Python爬虫进阶——Scrapy框架原理及分布式爬虫构建
1 Scrapy简介
1.1 概念
-
Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web信息抓取框架,用于抓取web站点并从页面中提取结构化的数据。
-
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试, Scrapy还使用了Twisted异步网络库来处理网络通讯。

-
Scrapy最便捷的地方在于,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
-
通过scrapy框架可以实现分布式爬取。
1.2 Scrapy的优点
-
提供了内置的HTTP缓存,以加速本地开发。
-
提供了自动节演调节机制,而且具有遵守robots.txt的设置的能力。
-
可以定义爬行深度的限制,以避免爬虫进入死循环链接。
-
会自动保留会话。
-
执行自动HTTP基本认证。不需要明确保存状态。
-
可以传递登录表单。
-
Scrapy 有一个内置的中间件,可以自动设置请求中的引用(referrer)头。
-
支持通过3xx响应重定向,也可以通过HTML元刷新。
-
避免被网站使用的
-
默认使用CSS选择器或XPath编写解析器。
-
可以通过Splash或任何其他技术(如Selenium)呈现JavaScript页面。
-
拥有强大的社区支持和丰富的插件和扩展来扩展其功能。
-
提供了通用的蜘蛛来抓取常见的格式:站点地图、CSV和XML。
-
内置支持以多种格式(JSON、CSV、XML、JSON-lines)导出收集的数据并将其存在多个后端(FTP、S3、本地文件系统)中
1.3 主要组件
-
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy
Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Pipeline(管道)**:
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件)**:
你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件)**:
你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2 Scrapy数据流处理流程
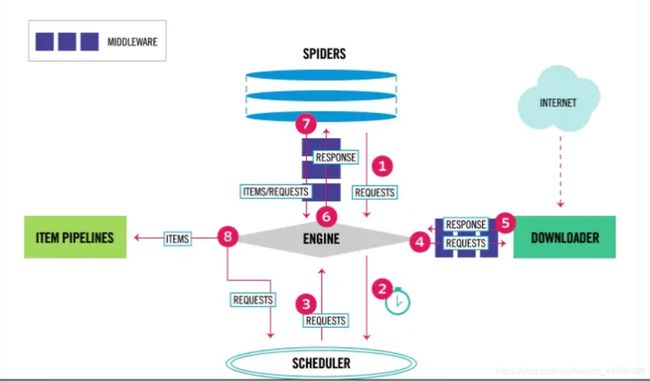
-
引擎打开一个网站(open adomain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
-
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
-
引擎向调度器请求下一个要爬取的URL。
-
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
-
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
-
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
-
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
-
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
-
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站
3 Scrapy安装与使用
3.1 安装
安装命令: pip3 install scrapy
如果安装失败按照下面的步骤进行安装:
-
pip3 install wheel.
-
pip3 install scrapy.
-
如果安装过程中提示缺失 twisted
- 访问http://www.lfd.uci.edu/~gohlke/pythonlibs/#twistedc.下载对应的twisted.whl文件
- 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whld.
-
下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
3.2 基本使用
3.2.1 新建工程
创建命令: scrapy startproject xxx #创建项目
执行这条命令将创建一个新目录:包括的文件如下:
-
zhaobiaoscrapy.cfg:项目配置文件
-
quotes/:项目python模块,代码将从这里导入
-
quotes/items:项目items文件
-
quotes/pipelines.py:项目管道文件
-
quotes/settings.py:项目配置文件
-
quotes/spiders:放置spider的目录
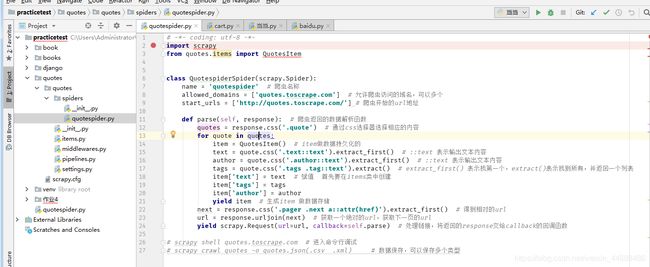
3.2.2 spider
import scrapy
from quotes.items import QuotesItemclass
QuotespiderSpider(scrapy.Spider):
name = 'quotespider' # 爬虫名称
allowed_domains = ['quotes.toscrape.com'] # 允许爬虫访问的域名,可以多个
start_urls = ['http://quotes.toscrape.com/'] # 爬虫开始的url地址
def parse(self, response): # 爬虫返回的数据解析函数
quotes = response.css('.quote') # 通过css选择器选择相应的内容
for quote in quotes:
item = QuotesItem() # item做数据持久化的
text = quote.css('.text::text').extract_first() # ::text 表示输出文本内容
author = quote.css('.author::text').extract_first() # ::text 表示输出文本内容
tags = quote.css('.tags .tag::text').extract() # extract_first() 表示找第一个,extract()表示找到所有,并返回一个列表
item['text'] = text # 赋值 首先要在items类中创建
item['tags'] = tags
item['author'] = author
yield item # 生成item 做数据存储
next = response.css('.pager .next a::attr(href)').extract_first() # 得到相对的url
url = response.urljoin(next) # 获取一个绝对的url,获取下一页的url
yield scrapy.Request(url=url, callback=self.parse) # 处理链接,将返回的response交给callback的回调函数
# scrapy shell quotes.toscrape.com # 进入命令行调试
# scrapy crawl quotes -o quotes.json(.csv .xml) # 数据保存,可以保存多个类型
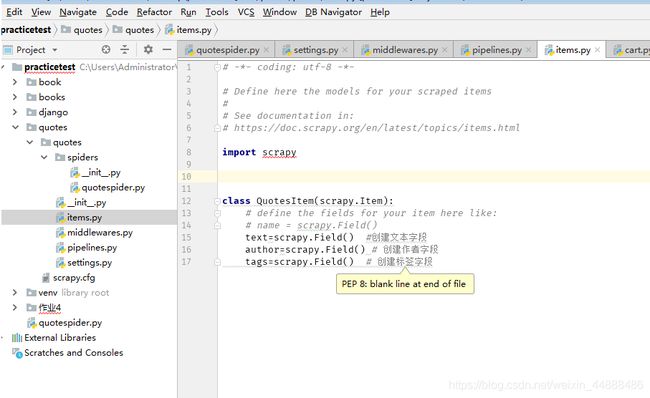
3.2.3 items
-
Items是将要装载抓取的数据的容器,它工作方式像python里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。
-
它通过创建一个scrapy.item.Item类来声明,定义它的属性为scrpy.item.Field对象,就像是一个对象关系映射(ORM).
-
我们通过将需要的item模型化,来控制获得的站点数据,比如我们要获得站点的名字,url和网站描述,我们定义这三种属性的域。要做到这点,我们编辑在quotes目录下的items.py文件,我们的Item类将会是这样
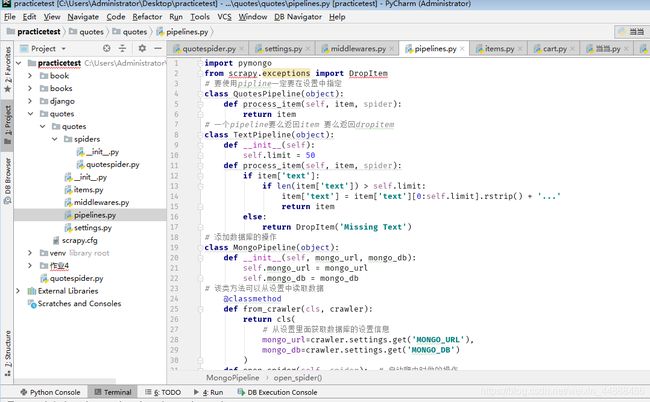
3.2.4 pipeline
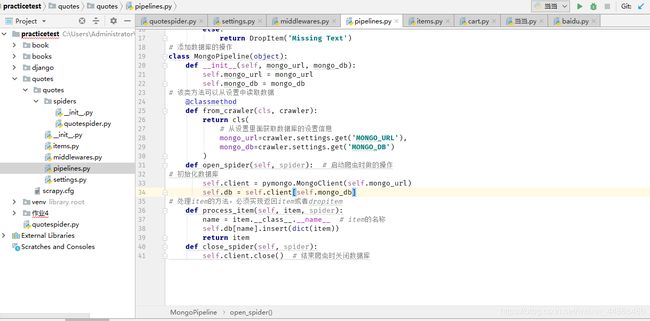
3.2.5 运行
scrapy crawl spidername
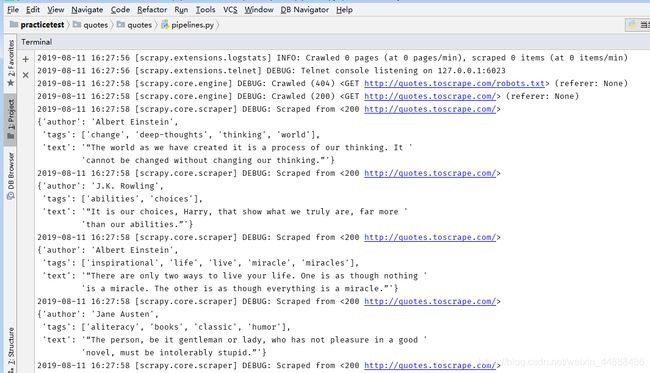
3.3 命令使用详情
3.3.1 使用范围
这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用
| 全局命令 | 项目命令 |
|---|---|
| scrapy +startproject+项目名 | scrapy +crawl+ 爬虫名字 |
| startproject | crawl |
| genspider | check |
| settings | list |
| runspider | edit |
| shell | parse |
| fetch | bench |
| view | |
| version |
3.3.2 startproject
这个命令没什么过多的用法,就是在创建爬虫项目的时候用
3.3.3 genspider
用于生成爬虫,这里scrapy提供给我们不同的几种模板生成spider,默认用的是basic,我们可以通过命令查看所有的模板
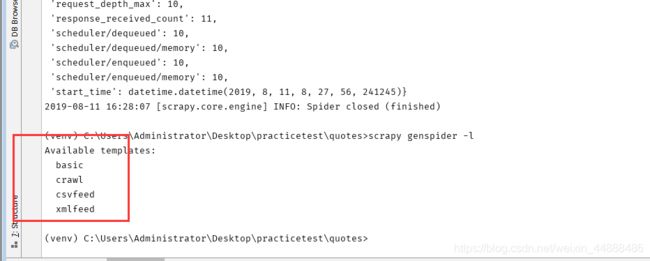
当我们创建的时候可以指定模板,不指定默认用的basic,如果想要指定模板则通过
scrapy genspider -t 模板名字
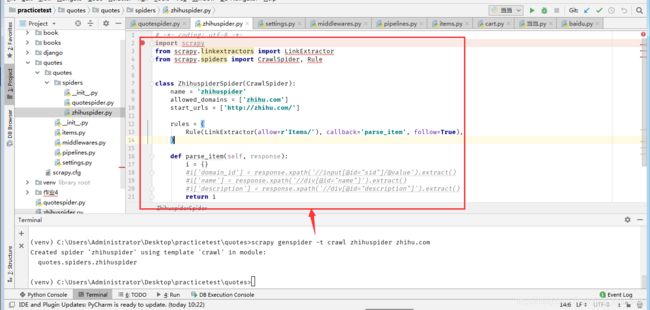
3.3.4 crawl
这个是用去启动spider爬虫格式为:
scrapy crawl 爬虫名字
这里需要注意这里的爬虫名字和通过scrapy genspider 生成爬虫的名字是一致的
3.3.5 check
用于检查代码是否有错误
scrapy check
3.3.6 list
列出所有可用的爬虫
scrapy list
3.3.7 fetch
scrapy+ fetch+ url地址
该命令会通过scrapy downloader 讲网页的源代码下载下来并显示出来
这里有一些参数:
–nolog 不打印日志
–headers 打印响应头信息
–no-redirect 不做跳转
3.3.8 view
scrapy view url地址
该命令会将网页document内容下载下来,并且在浏览器显示出来因为现在很多网站的数据都是通过ajax请求来加载的,这个时候直接通过requests请求是无法获取我们想要的数据,所以这个view命令可以帮助我们很好的判断所有的文件内容
3.3.9 shell
这是一个命令行交互模式
通过 scrapy shell url地址
进入交互模式
这里我们可以通过css选择器以及xpath选择器获取我们想要的内容(xpath以及css选择的用法会在下个文章中详细说明),例如我们通过命令
scrapy shell https://www.baidu.com
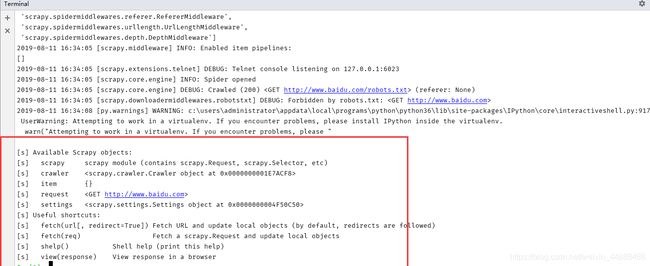
3.3.10 settings
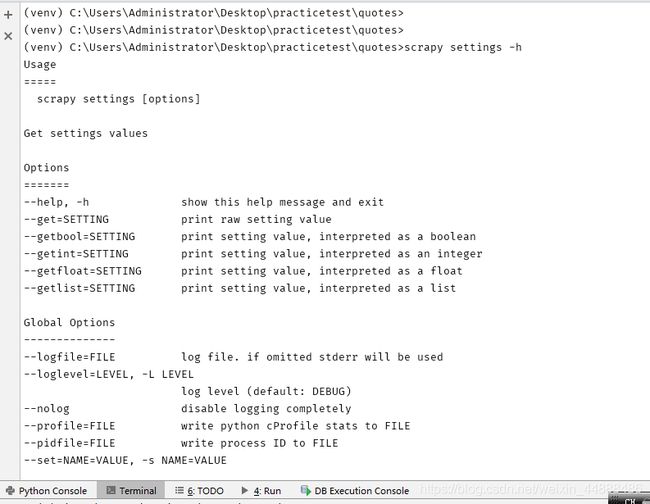
获取当前的配置信息
通过scrapy settings -h可以获取这个命令的所有帮助信息
3.3.11 runspider
这个和通过crawl启动爬虫不同,这里是
scrapy runspider 爬虫文件名称
所有的爬虫文件都是在项目目录下的spiders文件夹中
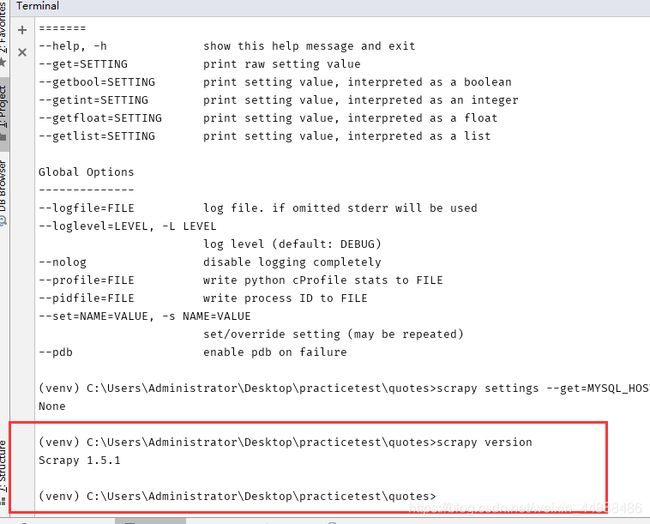
3.3.12 version
查看版本信息,并查看依赖库的信息
4 Middleware中间件
4.1 简介
-
中间件是Scrapy里面的一个核心概念。使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
-
中间件可以在中途劫持数据,做一些修改再把数据传递出去。
-
Downloader Middleware的功能十分强大:可以修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等。
-
在Scrapy中已经提供了许多Downloader Middleware,如:负责失败重试、自动重定向等中间件
-
它们都被定义到DOWNLOADER_MIDDLEWARES_BASE变量中。
-
字典格式,其中数字为优先级,越小的优先调用。
4.2 Downloader Middleware中间件—方法详解
我们可以通过项目的DOWNLOADER_MIDDLEWARES变量设置来添加自己定义的Downloader Middleware。
4.2.1 Downloader Middleware有三个核心方法:
process_request(request,spider)
process_response(request,response,spider)
process_exception(request,exception,spider)
process_request(request,spider)
当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:None,返回一个Response对象、返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。
-
None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(downloadhandler)被调用,该request被执行(其response被下载)。
-
Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
-
Request对象:Scrapy则停止调用process_request方法并重新调度返回的request。当新返回的request被执行后,相应地中间件链将会根据下载的response被调用。
-
raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常,则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常,则该异常被忽略且不记录。
process_response(request,response,spider)
-
process_response的返回值也是有三种:response对象,request对象,或者raise一个IgnoreRequest异常
-
如果其返回一个Response(可以与传入的response相同,也可以是全新的对象),
该response会被在链中的其他中间件的 process_response() 方法处理。 -
如果其返回一个 Request 对象,则中间件链停止,返回的request会被重新调度下载。处理类似于process_request() 返回request所做的那样。
-
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。
-
如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
-
写一个简单的例子:
#设置返回文本的状态码为201
def process_response(self, request, response, spider):
response.status = 201
return response
process_exception(request,exceptionspider)
-
下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括IgnoreRequest 异常)时,Scrapy调用 process_exception()。
-
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response对象、或者一个 Request 对象。
-
如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
4.如果其返回一个 Response 对象,则已安装的中间件链的 process_response()方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
4.3 代理中间件开发
Scrapy自动生成的这个文件名称为middlewares.py,名字后面的s表示复数,说明这个文件里面可以放很多个中间
在爬虫开发中,更换代理IP是非常常见的情况,有时候每一次访问都需要随机选择一个代理IP来进行。
中间件本身是一个Python的类,只要爬虫每次访问网站之前都先“经过”这个类,它就能给请求换新的代理IP,这样就能实现动态改变代理。
-
购买无忧代理,访问链接: http://www.data5u.com/vipip/dynamic.html
-
在创建一个Scrapy工程以后,工程文件夹下会有一个middlewares.py文件,打开以后其内容如下图所示。
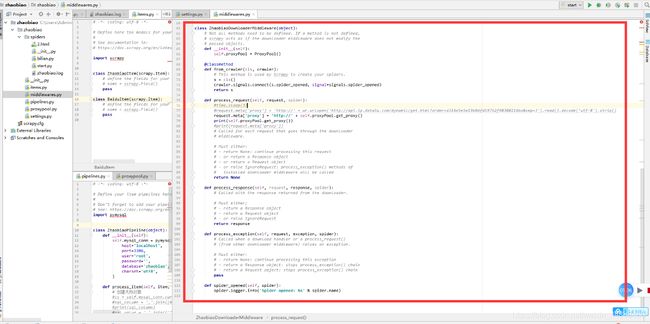
3在middlewares.py中添加下面一段代码
# 需要注意的是,代理IP是有类型的,HTTP型的代理 HTTPS型的代理IP. 如果用错,会导致无法访问
request.meta['proxy'] = 'http://' + self.proxyPool.get_proxy() print(self.proxyPool.get_proxy())
- 使用redis数据库存储ip代理信息,.编写ip脚本
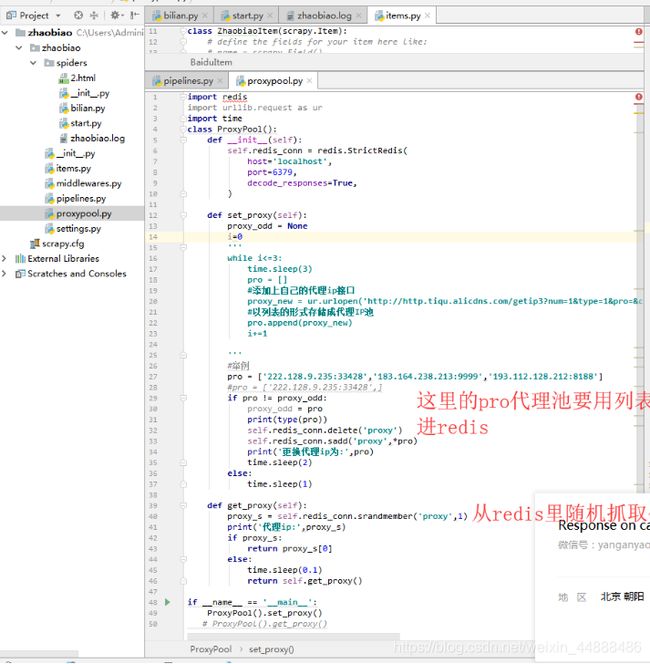
- settings.py中启动写好的中间件
在settings.py中找到下面这一段被注释的语句:
#如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要
DOWNLOADER_MIDDLEWARES = { 'zhaobiao.middlewares.ZhaobiaoDownloaderMiddleware': 543, }
如何确定后面的数字?最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道Scrapy自带中间件的顺序,如图下图所示:
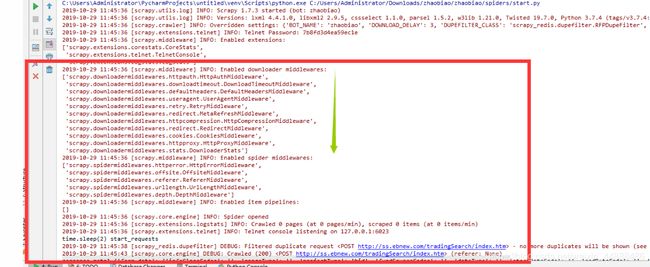
scrapy对某些内部组件进行了默认设置,这些组件通常情况下是不能被修改的,但是我们在自定义了某些组件以后,比如我们设置了自定义的middleware中间件,需要按照一定的顺序把他添加到组件之中,这个时候需要参考scrapy的默认设置,因为这个顺序会影响scrapy的执行,下面列出了scrapy的默认基础设置。
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware':350, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 400,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 500,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 550,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware':590, 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware': 830,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
-
数字越小的中间件越先执行,例如Scrapy自带的第1个中间件RobotsTxtMiddleware,它的作用是首先查看settings.py中ROBOTSTXT_OBEY这一项的配置是True还是False。如果是True,表示要遵守Robots.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了。
-
开发者自定义的中间件,会被按顺序插入到Scrapy自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求。
-
Scrapy其实自带了UA中间件(UserAgentMiddleware)、代理中间件(HttpProxyMiddleware)和重试中间件(RetryMiddleware)。所以,从“原则上”说,要自己开发这3个中间件,需要先禁用Scrapy里面自带的这3个中间件。要禁用Scrapy的中间件,需要在settings.py里面将这个中间件的顺序设为None:
查看Scrapy自带的代理中间件的源代码,如下图所示:
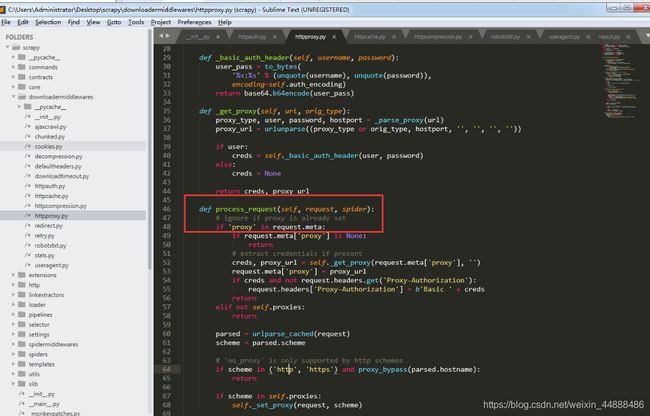
从上图可以看出,如果Scrapy发现这个请求已经被设置了代理,那么这个中间件就会什么也不做,直接返回。因此虽然Scrapy自带的这个代理中间件顺序为750,比开发者自定义的代理中间件的顺序543大,但是它并不会覆盖开发者自己定义的代理信息,所以即使不禁用系统自带的这个代理中间件也没有关系。
5 ItemPipeline
5.1 简介
-
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
-
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
-
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 将爬取结果保存到数据库中
5.2 方法详解
编写你自己的item pipeline很简单,每个item pipiline组件是一个独立的Python类,同时必须实现以下方法:
5.2.1 process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item(或任何继承类)对象, 或是抛出DropItem
异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:
-
item (Item 对象) – 被爬取的item
-
spider (Spider 对象) – 爬取该item的spider
5.2.2 open_spider(spider)
1.当spider被开启时,这个方法被调用。
2.参数: spider (Spider 对象) – 被开启的spider
5.2.3 close_spider(spider)
1.当spider被关闭时,这个方法被调用
2.参数: spider (Spider 对象) – 被关闭的spider
5.3 数据持久化储存开发
-
安装pymysql : pip install pymysql
-
mysql中必须存在对应的表与表结构,
-
自定义pipeline 使用pymysql模块,连接mysql数据库,连接时注意,将信息替换成自己本机的mysql账号密码,数据库即可
import pymysql
class ZhaobiaoPipeline(object):
def __init__(self):
self.mysql_conn = pymysql.Connection(
host='localhost',
port=3306,
user='root',
password='123456',
database='zhaobiao_a',
charset='utf8',)’
def process_item(self, item, spider):
# 创建光标对象
# sql_str = 'insert into t_zhaobiao (字段,字段) value ("值","值")'
cs = self.mysql_conn.cursor()
sql_column = ','.join([key for key in item.keys()])
sql_value = ','.join(['"%s"' % item[key]for key in item.keys()])
sql_str = 'insert into t_zhaobiao (%s) value (%s);' % (sql_column, sql_value) cs.execute(sql_str)
self.mysql_conn.commit()
return item
- 激活pipeline 可以同时定义多个管道文件,优先级原理和中间件的处理方式类似,
ITEM_PIPELINES = { 'zhaobiao.pipelines.ZhaobiaoPipeline': 300, }
6 settings解析
# scrapy 的settings官方文档说明,英文版
#https://doc.scrapy.org/en/latest/topics/settings.html
#scrapy 的 Downloader Middleware 官方文档说明,英文版
#https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# scrapy 的spider-middleware 官方文档说明,英文版
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#使用 startproject 命令创建项目时自动添加,如果不用自己的user_agent,就用它来构造默认 User-Agent,
#USER_AGENT = scrapy'zhaobiao (+http://www.yourdomain.com)
BOT_NAME = 'zhaobiao'
#项目启动时 Scrapy从列表里寻找爬虫文件夹,顺序查找
SPIDER_MODULES = ['zhaobiao.spiders']
# 使用genspider命令在这个文件夹下创建 .py 爬虫文件
NEWSPIDER_MODULE = 'zhaobiao.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# Obey robots.txt rules
#是否遵循robot协议,就是,碰到不允许抓的网站抓不抓,肯定抓,所以一般默认True,要改成False
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
#Scrapy下载器将执行的并发(即并发)请求的最大数量,scrapy默认的线程数为10
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
#从同一网站下载连续页面之前,下载程序应等待的时间(以秒为单位),用来限制爬取速度,以避免对服务器造成太大的冲击,支持小数
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#将对任何单个域执行的并发,请求的最大数量
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_IP = 16
#将对任何单个IP执行的并发,请求的最大数量
# Disable cookies (enabled by default)
#COOKIES_ENABLED = True
#注释是默认开启,True是启用Cookies中间件,注意不是settings的DEFAULT_REQUEST_HEADERS的cookie, False状态才是使用DEFAULT_REQUEST_HEADERS的cookie
# Disable Telnet Console (enabled by default)
#禁用Telnet控制台(默认启用
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#修改请求头,就是请求头没什么好说的,简单,举例
# DEFAULT_REQUEST_HEADERS = {
# 'accept': 'image/webp,*/*;q=0.8',
# 'accept-language': 'zh-CN,zh;q=0.8',
# 'referer': 'https://www.taobao.com/',
# 'user-agent': 'Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36',# }
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Cookie':'td_cookie=2885562732; __cfduid=da9eaafdfa77f326b2a6493ab987ad3181561096427; loginUser=kzl_knight; Hm_lvt_ce4aeec804d7f7ce44e7dd43acce88db=1565581565,1565664425;JSESSIONID=F831EEBBC3F4DAEFA3788033F85A5B55;Hm_lpvt_ce4aeec804d7f7ce44e7dd43acce88db=1565682498',}
#-------------------------------------------------------------------------
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zhaobiao.middlewares.ZhaobiaoSpiderMiddleware': 543,#}
# Enable or disable downloader middlewares
#Seehttps://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES ={
'zhaobiao.middlewares.ZhaobiaoDownloaderMiddleware': 543,}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'zhaobiao.pipelines.ZhaobiaoPipeline': 300,# }
#-----------------------------------------------------------------------------
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#启用或禁用扩展程序
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#启动自动节流设置
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#初始时 自动节流延迟设置
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#最大自动节流延迟设置
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to# each remote server
#被并行发送的Scrapy平均请求数
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#起用 AutoThrottle 调试(debug)模式,展示每个接收到的 response
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
#Seehttps://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#httpcache-middleware-settings
#是否启用HTTP缓存
#HTTPCACHE_ENABLED = True
#缓存的请求的到期时间,零,缓存的请求永不过期
#HTTPCACHE_EXPIRATION_SECS = 0
#用于存储HTTP缓存的目录
#HTTPCACHE_DIR = 'httpcache'
#默认为空,不缓存响应的http状态
#HTTPCACHE_IGNORE_HTTP_CODES = []
#http 缓存的存储方式,需要添加扩展文件才可以使用
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#日志的地址
# LOG_FILE = 'zhaobiao.log'
#日志记录的等级,CRITICAL -严重错误 ERROR 一般错误 WARNING -警告信息 INFO 一般信息 DEBUG -调试信息
# LOG_LEVEL = 'ERROR' / 'INFO'
# 启动Scrapy-Redis去重过滤器,取消Scrapy的去重功能
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 启用Scrapy-Redis的调度器,取消Scrapy的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Scrapy-Redis断点续爬
SCHEDULER_PERSIST = True
# 配置Redis数据库的连接
REDIS_URL = 'redis://127.0.0.1:6379'
更多详细文档可以查看官方文档:
https://doc.scrapy.org/en/latest/topics/settings.html
7 模拟请求头
使用scrpay抓取网站内容时,为了防止网站的反爬机制,也就是反反爬,我们通常会在发送请求时人为的携带上User-Agent和登录后的Cookie值,来伪造浏览器请求,一般在
settings—DEFAULT_REQUEST_HEADERS中进行设置
设置如下:
DEFAULT_REQUEST_HEADERS = {'User-Agent':’值’,'Cookie':’值’}
8 快速启动爬虫项目
1.自定义start.py,其作用是通过cmdline模块, 使用execute命令快速开启爬虫项目.
2.statr.py的位置: 与爬虫文件同级,即 在存在于spiders文件夹下.
代码如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl bilian'.split()) # scrapy crawl 爬虫name名称
9 异常请求的处理机制
-
使用中间件的process_exception方法,自定义处理方式.
-
使用log日志记录错误信息,方便错误勘正.
- 格式:
LOG_FILE=’日志文件地址’ LOG_LEVEL=’日志级别’
- 参数详解:
| 级别 | 说明 |
|---|---|
| CRITICAL | 严重错误 |
| ERROR | 一般错误 |
| WARNING | 警告信息 |
| INFO | 一般信息 |
| DEBUG | 调试信息 |
- 实例
LOG_FILE=’zhaobiao.log’
LOG_LEVEL=’ERROR’
10 Redis数据库
10.1 简介
-
Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
-
Redis与其他 key - value 缓存产品有以下三个特点:
-
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启后可以再次加载进行使用。
-
Redis不仅仅支持简单的key-value类型(hash)的数据,同时还提供包括string(字符串)、list(链表)、set(集合)和sorted set(有序集合)。
-
Redis支持数据的备份,即master-slave模式的数据备份。
-
Redis是一个高性能的key-value数据库。
-
Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。
-
它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
-
Redis优势:
-
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
-
支持常见的数据类型 – Redis支持二进制案例的Strings,Lists,Hashes,Sets及Ordered Sets数据类型操作。
-
Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
-
Redis还支持 publish/subscribe, 通知, key 过期等等特性。
-
10.2 安装
-
官方网站:https://redis.io
-
官方文档:https://redis.io/documentation
-
中文官网:http://www.redis.cn
-
可视化管理工具:https://redisdesktop.com/download
-
windows下安装:可使用课件内的msi安装包安装.
10.3 数据结构
-
Redis数据库安装后,默认存在16个数据库,db(0)-db(15)
-
开始Redis后默认使用的是db(0)
-
切换数据库的方式: select [index]
例如: 切换到db1 select 1
10.4 数据类型
| 类型 | 简介 | 操作 |
|---|---|---|
| 键 | 查找: keys[pattern] 删除:del[key] 检查是否存在: exists[key] 查看类型: type[key] | |
| String(字符串) | 1.一个 key 对应一个 value 2. 二进制安全的,可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | 设置值: set key value 取值: get key |
| hash(字典) | 1.键值对集合,相当于Python中的字典, 2.string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 设置值: hset key field value 取值:hget key field |
| list(列表) | 简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。 | 左边插入: lpush key [value] 右边插入: rphsh key [value] 根据索引设置: lset key index value 左边出栈: lpop key 右边出栈: rpop key |
| Set(集合) | 1. Set 是 string 类型的无序集合。 2.集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1) | 添加: sadd key [member] 删除指定member: srem key [member] 查看key所有的member: smembers key 随机出栈count个member: spop key count 随机查看count个member: srandmember key count 查看key中member的个数: scard key |
| Zset(有序集合) | 1.和set 一样也是string类型元素的集合,且不允许重复的成员。 2.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。 3.zset的成员是唯一的,但分数(score)却可以重复。 | 添加member和score: zadd key [score member] 删除member: zrem key [member] 根据排序删除: zremrangebyrank key start stop 根据score范围删除: zremrangebyscore key min max |
10.5 Python-Redis
-
安装 redis模块: pip install redis
-
导包: import redis
-
创建Redis连接
import redis
conn=redis.StrictRedis(
host=’localhost’,
port=6379,
password=’’,
decode_responses=True
)
#执行redis语句
ret=conn.execute_command(‘语句’)
注: 端口号,密码以本地Redis数据库的连接信息为准.
11 Scrapy-Redis
11.1 安装
安装命令: pip install scrapy-redis
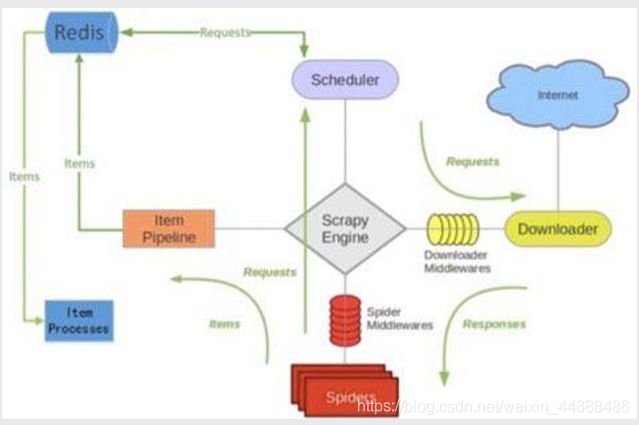
11.2 原理图
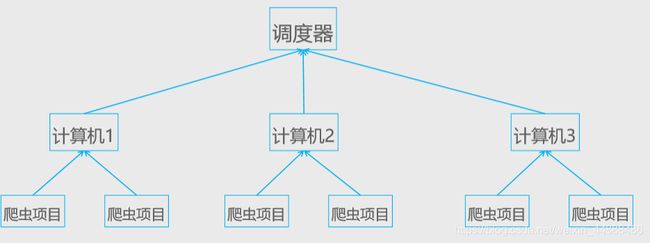
11.3 配置
项目的Settings.py中配置连接信息:
# 启动Scrapy-Redis去重过滤器,取消Scrapy的去重功能
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 启用Scrapy-Redis的调度器,取消Scrapy的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Scrapy-Redis断点续爬
SCHEDULER_PERSIST = True
# 配置Redis数据库的连接
REDIS_URL = 'redis://127.0.0.1:6379'
-
安装模块: pip install redis
-
导包: import redis
-
创建Redis连接
import redis conn=redis.StrictRedis(host=’localhost’,port=6379,password=’’,decode_responses=True) #执行redis语句 ret=conn.execute_command(‘语句’)