(详解)数据结构——带头双向循环链表——顺序表与链表的区别——即附带CPU高速缓存的知识
文章目录
-
- 链表的介绍
- 1.带头双向循环链表的初始化
-
- 初始化函数接口
- 2.销毁链表
- 3.打印链表
- 4.查找元素
- 5.删除指定节点
- 6.在指定结点前新增一个节点
- 7.头插
- 8.头删
- 9.尾插
- 10.尾删
- 链表判空
- 总结:
-
- 顺序表与链表的优缺点
-
- 顺序表:
- 链表(双向带头循环链表):
链表的介绍
链表的结构一共有八种:带头单向循环链表、带头单向非循环链表、带头双向循环链表、带头双向非循环链表、无头单向循环链表、无头单向非循环链表、无头双向循环链表、无头双向非循环链表。
在这八种结构中,我们只挑两种来进行刨析,即无头单向非循环链表和带头双向循环链表。


无头单向非循环链表:结构简单,一般不会用来存储数据。实际上更多是作为其他数据结构的子结构,如哈希桶、图的链接表等等。此外,这种结构在笔试面试中出现很多。
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构都是带头双向循环链表。另外,这个结构虽然复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
1.带头双向循环链表的初始化
// 带头+双向+循环链表增删查改实现
typedef int LTDataType;// 存储数据的数据类型
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;// 指向下一个节点next
struct ListNode* pre;// 指向后一个节点pre
}ListNode;
首先我们定义一个能初始化链表的函数,因为头节点不存储有效数据,所以我们不需要对头节点的数据进行初始化,我们只要把链表弄成一个循环就可以,如何循环?head->next指向head,head->pre 指向head
如图:

初始化函数接口
ListNode* ListInit()
{
ListNode* phead = (ListNode*)malloc(sizeof(ListNode));//创建一个头节点
phead->next = phead;// 造成循环
phead->pre = phead;// 结构
return phead; // 返回头节点地址
}
因为下面我们要插入数据,每次插入数据都要新增一个节点
所以我们创建一个新增节点函数
//新增节点
ListNode* BuyListNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->data = x;
return newnode;
}
2.销毁链表
销毁链表,从头结点的后一个结点处开始向后遍历并释放结点,直到遍历到头结点时,停止遍历并将头结点也释放掉。
//销毁链表
void ListDestroy(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;//从头结点后一个结点开始释放空间
ListNode* next = cur->next;//记录cur的后一个结点位置
while (cur != pHead)
{
free(cur);
cur = next;
next = next->next;
}
free(pHead);//释放头结点
}
3.打印链表
打印链表也是很简单,指针cur从头才是遍历,每到一个节点就打印有效数据,直到遇到pHead指针结束
// 打印链表
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur!=pHead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
4.查找元素
找到对应数据的节点位置,思路:从头遍历直到遇到对应数据,让后返回指针,如果没有那个数据就返回NULL
//寻找节点位置,如果没有那个数据则返回NULL
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
查找数据位置和打印链表思路几乎一样的!
5.删除指定节点
删除节点就是,把节点删了,把前一个结点与后一个节点进行对接,让前后节点有双向关系
如图

void ListErase(ListNode* pos)
{
assert(pos);
assert( !ListEmpty(pos));
ListNode* posnext = pos->next;// 记录后一个
ListNode* pospre = pos->pre;// 记录前一个
pospre->next = posnext;// 让前后两节点形成双向关系
posnext->pre = pospre;
free(pos); // 删除指定位置
}
6.在指定结点前新增一个节点
思路:
先记录前一个节点,
创建新结点
前一个节点与新结点,形成双向关系
指定结点与新结点,形成双向关系
如图
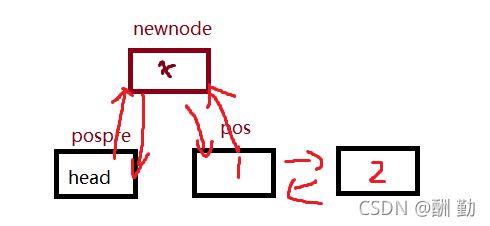
// 双向链表在pos的前面进行插入
//当pos等pHead时相当于尾插
void ListInsert(ListNode* pos, LTDataType x)
{
ListNode* newnode = BuyListNode(x);//创建新增节点
ListNode* posPre = pos->pre;// 记录前一个节点
posPre->next = newnode;// 前一个节点与新增节点形成双向关系
newnode->pre = posPre;
newnode->next = pos;//指定位置节点与新增节点形成双向关系
pos->pre = newnode;
}
7.头插
通过上述的学习,现在要进行头插 ,我们可以利用ListInsert接口来实现
ListInsert是在目标位置前插入
也就是如果要头插我们只需把第一个节点传给ListInsert即可
如图

//头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
// 方法一、
//ListNode* newnode = BuyListNode(x);
//ListNode* next = pHead->next;
//pHead->next = newnode;
//newnode->pre = pHead;
//newnode->next = next;
//next->pre = newnode;
//方法二:调用ListInsert
ListInsert(pHead->next, x);
}
8.头删
也是和上诉一样的思路
//头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
//if (pHead->next == pHead)
//{
// return;
//}
//ListNode* cur = pHead->next;
//ListNode* next = cur->next;
//pHead->next = next;
//next->pre = pHead;
//free(cur);
ListErase(pHead->next);
}
9.尾插
我们知道 head->pre就是尾结点
所以说head的前一个节点就尾结点
//尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
//ListNode* newnode = BuyListNode(x);
//ListNode* tail = pHead->pre;
//
//tail->next = newnode;
//newnode->pre = tail;
//newnode->next = pHead;
//pHead->pre = newnode;
//
ListInsert(pHead, x);//
}
10.尾删
和尾插一样思路
// 尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
//if (pHead->next == pHead)
//{
// return;
//}
//ListNode* tail = pHead->pre;
//ListNode* tailPre = tail->pre;
//free(tail);
//tailPre->next = pHead;
//pHead->pre = tailPre;
ListErase(pHead->pre);
}
链表判空
链表判空,即判断头结点的前驱或是后驱指向的是否是自己即可。
//链表判空
bool ListEmpty(ListNode* phead)
{
assert(phead);
return phead->next == phead;//当链表中只有头结点时为空
}
总结:
在写带头双向循环链表时,我们只需写ListInsert ,ListErase,就能轻松写出尾删尾插,头删头插的接口。
顺序表与链表的优缺点
这个两个结构各有优势,很难区分谁更优秀!
严格来说他们俩,是相辅相成的两个结构。
顺序表:
优点:
1.它支持随机访问。需要随机访问结构支持算法可以很好的使用。
2.CPU高速缓存利用率更高。(缓存级的知识)
缺点:
1.头部中部插入删除时间复杂度效率低。O(N)
2.连续的物理空间,空间不够了以后会增容,
增容有两个缺陷:
a、增容有一定程度的消耗(如果开辟时,空间后面不够realloc来开辟,要重新把顺序表里的数据挪动到新顺序表里,然后销毁旧顺序表)
b、为了避免频繁增容,一般我们都按倍数去增,用不完可能存在一定的空间浪费。
链表(双向带头循环链表):
优点:
1、任意位置插入删除效率高。O(1);
2、按需申请释放空间。一点都不浪费。
缺点:(一个缺点在很多地方就用不到了,因为在生活中有很多需要排序的地方)
1、不支持随机访问。(用下标访问)意味着一些排序不能使用,二分查找等在这种结构上不适用。
2、链表存储一个值,同时要存储链接指针,也有一定的消耗。(不碍事)
3、CPU高速缓存命中率更低
小结:
链表能做的事,顺序表都可以完成,只是操作方法不同,效率不同
如果想了解高速缓存命中率这块知识点击下面链接
与程序员相关的CPU缓存知识
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连 续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除元 素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩 容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |