【Linux操作系统】带你深入理解文件系统
欢迎来到小林的博客!!
️博客主页:✈️林 子
️博客专栏:✈️ Linux
️社区 :✈️ 进步学堂
️欢迎关注:点赞收藏✍️留言
目录
- 了解磁盘
-
- 磁盘是什么
- 磁盘的结构
- 磁盘的存储结构
- 磁盘的抽象
- 文件系统
-
- 分区
- Block group 块组
-
- Super Block
- Group Descriptor Table
- Block BitMap
- inode Bitmap
- inode Table
- Data Blocks
- 如何通过inode编号找到对应的数据?
- inode 和 文件名
- 死亡四连问
- 软硬链接的原理
-
- 目录的硬链接数
了解磁盘
首先,我们要了解文件系统的话。需要了解一下磁盘以及磁盘的存储结构以及磁盘是如何存储的。
磁盘是什么
我们都知道,打开后的文件是在内存中的。那么没有打开的文件呢?毫无疑问,是在磁盘中存储的、磁盘是一个外设,也是计算机中唯一的机械设备。所以磁盘相对于内存而言速度是非常非常慢的。而内存只要断电就会丢失存储介质。磁盘则不一样,磁盘是永久性存储介质。还有其他如 SSD,U盘,flash卡,光盘,磁带… 都和磁盘一样是永久性存储介质。

磁盘的结构
磁盘的结构分为 磁盘盘片,磁头,伺服系统,音圈马达…
因为计算机只认识二进制,所以盘面上存储的数据实际上就是存储二进制。而磁盘如何分辨这些二进制呢?我们都知道一个东西—磁铁 。它有南北极。正好对应二进制中的0和1,向磁盘写入本质就是用磁头去改变磁盘上的正负形。
磁盘的存储结构
首先磁盘会有多个盘面,每个盘面都有多个磁道,每个磁道又有多个扇区。每个扇区的大小是 512字节(先进的会有4kb大小)。而只要磁头找到对应的扇区,就可以对扇区的内容进行读写。
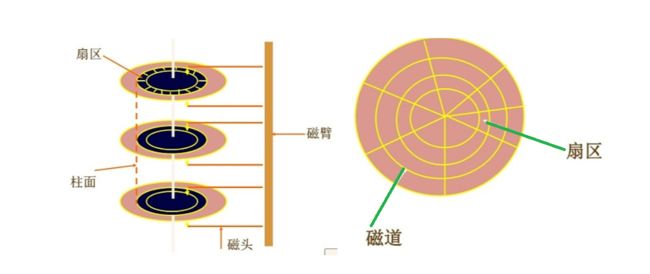
而磁头和盘面的距离相当于一架飞机在贴地飞行。磁头不会触碰到盘面,否则会刮花盘面造成数据丢失。
在物理结构上,如何把数据写入到指定的扇区区域?
流程大概是这样的: C找到对应的磁道 -> H找到对应的盘面(每个盘面都有一个磁头) -> S找到指定的扇区 -> 对数据进行读写。 而这种查找方法我们称之为CHS,有了CHS,就可以轻松的找到任意一个扇区。
磁盘的抽象
因为磁盘在硬件上是一个圆形结构。那么在计算机的角度,它会被抽象成一个线性结构。想必大家都知道磁带这个东西。我们在用它的时候,它是个环形结构。当我们把磁带拉出来,就会发现它其实是个线性结构。

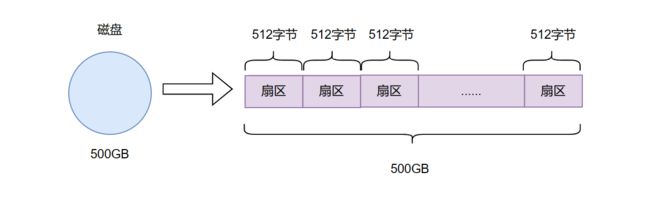
抽象成线性结构后我们惊人的发现。这个磁盘不就是一个大数组吗?每一个元素对应一个扇区,每一个扇区是512字节。而我们只需要通过数组的下标即可定位到指定的扇区。
文件系统
我们把磁盘抽象成一个大数组之后,那么就想要对这个大数组进行管理。如何管理呢?那么就需要用文件系统来对磁盘的文件进行管理。
分区
我们会发现我们的电脑上有C,D,E,F…等多个盘。每个盘的大小是多少多少GB。这种行为我们叫做分区。

分区之后,我们就把对磁盘的管理,变成对每个分区的管理。而每个分区又有若干个Block Group块组。

Block group 块组
每个分区里面都会有一个Boot Block 和 若干个Block group块组。Boot Block 是一个启动块,大小为1kb,由pc标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能操作该块。
块组有下面这些内容 :
Super Block
存储文件系统的属性信息 ,块组中都会有一份。
为什么Super Block 在每个文件系统中都有一份?
我们知道Super Block 是存储文件系统的属性信息。那为什么每个块组里面都要维护一份?
这是为了避免Super Block发生了数据缺失,那么就可以从其他的块组里面拷贝一份过来修复。相信我们大家都会遇到电脑突然蓝屏提示正在修复中… 实际上就会从其他的块组中拷贝一份新Super Block的过来。这也就是为什么要在每一个块组里面都放一个Super Block的原因。
Group Descriptor Table
对于整个块组的信息存储,例如 : 块组的描述符,这个块组有多大,已经使用了多少空间。有多少个inode,占用了多少个inode。有多少block,使用了多少block。
Block BitMap
一个位图,用来标记Blocks中哪些位置被占用。如果被占用则对应的比特位会被置为1,每一个比特位对应的是一个4kb的block块。
inode Bitmap
一个位图,记录当前文件系统中哪些inode被占用。如果被占用则会置为1,每一个比特位对应一个inode编号。可以快速查找inode是否被占用。
inode Table
inode表,存储的是一个个大小为128字节的inode。每个inode都保存着对应的文件的的信息以及inode编号。一般而言,一个inode对应一个文件。
Data Blocks
多个 4kb(扇区*8)大小的集合,存储的是对应的文件的内容。 虽然磁盘的基本单位是扇区(512字节)。但是操作系统(文件系统)和磁盘进行IO的基本单位是4kb。为什么不以512字节为单位呢? 一是因为 512字节太小了,每次IO的字节太小,就会造成IO变得更频繁,而IO又是非常慢的。二是如果操作系统和磁盘一样的大小,万一磁盘基本大小变了的话,那么OS的代码是不是也要改呢?那肯定是不能的。所以用4kb可以更好的让硬件和软件进行解耦。
我们将块组分割成上面的内容,并写入相关的管理数据。每一个块组都这么干,那么整个分区就都写入了文件系统。每个分区都写入了文件系统,那么整个磁盘就写入了文件系统。
如何通过inode编号找到对应的数据?
我们可以通过inode去对应的inode BitMap找当前inode是否存在,存在的话就可以在inode Table中找到对应的inode。 而inode除了存储文件的属性信息以及inode编号之外,一定还会有一个 int blocks[15]。
struct inode
{
//文件的大小
//文件的inode编号
.... //其他属性
int blocks[15];
};
而这个int blocks[]数组对应的是Data blocks的下标。因为Data blocks存储的是多个4kb大小的集合。所以inode可以通过int blocks[]数组,来存储自己文件的内容所在的Data blocks里的下标。

那么这时候就有疑问了,如果按照这种说法,那么一个文件的最大大小只能是 16 * 4kb了。那如果文件很大怎么办?所以,blocks[]数组存储的块的下标不一定是拿来存文件内容的,也有可能拿来存储其他内容块的下标。打个比方,blocks[0] = 6。而Data Blocks[6] 块中存储的是其他内容的下标。那么就有 4kb的大小拿来存储下标。一个整形是4字节,4kb可以存储1024个整形。那么blocks[0]存储的内容的最大大小就变成了 1024 * 4 = 4MB。以此类推,如果用这4MB继续存储其他块的下标,就会变成拿4MB的空间来存储内容的下标,那么就是 1MB * 4kb 就会变成4GB… 还可以继续往下推。所以不用担心文件太大的情况。
inode 和 文件名
虽然我们都说一个inode对应一个文件。可是在实际使用的时候,我们都是操作文件名来使用。所以inode和文件名是什么区别呢?
我们都知道如果要找到一个文件,那么必须先找到对应的inode编号,然后找到对应的块组,再找到对应的inode,在inode中找到对应的属性和内容。那么我们是如何知道inode编号的呢?
这2个问题可以一起回答。因为在linux下,一切皆文件。我们的目录结构也不例外。我们的目录也是一个文件,那么目录就有自己对应的inode。那么目录的内容就是当前目录下,所有文件与inode编号的映射关系。inode与文件名互为key值。这也就是为什么一个目录下不能出现相同的文件名,因为一个文件名不能映射多个inode。
所以
第一个问题回答: inode编号 和 文件名在当前目录的内容中互为key值,是映射关系。
第二个问题回答: inode编号 和文件名互为映射关系,那么就可以通过文件名知道该文件对应的inode编号。
我们用ll -i 命令查看当前目录下的文件时,第一个显示的就是inode编号。

死亡四连问
创建文件时,系统做了什么?
创建文件时,首写要保证当前目录具有写权限。如果当前目录没有写权限,那么就在目录的内容中建立inode编号与文件名的映射关系。随后把inode BitMap对应的inode编号由0置为1,再在inode Table找到对应的inode进行文件属性信息,以及内容…等东西的写入。
删除文件时,系统做了什么?
很简单,通过当前目录的文件名找到inode编号,再在inode BitMap位图中将该位置由1置0就完成了删除。所以文件被删除是有可能恢复的,因为只需要在把位图由1置0即可。但如果你创建了其他的文件,让其他文件的Inode编号覆盖了这个删除文件的Inode,那么这时神仙难救。
查看文件时,系统做了什么?
查看文件时,通过文件名找到inode编号->找到对应的inode->找到inode对应的内容。当然前提是要确保当前文件具有可读权限。
如果一个磁盘明明还有空间,却创建文件失败了,这是为什么?
因为inode和Date blocks的大小是固定的。所以就会有两种情况。
情况一 : inode没满,Date Blocks满了
这种情况就是典型的磁盘空间不够了,所以创建文件失败。
情况二:inode满了,Date Blocsk没满
这种情况一样会创建失败,即使你的磁盘还有空间(因为Data Blocks没满)。 因为你inode Table满了,无法创建新的inode,所以就导致文件创建失败。简单来说,就是一个Block group内,文件的数量是有限制的。不能无限创建(排除硬链接的情况)。
软硬链接的原理
首先,我们有两个文件。

然后我们为了file1.txt创建一个软链接,为file2.txt创建一个硬链接。

我们会发现,软链接后的文件和原文件的indoe是不一样的。所以我们可以肯定,软链接的过程肯定创建了一个新的inode。而这个inode的内容就是链接的原文件的路径。 所以我们windows系统下的快捷方式,就是一个软链接,删除软链接并不会影响软链接指向的路径文件。
而硬链接后生成的inode是一样的。所以我们可以肯定,没有创建新的inode,那么就是在当前目录的内容种新建了一对文件名与inode编号的映射关系。而我们可以发现,原本为1的那一列,现在都变成了2。而这一列就是硬链接的数量,也就是说当前inode和多少个文件名进行了映射。
那么我们删除硬链接的文件。

我们会发现链接数从2变成了1。没错,这就是传说中的引用计数。当我们删除一个文件的时,并不是直接去修改inode BitMap位图。而是先对当前inode的引用计数进行自减。如果自减后为0。那么就删除,如果不为0,那么就仅仅删除这一对映射关系即可。新创建的文件硬链接数默认为1(目录除外)。
目录的硬链接数
我们在一个当前目录创建一个空目录。

我们会发现一个目录的初始硬链接数是2,这是为什么呢?
很简单,在当前目录下。我们创建了一个dir目录,那么就要在当前目录的内容中写入dir与其inode的映射。 这是一个硬链接。随后我们cd dir 进去查看dir目录。

我们会发现,这个目录自己也会为自己建立一份硬链接文件 “.” 。 这就是为什么我们用 ./ 就会默认变成当前目录。因为 . 也是一个文件,与当前目录进行了硬链接。所以我们在pwd . 的时候,实际上是pwd 当前的路径。

**那么我们在dir目录下再创建一个目录呢? **

我们会发现当前dir目录的硬连接变成了3。想必大家已经知道这是为什么了吧。因为目录不仅会给自己建立一个硬链接,还会给个自己的上层目录也建立一个硬链接文件,这个文件就是 “…” 。
第一个硬链接 ./dir
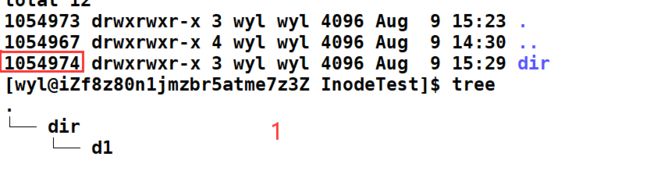
第二个硬链接 ./dir/.
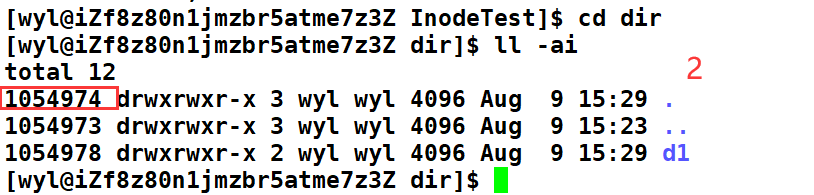
第三个硬链接 ./dir/d1/…
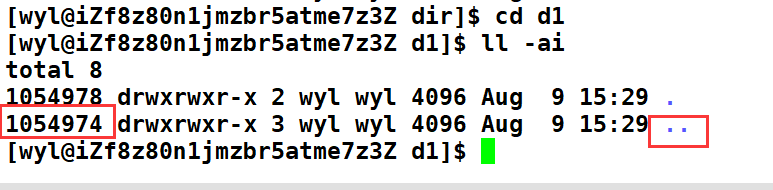
所以,我们在一个目录下创建的每一个目录。这些目录都会为它的上层目录建立一层链接。

所以我们只需要用硬链接数 - 2。就可以一眼看出当前目录下有几个目录了。上图种的硬链接数为7,7 - 2 那么dir目录下就有5个目录。