微服务井喷时代,我们如何规模化运维?
随着云原生技术发展及相关技术被越来越多运用到公司生产实践当中,有两种不可逆转的趋势:
1、微服务数量越来越多。原来巨型单体服务不断被拆解成一个个微服务,在方便功能复用及高效迭代的同时,也给运维带来了不少挑战:
成本问题:服务及基础资源依赖的生命周期该如何运转?如何防止孤儿资源存在,防止资源浪费?如何提升资源利用率?
效率问题:单元化服务如何快速高效部署?服务梳理及批量搭建
责任归属:面对数量级倍增的服务及资源,如何找到责任人及归属团队?(有问题如何找到合适的人处理及跟进?成本如何归属到合适的团队?)
备注:这里主要关注服务及服务依赖的基础设施管理及运维,不关注上下游依赖管理,上下游依赖可以通过服务治理(依赖拓扑)等解决。
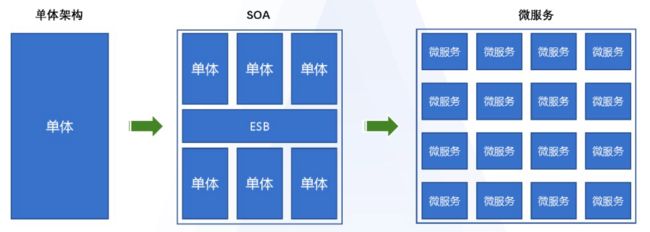

2、服务越来越复杂,依赖的基础设施更多样化(如自建机房、云机房、混合机房等),依赖的中间件越来越多(如企业内部自建系统、各大云厂商服务等),用户是否需要感知这些基础设施的差异?
如果感知,用户的使用成本会增加,规范标准如何去约束?
如果不感知,则这些底层差异如何屏蔽?
解决思路
要解决如上两个问题, 首先要找到如上问题的根因是啥?
问题1:信息割裂、冗余及缺乏信息更新
举例1:
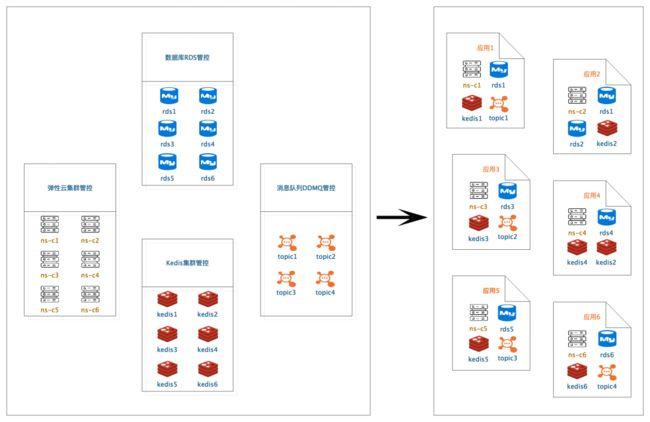
当前滴滴内部对于一个服务主要关注它的计算资源(弹性云资源)及对应服务树节点的观测、报警等运维相关属性,如上属性都是通过服务树节点ns关联起来,对于存储类资源并没有相应的关联关系元信息(只存在代码配置中)。一个服务能整体运转起来的完整依赖没有一个清晰的视角,如果想要了解完整依赖,需要SRE去梳理相关运维属性,服务负责人去查看代码梳理出来底层中间件依赖。
解法:将计算资源、存储资源及一些偏运维配置按照服务维度做整体抽象及关联,这样使得服务有整体的视角,同时相对单个服务,整体才能更好的管理生命周期,避免出现孤儿资源,防止资源浪费。见图应用示例,可以看清一个应用所依赖的所有IaaS资源及PaaS资源。
同时通过观测服务整体的资源使用情况,可及时发现资源利用率低下或资源不足的问题,并采取响应的措施进行优化。
应用组合抽象
应用示例
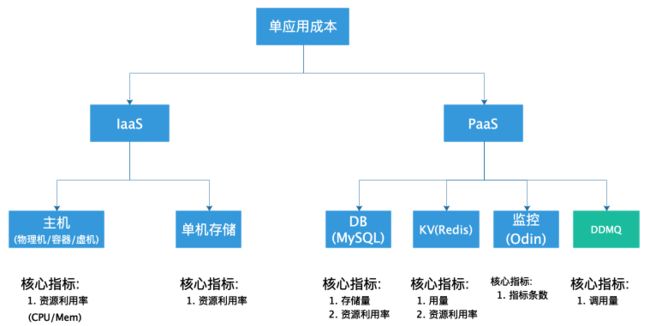 应用资源治理视图
应用资源治理视图
举例2:
对于建站及单元化交付场景,首先人工梳理服务资源(计算资源、存储资源、运维配置等等一系列数据),然后进行逐一批量交付,最后进行逐一资源组装的过程占据了很大的一部分时间,且由于涉及的人员往往特别多(交付时效性无法保证,协调人力特别困难),耗时费力。如果这个过程出现遗漏等问题,第一会带来返工,重新交付及组装,第二是验收阶段会带来一系列不可预测的问题(排查及修复时间不可控)。
解法:基于如上服务整体的抽象及关联,可以降低人工梳理的工作量,然后做统一交付,甚至可以自动化生成新环境配置,自动化交付环境。大大减少人工梳理、降低遗漏问题及人工介入等问题。
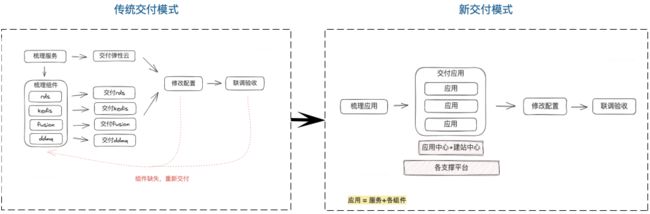
新老交付模式对比
举例3:
各个依赖资源(弹性云、RDS等)都有自己的一套管控及元信息,彼此割裂无同步,比如弹性云、RDS都有自己的负责人、成本归属团队。数据的大量冗余,导致数据更新困难:信息发生变更,需要同时更新所有资源平台的相关信息,且各个资源无关联关系(做到关联更新极其困难)。
数据变更缺少更新机制,比如服务负责同学离职了,对应资源平台的负责人并未因此而发生改变及流转。久而久之,这些服务元信息就成了脏数据,等需要使用的时候,只能人工通过之前的人员组织信息等各种资料去猜想人员及组织归属。
解法:基于以上问题,首先需要将各个系统的冗余数据精简至统一的一份,合并到服务级别,降低冗余度。其次建立数据流转机制,定时监测异常数据并触发一系列流转流程,确保数据能及时更新。
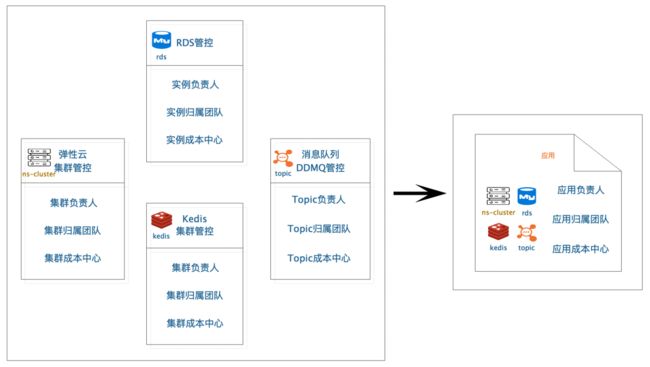
资源负责人抽象管理
问题2:缺乏更高纬度抽象
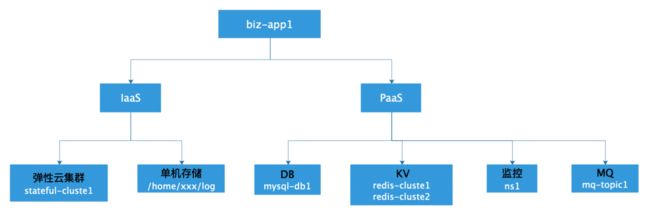
Kubernetes 带来的云原生技术革命,在于实现了基础设施层的标准化和抽象,但这一层抽象距离业务研发与运维还是太过遥远。一个最典型的例子,直到今天,Kubernetes里面始终都没有 “应用” 这个概念,它提供的是更细粒度的 “工作负载” 原语,比如 Deployment或者DaemonSet。而在实际环境中,一个应用往往是由一系列独立组件的组合,比如一个 “ Java应用容器” 和一个 “数据库实例” 组成的订单服务,一个 “Deployment + StatefulSet + HPA + Service + Ingress” 组成的微服务应用。
业务研发和运维SRE一夜之间都被迫变成了 “容器专家”,一边学习着根本不应该是他们关心的各种 “基础设施即代码(Infrastructure as Code)” 领域的概念(比如:声明式 API,控制器等),一边吐槽 Kubernetes 实在是太复杂了、设计太奇葩了。因此我们需要提供一种大家都可以遵循的、标准化的方式来定义更高层级的应用层抽象,并且把“关注点分离”作为这个定义模型的核心思想。
详细来说,OAM 基于 Kubernetes API 资源模型(Kubernetes Resource Model)来标准化应用定义的规范,它强调一个现代应用是多个组件的集合,而非一个简单的工作负载或者 K8s Operator。所以在OAM的语境中,一个Java容器和它所依赖的数据库,以及它所需要使用的各种云服务,都是一个“订单服务”应用的组成部分。更进一步的,OAM把这个应用所需的“运维策略”也认为是一个应用的一部分,比如这个Java容器所需的HPA(水平自动扩展策略)。
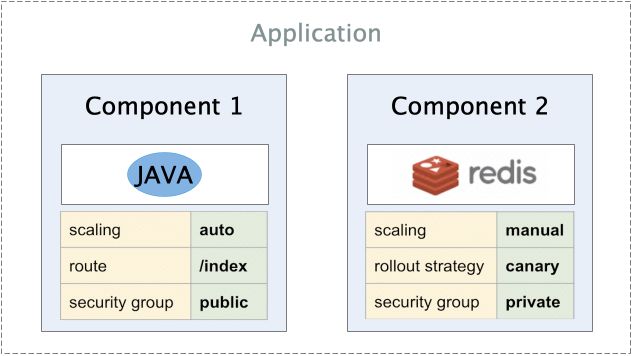 服务OAM模型举例
服务OAM模型举例
这种平台无关的应用定义范式,使得应用研发人员只需要通过 OAM 规范来描述他们的应用程序,该应用程序就可以在任何 Kubernetes 群集或者 Serverless 应用平台甚至边缘环境上运行,而无需对应用描述做任何修改。
有了OAM模型的抽象能力,基础服务提供方(Platform Team)主要基于自建服务、上云服务、第三方云厂商服务封装提供给内部用户的基础服务:比如内部弹性云、RDS、Redis等等,屏蔽各个云厂商及不同平台的差异。而对于业务研发(End User)则专注业务逻辑设计,通过编排弹性云、RDS 等基础设施对外提供服务,从而降低平台相关性的学习成本。
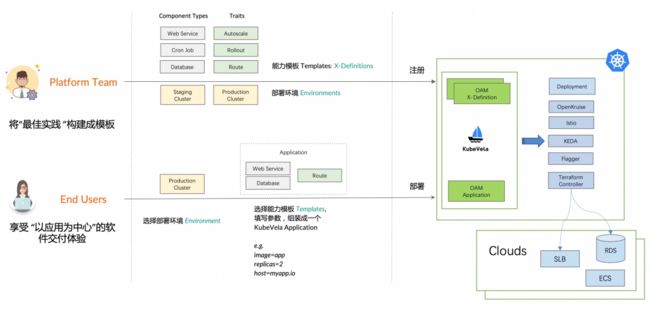
平台研发及业务研发视角
内部实践
业务抽象
基于对以上问题的分析,我们调研了业界相关的实践。KubeVela是一个开源的云原生应用编排引擎,它使用了 Open Application Model(OAM)模型来描述和管理应用程序的部署和运行。
OAM 是一个用于云原生应用程序的开放标准,旨在提供统一的方式来描述和管理应用程序的可移植性、可扩展性和可观察性。OAM 模型提供了一种声明性的方式来描述应用程序的组件、依赖关系和配置。它将应用程序从底层基础设施解耦,使开发人员能够更关注应用程序本身,而不用担心底层的运行时环境。这种抽象能够提高开发人员的生产力,简化应用程序的开发和部署过程。
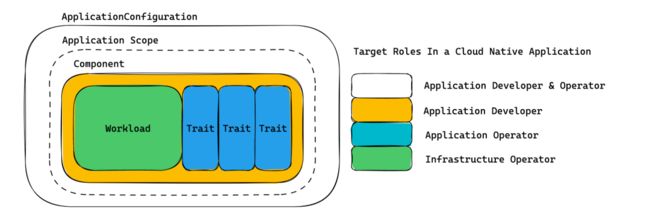 OAM模型
OAM模型
综上所述,KubeVela 和 OAM 模型提供了一种简化应用程序开发和管理的方式,如上图所示就是一个应用大概组成部分,可能有些抽象,那我们以公司内部具体服务来举例说明:
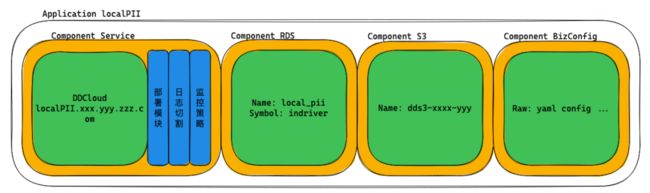 应用OAM举例
应用OAM举例
以服务localPII应用举例,由如下组件构成:
Service 组件:包含 弹性云cluster集群 (Workload)和三个Trait(负责代码更新的部署模块、日志清理的CutLog日志切割以及观测策略);
RDS 组件:包含RDS实例 (Workload),包含实例信息、业务类型、套餐信息和连接信息(VIP+Port、用户名、密码);
S3 组件:和RDS组件一样,S3桶 (Workload) 包含桶名称、桶权限类型和连接信息;
BizConfig 组件:包含一组Yaml配置和RDS组件、S3组件的连接信息,最终由SDK进行消费使用,生成服务环境配置。
在此基础上,我们可以抽象出服务依赖拓扑,进而将服务、资源等元信息维护整合到应用维度,从而降低数据割裂及冗余,增加相关信息变更流程(离职、活水交接服务),解决云信息更新问题。
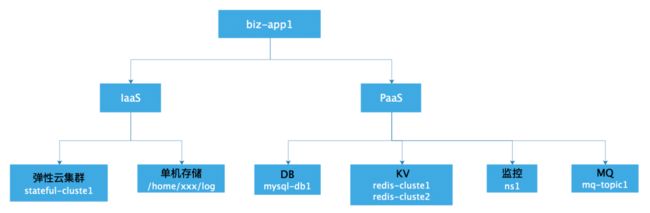 服务资源拓扑
服务资源拓扑
关注点分离
基于KubeVela及OAM模型进行了业务模块抽象,与此同时随着云原生技术在公司内部落地,基础设施及基础服务的复杂性也随之递增,拿基础服务RDS举例:目前公司呈现的形态有自建RDS、基于K8S服务定义提供的服务及各个云厂商的RDS服务,如果不对业务研发做相关底层细节屏蔽,那各业务研发就需要了解各个产品的差异性及了解K8S技术细节,导致学习成本急剧上升,同时很多标准规范无法保障。
因此需要做到业务Dev和平台Dev关注点分离,底层能力迭代无需业务介入,直接供App使用。
平台工程师:专注于基础服务的抽象及定义,同时做好对上层业务屏蔽底层基础设施的差异,降低上层业务研发的学习成本。
业务研发工程师:专注于业务逻辑,根据需要编排底层基础服务,不用关注底层基础设施差异。
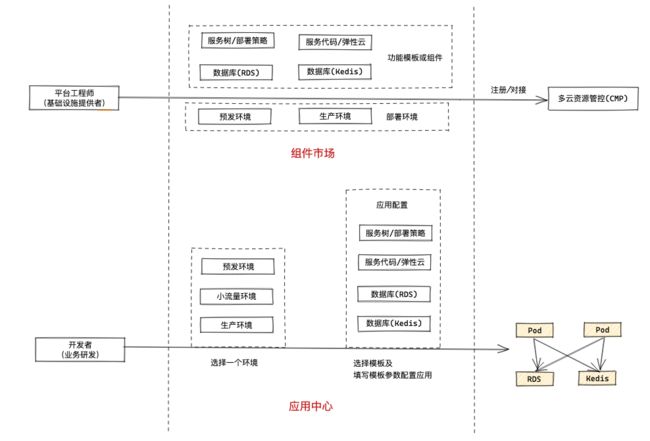 服务关注点分离
服务关注点分离
一个应用的整体交付如下,平台提供方、研发、SRE都着重于各自的职责及关注点,整体上保证服务正常、高效工作。
平台提供方: 由基础设施及运维平台方提供组件定义及组件服务
研发: 通过应用中心做服务架构编排,组织业务所需的组件
SRE: 通过应用中心做服务运维特性及能力编排
RD + SRE: 共同配置环境差异
交付中心: 做服务环境交付, 包括资源及运维特征等
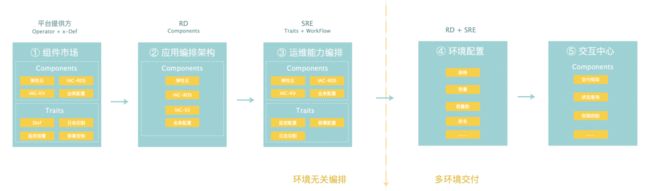 服务交付新模式
服务交付新模式
实际产品落地
基于以上分析及整体设计,我们大体分为四大块功能产品。
组件市场
组件市场主要为公司内部各个基础服务提供产品定义及注册,比如RDS、Kedis、Fusion等组件负责人在组件市场定义自身服务能力,并负责组件功能维护及底层多云适配等,通过可插拔的方式提供能力给到应用中心,由业务研发人员根据自身服务需求在应用中心编排资源、组装功能,从而对外提供服务。
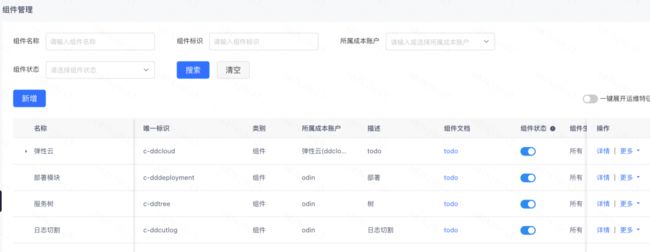 组件市场
组件市场
应用中心
应用中心是一个将资源依赖及运维设施与服务绑定的应用全生命周期管理平台,提供应用的完整描述与快速交付能力,方便资源管理并提升交付效率。
首先集成了以成本中心组织树为基础,确定服务成本归属及相关的流转功能。应用属性包含应用负责人、负责团队及所属成本中心,建立应用责任归属及成本归属更新及流转机制,极力做到服务到人,归属到团队,成本到部门。
 应用中心-首页
应用中心-首页
应用中心-基础信息
其次,提供服务组件编排能力,业务研发人员可以根据自身服务需要,组装所需资源组件以达成服务功能;通过应用中心的环境管理,可以整体交付服务集群及做服务集群复制等。
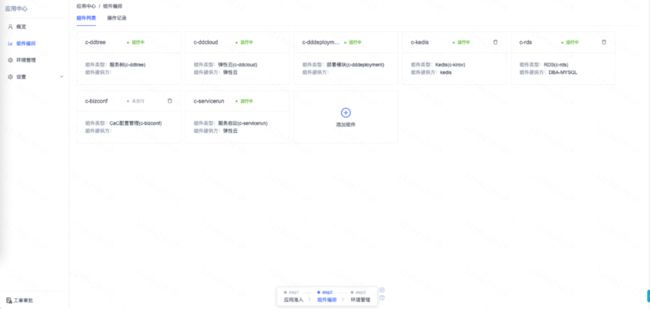 应用中心-组件编排
应用中心-组件编排
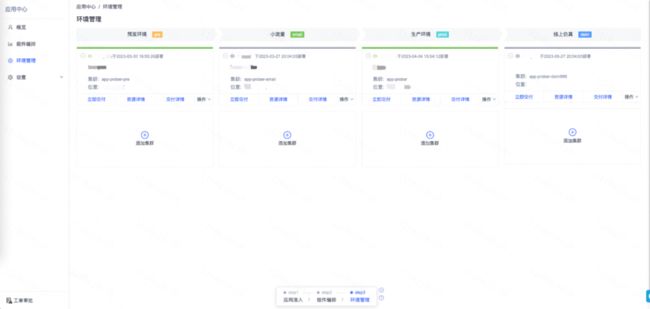 应用中心-环境管理
应用中心-环境管理
云原生运维平台
以应用(服务模块)为中心重新组织运维管控功能(部署/弹性云/观测),结合应用中心将应用(服务模块)与资源关系做了绑定及维护,解决生命周期管理等问题。
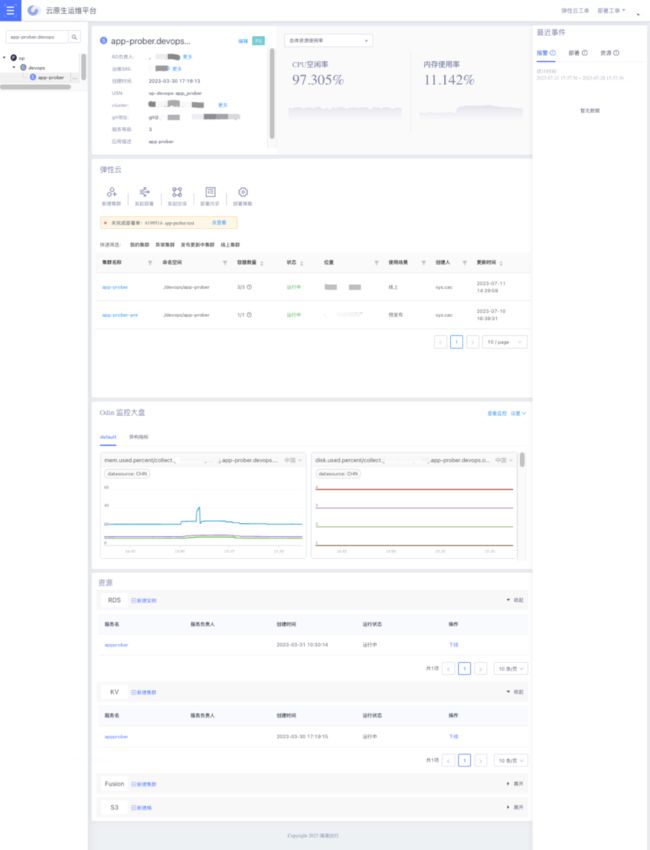 云原生运维平台
云原生运维平台
建站中心
建站中心是在应用中心基础上建设的完整业务站点的交付平台,交付能力依赖应用中心,同时提供交付过程中的链路管理、流程管理等能力,提高完整站点的交付效率。
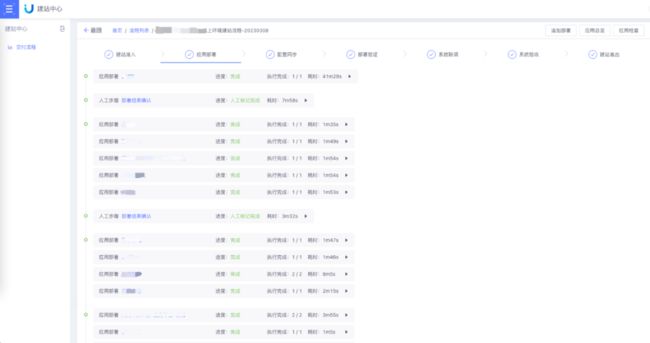
建站中心
业务线落地
国际化业务
考虑到国际化业务自身业务特点,其对机房交付需求更频繁及交付效率要求更高,我们和国际化业务架构合作,通过应用中心解决元信息整合、整体服务抽象,以及国际化业务CaC(配置即代码)技术落地(机房差异化配置自动生成)整体提升整机房服务交付效率。当前在国际化有两块较大的收益:
通过应用中心托管(资源拓扑自动生成 及 服务资源自动化申请)减少人工梳理及交付参与,CaC技术落地减少业务开发参与修改配置及上线等流程,整体机房交付可以节省30%以上的人力投入。
应用中心整体对资源生命周期的管理并提供成本归属流转等能力,解决了之前孤儿资源及找不到接口人问题,提供应用维度成本观测,为后续成本治理提供重要抓手。
国内业务
国内业务推广则借助今年国内多活机房建设及降本增效等项目机会:
利用应用中心及建站中心能力提升多活机房计算资源建设效率及建站交付一致性。
利用应用中心提供的应用负责人、归属团队及归属成本中心维护及流转能力,推进成本算清及责任到团队,助力降本项目推进。
云原生夜话
你们在实际项目中是如何使用KubeVela的?遇到了哪些挑战和最佳实践?欢迎在评论区留言,如需与我们进一步交流探讨,也可直接私信后台。
作者将选取1则最有意义的留言,送出滴滴定制多功能跨包,9月14日晚9点开奖。