python爬虫自学习1+京东商品爬取实例
自学习笔记
- 序
- 安装第三方库
- request 库
-
- 使用方法
- 实例爬取
- HTML内容解析——Beautiful Soup 库
-
- BeautifulSoup类的基本元素
- 基于bs4库的HTML内容遍历方法
- bs4库的prettify()方法
- 实例练习(re+BeautifulSoup+requests)
序
注:本文为自己学习感兴趣内容所做笔记,文中由大量图片构成,因为我是从mooc学的,懒得浪费时间去写那么多文字,用图片记录
最近突然觉得有必要学一下python,翻开大一的Python书发现忘的那是一干二净,想学一下爬虫,只好重头再来,找了个教程一看啥都看不懂,还是老老实实从零开始吧。
安装第三方库
爬虫有一个库叫 requests 说出来不怕丢人我好像连安装第三方库都不会,算了一步一步来
打开 cmd ,因为我的Python是装在D盘的,哪怕以前学过,我还是忘得一干二净

按照图片操作即可得到想安装的第三方库
request 库
使用方法
request的respance对象的属性

request库六种连接异常

response提供了一种异常处理方法

爬取网页的通用代码框架
可以使用异常处理避免程序的崩溃
import requests
def getHTMLText(url):
try:
r = request.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Error"
if __name__ == "__main___":
url = "http://www.baidu.com"
print(getHTMLText(url))
request库的主要方法

- request 方法对应三个参数
requests.request(method, url, **kwargs)
method: 请求方式,对应 get/put/post 等7种

url: 拟获取页面的url连接
**kwargs: 控制访问的参数,共13个
1)params: 字典或字节序列,作为参数增加到url中,(通过这个参数加到url,服务器可以接受参数作为筛选)
2)data: 字典、字节序列或文件对象,作为Request的内容
3)json: JSON格式的数据
4)headers: 字典,HTTP定制头(可以用该字段访问HTTP url协议的头)(可以模拟浏览器发起访问)
5)cookies: 字典或CookieJar, Reques中的cookie
6)auth: 元组,支持HTTP认证功能
7)files: 字典类型,传输文件
8)timeout: 设定超时时间,秒
9)proxies: 字典类型,设定访问代理服务器,可以增加登录认证(可以隐藏服务器IP)
10)allow_redirects: True/False, 默认为True,重定向开关
11)stream: True/False,默认为True,获取内容立即下载开关
12)verify: True/False, 默认为True,认证ssl证书开关
13)cert本地SSL证书路径
HTTP对资源的操作方法

实例爬取
- 1>爬取京东商品链接
import requests
url = "https://item.jd.com/100027042714.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[0:1000])
except:
print("Error")
- 2>爬取亚马逊商品
import requests
url = "https://www.amazon.cn/dp/B09H1ZKJLX/ref=s9_acsd_al_bw_c2_x_1_i?pf_rd_m=A1U5RCOVU0NYF2&pf_rd_s=merchandised-search-2&pf_rd_r=1XFNK1ZGT2F7VJJ77XJT&pf_rd_t=101&pf_rd_p=1a2a7e12-3362-49bf-9ac6-cc9c4bb4bb49&pf_rd_i=116169071"
try:
kv = {'User-Agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent.encoding
print(r.text[0:1000])
except:
print("Error")
- 3>进行关键字爬取
import requests
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get("htpp://www.baidu.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(r.text[0:1000])
except:
print("Error")
- 4>图片爬取
import requests
import os
url = "http://img0.dili360.com/pic/2021/10/18/616d2709639fa7g80607553_t.jpg@!rw9"
root = "D://code//python//spider//test"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("成功")
else:
print("已存在")
except:
print("失败")
可以看到爬取结果时成功的
HTML内容解析——Beautiful Soup 库
这里有一篇写的很详细的文章,我就是参考他的文章
首先安装"beautifulsoup4"库,在cmd中运行pip install beautifulsoup4
安装完成之后来个小测试,演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
import requests
from bs4 import BeautifulSoup
r= requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print(soup.prettify())
来看看运行效果
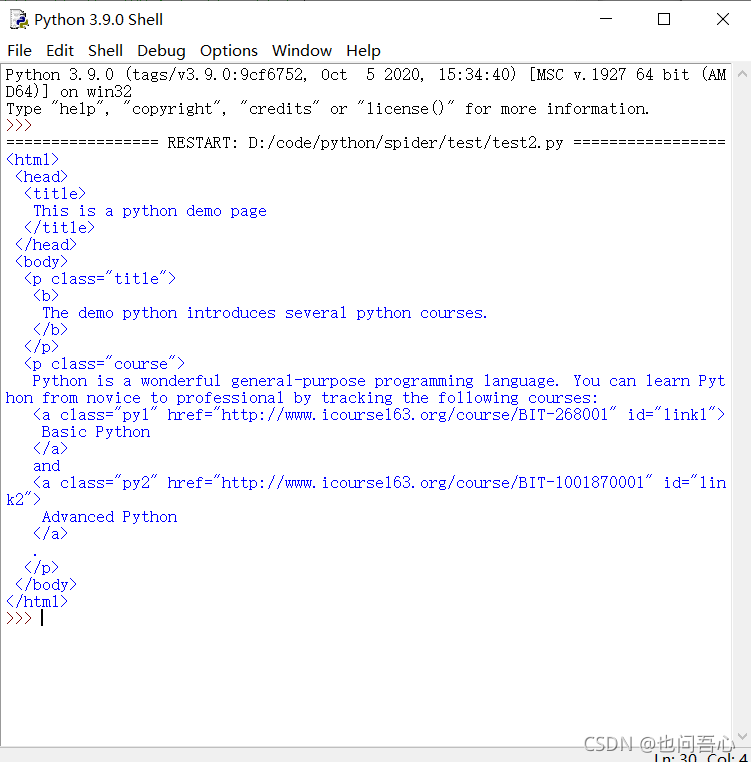
BeautifulSoup类的基本元素

然后来看看BeautifulSoup类基本元素使用
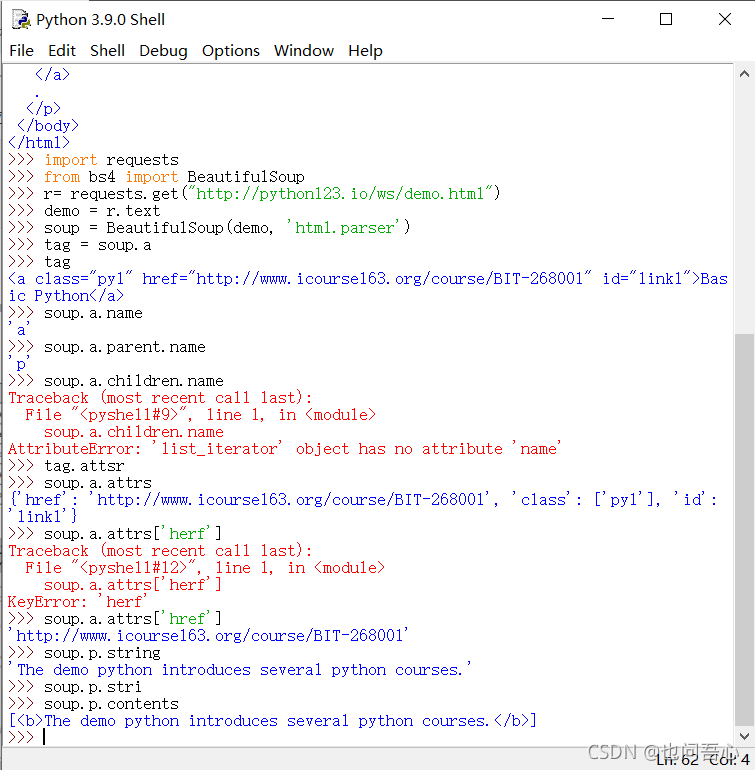
基于bs4库的HTML内容遍历方法
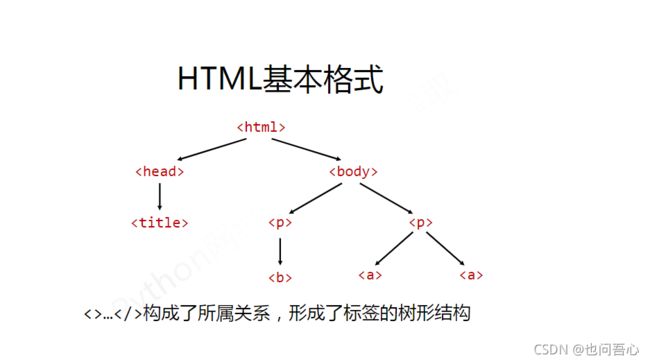
这张图很清晰的解释了HTML里面的标签树关系,各种所属关系,你可以采用下行遍历访问某标签的子标签,上行遍历访问父标签,以及平行遍历访问同属一个父类的标签
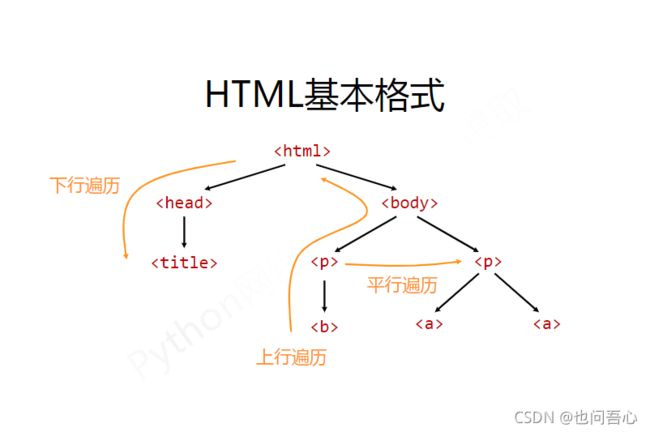
标签树的下行遍历

其中children 和 descendants 都是用在循环遍历中,来看看运行情况

标签树上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈的迭代类型,用于循环遍历先辈节点 |
同上
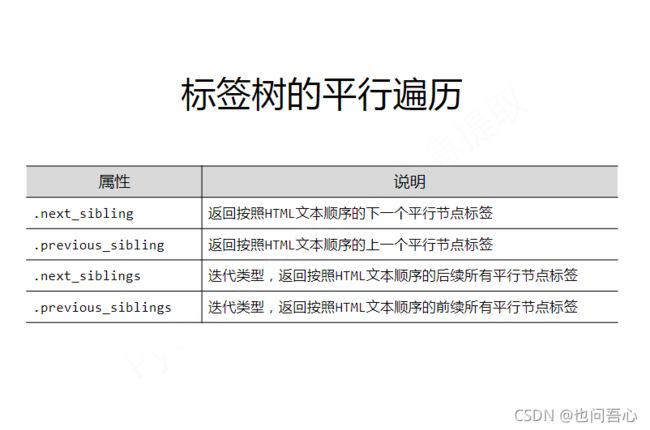
标签树的平行遍历
bs4库的prettify()方法
( 2021/11/11更新)
实例练习(re+BeautifulSoup+requests)
- 简单实例:爬取京东商品名称与价格
本来我是跟着教程去爬取淘宝的商品的,自己手动试了一下发现淘宝在查看商品居然要登陆?我不知道这是不是爬取不成功的原因,但是京东不用登陆,所以我换成了京东,经过自己一天的摸索,终于还是成功了,有点小瑕疵,但是问题不大,稍微调整一下就可以了。
首先是代码与结果
import requests
import re
from bs4 import BeautifulSoup
KEYWORD = '手机'
url = 'https://search.jd.com/Search?keyword='+KEYWORD
headers_kv = {'User-Agent':'Mozilla/5.0'}
def getHTML(url):
try:
responce = requests.get(url, timeout=30, headers=headers_kv)
responce.raise_for_status()
responce.encoding = responce.apparent_encoding
return responce.text
except:
print("Get HTML wrong!")
def dealHTML(goodslist,html):
try:
soup = BeautifulSoup(html, 'html.parser')
price_list = soup.select('div .p-price')
name_list = soup.select('div .p-name')
for i in range(len(price_list)):
splitprice = price_list[i].get_text()
price = re.split('\n',splitprice)
name = name_list[i].em.get_text()
goodslist.append([name,price[2]])
except:
print("Deal HTML wrong")
def OUTPUTgoods(goodslist):
try:
count = 0
tplt = "{:4}\t{:120}\t{:8}"
print(tplt.format("序号","商品名称","价格"))
for g in goodslist:
count = count+1
print(tplt.format(count,g[0],g[1]))
except:
print("output wrong")
def main():
page=4
for i in range(1,page+1):
start_url = url+ '&enc=utf-8&page=' +str(i)
try:
goodslist = []
html=getHTML(start_url)
dealHTML(goodslist,html)
except:
print("wrong")
OUTPUTgoods(goodslist)
main()
以及爬取结果:这是我用jupyter notebook写的代码爬取结果

可以看到除了显示部分有点小瑕疵(这是我学艺不精导致的)
然后是代码解析:
我一共定义了四个函数:获取网页信息的函数,解析网页信息的函数,处理输出信息的函数以及主函数;而在每个函数我都采用了python错误处理方法,防止崩掉,但是这个小的代码片段是可以不用的
- getHTML 函数
responce = requests.get(url, timeout=30, headers=headers_kv)
responce.raise_for_status()
responce.encoding = responce.apparent_encoding
return responce.text
用requests库里面获取网页信息,最值得注意的是,在这里你应该伪装一下免得让网页认出你是一个爬虫程序,那么就用requests.get()函数里面的herders属性,headers_kv = {'User-Agent':'Mozilla/5.0'},这样就伪装成了浏览器的访问;然后使用responce.raise_for_status()语句,如果成功返回requests.get()的responce对象的话raise_for_starus()返回值是正常的200,否则返回一个错误值,程序就执行不成功
- dealHTML函数
soup = BeautifulSoup(html, 'html.parser')
price_list = soup.select('div .p-price')
name_list = soup.select('div .p-name')
for i in range(len(price_list)):
splitprice = price_list[i].get_text()
price = re.split('\n',splitprice)
name = name_list[i].em.get_text()
goodslist.append([name,price[2]])
首先打开网页源代码进行分析
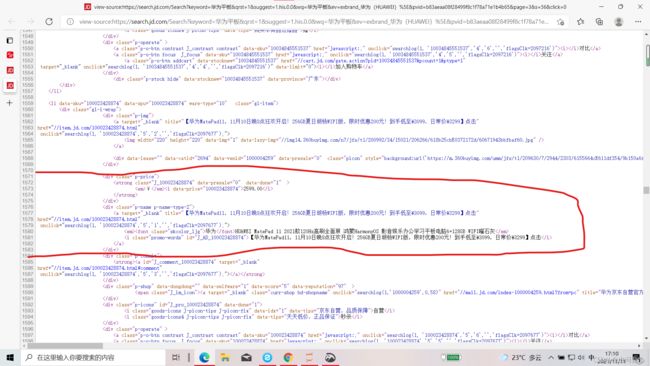
仔细分析你就会发现,商品的名称和价格都是封装在一个名为’div’的tag下面,价格的tag属性为{‘class’:‘p-price’},名称的属性为{‘class’:‘p-name’},那我们就可以根据这两个条件分别将价格和名称提取出来,同时放入一个列表当中储存商品的信息,一开始我用的是BeautifulSoup库的find_all函数,你可以用soup.find_all('div', attrs={'class':'p-price')语句获得商品价格与名称信息将他装入一个List当中,再用List[i].string方法就可以获得div标签下的字符串,但是你仔细观察,名称是封装在div子标签em中的你获取div的字符串会获取除了名称以外的其它信息,你可能会说用div.em.string不就可以了吗?然而事实是:NO由于em标签下还有多个子标签,所以他返回的字符串是不确定,而我在测试当中,返回的是一个空字符串,那要怎样才能获得信息呢?这得提到我前面说的那篇文章,我在里面找到了soup.selece方法,具体使用请看原文:Python中BeautifulSoup库的用法
使用soup.select对应的.get_text()方法就可以获取标签中的内容了
这样我们就可以根据商品信息所在标签的名称以及class类精确获取商品信息了,至于其它的,我用了一点正则表达式将价格字符串里面的空格筛选掉了。
- OUTPUTgoods函数
这个函数只是调用了一下格式化输出而已没有什么好说的,可以自己调一下count 和 输出间隔,让输出更美观。 - 主函数
page=4
for i in range(1,page+1):
start_url = url+ '&enc=utf-8&page=' +str(i)
try:
goodslist = []
html=getHTML(start_url)
dealHTML(goodslist,html)
except:
print("wrong")
OUTPUTgoods(goodslist)
上面的几个函数只能做到获取某一页商品的信息而已,而在京东当中商品页面有好多好多,怎么做到获取后面页面的商品信息呢?自己翻页再把网页复制过来吗?当然不是,我们继续观察网页源代码
![]()
观察源代码的链接可以发现,链接当中存在一个 ‘keywords=华为平板’ 的关键字样,这就是你的检索关键词,改变关键词你就可以爬取自己想要爬取的商品
KEYWORD = '手机'
url = 'https://search.jd.com/Search?keyword='+KEYWORD
这一段代码就可以让我们爬取手机商品,那有怎么做到翻页呢,同样,链接当中有 ‘page=3’ 字样,这是我截取的第三页商品的链接图,那么可以肯定,这个参数就是控制我们访问的是商品的哪一页,构造一个for循环,通过一页一页访问的方式,就可以控制我们想爬取商品的数量了!