浏览器渲染页面的过程——一次完整的HTTP服务:TCP连接建立、发起HTTP请求、keep-alive、重绘,重排
结合具体问题:在浏览器输入一个网址并访问,具体发生了什么?
1. 对这个网址进行DNS域名解析,得到对应的IP地址
DNS怎么找到域名的?
DNS域名解析采用的是递归查询的方式,过程是,先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找后,找到了,返回给我们的浏览器
2. 根据这个IP,找到对应的服务器,发起TCP的三次握手,即建立连接
TCP连接的建立(三次握手)?
1、客户端采用TCP协议将带有SYN标志的数据包发送给服务器,等待服务器的确认。(客户端:一个SYN)
2、服务器端在收到SYN的数据包后,必须确认SYN,即向客户端发送一个ACK标志,同时,也发送一个SYN标志。(服务端:一个ACK+一个SYN)
3、客户端在接收到服务器端的SYN+ACK数据包后,会再向服务器发送一个ACK,完成三次握手。客户端和服务器正式建立了连接,开始传输数据。(客户端:一个ACK)
3. 建立TCP连接后发起HTTP请求
为什么HTTP协议要基于TCP来实现?
TCP是一个端到端的可靠的面向连接的协议,HTTP基于传输层TCP协议,发生数据传输问题时,有重传机制。
4. 服务器响应HTTP请求,浏览器得到HTML代码
5. 浏览器解析HTML代码,并请求HTML代码需要的资源(js,css,图片等)
6. 浏览器对页面进行渲染呈现给用户 *
如何渲染页面?
a)解析html文件构成 DOM树
b)解析CSS文件构成渲染树
c)边解析,边渲染
d) 等到渲染树构建完成后,浏览器开始布局渲染树,并将其绘制到屏幕上。
e)JS 单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
7. 服务器关闭TCP连接
补充:TCP协议的主要特点
1、TCP是面向连接的运输层协议。应用程序使用TCP协议之前,必须先建立TCP连接。传输数据完成之后需要结束连接。
2、每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的。
3、TCP提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达。
4、TCP提供全双工通信。TCP允许通信双方的应用程序在任何时候都能发送数据。TCP连接两端都设有发送缓存和接收缓存。用来临时存放双向通信的数据。在发送时,应用程序在把数据传送给TCP的缓存后,就可以做自己的事,而TCP在合适的时候把数据发送出去。在接收时,TCP把收到的数据放入缓存,上层的应用程序在合适的时候读取缓存中的数据。
5、面向字节流。TCP中的“流”指的是流入到进程或从进程流出的字节序列。“面向字节流”的含义:应用程序和TCP的交互时一次一个数据块(大小不等),但TCP把应用程序交下来的数据看成仅仅是一连串的无结构的字节流。TCP不知道所传送的字节流的含义。TCP不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块具有对应大小的关系。
补充:建立连接后,发起HTTP请求
HTTP请求报文
HTTP请求报文由三部分组成:请求行,请求头、空行 / 请求正文
**请求行:**用于描述客户端的请求方式(GET/POST等),请求的资源名称(URL)以及使用的HTTP协议的版本号
**请求头:**用于描述客户端请求哪台主机及其端口,以及客户端的一些环境信息等
**空行:**空行就是\r\n (POST请求时候有)
**请求正文(体):**当使用POST等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中(GET方式是保存在url地址后面,不会放到这里)
请求行的请求方式 GET/POST
GET请求:完整请求一个资源(常用)
下面是浏览器对 http://localhost:8081/test?name=XXG&age=23的GET 请求时发送给服务器的数据:
请求方法+url+http版本
 可以看出请求包含请求行和请求头两部分。其中请求行中包含 method(例如 GET、POST)、URI(通一资源标志符)和协议版本三部分,三个部分之间以空格分开。请求行和每个请求头各占一行,以换行符 CRLF(即 \r\n)分割。
可以看出请求包含请求行和请求头两部分。其中请求行中包含 method(例如 GET、POST)、URI(通一资源标志符)和协议版本三部分,三个部分之间以空格分开。请求行和每个请求头各占一行,以换行符 CRLF(即 \r\n)分割。
POST请求:提交表单
下面是浏览器对 http://localhost:8081/test 的 POST 请求时发送给服务器的数据,消息体中带上参数 name=XXG&age=23
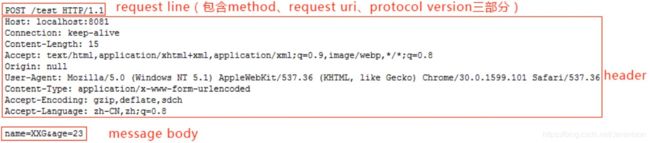
可以看出,上面的请求包含三个部分:请求行、请求头、空格/消息体,比之前的 GET 请求多了一个消息体,其中 请求头和消息体之间用一个空行分割。**POST 请求的参数不在 URL 中,而是在消息体中,且请求头中多了一项 Content-Length 用于表示消息体的字节数,这样服务器才能知道请求是否发送结束。**这也就是 GET 请求和 POST 请求的主要区别
HEAD :仅请求响应头部
PUT:上传文件(但是浏览器不支持该方法)
DELETE:删除
OPTIONS:返回请求的资源所支持的方法的方法
TRACE:追求一个资源请求中间所经过的代理(该方法不能由浏览器发出)
GET 和 POST 有什么区别?
- 传输方式不同:get请求通过url传输数据,而post请求是通过请求体传输
- 安全性不同:post请求的数据是在请求体中,所以相对安全,而get请求的数据是在url中,容易在历史记录,缓存中被查到
- 特性不同:get请求是幂等的(即同一个请求方法执行一次和多次的效果是完全相同的),而post非幂等
什么是URL、URI、URN?
- URI Uniform Resource Identifier 统一资源标识符
- URL Uniform Resource Locator 统一资源定位符
- URN Uniform Resource Name 统一资源名称
服务器响应http请求,浏览器得到html代码
HTTP响应也由三部分组成:状态行,响应头,空格,消息体
状态行包括:协议版本、状态码、状态码描述
状态码:用于表示服务器对请求的结果处理
1xx:指示信息——表示请求已经接受,继续处理
2xx:成功——表示请求已经被成功接收、理解、接受。
- 200 成功
3xx:重定向——要完成请求必须进行更进一步的操作
- 302:临时性重定向,表示资源临时被分配了新的url
- 304:表示服务器允许访问资源,但因为发生请求未满足条件的情况
4xx:客户端错误——请求有语法错误或请求无法实现
- 403:表示对请求资源的访问被服务器拒绝
- 404:服务器上没有找到请求的资源
- 408:请求超时
5xx:服务器端错误——服务器未能实现合法的请求。
- 500:服务器执行请求时出错
- 503:服务器处于瘫痪,超负荷状态,无法处理请求
HTTP响应
响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
空格:CRLF(即 \r\n)分割
消息体:服务器返回给客户端的数据
 上面的 HTTP 响应中,响应头中的 Content-Length 同样用于表示消息体的字节数。Content-Type 表示消息体的类型,通常浏览网页其类型是HTML,当然还会有其他类型,比如图片、视频等。
上面的 HTTP 响应中,响应头中的 Content-Length 同样用于表示消息体的字节数。Content-Type 表示消息体的类型,通常浏览网页其类型是HTML,当然还会有其他类型,比如图片、视频等。
补充:浏览器解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这是时候就用上 keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里面的顺序,但是由于每个资源大小不一样,而浏览器又是多线程请求请求资源,所以这里显示的顺序并不一定是代码里面的顺序。
keep-alive
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码:
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
补充:浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后呈现给用户,浏览器是一个边解析边渲染的过程。
首先浏览器解析HTML文件①构建DOM树,然后解析CSS文件②构建渲染树,等到渲染树构建完成后,浏览器开始③布局渲染树,并将其④绘制到屏幕上。
这个过程比较复杂,涉及到两个概念: reflow(回流/重排)和repain(重绘)。(具体描述见其他文章)
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。
页面在首次加载时必然会经历reflow和repain。
reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。
JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载。