TTS | VocGAN声码器训练自己的数据集
哈喽,今天给大家介绍的是如何使用VocGAN声码器训练自己的数据集。
原文
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
想要论文解读,请参考我的这篇文章~
本博客主要包括以下内容:
目录
1.环境设置
2.数据集处理
2.1.数据集LJSpeech
2.2.数据集KSS
3.训练数据集
3.1.训练LJSpeech
4.训练自定义数据集
推理
过程中遇到的错误及解决
【PS1】AttributeError: module 'torch._C' has no attribute 'DoubleStorageBase'
【PS2】AssertionError: sample rate mismatch. expected 22050, got 48000 at /workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs/72.wav
【PS3】ValueError: num_samples should be a positive integer value, but got num_samples=0
扩展
1.环境设置
git clone https://github.com/rishikksh20/VocGAN
cd VocGAN
conda create -n gan python=3.8
conda activate gan
pip install -r requirements.txt
- 下载数据集进行训练。这可以是任何采样率为 22050Hz 的 wav 文件。(论文中使用了LJSpeech)
- 预处理:
python preprocess.py -c config/default.yaml -d [data's root path] - 编辑配置
yaml文件
修改preprocess.py中的配置文件和数据集路径
2.数据集处理
2.1.数据集LJSpeech
新建一个文件夹data,下载数据集LJSpeech,然后解压缩,新建一个mels文件夹.可参考【LJSpeech数据集下载】13100个语音
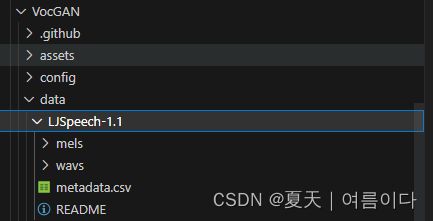
python preprocess.py -c config/ljs.yaml -d /workspace/tts/VocGAN/data/LJSpeech-1.1/wavs 运行后出现![]()

然后进入下一步3.训练数据集
2.2.数据集KSS
在kss文件夹下新建了文件夹valid,mels
data: # root path of train/validation data (either relative/absoulte path is ok)
train: '/workspace/tts/Fastspeech2-Korean/data/kss/wavs_bak'
validation: '/workspace/tts/Fastspeech2-Korean/data/kss/valid'
mel_path: '/workspace/tts/Fastspeech2-Korean/data/kss/mels'
eval_path: ''
---
train:
rep_discriminator: 1
discriminator_train_start_steps: 100000
num_workers: 8
batch_size: 16
optimizer: 'adam'
adam:
lr: 0.0001
beta1: 0.5
beta2: 0.9
---
audio:
n_mel_channels: 80
segment_length: 16000
pad_short: 2000
filter_length: 1024
hop_length: 256 # WARNING: this can't be changed.
win_length: 1024
sampling_rate: 22050
mel_fmin: 0.0
mel_fmax: 8000.0
---
model:
feat_match: 10.0
lambda_adv: 1
use_subband_stft_loss: False
feat_loss: False
out_channels: 1
generator_ratio: [4, 4, 2, 2, 2, 2] # for 256 hop size and 22050 sample rate
mult: 256
n_residual_layers: 4
num_D : 3
ndf : 16
n_layers: 3
downsampling_factor: 4
disc_out: 512
stft_loss_params:
fft_sizes: [1024, 2048, 512] # List of FFT size for STFT-based loss.
hop_sizes: [120, 240, 50] # List of hop size for STFT-based loss
win_lengths: [600, 1200, 240] # List of window length for STFT-based loss.
window: "hann_window" # Window function for STFT-based loss
subband_stft_loss_params:
fft_sizes: [384, 683, 171] # List of FFT size for STFT-based loss.
hop_sizes: [30, 60, 10] # List of hop size for STFT-based loss
win_lengths: [150, 300, 60] # List of window length for STFT-based loss.
window: "hann_window" # Window function for STFT-based loss
---
log:
summary_interval: 1
validation_interval: 5
save_interval: 20
chkpt_dir: 'chkpt'
log_dir: 'logs'
然后运行
python preprocess.py -c config/default.yaml -d /workspace/tts/Fastspeech2-Korean/data/kss/wavs_bak如果出错,请参考【PS1】
3.训练数据集
3.1.训练LJSpeech
复制VocGAN/config/default.yaml,改名为ljs.yaml
修改ljs.yaml中数据(data)中,train的路径和validation的路径(这俩是必须的,eval为空也可以)
所以要把数据集进行划分训练集和验证集,进入data文件夹下新建splitdata.py
import os
import random
def main():
random.seed(0) # 设置随机种子,保证随机结果可复现
files_path = "/workspace/tts/VocGAN/data/LJSpeech-1.1/wavs"
assert os.path.exists(files_path), "path: '{}' does not exist.".format(files_path)
val_rate = 0.3 #验证集比例设置为0.3
#获取数据集的名字(不包含后缀),排序后存放到files_name列表中
files_name = sorted([file.split(".")[0] for file in os.listdir(files_path)])
files_num = len(files_name)
val_index = random.sample(range(0, files_num), k=int(files_num*val_rate))
train_files = []
val_files = []
for index, file_name in enumerate(files_name):
if index in val_index:
val_files.append(file_name)
else:
train_files.append(file_name)
try:
train_f = open("train.txt", "x")
eval_f = open("val.txt", "x")
train_f.write("\n".join(train_files))
eval_f.write("\n".join(val_files))
except FileExistsError as e:
print(e)
exit(1)
if __name__ == '__main__':
main()
然后进行划分
cd data
python splitdata.py结果如图

最后进行训练
python trainer.py -c config/ljs.yaml -n ljs_ckpt参数:
- -c也就是--config 是要求的配置文件
- - n也就是--name 是要求的训练数据后保存权重文件的文件夹名
训练完后,可查看
tensorboard --logdir logs/4.训练自定义数据集
自己收集的语音数据集,包含语音和语音文本
对语音数据的收集包含了:手机电脑自带录音,利用软件录音
手机录音的采样率是指录制声音时每秒钟采集的样本数。采样率越高,录制声音的准确性越高,但同时也会增加文件的大小。大多数手机录音应用默认的采样率为44.1 kHz,与CD音质相同。然而,一些应用程序允许用户自定义采样率,让用户在文件大小和音质之间做出选择。
对数据进行重命名
import os
path_in = "/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs" # 待批量重命名的文件夹
class_name = ".wav" # 重命名后的文件名后缀
file_in = os.listdir(path_in) # 返回文件夹包含的所有文件名
num_file_in = len(file_in) # 获取文件数目
for i in range(0, num_file_in):
t = str(i + 1)
new_name = os.rename(path_in + "/" + file_in[i], path_in + "/" +t+ class_name) # 重命名文件名
file_out = os.listdir(path_in)
print(file_out) # 输出修改后的结果`
因为vocgan要求采样率是22050,
如果是手机录音的话,采样率可能不同,所以要批量将采样率统一为22050。
resamplingrate.py
import os
import librosa
import tqdm
import soundfile as sf
if __name__ == '__main__':
# 要查找的音频类型
audioExt = 'wav'
# 待处理音频的采样率
input_sample = 22050
# 重采样的音频采样率
output_sample = 16000
# 待处理音频的多个文件夹
#audioDirectory = ['/data/orgin/train', '/data/orgin/test']
audioDirectory = ['/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs']
# 重采样输出的多个文件夹
#outputDirectory = ['/data/traindataset', '/data/testdataset']
outputDirectory = ['/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wav']
# for 循环用于遍历所有待处理音频的文件夹
for i, dire in enumerate(audioDirectory):
# 寻找"directory"文件夹中,格式为“ext”的音频文件,返回值为绝对路径的列表类型
clean_speech_paths = librosa.util.find_files(
directory=dire,
ext=audioExt,
recurse=True, # 如果选择True,则对输入文件夹的子文件夹也进行搜索,否则只搜索输入文件夹
)
# for 循环用于遍历搜索到的所有音频文件
for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):
# 获取音频文件的文件名,用作输出文件名使用
fileName = os.path.basename(file)
# 使用librosa读取待处理音频
y, sr = librosa.load(file, sr=input_sample)
# 对待处理音频进行重采样
y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
# 构建输出文件路径
outputFileName = os.path.join(outputDirectory[i], fileName)
# 将重采样音频写回硬盘,注意输出文件路径
sf.write(outputFileName, y_16k, output_sample)
python /workspace/tts/VocGAN/data/resampling.py

先对语音进行预处理,将wav文件转化为mel文件
python preprocess.py -c config/maydata.yaml -d /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs
划分train和val后
然后训练
python trainer.py -c config/mydata.yaml -n dyon如果出错没请参考【PS3】
运行后结果如图


注意:这里不小心中断后,会从头训练
推理
# python inference.py -p checkpoint路径 -i 输入mel的路径
python inference.py -p /workspace/tts/VocGAN/chkpt/dyon/dyon_2dfbde2_33680.pt -i /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/mels过程中遇到的错误及解决
【PS1】AttributeError: module 'torch._C' has no attribute 'DoubleStorageBase'

错误原因可能是torch版本和cuda版本不兼容
查询cuda版本:nvcc -v,可以看到cuda11.8

更换版本
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge更换后还是出错
尝试
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia升级后

导入torch没问题
但是运行时出现
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant' (/opt/miniconda3/envs/gan/lib/python3.8/site-packages/charset_normalizer/constant.py)导入错误:无法从“charset_normalizer.constant”导入名称“COMMON_SAFE_ASCII_CHARACTERS”
这个报错可能是由于charset_normalizer模块的版本问题引起的。尝试更新charset_normalizer模块到最新版本,或者使用较旧的版本,看看是否可以解决问题。可以尝试以下命令更新模块:
pip install --upgrade charset-normalizer
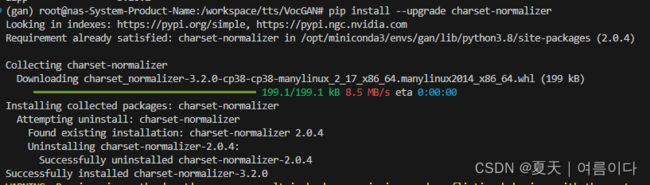
AttributeError: module 'numpy' has no attribute 'complex'.
点开对应代码
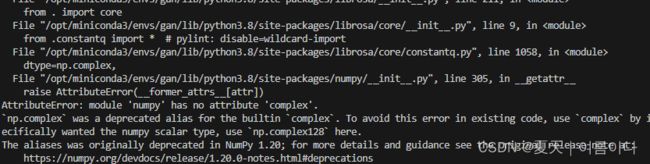
"/opt/miniconda3/envs/gan/lib/python3.8/site-packages/librosa/core/constantq.py", line 1058,
np.complex是内置complex的一个已弃用的别名。
除了np.complex,还可以使用:
complex(1) #output (1+0j)
#or
np.complex128(1) #output (1+0j)
#or
np.complex_(1) #output (1+0j)
#or
np.cdouble(1) #output (1+0j)改完后如图
然后就可以啦~
【PS2】AssertionError: sample rate mismatch. expected 22050, got 48000 at /workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs/72.wav
因为 .wav 文件是立体声,但您需要转换为单声道。使用以下指南将一批文件批量转换为单声道格式。
【PS3】ValueError: num_samples should be a positive integer value, but got num_samples=0
解决方法:
1. 检查dataset中的路径,路径不对,读取不到数据。
2. 检查Dataset的__len__()函数为何输出为零
扩展
train: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs'
validation: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/vaild'
mel_path: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/mels'
eval_path: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/korean_corpus.csv'python preprocess.py -c config/mydata.yaml -d /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs