go语言基本操作---六
并发编程
并行:指在同一时刻,有多条指令在多个处理器上同时执行。
并发:指在同一时刻只能有一条指令执行,但是多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
Go语言为并发编程而内置的上层api基于CSP(顺序通信进程)模型。这就意味着显示锁都可以避免的,因为Go语言通过安全的通道发送的接受数据以实现同步,这大大简化了并发程序的编写。
goroutine(go ru keng)
它是Go并发设计的核心。它其实就是协程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存,当然会根据相应的数据伸缩。也正因为如此,可以同时运行成千上万个并发任务。goroutine比thread更医用,更高效,更轻便。
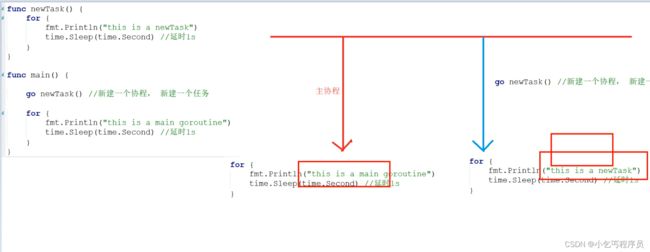
package main
import (
"fmt"
"time"
)
func newTask() {
for {
fmt.Println("this is a main newTask")
time.Sleep(time.Second) //延时1s
}
}
func main() {
/**
this is a main goroutine
this is a main goroutine
this is a main newTask
*/
go newTask() //新建一个协程
for {
fmt.Println("this is a main goroutine")
time.Sleep(time.Second) //延时1s
}
}
创建goroutine
只需在函数调用语句前添加go关键字,就可以创建并发执行单元,开发人员无需了解任何执行细节,调度器会自动将安排到合适系统线程上执行。
主协程先退出

package main
import (
"fmt"
"time"
)
// 主协程退出来,其他子协程也要跟着退出
/**
main i = 1
子协程 i = 1
子协程 i = 2
main i = 2
进程 已完成,退出代码为 0
*/
func main() {
go func() {
i := 0
for true {
i++
fmt.Println("子协程 i = ", i)
time.Sleep(time.Second)
}
}()
i := 0
for true {
i++
fmt.Println("main i = ", i)
time.Sleep(time.Second)
if i == 5 {
break
}
}
}
主协程先退出导致子协程没来得及调用
package main
import (
"fmt"
"time"
)
// 主协程退出来,其他子协程也要跟着退出
/**
main i = 1
子协程 i = 1
子协程 i = 2
main i = 2
进程 已完成,退出代码为 0
*/
func main() {
go func() {
i := 0
for true {
i++
fmt.Println("子协程 i = ", i)
time.Sleep(time.Second)
}
}()
}

runtime.Gosched的使用
它用于让出CPU时间片。让出当前goroutine的执行权限,调度器安排其他等待任务运行,并在下次某个时间从该位置恢复执行。
package main
import (
"fmt"
"runtime"
)
func main() {
go func() {
for i := 0; i < 5; i++ {
fmt.Println("go")
}
}()
for i := 0; i < 2; i++ {
//让出时间片,先让别的协程执行,它执行完,再回来执行此协程
runtime.Gosched() //如果不写这个就只会打印hello hello
fmt.Println("hello")
}
}
runtime.Goexit的使用
调用它将立即终止当前goroutine执行,调度器确保所有已注册defer延迟调用被执行。
package main
import (
"fmt"
"runtime"
)
func test1() {
defer fmt.Println("ccccccccccccccccc")
//return //终止此函数 如果有它 acb
runtime.Goexit() //终止所在的协程 ac 如果没有这个则打印 adcb
fmt.Println("dddddddddddddddddddddd")
}
func main() {
//创建新建的协程
go func() {
fmt.Println("aaaaaaaaaaaaaaaaaaaaaaa")
//调用别的函数
test1()
fmt.Println("bbbbbbbbbbbbbbbbbbbbbbb")
}()
//特地写一个死循环,目的不让主协程结束
for {
}
}
runtime.GOMAXPROCS()
它用来设置可以并行计算的CPU核数最大值,并返回之前的值。
package main
import (
"fmt"
"runtime"
)
func main() {
//n := runtime.GOMAXPROCS(1) //指定以单核运算
n := runtime.GOMAXPROCS(2)
fmt.Println("n = ", n)
for true {
go fmt.Print(1)
fmt.Print(0)
}
}
多任务资源竞争问题–这样就需要同步
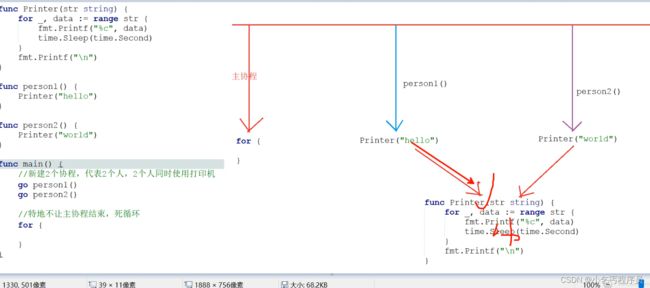
package main
import (
"fmt"
"time"
)
// 定义一个打印机,参数为字符串,按每个字符打印
func Printter(str string) {
for _, data := range str {
fmt.Printf("%c", data)
time.Sleep(time.Second)
}
fmt.Printf("\n")
}
func person1() {
Printter("hello")
}
func person2() {
Printter("world")
}
func main() {
//Printter("hello")
//
//Printter("world")
//新建2个协程,代表2个人,2个人同时使用打印机
go person1()
go person2()
for true {
}
}
channel
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine奉行通过通信来共享内存,而不是共享内存来通信
引用类型channel是CSP模型的具体实现,用于多个goroutine通讯。其内部实现了同步,确保并发安全。
channel类型
和map类似,channel也一个对应make创建的底层数据结构的引用。
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者何被调用者将引用同一个channel对象。和其他的引用类型一样,channel的零值也是nil。
channel定义
make(chan Type) //创建类型
make(chan Type,capacity)//capacity指定容量

通过channel实现同步
package main
import (
"fmt"
"time"
)
// 全局变量,创建一个channel
var channel = make(chan int)
// 定义一个打印机,参数为字符串,按每个字符打印
func Printter(str string) {
for _, data := range str {
fmt.Printf("%c", data)
time.Sleep(time.Second)
}
fmt.Printf("\n")
}
// person1执行完后,才能到person2执行
func person1() {
Printter("hello")
channel <- 666 //给管道写数据,发送
}
func person2() {
<-channel //从管道取数据,接收,如果通道没有数据他就会阻塞
Printter("world")
}
func main() {
//Printter("hello")
//
//Printter("world")
//新建2个协程,代表2个人,2个人同时使用打印机
go person1()
go person2()
for true {
}
}
通过channel实现同步和数据交互
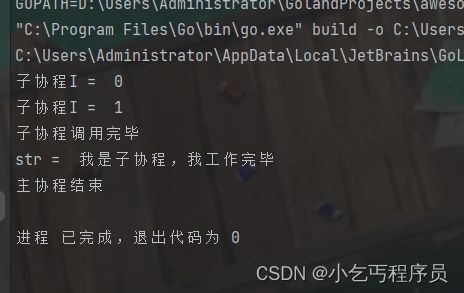
package main
import (
"fmt"
"time"
)
func main() {
//创建chann
ch := make(chan string)
defer fmt.Println("主协程结束")
//它执行完才结束
go func() {
defer fmt.Println("子协程调用完毕")
for i := 0; i < 2; i++ {
fmt.Println("子协程I = ", i)
time.Sleep(time.Second)
}
ch <- "我是子协程,我工作完毕"
}()
str := <-ch //没有数据前,阻塞
fmt.Println("str = ", str)
}
无缓冲的channel
无缓冲的通道是指在接收前没有能力保存任何值的通道。
这种类型的通道要求发生goroutine和接收gorutine同时准备好,才能完成发送和接收操作。否则通道会导致先执行发送或接收操作的goroutine阻塞等待。
这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个单独存在。
无缓冲的channel创建格式:
make(chan Type)
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
package main
import (
"fmt"
"time"
)
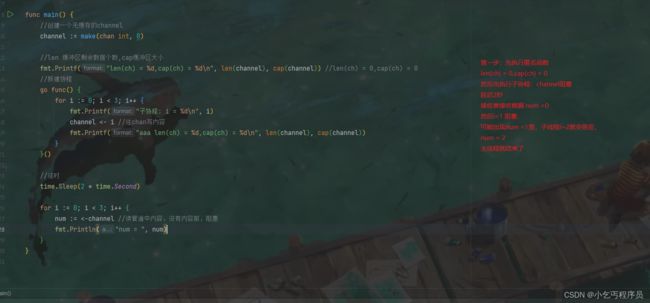
func main() {
//创建一个无缓存的channel
channel := make(chan int, 0)
//len 缓冲区剩余数据个数,cap缓冲区大小
fmt.Printf("len(ch) = %d,cap(ch) = %d\n", len(channel), cap(channel)) //len(ch) = 0,cap(ch) = 0
//新建协程
go func() {
for i := 0; i < 3; i++ {
fmt.Printf("子协程: i = %d\n", i)
channel <- i //往chan写内容
fmt.Printf("aaa len(ch) = %d,cap(ch) = %d\n", len(channel), cap(channel))
}
}()
//延时
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <-channel //读管道中内容,没有内容前,阻塞
fmt.Println("num = ", num)
}
}
len(ch) = 0,cap(ch) = 0
子协程: i = 0
num = 0
aaa len(ch) = 0,cap(ch) = 0
子协程: i = 1
aaa len(ch) = 0,cap(ch) = 0
子协程: i = 2
num = 1
num = 2
**阻塞:**由于某种原因数据没有到达,当前协程(线程)持续处于等待状态,直到条件满足,才接触阻塞。
**同步:**在两个或多个协程(线程)间,保持数据内容一致性的机制。
有缓冲的channel
有缓冲的通道是一种在被接收前能存储一个或者多个数据值的通道。
这种类型的通道并不强制要求goroutine之间必须同时完成发送和发送。通道会阻塞发送和接收动作的条件也不同。
只有通道中没有要接收的值时,接收动作才会阻塞。
只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的goroutine会在同一时间进行数据交换;有缓冲的通道没有这种保证。
当通道满或者为空的时候,就阻塞
有缓冲的channel创建格式:
make(chan Type,capcity)
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
package main
import (
"fmt"
"time"
)
func main() {
//创建一个有缓存的channel
channel := make(chan int, 3)
//len 缓冲区剩余数据个数,cap缓冲区大小
fmt.Printf("len(ch) = %d,cap(ch) = %d\n", len(channel), cap(channel)) //len(ch) = 0,cap(ch) = 3
//新建协程
go func() {
for i := 0; i < 3; i++ {
channel <- i //往chan写内容
fmt.Printf("子协程[%d] len(ch) = %d,cap(ch) = %d\n", i, len(channel), cap(channel)) //立马写三个
}
}()
//延时
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <-channel //读管道中内容,没有内容前,阻塞
fmt.Println("num = ", num)
}
}
len(ch) = 0,cap(ch) = 3
子协程[0] len(ch) = 1,cap(ch) = 3
子协程[1] len(ch) = 2,cap(ch) = 3
子协程[2] len(ch) = 3,cap(ch) = 3
num = 0
num = 1
num = 2
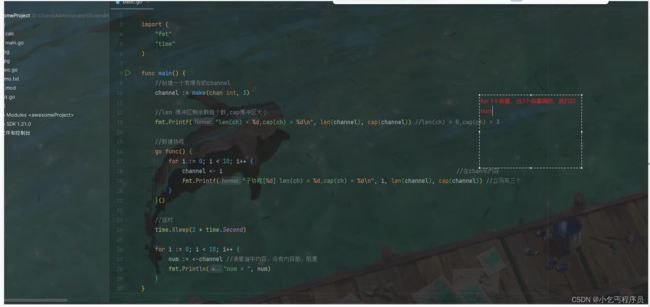
len(ch) = 0,cap(ch) = 3
子协程[0] len(ch) = 1,cap(ch) = 3
子协程[1] len(ch) = 2,cap(ch) = 3
子协程[2] len(ch) = 3,cap(ch) = 3
num = 0
子协程[3] len(ch) = 3,cap(ch) = 3
子协程[4] len(ch) = 3,cap(ch) = 3
num = 1
num = 2
num = 3
num = 4
num = 5
子协程[5] len(ch) = 3,cap(ch) = 3
子协程[6] len(ch) = 0,cap(ch) = 3
子协程[7] len(ch) = 1,cap(ch) = 3
子协程[8] len(ch) = 2,cap(ch) = 3
子协程[9] len(ch) = 3,cap(ch) = 3
num = 6
num = 7
num = 8
num = 9
关闭channel
如果发送者知道,没有更多的值需要发送到channel的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close函数来关闭channel实现。.
package main
import (
"fmt"
)
func main() {
//创建一个无缓存的channel
channel := make(chan int, 0)
//len 缓冲区剩余数据个数,cap缓冲区大小
fmt.Printf("len(ch) = %d,cap(ch) = %d\n", len(channel), cap(channel)) //len(ch) = 0,cap(ch) = 3
//新建协程
go func() {
for i := 0; i < 5; i++ {
channel <- i //往通道写数据 //往chan写内容
fmt.Printf("子协程[%d] len(ch) = %d,cap(ch) = %d\n", i, len(channel), cap(channel)) //立马写三个
}
//不需要再写数据时,关闭channel
close(channel)
}()
for true {
//if ok为true ,说明管道没有关闭
if num, ok := <-channel; ok == true {
fmt.Println("num = ", num)
} else {
//管道关闭
break
}
}
}
channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的,才去关闭channel;
关闭channel后,无法向channel 再发送数据(引发 panic 错误后导致接收立即返回零值);
关闭channel后,可以继续从channel接收数据;
对于nil channel,无论收发都会被阻塞。
通过range遍历channel内容
package main
import (
“fmt”
)
func main() {
//创建一个无缓存的channel
channel := make(chan int, 0)
//len 缓冲区剩余数据个数,cap缓冲区大小
fmt.Printf("len(ch) = %d,cap(ch) = %d\n", len(channel), cap(channel)) //len(ch) = 0,cap(ch) = 3
//新建协程
go func() {
for i := 0; i < 5; i++ {
channel <- i //往通道写数据 //往chan写内容
fmt.Printf("子协程[%d] len(ch) = %d,cap(ch) = %d\n", i, len(channel), cap(channel)) //立马写三个
}
//不需要再写数据时,关闭channel
close(channel)
}()
for num := range channel {
fmt.Println("num = ", num)
}
}
单向channel特点
默认情况下,通道时双向的,也就是,即可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而值希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。

可以将channel隐式转换为单向队列,只收或只发,不能将党项channel转换为普通的channel
var ch1 chan int // ch1是一个正常的channel,是双向的
var ch2 chan<- float64 // ch2是单向channel,只用于写float64数据
var ch3 <-chan int // ch3是单向channel,只用于读int数据
单向不能转换为双向
单向channel的应用
package main
import "fmt"
// 此通道只能写,不能读
func producer(channel chan<- int) {
for i := 0; i < 10; i++ {
channel <- i * i
}
close(channel)
}
/**
num = 0
num = 1
num = 4
num = 9
num = 16
num = 25
num = 36
num = 49
num = 64
num = 81
*/
// 此通道只能读,不能写
func consumer(channel <-chan int) {
for num := range channel {
fmt.Println("num = ", num)
}
}
func main() {
//创建一个无缓存的channel 双向
channel := make(chan int, 0)
//生产者,生产数字,写入channel
//新开一个协程
go producer(channel) //channel传参,引用传递
//消费者,从channel读取内容,打印
consumer(channel)
}
定时器
Timer是一个定时器,代表未来的一个单一事情,你可以告诉timer你要等待多长时间,它提供一个channel,在将来的那个时间那个channel提供一个时间值。
type Timer struct {
C <-chan Time
r runtimeTimer
}
它提供一个channel,在定时时间到达之前,没有数据写入timer.C会一直阻塞。直到定时时间到,向channel写入值,阻塞解除,可以从中读取数据。
package main
import (
"fmt"
"time"
)
func main() {
//创建一个定时器,设置时间为2秒,2秒后,往time通道写内容(当前时间)
timer := time.NewTimer(2 * time.Second)
fmt.Println("当前时间:", time.Now())
// 2秒后,往timer.C写数据,有数据后,就可以读取
t := <-timer.C //channel没有数据前后阻塞
fmt.Println("t = ", t)
}
package main
import (
"fmt"
"time"
)
// 验证 time.NewTimer(),时间到了,只会响应一次
func main() {
//创建一个定时器,设置时间为2秒,2秒后,往time通道写内容(当前时间)
timer := time.NewTimer(1 * time.Second)
for true {
<-timer.C //时间到只会写一次,导致死锁
fmt.Println("时间到")
}
}
Timer实现延时功能
package main
import (
"fmt"
"time"
)
func main() {
//延时2s后打印一句话
<-time.After(2 * time.Second) //定时2s,阻塞2s,2s后产生一个事件 往channel写内容
fmt.Println("时间到")
}
func main02() {
//延时2s后打印一句话
time.Sleep(2 * time.Second)
fmt.Println("时间到")
}
func main01() {
//延时2s后打印一句话
timer := time.NewTimer(2 * time.Second)
<-timer.C
fmt.Println("时间到")
}
定时器停止和重置
package main
import (
"fmt"
"time"
)
func main() {
timer := time.NewTimer(3 * time.Second)
ok := timer.Reset(1 * time.Second) //重置为一秒,此时三秒就无效
fmt.Println("Ok = ", ok)
<-timer.C
fmt.Println("时间到")
}
func main01() {
timer := time.NewTimer(3 * time.Second)
go func() {
<-timer.C
fmt.Println("子协程可以打印了,因为定时器的时间到")
}()
timer.Stop() //停止定时器 立马执行,timer就是无效的
for true {
}
}
Ticker的使用
Ticker是一个定时触发的计时器,它会以一个间隔(interval)往channel发送一个事件(当前时间),而channel的接收者可以以固定的时间间隔从channel中读取事件。
type Ticker struct {
C <-chan Time // The channel on which the ticks are delivered.
r runtimeTimer
}
package main
import (
"fmt"
"time"
)
func main() {
ticker := time.NewTicker(1 * time.Second)
i := 0
for true {
<-ticker.C
i++
fmt.Println("i = ", i)
if i == 5 {
ticker.Stop() //停止
break
}
}
}
select的作用
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述.
与switch语句可以选择任何可使用相等比较的条件相比,select有比较多的限制,其中最大的一条限制的就是每个case语句里必须是一个IO操作。
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
在一个select语句中,go语言会按顺序从头至尾评估每一个发送和接收的雨具。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能得情况:
1:如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。
2::如果没有default语句,那么select语句将被阻塞,直至至少有一个通信可以进行下去。
通过select实现斐波那契数列
package main
import "fmt"
// ch 只写,quit只读
func fibonacci(ch chan<- int, quit <-chan bool) {
x, y := 1, 1
for true {
//监听channel数据流动
select {
case ch <- x:
x, y = y, x+y
case flag := <-quit:
fmt.Println("flag =", flag)
return
}
}
}
func main() {
ch := make(chan int) //通信数字
quit := make(chan bool) //程序是否结束
//消费者 从channel读取内容
//新建协程
go func() {
for i := 0; i < 8; i++ {
num := <-ch //取数据,没有数据就会阻塞
fmt.Println(num)
}
//可以停止了
quit <- true
}()
//生产者 产生数字,写入channel
fibonacci(ch, quit)
}
select实现的超时机制
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int) //通信数字
quit := make(chan bool) //程序是否结束
//新建协程
go func() {
for true {
select {
case num := <-ch: //取数据
fmt.Println("num =", num)
case <-time.After(3 * time.Second):
fmt.Println("超时")
quit <- true
}
}
}()
//写数据
for i := 0; i < 5; i++ {
ch <- i //写数据
time.Sleep(time.Second)
}
<-quit //没有数据阻塞在这里
fmt.Println("程序结束")
}