JVM垃圾回收
Java运行时内存的各个区域。对于程序计数器、虚拟机栈、本地方法栈这三部分区域而言,其
生命周期与相关线程有关,随着线程的结束而结束。因为当方法结束或者线程结束时,内存就自然跟着线程回收了。
Java堆中存放着几乎所有的实例对象,垃圾回收器在对堆进行垃圾回收前,首先要判断这些对象哪些还存活,哪些已经 “死去” 。 死去的对象可以简单的理解为:当前对象已经无法使用。
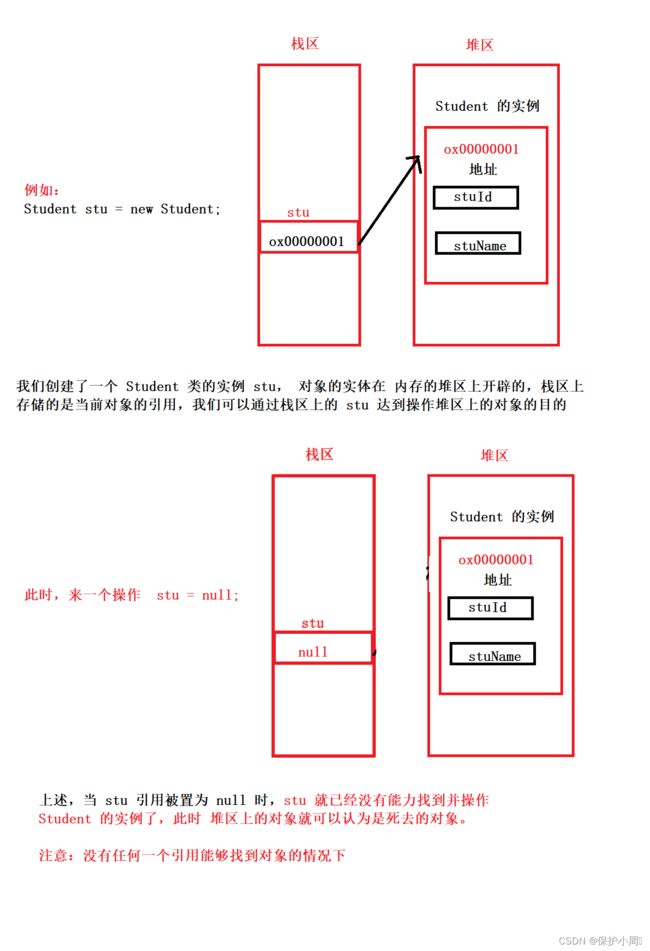
上述是一种判断对象是否存活的机制。
一、垃圾回收
垃圾回收(GC),就是帮住程序猿自定的释放内存,在 C 语言中,我们动态开辟的内存(malloc),不使用的时候就需要手动的是调用 free() 方式释放,如果不释放有什么危害呢? 内存是空间是固定的,程序在运行时会向内存申请大量的内存空间,当一些数据,不再使用,也不释放内存,这些无效数据就会一直占据内存的空间,随着无效的数据越来越多,内存逐渐用完,导致内存溢出(抛异常),程序崩溃, 系统宕机的话,重启就好了~
总而言之,内存泄露 是 C/C++ 程序猿职业生涯中的一生之敌。
但是博主是学 Java 的,Java 等后续的编程语言引入了垃圾回收来解决上述问题,能够有效的减少内存的泄露。除非你程序循环\递归申请空间,没有终止条件。
内存的释放是一件比较纠结的事情:
C/C++ 的做法是让程序猿自己决定何时释放内存,依赖于程序猿的水平。
Java 通过JVM 的一些策略自动判定,准确性比较高,但是也意味着在性能上会付出一些代价。
JVM 中的内存有好几个区域, 我们所说的内存回收,具体是回收那一部分的空间呢?
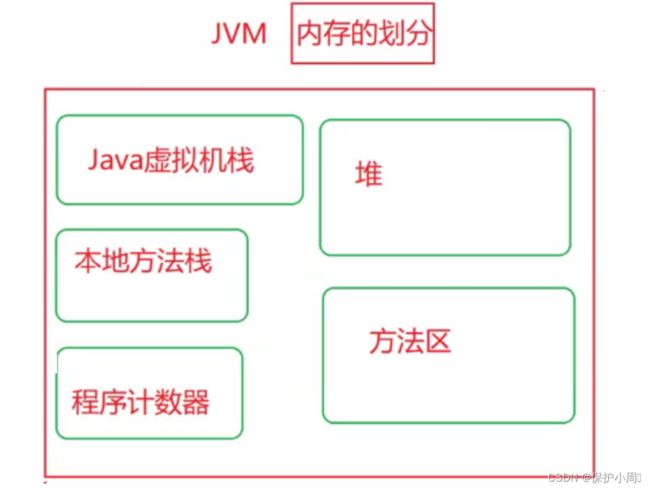
程序计数器,就是一个单纯的存地址的整数,用于存储当前正在执行的指令地址或下一条将要执行的指令地址。随着线程的销毁而销毁。
Java虚拟机栈,是Java虚拟机为执行Java方法而提供的一块内存区域,用于支持方法调用和执行。它由栈帧组成,保存了方法的参数、局部变量、返回值等信息。随着方法的结束而结束
本地方法栈,主要维护的是JDK , 内部集成的一些由C/C++ 语言所编写的本地方法或类对象,本地方法栈的大小是可以配置的,可以通过JVM参数来指定。如果本地方法栈空间不足,会抛出栈溢出异常(StackOverflowError)。
方法区(Method Area)是Java虚拟机(JVM)中的一块内存区域,用于存储类的结构信息、常量、静态变量、编译器编译后的代码等数据。它是所有线程共享的,与堆区不同,每个线程都有自己独立的方法栈和程序计数器。
堆区:主要存储就是 类实例后的对象,堆区也是垃圾回收的主要区域。GC 也可以认为是以对象为单位进行释放的。
垃圾回收主要分为两个阶段:这也是主要关注的策略
1. 判断谁是垃圾2. 删除垃圾的策略
二、确定垃圾
垃圾回收主要是针对堆区上的对象讲述,一个对象如果后续再也不使用了,就可以认为是垃圾。
Java 中使用一个对象,只能通过引用。
如果一个对象,没有引用指向,那么这个对象一定是无法被使用的,就可以认为是垃圾。
如果一个对象, 已经不需要使用了,但是还有引用维护着这个对象,此时并不认为是垃圾。
Java 中只是单纯的判断一个对象有没有引用来维护,来确定是否是垃圾。
Java 对于垃圾对象的标识是保守的,没有及时释放是小,如果不小心干掉了有用的对象,那可能程序都无法继续执行了。
如何判断一个对象是否有引用指向呢?
这里给大家讲解两种策略: 1. 引用计数 2. 可达性分析
2.1 引用计数
引用计数: 给对象安排一个额外的空间,保存一个整数, 表示该对象有几个引用指向。当前这个策略 Java 并没有使用,Python 使用的是引用计数的策略。
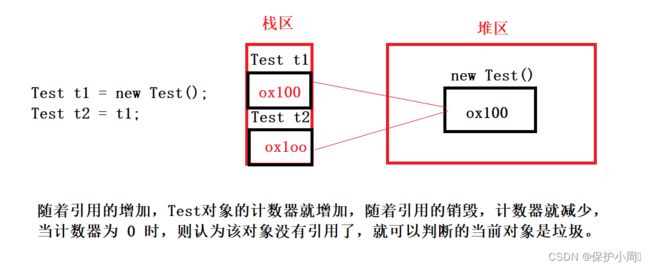
但是引用计数有两个缺点:
1. 需要开辟额外的空间来计数。
2. 存在循环引用的情况。会导致引用计数的判定逻辑出错
举个例子:
class Test { public Test n; } Test a = new Test(); // 此时 a 引用指向的 Test 对象计数器 = 1 Test b = new Test(); // 此时 b 引用指向的 Test 对象计数器 = 1 a.n = b; // 此时 b 引用指向的 Test 对象又被 a-> Test 的成员n 引用指向, b-> Test 计数器 +1 = 2 b.n = a; // 此时 a 引用指向的 Test 对象又被 b-> Test 的成员n 引用指向, a -> Test 计数器 +1 = 2如果此时,把 a ,b 引用销毁,那么各自引用的 Test 对象计数器 - 1, 但是 Test 对象的成员变量 n 还保持着引用, 这俩对象的计数器并不是 0 , 不能作为垃圾,但是这俩对象已经无法使用了。这就是陷入了逻辑的循环。
Java 并没有采用引用计数作为确定垃圾的策略,而是使用了可达性分析~
解决引用计数的问题可以采用其他的内存管理技术,如垃圾回收(Garbage Collection)。垃圾回收器可以通过追踪对象之间的引用关系,从根对象开始遍历访问可达对象,将不可达对象标记为垃圾并进行回收。垃圾回收器可以解决循环引用的问题,并且可以在适当的时机自动回收不再使用的内存,减少了手动内存管理的工作量。
2.2 可达性分析 (Java 策略)
可达性分析,把对象之间的引用关系,理解成一个树形结构,从一些特殊的起点出发,进行遍历,要是能遍历到的对象,就是 “可达”, 那么 “不可达” 的当作垃圾处理即可。
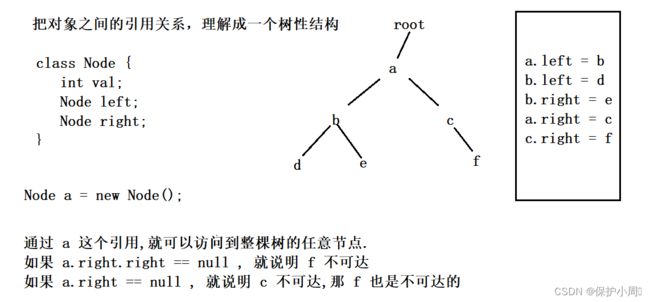
上述策略,垃圾回收器可以解决循环引用的问题。
可达性分析的要点:遍历需要有起点,以下可以作为起点。
1. 栈上的局部变量(引用)都是“起点” 都会进行遍历。
2. 常量池中引用的对象
3. 方法区中,静态成员引用的对象。
可达性分析:就是从所以的起点出发,看看该对象里是不是可以访问到其他对象,顺藤摸瓜,把所有可以访问的对象都遍历一遍,遍历的同时把对象标记为 “可达”, 那么剩下的就是 “不可达”就可以认为是垃圾。
可达性分析的缺点:
1. 因为判断对象是否是垃圾,从起点开始需要进行遍历,这就意味着要消耗更多的时间,而且当某一个对象成为了垃圾,也不一定能够及时的发现。
2. 在进行可达性分析的时候,要从进行顺藤摸瓜,在这个过程中,如果当前代码中的对象引用关系发送了变化,也不能够及时的察觉,所以为了更准确的完成遍历标记,就需要其他业务线程暂停工作(STW 问题),这也是Java垃圾回收机制最大的缺点。
三、释放“垃圾” 对象
通过上述讲解,我们已经知道了Java 如何确定“垃圾”,利用可达性分析。确定垃圾之后就需要对垃圾进行处理。 关于垃圾处理机制,有三种比较典型的策略:
3.1 标记清除

使用标记清除,就直接把标志垃圾对象处理里,释放了 ,但是这种方式明显的缺点就是会产生内存碎片,申请空间的时候都是申请 “一块连续的存储空间”,但现在内存的空闲空间是离散的,独立的空间,像这种离散的空间,假设有 1 G , 但是想一次性申请 200M 的空间还不一定能够申请到
3.2 复制算法
复制算法:把整个内存空间,分成两段,一次只使用一半,再把不是垃圾的对象,拷贝到另外一边,然后再统一的释放整个区域。
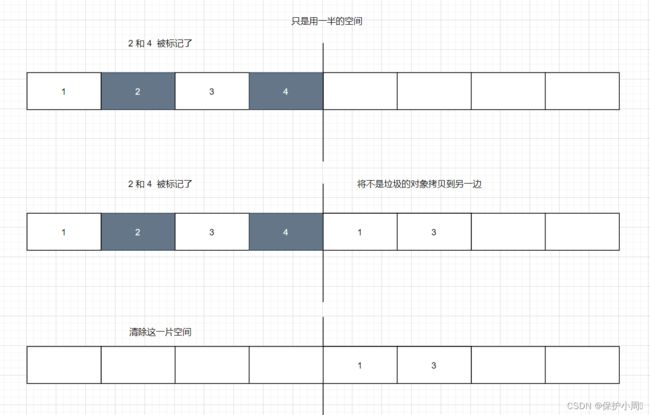
复制算法可以解决内存碎片的问题,同时缺陷也是比较明显的:
1. 一次只是用一半的内存, 对内存的利用率比较低。2. 如果标记删除的对象比较少,大部分都是要保留的对象,此时将要保留的对象复制到另一边,整个复制的成本是比较高的。
3.3 标记整理
类似于ArrayList (顺序表)删除中间元素,为了保证数据的连续性,有一个搬运的过程。
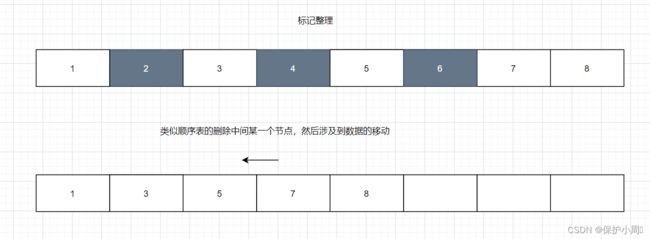
标志整理,解决了内存碎片的问题,也提升了内存的利用率,但是每一次清除标记元素后,搬运数据的开销也是很大的。
根据上述得三种清除标记对象的策略,我们知道,标记清除,会产生内存碎片,复制算法对内存的利用率不高,在要保留的数据很多的情况下,会执行大量的复制操作。标志整理,完美的改善了上述问题,但是又会涉及到大量的数据移动。
因此 JVM 清除标记的实现思路,结合了上述的三种思想 —— 分代回收思想
3.4 分代回收
分代回收,给对象设定了 “年龄“ 的概念,用来描述了这个对象存在了多久。
如果一个对象刚诞生,则认为是 0 岁,每次经过一轮可达性分析,没有被标记的对象就会涨一岁,通过这个年龄来区分这个对象的存活时间。
然后就可以根据不同年龄段的对象采取不同的回收策略。
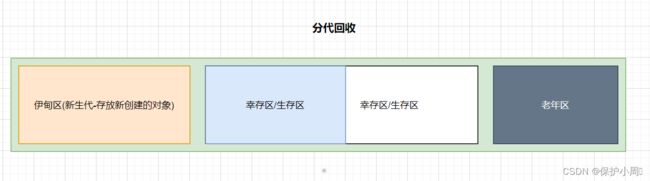
1. 新创建的对象,放在伊甸区
当垃圾回收(GC)扫描(可行性分析)到伊甸区之后,大部分对象都会在第一轮GC中被淘汰
在年轻代中,主要采用的回收策略是复制算法(Copying Algorithm)和标记-清除算法 (Mark-Sweep Algorithm)
2. 伊甸区中的对象,如果没有在第一轮GC 中淘汰,就会通过复制算法,拷贝到生存区,生存区分为大小相同的两部分,一次只使用其中的一半,当生存区的对象在一轮GC 后被标记,其他幸存的对象就会通过复制算法拷贝到另一块未使用的幸存区,然后清除全部标记对象。如此交替。
3. 当一个对象在生存区,经过若干论都没有被淘汰,年龄增长到一定的程度,就会通过复制算法拷贝到老年区,进入老年区的对象,被淘汰的概率就很低了,此时针对老年区 GC 的频率也随之降低,如果老年区中发现某个对象是垃圾,就使用标记整理删除。
4. 特殊情况,当一个对象非常大的时候,是直接进入老年区的(大对象进行复制算法成本比较高)
内向而不呆滞,寂静而有力量