数据中台建设方案-基于大数据平台
数据中台建设方案
-基于大数据平台-
1数据中台建设方案
1.1 总体建设方案
1.2大数据集成平台
1.3大数据计算平台
1.3.1数据计算层建设
计算层技术含量最高,最为活跃,发展也最为迅速。计算层主要实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持。大数据基础平台技术能力的高低,主要依赖于该层组件的发展。
本建设方案满足甲方对于数据计算层建设的基本要求:
利用了MapReduce、Spark 、MPP 、Zookeeper、Yarn、HBase、Mahout 等开源组件和技术;实现了实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持;并且提供了更高效的列式数据库Hyperbase、跨内存/闪存/磁盘等介质的分布式混合列式存储Holodesk、一体化的机器学习平台Discover和拖拽式图形界面工具Midas。可以给甲方后续建设提供更丰富、更多样性的选择。
1.3.1.1分布式数据仓库
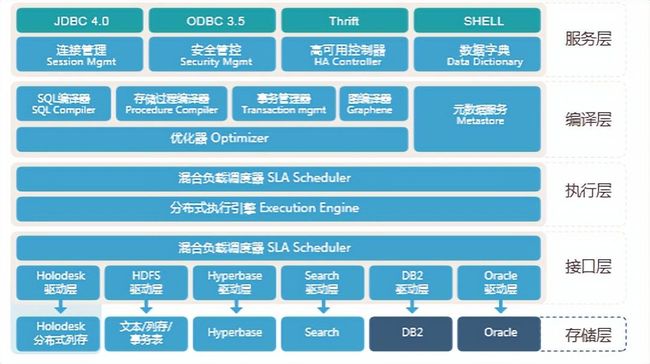
Transwarp Inceptor是一个企业级数据仓库,最下面是存储层接口层,Inceptor可将存储在分布式列存、文本/列存/事务表、Hyperbase、Search、DB2、Oracle中的数据,通过提供的对应驱动层,进入到执行层。在执行层中,Inceptor提供了混合负载调度器SLA Scheduler和分布式执行引擎。在编译层提供了各种编译器和优化器,以及元数据服务。最上层提供完整的交互访问接口和各类安全管控。
Spark是Map/Reduce计算模式的一个全新实现。Spark的创新之一是提出RDD(Resilient Distributed Dataset)的概念,所有的统计分析任务是由对RDD的若干基本操作组成。RDD可以被驻留在内存中,后续的任务可以直接读取内存中的数据,因此速度可以得到很大提升。Spark的创新之二是把一系列的分析任务编译成一个由RDD组成的有向无环图,根据数据之间的依赖性把相邻的任务合并,从而减少了大量的中间结果输出,极大减少了磁盘I/O,使得复杂数据分析任务更高效。从这个意义上来说,如果任务够复杂,迭代次数够多,Spark比Map/Reduce快100倍或1000倍都很容易。基于这两点创新,可在Spark基础上进行批处理、交互式分析、迭代式机器学习、流处理,因此Spark可以成为一个用途广泛的计算引擎,并在未来取代Map/Reduce的地位。
Inceptor可以分析存储在HDFS,HBase或者Holodesk分布式缓存中的数据,可以处理的数据量从GB到数十TB,即使数据源或者中间结果的大小远大于内存,也可高效处理。另外也通过改进Spark和YARN的组合,提高了Spark的可管理性。这些使得Inceptor成为目前真正适合企业生产环境7x24小时部署的Spark衍生产品。同时星环不仅仅是将Spark作为一个缺省计算引擎,也重写了SQL编译器,提供更加完整的SQL支持。
同时,星环通过改进Spark使之更好的与HBase融合。星环基于HBase的产品叫做Hyperbase,通过结合Inceptor,可以为HBase提供完整的SQL支持,包括批量SQL统计、OLAP分析以及高并发低延时的SQL查询能力,使得HBase的应用可以从简单的在线查询应用扩展到复杂分析和在线应用结合的混合应用中,大大拓展了HBase的应用范围。这两个产品的组合使得星环在市场上处于领先地位。
SQL语法支持
标准SQL语句支持
TDH提供ANSI SQL2003语法支持以及PL/SQL过程语言扩展,并且可以自动识别HiveQL、SQL2003和PL/SQL语法,在保持跟Hive兼容的同时提供更强大的SQL支持。减少系统迁移和新应用开发成本。支持SQL2003语法,支持TD SQL语法,支持Oracle PL/SQL和IBM DB2 SQL/PL存储过程。
由于现有的数据仓库应用大都基于标准SQL,对于客户,现有应用也大量使用了PL/SQL,要从现有数据库系统迁移到Hadoop,标准SQL以及PL/SQL的支持显得尤为重要。TDH可以支持标准SQL以及PL/SQL,支持复杂的数据仓库类分析应用,使得从原有数据库系统迁移到Hadoop更为容易,可以帮助企业建立高速可扩展的数据仓库和数据集市。
Inceptor支持以下SQL要求:
支持创建数据库、删除数据库、配置数据库的容量
支持创建表、删除表、增加表字段
支持创建、修改、删除视图CREATE/DROP/ALERT VIEW
支持表数据类型包括所有的结构化数据类型如整形、字符串、浮点型、布尔型、二进制、时间类型等,文档数据类型如XML,JSON,BSON,以及针对图片类文件的LOB类型;
支持创建索引、删除索引;
支持所有类型的表的连接,支持表的集合运算包括求并集、求交集、求差集,支持多层的SQL嵌套查询,支持 IN/Not IN/Exists/Not Exists 等复杂查询
支持字符串、日期等常用操作函数
支持最大值、最小值、平均值等聚合函数,支持常用Oracle函数,
支持select into、insert into、merge into 功能
支持完整的增删改语法,具体包括支持单条或者多条插入,支持单条更新和用子查询更新,支持从表中删除数据,支持Merge Into功能。
支持子查询 (sub-query factoring),包括非同步子查询(Non-correlated Sub-query)和同步子查询(Correlated Sub-query),支持子查询的多层嵌套。
支持在 where clause 子句使用同步和非同步subquery (包括IN 和 NOT IN)
支持在From clause子句中使用非同步subquery
支持 Having clause子句使用非同步subquery
支持 Select list里面使用同步和非同步 subquery
支持 WITH AS 语法,并可在系统运行中实时决定是否选择物理化 WITH AS来加速查询
支持 Inner JOIN, Outer JOIN (Left Outer JOIN, Right Outer JOIN, Full Outer JOIN), Implicit JOIN, Nature JOIN, Cross JOIN,SELF JOIN, Non-equi JOIN(JOIN条件可以是不等式),Map JOIN,left semi join 和 left anti semi join
支持 union, intersect, except操作,并且他们可以作为top level operator
支持 in 、between 以及运算符(+ - * )直接操作 subquery
具备较完整的事务处理支持(包括嵌套事务),支持BEGIN TRANSACTION, END TRANSACTION, COMMIT, ROLLBACK操作,支持自治事务
支持基于预定义维度的数据查询,支持简单查询、组合查询、模糊查询等。
支持标准DDL,DML,事务处理,支持SQL 2003 等,支持SQL子查询及窗口函数。
支持基本数据类型、复杂数据类型、with as 子句、同步子查询、相关子查询、嵌套子查询,窗口函数、聚合函数、类型转换、集合函数、操作符、Oracle PL/SQL过程扩展,HiveQL。
支持数据累加、统计、关联、比对、去重等各种常见的数据分析场景。
支持标准SQL的方式来访问Hadoop生态系统中的其他组件模块,如Hive、Hbase、hdfs中的文件,并能跨数据源做关联查询和分析。
TDH平台全面支持HiveQL、SQL2003标准等,可以有效支持数据仓库中常用的数据立方统计(CUBE/ROLLUP)、窗口聚合统计、嵌套(nested)/同步(correlated)子查询、子表定义和操作,这些功能无法用HiveQL有效实现。
TDH平台提供了对SQL2003标准最全面的支持,最大程度方便用户开发基于Hadoop平台的应用和现有应用的迁移。
Inceptor中对于SQL的相关支持可参见下表:
函数支持 |
|
聚合函数 |
count, sum, avg, min, max, variance, var_pop, var_samp, stddev_pop, stddev_samp, covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set, collect_list, ntile |
窗口函数 |
sum, avg, min, max, count |
dense_rank, group_max, group_min, group_sum, rank, row_number |
|
类型转换函数 |
binary, cast(expr as |
UDTF |
explode, inline, json_tuple, parse_url_tuple, posexplode, stack |
集合函数 |
size, map_keys, map_values, array_contains, sort_array |
其他功能函数 |
to_card_15_to_18(15位身份证号转18位) |
数据类型支持 |
|||
基本 数据类型 |
TINYINT, SMALLINT |
||
INT, INTEGER, BIGINT |
|||
BOOLEAN |
|||
FLOAT, DOUBLE |
|||
DATE, DATETIME, INTERVAL |
|||
TIMESTAMP |
|||
STRING |
|||
BINRAY |
|||
VARCHAR, VARCHAR2 |
|||
DECIMAL,DECIMAL(no.,no.), DEC(no., no.) |
|||
NUMERIC(no.,no.),NUMBER(no., no.) |
|||
复杂 数据类型 |
LIST |
||
MAP |
|||
STRUCT |
|||
UNION |
|||
WITH AS语句、嵌套查询支持 |
|||
WITH AS定义子表 |
SQL’92的WITH AS语句 |
WITH DEPT_COSTS AS --查询出部门的总工资 (SELECT D.DNAME,SUM(E.SAL)DEPT_TOTAL FROM DEPT D, EMP E WHERE E.DEPTNO = D.DEPTNO GROUP BY D.DNAME), AVE_COST AS --查询出部门的平均工资,在后一个WITH语句中可以引用前一个定义的WITH语句 (SELECT SUM(DEPT_TOTAL) / COUNT(*) AVG_SUM FROM DEPT_COSTS) SELECT * FROM DEPT_COSTS DC WHERE DC.DEPT_TOTAL > (SELECT AC.AVG_SUM FROM AVE_COST AC) --进行比较 |
|
嵌套 子查询 |
子查询在FROM子句中 |
SELECT employees.employee_number, employees.name FROM employees INNERJOIN (SELECT department, AVG(salary) AS department_average FROM employees GROUPBY department) AS temp ON employees.department = temp.department WHERE employees.salary > temp.department_average; |
|
子查询在WHERE子句中 |
SELECT e.name, e.salary, e.department FROM employess e WHERE e.employee_id = (SELECT MIN(employee_id) FROM employess) |
||
子查询在SELECT子句中 |
SELECT employee_number, name, (SELECT AVG(salary) FROM employees) AS department_average FROM employees; |
||
子查询在HAVING子句中 |
SELECT department_id, manager_id FROM employees GROUP BY department_id, manager_id HAVING department_id = (SELECT max(department_id) FROM employees x ) ORDER BY department_id; |
||
子查询、窗口函数、Rollup扩展支持 |
|||
CORRELATED SUB-QUERY 相关/同步子查询 |
子查询在WHERE子句中 |
SELECT employee_number, name FROM employees AS Bob WHERE salary = ( SELECT AVG(salary) FROM employees WHERE department = Bob.department); |
|
子查询在SELECT子句中 |
SELECT employee_number, name, (SELECT AVG(salary) FROM employees WHERE department = Bob.department) AS department_average FROM employees AS Bob; |
||
子查询在HAVING子句中 |
SELECT department_id, manager_id FROM employees GROUP BY department_id, manager_id HAVING department_id = (SELECT department_id FROM employees x WHERE x.department_id = employees.department_id) ORDER BY department_id; |
||
窗口 聚合函数 |
OVER子句 |
SELECT SalesOrderID, CustomerID,OrderDate, TotalDue, SUM(TotalDue) OVER (PARTITION BY CustomerID) AS CustomerTotal, SUM(TotalDue) OVER() AS GrandTotal, AVG(TotalDue) OVER (PARTITION BY CustomerID) AS AvgCustSale FROM Sales.SalesOrderHeader OuterQuery ORDER BY CustomerID; |
|
Group By扩展 |
Rollup 生成简单的GROUP BY 聚合行以及小计行或超聚合行,还生成一个总计行 |
SELECT a, b, c, SUM ( |
|
Cube生成简单的GROUP BY 聚合行、ROLLUP 超聚合行和交叉表格行 |
SELECT a, b, c, SUM ( 会为 (a, b, c)、(a, b)、(a, c)、(b, c)、(a)、(b) 和 (c) 值的每个唯一组合生成一个带有小计的行,还会生成一个总计行。 |
||
多种数据访问形式支持
CLI命令行支持
大数据计算服务提供基于Beeline的命令行终端接口,通过JDBC连接大数据计算服务控制台,用户可以通过Beeline,使用SQL语言,对大数据计算服务中的数据进行检索、查询、关联等分析操作。
标准化API接口
平台对上层应用提供各种开发接口,包括JAVA API接口,REST接口,JDBC/ODBC接口以及R语言等接口。通过这些接口,平台上层应用可以通过平台开放的JAVA API进行二次开发,可以完全支持常见的应用开发框架,如Hibernate, mybatis。平台开放的API完全兼容Hadoop生态圈的所有组件的API,同时提供额外并行算法库的Java API给上层应用调用;平台上层应用开发人员可以通过平台开放的REST API接口,对接平台作业调度工具或HUE图形化界面等,进行作业创建和管理;平台上层应用开发人员可以通过平台开放的标准JDBC/ODBC接口,使用SQL语言交互式查询和分析数据平台的海量数据;平台上层应用开发人员可以使用R语言接口进行交互式数据挖掘探索。
平台提供的主要开发接口描述如下:
数据接口 |
接口描述 |
接口使用对象 |
JDBC/ODBC接口 |
TDH支持标准的SQL形式访问数据,提供ANSI SQL2003语法支持以及存储过程语言支持。使得复杂的数据仓库、数据集市应用可以快速落地到TDH平台。 |
上层应用开发人员 |
REST接口 |
TDH支持通过REST接口对接Transwarp Manager、HDFS、YARN、Hyperbase、Inceptor、OOZIE、HUE等服务。 |
上层应用开发人员 |
Java API接口 |
TDH支持通过JAVA API编程接口对接HDFS、YARN、Kafka、、flume、sqoop、Hyperbase、Inceptor等服务。 |
上层应用开发人员 |
R接口 |
提供RStudio Web图形化开发界面,通过R语言调用并行算法库,并可通过并行化算子二次开发并行化算法。 |
上层应用开发人员 |
SQL开发辅助工具
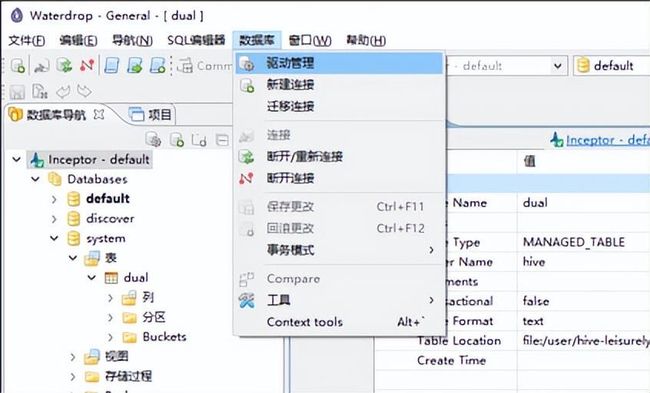
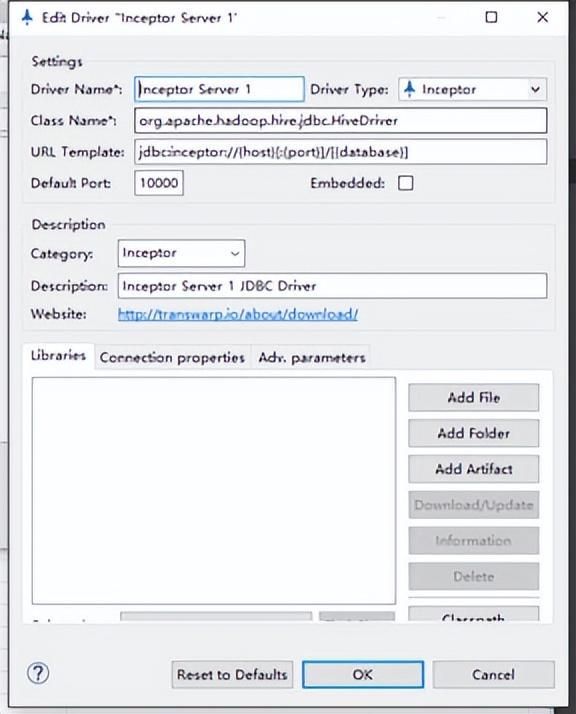
Waterdrop是为开发人员和数据库管理人员提供的数据库管理工具,它可进行跨平台管理,可作为Inceptor SQL客户端,除了Inceptor还支持并兼容其余多种数据库。它具有有四个功能模块:DatabaseNavigator、SQL Editor、SQL Executor、Data Viewer/Eidtor,分别用来帮助用户实现数据库管理、SQL编辑、SQL执行、数据操作这四项功能。
Waterdrop提供一个类似Eclipse的环境,用户可以通过Waterdrop连接Inceptor并在之上做数据库开发。
Waterdrop的开发环境如下:

操作系统/数据库支持度
Waterdrop支持的操作系统有:Windows(32/64位),Linux(32/64位),Mac OS X(64位),Solaris(32位)
Waterdrop支持连接的数据库有:
Inceptor |