒸馏模型实验
1、工程数据测试
教师模型使用yolov5m模型-学生与蒸馏模型使用yolov5s模型,测试结果如下:

PR曲线图:
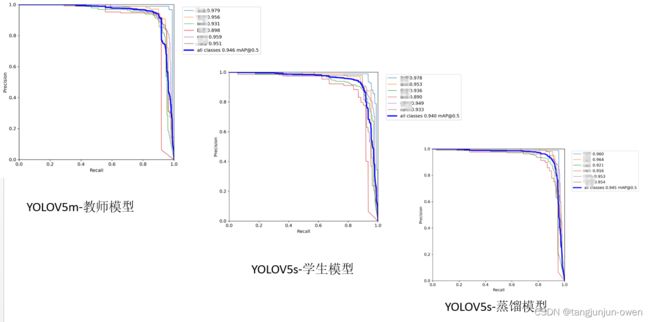
map0.5与map0.5:0.95均比学生模型高一点点。
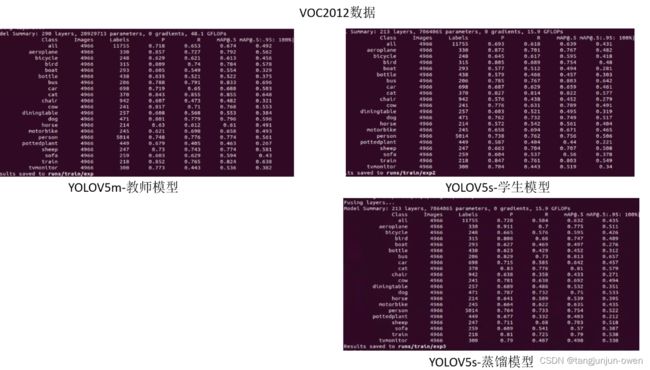
2、voc2012开源数据测试
进一步实验测试,采用开源数据测试。
教师模型使用yolov5m模型-学生与蒸馏模型使用yolov5s模型,测试结果如下:
PR曲线图:
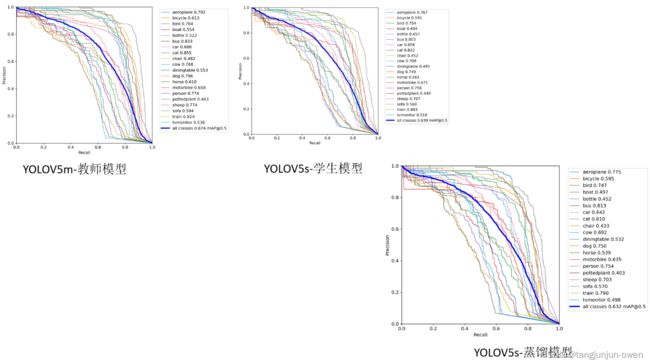
蒸馏模型在map0.5表现较差0.007个点,但map0.5:0.95却高了0.004个点。