【python爬虫】13.吃什么不会胖(爬虫实操练习)
文章目录
- 前言
- 项目实操
-
- 明确目标
- 分析过程
- 代码实现
前言
吃什么不会胖——这是我前段时间在健身时比较关注的话题。
相信很多人,哪怕不健身,也会和我一样注重饮食的健康,在乎自己每天摄入的食物热量。
不过,生活中应该很少有人会专门去统计自己每日摄入的食物热量。显然这样做多少有一些麻烦。可能你得下载一个专门查询热量的APP,填写食物的名字,一个个地去查询。
但其实利用爬虫,我们可以很简单就爬取到这些食物的热量信息,不用费力就能知道自己摄入了多少食物热量。
食物的数量有千千万,如果我们要爬取食物热量的话,这个数据量必然很大。
可能你会想到可以使用多协程来爬取。确实,使用多协程来爬取大量的数据是非常合理且明智的选择。
关于多协程的用法,我们在上一关已经讲过了,这里照旧简单复习一下。

项目实操
说回爬取食物热量的事,如果我们要爬取的话,那就得选定一个有存储食物热量信息的网站才能爬到数据。
我倒是知道一个这样的网站——薄荷网。它是一个跟健身减肥有关,且可以查询食物数据的网站。
我们选取这个网站进行食物热量的爬取的话,既能将上一关学到的协程知识实践起来,又能获得一份食物热量表,还是蛮两全其美的。
那么,我们这一关的项目就可以定为:用多协程爬取薄荷网的食物热量。
你也知道,我们在做一个项目时,不是上来就写代码的,最先要做的是明确目标。
明确目标
现在,请你先用浏览器打开薄荷网的链接:
http://www.boohee.com/food/
打开了吗?一定要真的打开了哦!
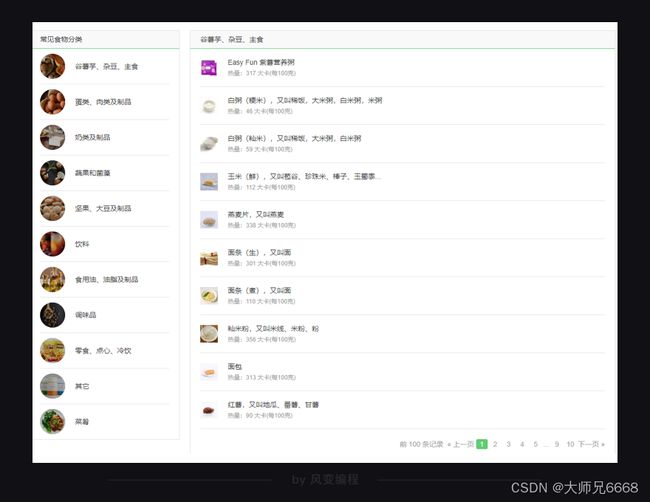
简单浏览一下这个网站,你会发现一共有11个常见食物分类——

点击【谷薯芋、杂豆、主食】这个分类,你会看到在食物分类的右边,有10页食物的记录,包含了这个分类里食物的名字,及其热量信息。点击食物的名字还会跳转到食物的详情页面。
至此,我们的项目目标可以定为:用多协程爬取薄荷网11个常见食物分类里的食物信息(包含食物名、热量、食物详情页面链接)。
分析过程
目标明确好后,我们接着【分析过程】,这一步骤对于项目成功与否起着关键的作用。
我们可以从爬虫四步(获取数据→解析数据→提取数据→存储数据)入手,开始逐一分析。
想要获得食物热量的数据,我们得先判断这些数据具体存在哪里。
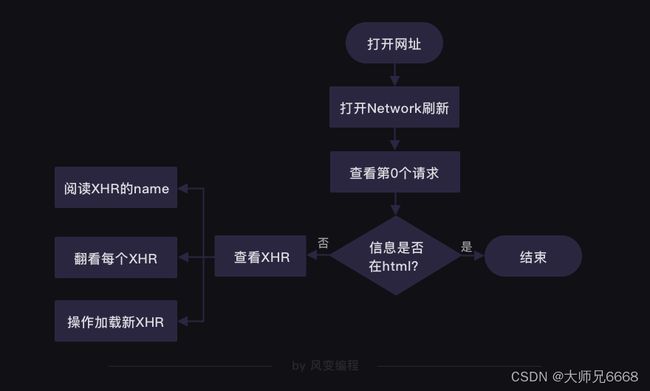
第7关的时候,我们讲过判断数据存储在哪里的方法。请你打开http://www.boohee.com/food/group/1网站,右击打开“检查”工具,并点击Network,然后刷新页面。点击第0个请求1,看Response。

我们能在Response里找到食物的信息,说明我们想要的数据存在HTML里。
再看第0个请求1的Headers,可以发现薄荷网的网页请求方式是get。

知道了请求方式是get,我们就知道可以用requests.get()获取数据。
先关闭“检查”工具。我们接着来观察,每个常见食物分类的网址和每一页食物的网址有何规律。
点击第一个分类【谷薯芋、杂豆、主食】,网址显示的是:
http://www.boohee.com/food/group/1
点击第二个分类【蛋类、肉类及制品】,网址变成:
http://www.boohee.com/food/group/2
我们可以做个猜想:网址的group参数代表着常见食物分类,后面的数字代表着这是第几个类。
只要再多点击几个常见食物分类看看,就能验证我们的猜想。

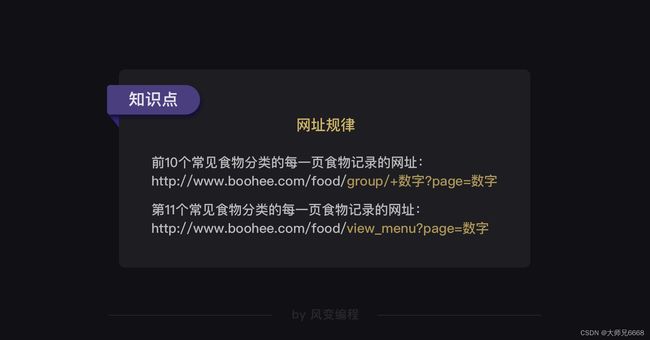
果然,常见食物分类的网址构造是有规律的。前10个常见食物分类的网址都是:
http://www.boohee.com/food/group/+数字
唯独最后一个常见食物分类【菜肴】的网址与其他不同,是:
http://www.boohee.com/food/view_menu
每个常见食物分类网址的规律我们找到了。现在看回【谷薯芋、杂豆、主食】这个分类,点击翻到第2页的食物记录,我们看看网址又会发生怎样的变化。

网址从http://www.boohee.com/food/group/1变成了:
http://www.boohee.com/food/group/1?page=2
网址多了page这个参数。数字2是不是第2页的意思?我们往后再翻两页看看。

原来?page=数字真的是代表页数的意思。只要改变page后面的数字,就能实现翻页。
可是为什么第1页的食物记录的网址在最开始是:
http://www.boohee.com/food/group/1,没有加?page=1呢?
难道是网站默认不显示的?我们试下给http://www.boohee.com/food/group/1加上?page=1,看看会怎样。
http://www.boohee.com/food/group/1?page=1
你会发现,其实加上了?page=1,打开的同样还是第1页的食物记录。
基于我们上面的观察,可以得出薄荷网每个食物类别的每一页食物记录的网址规律——
接下来,我们来分析怎么解析数据和提取数据。
前面我们知道薄荷网的食物热量的数据都存在HTML里,所以等下就可以用BeautifulSoup模块来解析。
至于怎么提取数据,我们得先弄清楚HTML的结构才行。

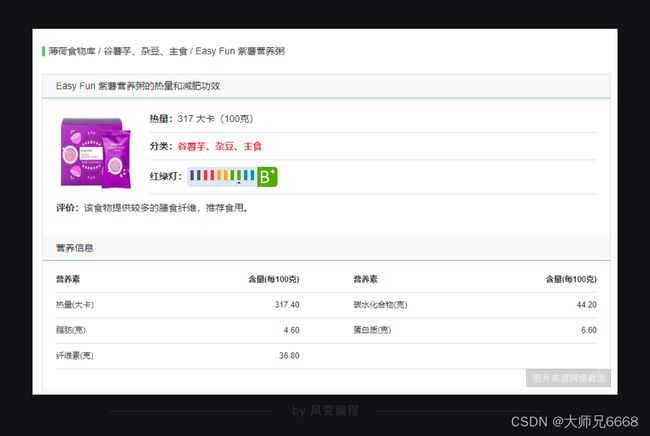
右击打开“检查”工具,看Elements,点击光标,把鼠标移到食物【Easy Fun 紫薯营养粥】这里,会发现在元素下,藏有食物的信息,包括食物详情的链接、食物名和热量。
你点击href=“/shiwu/fdd9b123”,就会跳转到【Easy Fun 紫薯营养粥】的详情页面。
你再把鼠标接着移到其他食物上,你就会发现:原来每个食物的信息都被分别藏在了一个
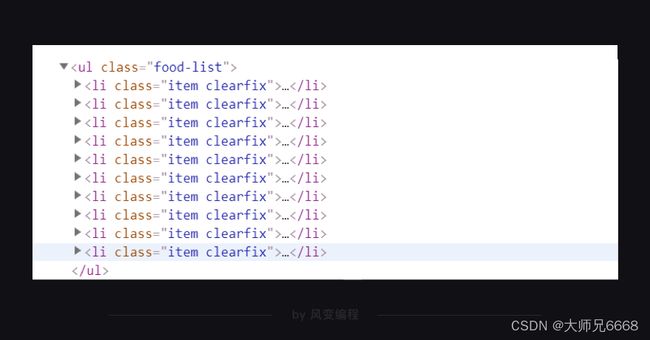
这么看来的话,我们用find_all/find就能提取出
- …
- 标签下的食物详情链接、名称和热量。
提取完数据,我们从csv和openpyxl模块中任意选择使用其中一个模块,把数据存储起来,项目就可以完工啦。
总结一下我们刚刚分析得出的思路:

代码实现
下面,应该是你做项目时最期待的一步——代码实现。
基于前面的【分析过程】,此时我们已经有了实现项目的思路。我们只要把这些思路变成代码,就能完成项目——用多协程爬到薄荷网的食物热量数据。
正式开始写代码~
#导入所需的库和模块: from gevent import monkey monkey.patch_all() #让程序变成异步模式。 import gevent,requests, bs4, csv from gevent.queue import Queue写代码的第一件事,都是先导入我们所需要的库和模块。
根据项目目标和分析过程得出的思路,我们知道需要用到实现协程功能的gevent库、queue、monkey模块,以及requests、BeautifulSoup、csv模块。
接下来的代码,需要由你来写。请你按照要求,先试着写出来,等下我再给你看我写的代码。
代码要求:导入所需模块,并根据前面分析得出的网址规律,用for循环构造出前3个常见食物类别的前3页食物记录的网址和第11个常见食物类别的前3页食物记录的网址,并把这些网址放进队列,打印出来。

参考代码在这里:
#导入所需的库和模块: from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queue work = Queue() #创建队列对象,并赋值给work。 #前3个常见食物分类的前3页的食物记录的网址: url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4): for y in range(1, 4): real_url = url_1.format(type=x, page=y) work.put_nowait(real_url) #通过两个for循环,能设置分类的数字和页数的数字。 #然后,把构造好的网址用put_nowait方法添加进队列里。 #第11个常见食物分类的前3页的食物记录的网址: url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4): real_url = url_2.format(page=x) work.put_nowait(real_url) #通过for循环,能设置第11个常见食物分类的食物的页数。 #然后,把构造好的网址用put_nowait方法添加进队列里。 print(work) #打印队列用Queue()创建了空的队列。通过两个for循环,构造了前3个常见食物分类的前3页的食物记录的网址。
由于第11个常见食物分类的网址比较特殊,要分开构造。然后把构造好的网址用put_nowait方法,都放进队列里。
你可以运行这个代码,把队列打印出来看看。
打印结果:
<Queue queue=deque(['http://www.boohee.com/food/group/1?page=1', 'http://www.boohee.com/food/group/1?page=2', 'http://www.boohee.com/food/group/1?page=3', 'http://www.boohee.com/food/group/2?page=1', 'http://www.boohee.com/food/group/2?page=2', 'http://www.boohee.com/food/group/2?page=3', 'http://www.boohee.com/food/group/3?page=1', 'http://www.boohee.com/food/group/3?page=2', 'http://www.boohee.com/food/group/3?page=3', 'http://www.boohee.com/food/view_menu?page=1', 'http://www.boohee.com/food/view_menu?page=2', 'http://www.boohee.com/food/view_menu?page=3'])>一共打印出了12个网址,分别是【谷薯芋、杂豆、主食】前3页食物记录的网址、【蛋类、肉类及制品】前3页食物记录的网址、【奶类及制品】前3页食物记录的网址和最后一个常见食物分类【菜肴】前3页食物记录的网址。
作为教学演示,我们这里不会真的把薄荷网的11个常见食物分类里的所有页数的食物都爬取下来。因为这样做,会给薄荷网的服务器增添负担,并不是道义的做法,所以我也不推荐你这么去做。
接着,我们要写的是最核心的爬取代码——使用gevent帮我们爬取数据。
你还记得用gevent实现多协程的重点是什么吗?

我们得先定义一个爬取函数。请认真看下面的代码,后面练习环节需要你自己把这些代码都写出来的。def crawler(): #定义crawler函数 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } #添加请求头 while not work.empty(): #当队列不是空的时候,就执行下面的程序。 url = work.get_nowait() #用get_nowait()方法从队列里把刚刚放入的网址提取出来。 res = requests.get(url, headers=headers) #用requests.get获取网页源代码。 bs_res = bs4.BeautifulSoup(res.text, 'html.parser') #用BeautifulSoup解析网页源代码。 foods = bs_res.find_all('li', class_='item clearfix') #用find_all提取出- 标签的内容。
for food in foods: #遍历foods food_name = food.find_all('a')[1]['title'] #用find_all在- 标签下,提取出第2个元素title属性的值,也就是食物名称。
food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href'] #用find_all在- 元素下,提取出第2个元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接。
food_calorie = food.find('p').text #用find在- 标签下,提取
print(food_name) #打印食物的名称。元素,再用text方法留下纯文本,也提取出了食物的热量。
上面定义crawler函数的代码,可能你看到提取数据的部分会有疑惑的点。

不过,对照着看HTML的结构,应该就能解开你的疑惑。我们想要的食物详情链接和名称在标签的第2个元素里,用find_all就能提取出来。食物热量在元素里,我们用find提取就可以。定义完了crawler函数,整个核心代码就差用gevent.spawn()创建任务和用gevent.joinall()执行任务,启动协程,就能开始爬取我们想要的数据。
我希望最后的核心能由你来补全。所以,请你在以上代码的基础上,写出crawler函数和启动协程的代码,完成爬取数据的任务。
顺利写出来了吗?如果没有顺利写出来,我希望你在看完下面的完整代码之后,能再回去重写一遍。
参考代码:
#导入所需的库和模块: from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queue work = Queue() #创建队列对象,并赋值给work。 #前3个常见食物分类的前3页的食物记录的网址: url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4): for y in range(1, 4): real_url = url_1.format(type=x, page=y) work.put_nowait(real_url) #通过两个for循环,能设置分类的数字和页数的数字。 #然后,把构造好的网址用put_nowait添加进队列里。 #第11个常见食物分类的前3页的食物记录的网址: url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4): real_url = url_2.format(page=x) work.put_nowait(real_url) #通过for循环,能设置第11个常见食物分类的食物的页数。 #然后,把构造好的网址用put_nowait添加进队 def crawler(): #定义crawler函数 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } #添加请求头 while not work.empty(): #当队列不是空的时候,就执行下面的程序。 url = work.get_nowait() #用get_nowait()方法从队列里把刚刚放入的网址提取出来。 res = requests.get(url, headers=headers) #用requests.get获取网页源代码。 bs_res = bs4.BeautifulSoup(res.text, 'html.parser') #用BeautifulSoup解析网页源代码。 foods = bs_res.find_all('li', class_='item clearfix') #用find_all提取出- 标签的内容。
for food in foods: #遍历foods food_name = food.find_all('a')[1]['title'] #用find_all在- 标签下,提取出第2个元素title属性的值,也就是食物名称。
food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href'] #用find_all在- 标签下,提取出第2个元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接。
food_calorie = food.find('p').text #用find在- 标签下,提取
print(food_name) #打印食物的名称。 tasks_list = [] #创建空的任务列表 for x in range(5): #相当于创建了5个爬虫 task = gevent.spawn(crawler) #用gevent.spawn()函数创建执行crawler()函数的任务。 tasks_list.append(task) #往任务列表添加任务。 gevent.joinall(tasks_list) #用gevent.joinall方法,启动协程,执行任务列表里的所有任务,让爬虫开始爬取网站。元素,再用text方法留下纯文本,就提取出了食物的热量。
你可以运行这个代码,看看能不能成功爬取到食物的数据。
我运行的结果是:
Easy Fun 营养粉丝(香菇炖鸡),又叫Easy Fun 营养粉丝(香菇炖鸡味) 白粥,又叫白粥(粳米),稀饭,大米粥,白米粥,米粥,大米汤汤 Easy Fun 营养粉丝(番茄鸡蛋),又叫Easy Fun 营养粉丝(番茄鸡蛋味) Easy Fun 低脂咖喱鸡饭 Easy Fun 抹茶红豆麦片 Easy Fun 高蛋白微波蛋糕预拌粉(香浓可可味) Easy Fun 红枣黑米圈,又叫红枣黑米、Easy Fun 薄荷健康红枣黑米圈 Easy Fun 山药紫薯圈 稀饭,又叫白粥(籼米),大米粥,白米粥 鲜玉米,又叫玉米(鲜)、苞谷、珍珠米、棒子、玉蜀黍、苞米、六谷、 虾,又叫对虾、鲜虾仁、虾仁 鸭肉,又叫鸭子、鹜肉、家凫肉 猪蹄,又叫猪脚、猪手、猪蹄爪 猪肉(瘦),又叫猪精肉,瘦肉 鸡蛋白(鸡蛋清),又叫鸡蛋白、鸡蛋清、蛋清、蛋白 火腿肠 鸡胸肉,又叫鸡柳肉、鸡里脊肉、鸡胸、鸡胸脯肉 荷包蛋(油煎),又叫荷包蛋、煎蛋、煎荷包蛋、煎鸡蛋 咸鸭蛋,又叫盐蛋、腌蛋、味蛋 猪肉(肥瘦),又叫豕肉、彘肉 Easy Fun 高纤奇亚籽苏打饼干,又叫Easy Fun 高纤 奇亚籽苏打饼干、奇亚籽苏打咸味饼干、苏打饼干、EASY FUN 苏打饼干、Easy Ace 高纤奇亚籽苏打饼干 白薯,又叫山芋、红皮山芋,地瓜、甘薯、红皮山芋 大米,又叫稻米、米、生米 全麦面包,又叫全麦面包、全麦吐司、全麦面包片、全麦土司 烙饼 花卷,又叫花之卷、大花卷、小花卷 油条,又叫小油条 曼可顿 全麦高纤维面包 嘉顿 生命面包 450g 包子(三鲜馅) 燕麦片,又叫燕麦 面条(生),又叫面 煮面条,又叫面、水煮面、面条(煮) 籼米粉,又叫米线、米粉、粉、排米粉 面包 红薯,又叫地瓜、番薯、甘薯、山芋、红薯 小米粥 马铃薯,又叫土豆、洋芋、地蛋、山药蛋、洋番薯、土豆、洋芋 包子(猪肉馅) 米饭,又叫大米饭,饭,蒸米、锅巴饭、煮米饭 Easy Fun 高蛋白小酥鱼(藤椒味) 鸡蛋,又叫鸡子、鸡卵、蛋 Easy Fun 低脂鸡胸肉肠(香辣味),又叫Easy Fun easy fun 低脂鸡胸肉肠、鸡胸肉肠 Easy Fun 鸡胸肉丝(原味) Easy Fun 高蛋白小酥鱼(海苔味),又叫Easy Fun 高蛋白海苔鱼酥 Easy Fun 低脂鸡胸肉肠(原味),又叫Easy Fun 低脂鸡胸肉肠、鸡胸肉肠、easyfun 低脂鸡胸肉肠 猪小排,又叫排骨、猪排、猪脊骨 鸡(土鸡,家养) 鸡(母鸡,一年内) 鸡(肉鸡,肥) 瓦罐鸡汤(含料),又叫瓦罐汤 瓦罐鸡汤(无料) 猪小排(良杂猪) 猪肉(奶脯),又叫软五花、奶脯、五花肉 猪大排,又叫猪排 牛肉(腑肋),又叫牛腩 Easy Fun 低脂鸡胸肉肠(原味),又叫Easy Fun 低脂鸡胸肉肠(原味)、鸡胸肉肠 Easy Fun 低脂鸡蛋干(五香味) Easy Fun 低脂蛋清鸡肉饼(原味),又叫Easy Fun 低脂蛋清鸡肉饼 草鱼,又叫鲩鱼、混子、草鲩、草包鱼、草根鱼、草青、白鲩 酸奶 牛奶,又叫纯牛奶、牛乳、全脂牛奶 无糖全脂拿铁,又叫拿铁咖啡、拿铁(全脂,无糖) 奶酪,又叫乳酪、芝士、起司、计司 酸奶(中脂) 脱脂奶粉 酸奶(调味) 酸奶(果料),又叫果料酸奶 酸奶(果粒),又叫果粒酸奶 蒙牛 高钙牛奶,又叫蒙牛袋装高钙牛奶 光明 0脂肪 鲜牛奶,又叫光明 0脂肪鲜牛奶 牛奶(强化VA,VD),又叫牛乳(强化VA,VD) 光明 低脂牛奶 蒙牛 木糖醇酸牛奶,又叫蒙牛木糖醇酸奶 低脂奶酪 伊利 无蔗糖酸牛奶(利乐包)150g 蒙牛 酸牛奶(草莓+树莓)100g (小盒装) 光明减脂90%脱脂鲜牛奶 伊利优品嘉人优酪乳(原味) 光明 畅优红枣燕麦低脂酸奶 炒上海青,又叫炒青菜 番茄炒蛋,又叫番茄炒鸡蛋、西红柿炒蛋、柿子炒鸡蛋、番茄炒鸡蛋、西红柿炒鸡蛋、西虹市炒鸡蛋、番茄炒蛋 鸡蛋羹,又叫蒸蛋 绿豆汤 素炒小白菜,又叫小青菜 烧茄子 绿豆粥,又叫绿豆稀饭 菜包子,又叫香菇菜包、菜包子、素包子、素包、香菇青菜包、素菜包、香菇青菜包、香菇包子 蛋炒饭,又叫黄金炒饭、蛋炒饭 红烧鳓鱼 光明 e+益生菌酸牛奶(原味)220ml (袋装) 早餐奶 酸奶(高蛋白) 奶片 全脂牛奶粉 光明 纯牛奶,又叫光明牛奶 光明 优倍 高品质鲜牛奶,又叫光明 优倍高品质鲜牛奶 光明 优倍 0脂肪 高品质脱脂鲜牛奶 光明 优倍 0乳糖 巴士杀菌调制乳 光明 致优 全鲜乳,又叫光明 致优全鲜乳 盐水虾,又叫焖鲜虾 清炒绿豆芽,又叫有机活体豆苗、炒绿豆芽 葱油饼,又叫葱花饼、葱油饼 清炒西葫芦,又叫炒西葫、西葫芦丝 西红柿鸡蛋面,又叫番茄蛋面、番茄鸡蛋面 酸辣土豆丝 红烧肉 韭菜包子 卤蛋,又叫卤鸡蛋 清炒土豆丝 烧麦,又叫烧卖、糯米烧卖 炒大白菜,又叫大白菜 西红柿鸡蛋汤,又叫西红柿蛋汤、西红柿蛋花汤 大饼,又叫饼,家常饼,死面饼 清蒸鱼,又叫清蒸鱼、蒸鱼、鱼、蒸洄鱼 酸菜鱼,又叫酸汤鱼、酸辣鱼、酸菜鱼、酸辣鱼汤 寿司 自制1,又叫寿司卷 麻婆豆腐,又叫麻婆豆腐 牛肉面,又叫兰州拉面、牛腩面、牛肉拌面 烧包菜丝至此,项目的核心代码已经完成,只要再加上存储数据的代码,我们就完成了整个项目的【代码实现】步骤。
我选取了csv模块来做存储数据的演示。
from gevent import monkey monkey.patch_all() import gevent,requests, bs4, csv from gevent.queue import Queue work = Queue() url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4): for y in range(1, 4): real_url = url_1.format(type=x, page=y) work.put_nowait(real_url) url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1,4): real_url = url_2.format(page=x) work.put_nowait(real_url) def crawler(): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } while not work.empty(): url = work.get_nowait() res = requests.get(url, headers=headers) bs_res = bs4.BeautifulSoup(res.text, 'html.parser') foods = bs_res.find_all('li', class_='item clearfix') for food in foods: food_name = food.find_all('a')[1]['title'] food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href'] food_calorie = food.find('p').text writer.writerow([food_name, food_calorie, food_url]) #借助writerow()函数,把提取到的数据:食物名称、食物热量、食物详情链接,写入csv文件。 print(food_name) csv_file= open('boohee.csv', 'w', newline='') #调用open()函数打开csv文件,传入参数:文件名“boohee.csv”、写入模式“w”、newline=''。 writer = csv.writer(csv_file) # 用csv.writer()函数创建一个writer对象。 writer.writerow(['食物', '热量', '链接']) #借助writerow()函数往csv文件里写入文字:食物、热量、链接 tasks_list = [] for x in range(5): task = gevent.spawn(crawler) tasks_list.append(task) gevent.joinall(tasks_list)呼~这一关的项目终于圆满完成!
不知道你在做这次项目时的感受是怎样的?会不会因为看不懂一行代码而苦恼许久,但在代码运行通过时又欣喜雀跃?
我到现在都深深地记得,在我最开始接触编程,写出人生中第一个程序的那种感受——妙不可言又一直萦绕心头的开心。
毫不夸张地说,当我敲下那个程序最后的一行代码,点击运行,看到终端跑出我想要的数据时,我激动地差点跳了起来。
我始终觉得,是在那一刻,编程用它的魅力改变了我,让我有机会成为今天被你看见的我。
如果有机会的话,我也很想听你和我分享,你每一次做项目的感受,不吐不快的话,可以放在评论区
我们下一关见~