词法分析使用正则表达式识别出 Token,语法分析使用 BNF 范式识别出 Token 间的层次组合关系。
词法分析
词法分析主要目的是从源代码中识别出一个个的 Token,一般使用正则表达式来识别 Token
LNUM [0-9]+
DNUM ([0-9]*"."[0-9]+)|([0-9]+"."[0-9]*)
EXPONENT_DNUM (({LNUM}|{DNUM})[eE][+-]?{LNUM})
HNUM "0x"[0-9a-fA-F]+
BNUM "0b"[01]+
LABEL [a-zA-Z_\x80-\xff][a-zA-Z0-9_\x80-\xff]*
WHITESPACE [ \n\r\t]+
TABS_AND_SPACES [ \t]*
TOKENS [;:,.\[\]()|^&+-/*=%!~$<>?@]
ANY_CHAR [^]
NEWLINE ("\r"|"\n"|"\r\n")有了正则表达式,接下来就是依据正则来一个个字符匹配验证,可使用 NFA 和 DFA 来识别一段文本是否满足正则表达式,如对于正则(a|b)*abb 举例:
NFA 不确定有穷自动机
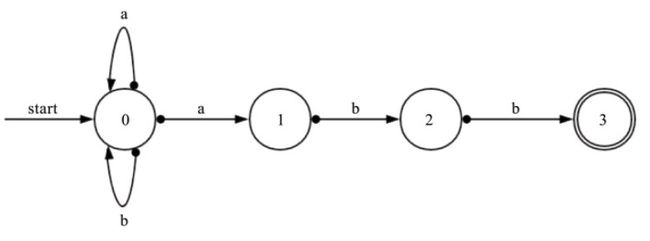
由于在 0 位置,接到 a 有可能向 1 走,也有可能循环,走到哪是不确定的。
DFA 确定有穷自动机
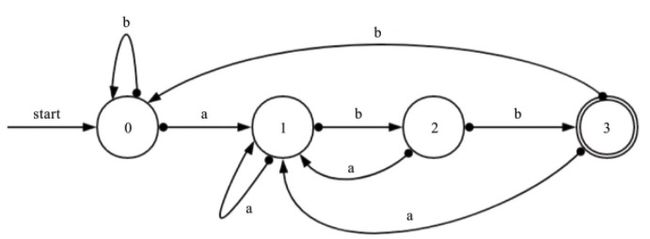
在之前基础上做了改进,演进方向确定了。
将正则转换为有穷自动机比较复杂,但是又有规律可循,可由工具代替,如 re2c。
re2c
re2c 可以解析正则,生成 C 语言实现的 DFA。类似的词法分析器还有 Lex(Lexical Analyzar),与re2c 类似,也是通过正则生成 C 语言 DFA 代码,C 语言解析正则一般使用 regex.h 库。
如下代码中,char *scan 中定义了一系列正则,针对输入的内容做类型判断,保存为 a.l 文件
#include
char *scan(char *p){
#define YYCTYPE char
#define YYCURSOR p
#define YYLIMIT p
#define YYMARKER q
#define YYFILL(n)
/*!re2c
[0-9]+ {return "number";}
[a-z]+ {return "lower";}
[A-Z]+ {return "upper";}
[^] {return "unkown";}
*/
}
int main(int argc, char* argv[])
{
printf("%s\n", scan(argv[1]));
return 0;
} 使用 re2c a.l -o a.c -i 解析正则生成 C 语言的 DFA :
/* Generated by re2c 2.0.3 on Tue Jun 8 16:57:11 2021 */
#include
char *scan(char *p){
#define YYCTYPE char
#define YYCURSOR p
#define YYLIMIT p
#define YYMARKER q
#define YYFILL(n)
{
YYCTYPE yych;
if (YYLIMIT <= YYCURSOR) YYFILL(1);
yych = *YYCURSOR;
switch (yych) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': goto yy4;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
case 'G':
case 'H':
case 'I':
case 'J':
case 'K':
case 'L':
case 'M':
case 'N':
case 'O':
case 'P':
case 'Q':
case 'R':
case 'S':
case 'T':
case 'U':
case 'V':
case 'W':
case 'X':
case 'Y':
case 'Z': goto yy7;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'h':
case 'i':
case 'j':
case 'k':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'q':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
case 'y':
case 'z': goto yy10;
default: goto yy2;
}
yy2:
++YYCURSOR;
{return "unkown";}
yy4:
++YYCURSOR;
if (YYLIMIT <= YYCURSOR) YYFILL(1);
yych = *YYCURSOR;
switch (yych) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': goto yy4;
default: goto yy6;
}
yy6:
{return "number";}
yy7:
++YYCURSOR;
if (YYLIMIT <= YYCURSOR) YYFILL(1);
yych = *YYCURSOR;
switch (yych) {
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
case 'G':
case 'H':
case 'I':
case 'J':
case 'K':
case 'L':
case 'M':
case 'N':
case 'O':
case 'P':
case 'Q':
case 'R':
case 'S':
case 'T':
case 'U':
case 'V':
case 'W':
case 'X':
case 'Y':
case 'Z': goto yy7;
default: goto yy9;
}
yy9:
{return "upper";}
yy10:
++YYCURSOR;
if (YYLIMIT <= YYCURSOR) YYFILL(1);
yych = *YYCURSOR;
switch (yych) {
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'h':
case 'i':
case 'j':
case 'k':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'q':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
case 'y':
case 'z': goto yy10;
default: goto yy12;
}
yy12:
{return "lower";}
}
}
int main(int argc, char* argv[])
{
printf("%s\n", scan(argv[1]));
return 0;
} 可见其处理逻辑是根据输入的字符做 switch case 判断,处理完一个字符,作为当前字符指针的YYCURSOR+1,继续判断下一个字符,配合 goto 语法,流转到下一种状态。
测试的输出:
测试数字
> ./a 1
number
测试小写字母
> ./a x
lower
测试大写字母
> ./a Z
upper语法分析
语法分析目的是对源代码进行层次分析,将源程序分组分层,用语法树来表示,如代码 a = b + c * 2 经过语法分析后得到的结果:

如何更规范的表达语法,可以使用 BNF 范式即巴科斯范式。
巴科斯范式
巴科斯范式(BNF范式)使用递归思想表达语法规范,目的是对语法的进行抽象描述。看起来很像伪代码,如果满足规范后,可执行一个 action ,action 放在 {} 里。
expr: expr PLUS term {语义动作}
| term {语义动作}
;可使用 bisn 做语法解析:巴科斯范式的逆波兰记号计算器的例子:
%{
#define YYSTYPE double
#include
#include
#include
int yylex (void);
void yyerror (char const *);
%}
%token NUM
%%
input: /* empty */
| input line
;
line: '\n'
| exp '\n' { printf ("\t%.10g\n", $1); }
;
exp: NUM { $$ = $1; }
| exp exp '+' { $$ = $1 + $2; }
| exp exp '-' { $$ = $1 - $2; }
| exp exp '*' { $$ = $1 * $2; }
| exp exp '/' { $$ = $1 / $2; }
/* Exponentiation */
| exp exp '^' { $$ = pow($1, $2); }
/* Unary minus */
| exp 'n' { $$ = -$1; }
;
%%
#include
int yylex (void) {
int c;
/* Skip white space. */
while ((c = getchar ()) == ' ' || c == '\t') ;
/* Process numbers. */
if (c == '.' || isdigit (c)) {
ungetc (c, stdin);
scanf ("%lf", &yylval);
return NUM;
}
/* Return end-of-input. */
if (c == EOF) return 0;
/* Return a single char. */
return c;
}
void yyerror (char const *s) {
fprintf (stderr, "%s\n", s);
}
int main (void) {
return yyparse ();
} PHP 中的词法语法实现
词法分析的 Token 正则规则在 Zend/zend_language_scanner.l 中定义
语法分析的 BNF 范式在 Zend/zend_language_parser.y 中定义
可以使用 token_get_all 函数来获取一段 PHP 代码的 Token,如:
输出的 Tokens 为:
Line1 : T_OPEN_TAG 可参考:https://www.cnblogs.com/yanlingyin/archive/2012/04/17/2451717... 对比加强认知。
其中如针对 $a = 1; 这段代码,经过 re2c 和 bison 的词法语法分析后,得到的 AST 结构大致如下:
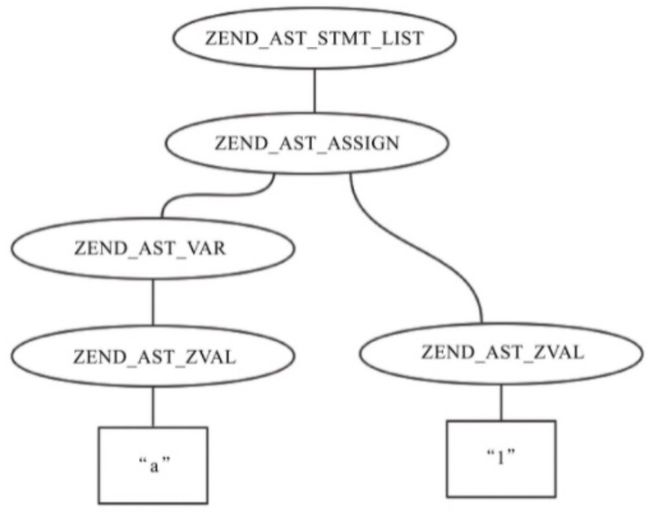
PHP 5 中没有 AST,词法语法分析后,直接得到 op_array 交给虚拟机执行。PHP 7 中增加了 AST。
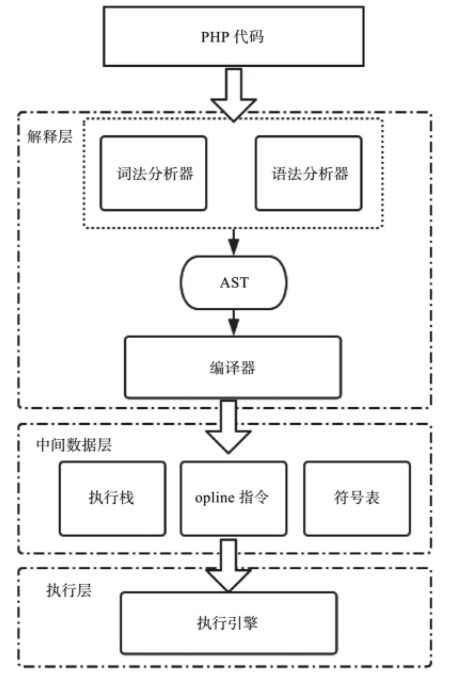
整体的过程图示:

zendparse() 就是词法语法分析,之后生成 AST。
compile_file() 中的 yyparse 函数不断调用 yylex 来获取token,之后加入到 AST 中

Zend 虚拟机编译执行 AST
即词法语法解析生成 AST,并交给编译器生成 op_array 和符号表与指令集,最后交给执行引擎执行opcode。
参考:
PHP的词法解析器 re2c:http://www.phppan.com/2011/09/php-lexical-re2c/
re2c User manual:https://re2c.org/manual/manual_c.html
本文由mdnice多平台发布