用MinIO对象存储构建企业数据集中备份系统
1、引言
现代企业的运营离不开IT系统的支撑,而数据则是IT系统的核心,也是企业的核心资产,关乎企业的生存与发展。一旦出现数据信息丢失或毁损,将严重影响企业和客户利益,甚至影响到企业的行业竞争力和市场声誉,其重要性不言而喻。但是就像人生不如意事十有八九,人为操作失误,设备系统故障、病毒侵袭、自然灾害等威胁数据安全的因素往往就在不经意间骤然发生。作为IT系统管理员,总是要千方百计地维护IT系统业务连续性和数据的完整性。通常会采取部署防火墙,安装防病毒软件,系统双活、异地容灾等措施,而数据备份则作为数据保护的最后手段,是数据安全的最后一道防线。
之前有一定规模数据量的企业会购买备份软件及大容量磁带库来实现企业数据的集中备份,这是当时性价比较高的数据备份办法。随着分布式对象存储的出现与普及,用对象存储构建企业数据集中备份系统更具有优势,主要表现在:
- 更低拥有成本
商用备份产品一般都比较昂贵,备份节点越多收费越高。每年还需高额维保费,产品的升级、扩容、维保完全依赖厂商;而开源对象存储只需普通的服务器及交换机,无软件方面的成本,部署及运维较简单,市场上人才储备充足,系统自主可控。 - 更高的可靠性、更快的响应、更大的并发访问能力
- 磁带会随着读写次数的增多发生磨损,其固有的非密封性也容易出现霉变,可靠性低于密闭的硬盘。分布式对象存储以硬盘为存储介质,数据块有两个以上副本(MinIO采用纠删码,允许一半磁盘损坏),可靠性更高;
- 磁带库机械手抓带,送入驱动器,驱动器导带等都是机械操作,响应速度慢。分布式对象存储从硬盘读写数据,响应更快;
- 磁带库并发读写能力有限(受驱动器数量限制),随着业务的发展,企业数据量以几何级数增长,磁带库难以及时完成备份任务。而分布式存储每个节点都可以并发读写,并发和吞吐能力极高。
- 远程复制能力
某些行业监管机构要求行业机构数据必须有远程异地备份。分布式对象存储具备远程数据复制的能力,而磁盘库显然不具备。
2、关于MinIO
2.1 概述
MinIO 对象存储系统是为海量数据存储、人工智能、大数据分析而设计,基于Apache License v2.0 开源协议的对象存储系统,它完全兼容 Amazon S3 接口,单个对象最大可达 5TB,适合存储海量图片、视频、日志文件、备份数据和容器/虚拟机镜像等。关于MinIO 对象存储的具体工作原理在网上可搜到大量的资料,本文不再赘述,这里简单总结一下使用体验:
- 部署简单:全部运行代码就是一个40M+的二进制文件(Go语言开发),没有复杂的安装步骤,一条简单的命令即可启动对象存储服务;
- 扩容简单:采用联盟模式添加集群,极大简化了扩容流程。规避了传统分布式存储扩容所需要的数据迁移,降低了系统出错概率,系统更加稳定可靠;
- 性能卓越:具有超高的读写性能。据MinIO官方数据,在标准硬件上,MinIO的读写速率可高达100GB/s以上;
- 节省空间:MinIO纠删码比传统分布式存储多副本模式节省硬盘空间;
- 运维简单:MinIO是非常轻量级的对象存储,运维极其简单。
不足之处是:
不支持向集群中添加单个节点并进行自动调节的扩容方式。
2.2 MinIO部署
MinIO支持以单机模式、分布式集群模式、联盟模式部署。
软件下载(linux-amd64):
# wget https://dl.min.io/server/minio/release/linux-amd64/minio -P /usr/local/bin/
# chmod +x /usr/local/bin/minio
2.2.1 单机模式
仅用一台主机作为MinIO Server,又分两种启动模式:
- 非纠错码单机模式(non-erasure code standalone mode)
# minio server /data
对象直接存储在/data目录下,不会建立副本,也不会启用纠删码机制。
该模式最大的好处是没有技术门槛,“开箱即用”,缺点是单机无高可用保障。如果您的对象存储容量要求不大,访问不太频繁,服务无需全天候在线,该模式不失为一种简便易行的好办法。
- 纠错码单机模式(erasure code standalone mode)
# minio server /data1 /data2 /data3 /data4
即启动minio server时传入多个目录参数(每个目录对应一块硬盘)。系统自动生成若干纠删组,每个纠删组包含4至16块硬盘。存储数据对象时,先进行纠删分片,默认策略是得到相同数量的数据分片和校验分片,然后分散存储至纠删组内的硬盘,纠删组内一半硬盘损坏不丢数据。同样,单机无高可用保障。
2.2.2 分布式集群模式
在多台主机上部署MinIO服务,组建为分布式存储集群,对外以一个整体提供服务。如一个由四个节点,每节点2块硬盘的MinIO分布式集群启动命令(在集群所有节点上运行):
# export MINIO_ACCESS_KEY=QS8W8H15JS0F6ZRN0F9S
# export MINIO_SECRET_KEY=IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4
# minio server --address :9000 http://172.16.2.{101...104}/data{1...2}
系统自动在集群内生成若干纠删组,每个纠删组包含4至16块硬盘。存储数据对象时,先进行纠删分片,然后将数据分片和校验分片分散存储至纠删组内的硬盘。与“纠错码单机模式”不同的是:分布式集群纠删组的硬盘会尽量取自于不同节点,避免单机模式无高可用性的弊端,最多允许一半节点宕机,数据仍可读。
MinIO集群采用去中心化架构,各节点间为对等关系,连接至任一节点均可实现对集群的访问,通过Load Balancer或DNS轮询等方式实现节点间的负载均衡。由于集群每个节点都能提供对象存储服务,其整体性能优于“机头”式的对象存储。
MinIO集群要求节点的硬件配置,磁盘数量完全对等。MinIO集群节点数不少于4个,但一般不超过32个,集群通过分布式锁保证强一致性,若集群节点数过大,维护强一致性将带来性能问题。
2.2.3 联盟模式
联盟模式即通过引入etcd和coreDNS,将多个MinIO分布式集群在逻辑上组成一个联盟,对外以一个整体提供服务,并提供统一的命名空间。
MinIO联盟集群的架构下图所示。
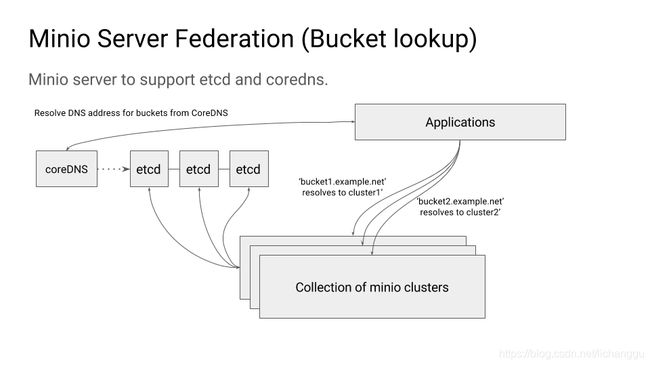 说明:
说明:
联盟会将所有存储桶域名和存储桶实际所在的集群节点IP地址写入etcd中;
coreDNS解析储桶域名对应的集群节点IP;
外部应用依赖coreDNS定位存储桶的实际存储节点,再进行数据访问。
启动包含两个MinIO分布式集群的联盟:
**在MinIO集群1所有节点上运行(4节点,每节点2块盘)**
# export MINIO_ETCD_ENDPOINTS="http://etcd1:2379,http://etcd2:2379,http://etcd3:2379"
# export MINIO_DOMAIN=domain.com
# export MINIO_PUBLIC_IPS=172.16.2.101,172.16.2.102, 172.16.2.103,172.16.2.104
# minio server http://minio{101...104}.domain.com/data{1...2}
**在MinIO集群2所有节点上运行(6节点,每节点3块盘):**
# export MINIO_ETCD_ENDPOINTS="http://etcd1:2379,http://etcd2:2379,http://etcd3:2379"
# export MINIO_DOMAIN=domain.com
# export MINIO_PUBLIC_IPS=172.16.2.105,172.16.2.110
# minio server http://minio{105...110}.domain.com/data{1...3}
联盟模式部署不要求各集群的节点数和磁盘数对等;联盟中单个集群故障不影响其它集群;通过不断添加新的集群来扩大整个系统,MinIO对象存储系统几乎可以无限的扩展总体性能和容量。
2.3 MC客户端
MinIO Client (mc)是用Go语言开发的MinIO客户端软件,兼容Amazon S3、Ceph RGW等对象存储,支持AWS Signature v2和v4。目前官网上有Windows、linux、darwin三种平台mc可下载,下载地址:https://dl.min.io/client/mc/release
软件下载(linux-amd64):
# wget https://dl.min.io/client/mc/release/linux-amd64/mc -P /usr/local/bin/
# chmod +x /usr/local/bin/mc
常用命令:
**增加alias:obs, alias相当于访问某一对象存储(MinIO、AWS S3、Ceph RGW等)的handle**
# mc alias set obs http://172.16.2.101/ QS8W8H15JS0F6ZRN0F9S IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4
**查询alias**
# mc alais ls
**创建存储桶**
# mc mb obs/bucket1
**上传文件**
# mc cp /tmp/test.txt obs/bucket1
**查看存储桶**
# mc ls obs/bucket1
[2021-04-02 14:53:08 CST] 0B test.txt
**帮助**
# mc --help
3、数据备份
对象存储可以用于两大类数据的备份:一类是指普通文件,如office文档、图片文件,视频影像文件等,普通文件的特点是其内容不会持续改变;第二类是数据库,数据库的数据文件一直处于open状态,其内容是持续变化的。这两类数据也是企业最核心的数据。其它诸如操作系统备份、虚拟机备份、CDP实时备份等,对象存储显然不太适合。
下面分别介绍普通文件及数据库的备份办法。
3.1 普通文件备份
利用mc、s3cmd、aws-cli工具将普通文件备份到对象存储。mc支持Windows、linux、darwins平台,s3cmd、aws-cli则是用python开发,支持多种平台。
mc备份示例:
# mc cp test.dat obs/bucket1
或者
# mc mirror /backup obs/bucket1
s3cmd配置及备份示例:
# s3cmd --configure
Access Key: QS8W8H15JS0F6ZRN0F9S
Secret Key: IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4
Default Region [US]: default
S3 Endpoint [s3.amazonaws.com]: 172.16.2.101:9000
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 172.16.2.101:9000/%(bucket)
Encryption password:
Use HTTPS protocol [Yes]: No
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name: ENTER
Test access with supplied credentials? [Y/n] n
Save settings? [y/N] y
# s3cmd mb s3://bucket2
# s3cmd put test.dat s3://bucket2
aws cli配置及备份示例:
# aws configure
AWS Access Key ID [None]: Q3AM3UQ867SPQQA43P2F
AWS Secret Access Key [None]: zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG
Default region name [None]: default
Default output format [None]: ENTER
# aws --endpoint-url https://172.16.2.101:9000 s3 mb s3://bucket3
# aws --endpoint-url https://172.16.2.101:9000 s3 cp test.dat s3://bucket3
3.2 数据库备份
数据库一般都具有数据转储的工具或SQL命令,如Oracle exp/expdp、mysql mysqldump、SQLServer backup database等。数据库最简单的备份方式是:利用数据库转储工具或命令将数据库转储,然后备份转储文件。数据库转储备份属于逻辑备份,对于小型数据库是可行的,对于TB级大型数据库则力所不及,因为转储可能要耗费很长时间,转储文件巨大,本地磁盘容量可能不足,大型数据库一般会选择物理备份,将数据库直接备份到大容量的磁带库。
3.2.1 Oracle数据库备份
RMAN是Oracle数据库的备份与恢复组件,DBA通常会利用RMAN把数据库物理备份到磁盘或磁带库。从Oracle 9i R2开始,通过在Oracle服务器上安装安全云备份模块(Oracle Secure Backup Cloud Module,OSB云模块),RMAN可以直接备份数据到AWS S3或兼容S3的对象存储,无需备份到本地后再上传。参考:https://docs.oracle.com/database/121/RCMRF/web_services.htm#RCMRF90489。
这里简单介绍一下部署OSB云模块及RMAN备份到MinIO的步骤:
- 下载OSB云模块安装文件
安装文件osbws_installer.zip下载地址:
https://www.oracle.com/database/technologies/secure-backup-s3.html
解压后生成两个文件,
osbws_install.jar: OSB云模块安装jar包,支持多种平台
osbws_readme.txt:OSB云模块安装说明文件
- 在Oracle主机上安装OSB云模块
# su - oracle
$ java -jar ./osbws_install.jar \
-AWSID QS8W8H15JS0F6ZRN0F9S \
-AWSKey IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4 \
-walletDir $ORACLE_HOME/dbs/osbws_wallet \
-libDir $ORACLE_HOME/lib \
-awsEndPoint 172.16.2.101 \
-awsPort 80 \
-no-import-certificate \
-location default
说明:
- Java版本1.7 或以上;
- 如果MinIO没有启用ssl,这里需加上no-import-certificate参数;
- awsPort必须是80(http)或443(https),否则会提示签名错误。MinIO默认端口是9000,可通过在其前面加haproxy或ngnix代理解决,或者启动MinIO时指定服务端口为80或443;
- 安装的最后会从Oracle官网下载OSB云模块库压缩文件osbws_linux64.zip。如果数据库服务器不能访问互联网,则会提示下载错误。可从我的百度网盘提取,提取码:8888,手工解压到$ORACLE_HOME/lib下即可;
- 安装完成后,会在$ORACLE_HOME/dbs目录下生成:
osbws{sid}.ora: OSB云模块参数文件
osbws_wallet目录: 包含加密的AWSID、AWSKEY等信息
- 修改OSB云模块参数文件
这里假设数据库sid为tadb
$ vi $ORACLE_HOME/dbs/osbwstadb.ora
OSB_WS_HOST=http://172.16.2.101
#OSB_WS_LOCATION=default
OSB_WS_BUCKET=bucket1
OSB_WS_VIRTUAL_HOST=FALSE
OSB_WS_WALLET=’location=file:/oracle/product/11.2/db_1/dbs/osbws_wallet CREDENTIAL_ALIAS=minio_aws’
- RMAN配置
RMAN> show all;
CONFIGURE DEFAULT DEVICE TYPE TO 'SBT_TAPE';
CONFIGURE CHANNEL DEVICE TYPE 'SBT_TAPE' PARMS 'SBT_LIBRARY=/oracle/product/11.2/db_1/lib/libosbws.so,SBT_PARMS=(OSB_WS_PFILE=/oracle/product/11.2/db_1/dbs/osbwstadb.ora)';
……
- RMAN备份示例
$ rman target /
RMAN> backup tablespace users;
Starting backup at 20210405 10:27:53
……
piece handle=g6vrh8l9_1_1 tag=TAG20210405T102753 comment=API Version 2.0,MMS Version 12.2.0.2
channel ORA_SBT_TAPE_1: backup set complete, elapsed time: 00:00:03
Finished backup at 20210405 10:27:56
- RMAN恢复示例
RMAN> shutdown immediate
RMAN> host '/bin/rm /oradata/tadb/users01.dbf';
RMAN> startup mount
RMAN> restore tablespace users;
……
channel ORA_SBT_TAPE_1: restore complete, elapsed time: 00:00:01
Finished restore at 20210407 14:11:54
RMAN> recover tablespace users;
……
media recovery complete, elapsed time: 00:00:00
Finished recover at 20210407 14:12:00
RMAN> alter database open;
database opened
3.2.2 Mysql数据库备份
xtrabackup是 Percona公司开发的一个用于MySQL数据库备份的开源工具,支持MySQL、Percona server和MariaDB,是广受欢迎的MySQL物理备份工具。官网地址:https://www.percona.com/
xtrabackup只能备份innoDB和xtraDB两种数据引擎的表,不能备份MyISAM数据表。从2.4.14版本开始(对应于mysql5.7),支持stream模式直接存储到AWS S3或兼容S3的对象存储,无需备份到本地后再上传。
这里也简单介绍一下部署及备份恢复过程:
- 下载xtrabackup
# wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.9/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
- 安装xtrabackup
# yum install -y ./percona-xtrabackup-24-2.4.9-1.el7.x86_64.rpm
- 备份示例
# xtrabackup --backup --stream=xbstream \
--user=root --password=123456 \
--extra-lsndir=/tmp --target-dir=/tmp | xbcloud put \
--storage=s3 --s3-endpoint=http://172.16.2.101 \
--s3-access-key='QS8W8H15JS0F6ZRN0F9S' \
--s3-secret-key='IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4' \
--s3-bucket='mysql' \
--parallel=10 \
--insecure \
--s3-bucket-lookup=PATH $(date '+%Y%m%d%H%M%S')-full_backup
……
210405 18:05:54 completed OK!
210405 18:05:54 xbcloud: Upload completed.
- 恢复示列
# systemctl stop mysqld
# cd /var/lib/mysql
# rm -rf ib_buffer_pool ibdata1 mysql performance_schema sys
# xbcloud get \
--storage=s3 --s3-endpoint=http://172.16.2.101 \
--s3-access-key='QS8W8H15JS0F6ZRN0F9S' \
--s3-secret-key='IRDCiiHxhVd5eDbkcVRh77R00VdS3NTgx5J7JXg4' \
--s3-bucket='mysql' \
--parallel=10 \
--insecure \
--s3-bucket-lookup=PATH 20210405180549-full_backup 2>download.log | xbstream -x -C /var/lib/mysql --parallel=10
# chown -R mysql:mysql /var/lib/mysql
# systemctl start mysqld
3.2.3 SQL Server数据库备份
目前还没有SQL Server数据库直接备份到对象存储的工具。SQL Server的备份办法是:通过其SQL命令BACKUP DATABASE把数据库转储出来,然后把转储文件上传到对象存储。
这里也简单演示一下备份及恢复过程:
- 编写备份脚本
C:\> type backup.bat
set tag=%Date:~0,4%%Date:~5,2%%Date:~8,2%
set db=%1%
if "%db%"=="" exit
echo BACKUP DATABASE %db% TO DISK='C:\SQLdata\Backup\%db%_%tag%.bak' > c:\backup.sql
sqlcmd –S localhost –U sa –P xxx -i c:\backup.sql
mc cp C:\SQLdata\Backup\%db%_backup_%tag%.bak obs/sqlserver
- 备份示例
C:\> backup.bat oiw
…
已处理百分之 92。
已为数据库 'oiw',文件 'oiw' (位于文件 1 上)处理了 328 页。
……
- 恢复示例
C:\>mc cp obs/sqlserver/oiw_backup_20210407.bak C:\SQLdata\Backup
C:\>sqlcmd –S localhost –U sa –P xxx
1> drop database oiw
2> go
1> RESTORE DATABASE oiw FROM DISK='C:\SQLdata\Backup\oiw_20210407.bak'
2> GO
已为数据库 'oiw',文件 'oiw' (位于文件 1 上)处理了 328 页。
……
3.2.4 其他数据库备份
一般数据库也没有专用的软件或agent直接备份数据到对象存储,其备份方法类似SQL Server备份:先转储数据库,然后备份转储文件。也有一些应用的数据库对数据文件一致性要求不高,直接备份其数据文件即可,需根据具体情况具体分析。
4、数据同步复制
利用MinIO Client(mc)的mirror命令,可轻松实现文件系统和对象存储之间,对象存储与对象存储之间的数据同步复制。mc mirror同步支持的对象存储不仅仅是MinIO,也包括兼容AWS S3的任何对象存储。
**同步本地目录到对象存储**
# mc mirror --overwrite --remove --watch /backup obs/backup
**同步对象存储site-A到对象存储site-B**
# mc mirror --overwrite --remove --watch site-A/backup site-B/backup
**甚至可以交叉同步复制,参见mc mirror --help**
Site-A: $ mc mirror --active-active siteA siteB
Site-B: $ mc mirror --active-active siteB siteA
(此处obs、site-A、site-B 是对象存储alias,可以是兼容AWS S3的任何对象存储)
有些行业机构的数据必须有异地备份, mc mirror一条简单的命令就帮助用户实现需求。
5、总结
本文简要介绍了用对象存储作为企业数据备份系统的优势,MinIO部署模式,数据备份方法,数据同步复制等。MinIO极简设计、性能卓越、运维简单。是企业数据集中备份的理想解决方案。此外,MinIO也非常适合作为医疗影像、视频监控、视频点播等海量数据的静态资源服务器,互联网上这类文章很多,不赘述。
本文“MinIO部署”一节的内容参考或摘录了中国农业银行李云婷,艾明浩的文章:https://blog.csdn.net/csdnnews/article/details/114860023,特此申明,并对作者表示感谢。