习题练习 C语言(暑期第四弹)

自我小提升!
- 前言
- 一、数组
- 二、指针运算
- 三、统计每个月兔子的总数
- 四、双指针的应用
- 五、判断指针
- 六、珠玑妙算
- 七、两数之和
- 八、数组下标
- 九、指针
- 十、寻找峰值
- 十一、二级指针
- 十二、大端小端
- 十三、无符号参数
- 十四、数对
- 十五、截取字符串
- 总结
前言
重要的事说三遍!
学习!学习!学习!
一、数组
若有定义 int a[8]; ,则以下表达式中不能代表数组元素 a[1] 的地址的是( )
A: &a[0]+1
B: &a[1]
C:&a[0]++
D: a+1
题目解析:
D选项a计算时是首元素地址,再加1,就是a[1]的地址,AB明显对,C选项a[0]先和++结合,形成一个表达式,不能对表达式取地址,会报错
题目答案:
C
二、指针运算
以下选项中,对基本类型相同的两个指针变量不能进行运算的运算符是( )
A: +
B: -
C: =
D: ==
题目解析:
A错误,因为两个地址相加无意义也可能越界,所以规定不允许指针相加。B选项,可以求出两个数据元素储存位置之间的相
隔同数据类型的元素个数,C选项,赋值,没问题,D选项,判断两指针是否相同
题目答案:
A
三、统计每个月兔子的总数
题目链接:OJ链接
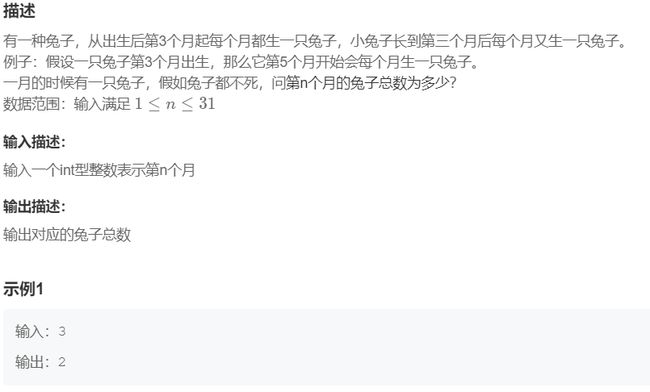
题目解析:
这道题的关键在于寻找数字之间的规律,如果细心的同学会发现这其实是一个斐波那契数列。第 n 个月的兔子数量实际上就是第 n-1 个斐波那契数。
题目答案:
#include 四、双指针的应用
有以下函数,该函数的功能是( )
int fun(char *s)
{
char *t = s;
while(*t++);
return(t-s);
}
A: 比较两个字符的大小 B: 计算s所指字符串占用内存字节的个数
C: 计算s所指字符串的长度 D: 将s所指字符串复制到字符串t中
题目解析:
循环在*t为0时停止,同时t++,t最后会停在字符串结束的’\0’之后的一个位置,t作为尾部指针减去头部指针就是整个字符串占用内存的字节数,包含\0在内;而c答案字符串长度不包括最后的\0
题目答案:
B
五、判断指针
以下程序运行后的输出结果是( )
include <stdio.h>
int main()
{
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}, *p = a + 5, *q = NULL;
*q = *(p+5);
printf("%d %d\n", *p, *q);
return 0;
}
A: 运行后报错 B: 6 6 C: 6 11 D: 5 10
题目解析:
指针q初始化为NULL,接着又解引用指针q,是错误的,对NULL指针是不能解引用的。
题目答案:
A
六、珠玑妙算
题目链接:OJ链接

提示:
len(solution) = len(guess) = 4
solution和guess仅包含"R",“G”,“B”,"Y"这4种字符
题目解析:
遍历两个数组,统计猜中次数和伪猜中次数
猜中次数:若位置相同且颜色字符也相同在猜中次数计数器+1
伪猜中次数:颜色相同,但是在不同位置,这时候只需要除去猜中位置之外,统计两个数组中各个字符出现的数量,取较小的一方就是每种颜色伪猜中的数量了
题目答案:
int* masterMind(char* solution, char* guess, int* returnSize){
*returnSize=2;
static int arr[2]={0};
arr[0] = 0; arr[1] = 0;//静态空间不会进行二次初始化因此每次重新初始化,可以使用memset函数
int solu[26]={0};//26个字符位 solution 四种颜色数量统计
int gue[26]={0};//26个字符位 guess 四种颜色数量统计
for(int i=0;i<4;i++){
if(solution[i]==guess[i])//位置和颜色完全一致则猜中数量+1
arr[0]++;
else{
solu[solution[i]-'A']+=1;///统计同一位置不同颜色的两组颜色数量,伪猜中不需要对应位置相同,只需要有对应数量的颜色就行
gue[guess[i]-'A']+=1;
}
}
for(int i=0;i<26;i++){//在两个颜色数量统计数组中查看颜色数量,取相同位置较小的一方就是为猜中数量
arr[1]+=(solu[i]<gue[i]?solu[i]:gue[i]);
}
return arr;
}
七、两数之和
题目链接:OJ链接
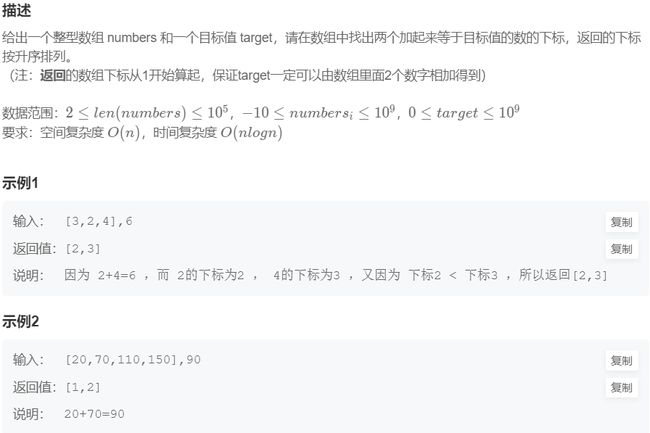
题目解析:
本题的基本思想是双重遍历思想
但是必须根据条件做出相应调整,防止浪费时间
题目答案:
int* twoSum(int* numbers, int numbersLen, int target, int* returnSize ) {
* returnSize=2;
static int arr[2]={0};
memset(arr, 0x00, sizeof(arr));//静态空间不会二次初始化,因此手动初始化
for(int i=0;i<numbersLen;i++){
if (numbers[i] > target)//一旦大于目标数,可以直接跳过
continue;
for(int j=i+1;j<numbersLen;j++){//配对的数直接从i+1开始,防止出现重复配对,造成时间浪费
if(numbers[i]+numbers[j]==target){
arr[0]=i+1;
arr[1]=j+1;
return arr;
}
}
}
* returnSize=0;
return NULL;
}
八、数组下标
有如下代码,则 *(p[0]+1) 所代表的数组元素是( )
int a[3][2] = {1, 2, 3, 4, 5, 6}, *p[3];
p[0] = a[1];
A: a[0][1]
B: a[1][0]
C: a[1][1]
D:a[1][2]
题目解析:
p是一个指针数组,p[0] = a[1];此处a[1]是二维数组的第二行的数组名,数组名表示首元素的地址,a[1]是a[1][0]的地址,所以p[0]中存储的是第2行第1个元素的地址,p[0]+1就是第二行第2个元素的地址,*(p[0]+1)就是第二行第二个元素了。所以C正确。
题目答案:
C
九、指针
关于指针下列说法正确的是【多选】( )
A: 任何指针都可以转化为void *
B: void *可以转化为任何指针
C:指针的大小为8个字节
D: 指针虽然高效、灵活但可能不安全
题目解析:
C选项,指针占几个字节要看平台,64位环境下8个字节,32位环境下4个字节
题目答案:
ABD
十、寻找峰值
题目链接:OJ链接

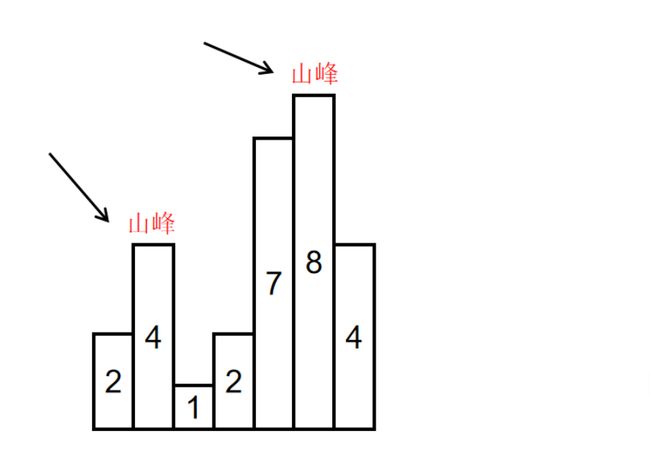
题目解析:
二分思想,
中间比右边大,认为从右往左半边递增,则把 right 不断向左靠拢 right=mid ,注意不能是 mid-1 ,因为这个位置有可能就是峰值点。
直到遇到中间比右边小了,意味着数据开始递降了,则 left 向右偏移, left=mid+1 ; 而一旦 mid+1 位置大于了right ,意味着刚好这个 mid+1 位置,是一个左半边-右往左递降,右半边-右往左递增的点,就是一个峰值点。
题目答案:
int findPeakElement(int* nums, int numsLen ) {
//边界情况处理,1个元素前后都是负无穷 以及 0号位置大于1号位置,-1位置负无穷的情况
if (numsLen == 1 || nums[0] > nums[1]) return 0;
//末尾位置数据大于上一个位置数据,而nums[numsLen]负无穷的情况
if (nums[numsLen - 1] > nums[numsLen - 2]) return numsLen - 1;
int left = 0, right = numsLen - 1, mid;
while (left < right) {
mid = left + (right - left) / 2;
if (nums[mid] < nums[mid + 1])//中间比右边小,意味着右边肯定有个峰值
left = mid + 1;
else //否则在左边包括当前位置肯定有个峰值
right = mid;
}
return left;
}
十一、二级指针
请指出以下程序的错误【多选】( )
void GetMemory(char **p, int num)
{
if(NULL == p && num <= 0)//1
return;
*p = (char*)malloc(num);
return;
}
int main()
{
char *str = NULL;
GetMemory(&str, 80); //2
if(NULL != str)
{
strcpy(&str, "hello"); //3
printf(str); //4
}
return 0;
}
A: 1 B: 2 C: 3 D: 4
题目解析:
第1处两种情况之一成立都是要返回的,应该用或,此处用与错误。在语句GetMemory(&str,100);中传入str的地址,在语句char*str=NULL;中str初始化为空指针,但是str指针变量也有地址,所以参数char**p里面的p保存的是指针变量str的地址,所以调用GetMemory函数之后,动态开辟的空间的地址存放在了str中,在函数返回之后没有释放内存,但是这不会导致程序错误,只会导致内存泄漏。第3处用&str是错的,应该直接用str,是刚申请下来的空间首地址,可以用来接收字符串的copy。
题目答案:
AC
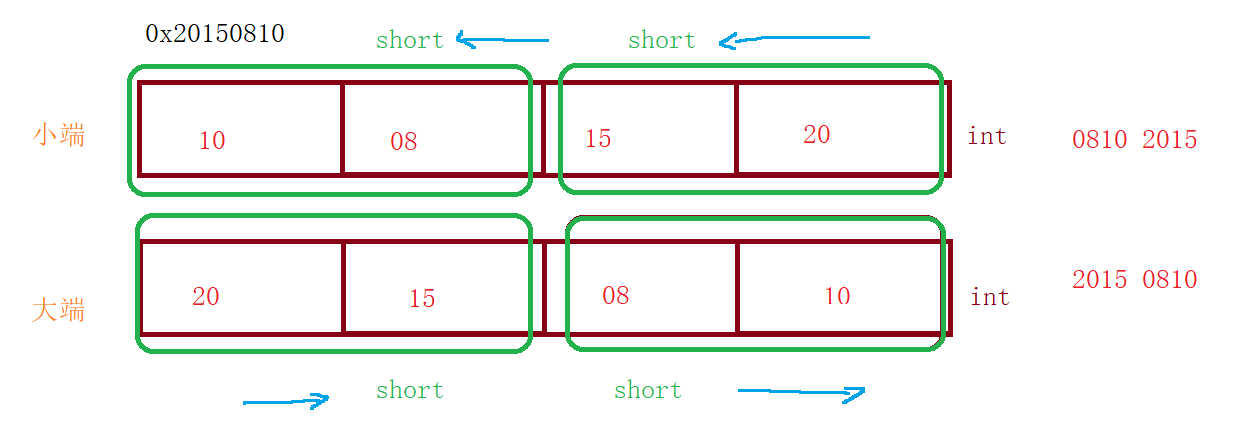
十二、大端小端
请问下列代码的输出结果有可能是哪些【多选】( )
#include A: 2015,810 B: 50810,201 C: 810,2015 D:`20150,810
题目解析:
对于0x20150810
如果按照大端模式存储:从低地址到高地址:20 15 08 10 输出从低地址到高地址:20 15 08 10
如果按照小端模式存储:从低地址到高地址:10 08 15 20 输出从高地址到低地址:08 10 20 15
此数以int类型赋值给联合体x.a,而以结构成员b和c分开访问,分别拿到低地址的2个字节和高地址的2个字节,大端下是2015和810,小端下是810和2015
题目答案:
AC
十三、无符号参数
下面这个程序执行后会有什么错误或者效果【多选】( )
#define MAX 255
int main()
{
unsigned char A[MAX], i;
for(i = 0; i <= MAX; i++)
A[i] = i;
return 0;
}
A: 数组越界 B: 死循环 C: 栈溢出 D: 内存泄露
题目解析:
数组下标越界:数组大小255,但是当a[255]就是256个元素,导致越界了。死循环:这个是因为无符号字符型的变量大小在0-255之间,所以说i永远不可能大于255的,是个死循环。内存泄漏:创建的临时变量,在栈中,应该会由系统自动释放,所以应该是不存在内存泄漏的问题。栈溢出:属于缓冲区溢出的一种。栈溢出是由于C语言系列没有内置检查机制来确保复制到缓冲区的数据不得大于缓冲区的大小,因此当这个数据足够大的时候,将会溢出缓冲区的范围
题目答案:
AB
十四、数对
题目链接:OJ链接

题目解析:
假设输入 n=10 , k=3 ;
当 y <=k 时,意味着任何数字取模y的结果都在 [0, k-1]之间,都是不符合条件的。
当 y = k+1=4 时,x符合条件的数字有 3,7
当 y = k+2=5 时,x符合条件的数字有 3,4,8,9
当 y = k+3=6 时,x符合条件的数字有 3,4,5,9,10
当 y = k+n时,
x小于y当前值,且符合条件的数字数量是:y-k个,
x大于y当前值,小于2*y的数据中,且符合条件的数字数量是:y-k个
从上一步能看出来,在y的整数倍区间内,x符合条件的数量就是 (n / y) * (y - k)个
n / y 表示有多少个完整的 0 ~ y区间, y - k 表示有每个区间内有多少个符合条件的数字
最后还要考虑的是6…往后这种超出倍数区间超过n的部分的统计
n % y 就是多出完整区间部分的数字个数,其中k以下的不用考虑,则符合条件的是 n % y - (k-1) 个
这里需要注意的是类似于9这种超出完整区间的数字个数 本就小于k的情况,则为0
最终公式:(n / y) * (y - k) + ((n % y < k) ? 0, (n % y - k + 1));
题目答案:
#include 十五、截取字符串
题目链接:OJ链接
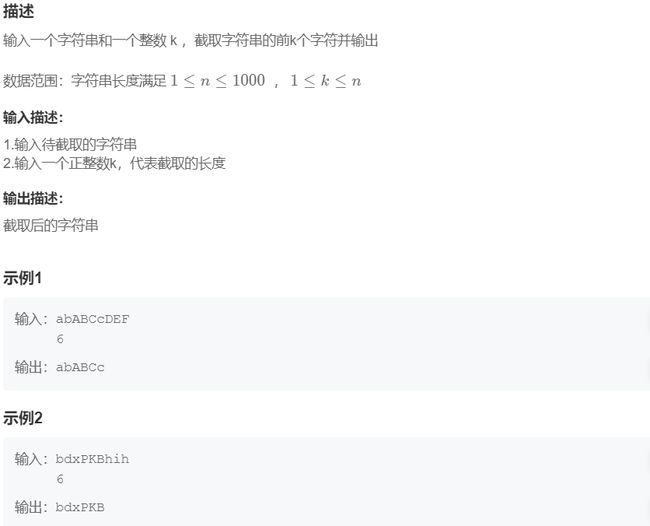
题目答案:
#include 还有一种更简洁的方法
题目解析:
截取字符串前 n 个字符,只需要将数组 n 下标位置的数据替换为字符串结尾标志即可
#include 总结
重要的事说三遍!
成功!成功!成功!
暑假期间所有的题目就到此为止啦!
让我们一起迎接下一个阶段的学习吧!