jemalloc 5.3.0源码总结

注意:jemalloc 的最新版本里没有所谓的 huge class,bin 中slab外面也不再套一个run的概念了,看其它人分享的文章时需要注意。
简述
用户侧通过 tcache 来访问,tcache 是一个线程的申请又释放的对象的缓存,它绑定了一个固定的arena(分配大小超过8m的除外,8m以上会选择huge arena 来分配),有一个gc机制负责将不用的object 归还给 arena。
arena 分配对象时以8k为界限,以上均为大对象,以下均为小对象。小对象是按 slab 去管理的,即每次从 huge page 或 page 分配一个大的 extent 作为 slab,划分后将整个slab挂在bin的对应大小的组上,然后标记一个返回给用户;大对象则直接分配一个extent 放在arena 的large list上。
arena 是一个逻辑的概念,它真实的数据分配是在shard上进行的,各arena 有不同的shard,内存之间不相交,shard 有 hpa(huge page)和 pac(page)两种分配器,优先使用hpa来分配,但hpa只能承担最多一个huge page 大小的内存,再大就只能用pac去分配。
hpa 在分配前会先用base分配器申请128 个大页,每次分配时从某个大页上切一块下来,pac每次缓存的内存不够时会通过base分配器来分配。
base 分配器一次分配一个block,并存在base 的 list 上。
pac,hpa,base都有一个类型的缓存结构来维护退回来的内存(ppset_t,ecache_t,edata_avail_t)。它们都是用bitmap 维护一个bin列表,bin中的每个元素是符合这一组内存大小的pairing heap最小堆。
size 与 bin 中 index 的映射
每个bin index对应的大小可以直接查表。
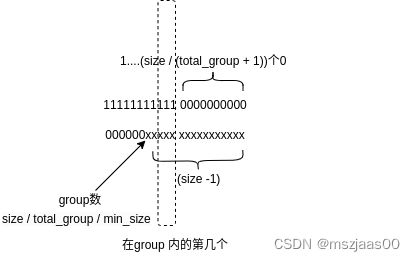
从size 到bin index 的关系在4k以下是可以查表的,4k以上需要计算
group = size / total_group / min_size
group 内的 delta = 1…(size / (total_group + 1))个0 & (size -1)去掉group的位
具体可以参考(sz_size2index_compute)
每个size class 的具体情况可以跑这个代码看下
scs = [None] * 1024
class SC:
def __init__(self, lg_max_lookup, lg_page, lg_ngroup, index, lg_base, lg_delta, ndelta) -> None:
self.index = index
self.lg_base = lg_base
self.lg_delta = lg_delta
self.ndelta = ndelta
self.unit_size = (1 << self.lg_base) + (ndelta << self.lg_delta)
# should from os, default 4096
self.page_size = (1 << lg_page)
# small or large
self.is_small = (self.unit_size < (1 << (lg_page + lg_ngroup)))
self.pages = self.get_slab_size() if self.is_small else 0
# small or large
self.lg_delta_lookup = lg_delta if (self.unit_size <= (1 << lg_max_lookup)) else 0
def get_slab_size(self):
# at most lg_group * 2 - 1 times
use_size = self.page_size
while (use_size % self.unit_size) != 0:
use_size += self.page_size
return use_size
def size_classes(lg_ptr_size, lg_quantum, lg_tiny_min, lg_max_lookup, lg_page, lg_ngroup):
lg_base = lg_tiny_min
lg_delta = lg_base
ngroup = 1 << lg_ngroup
ptr_bits = (1 << lg_ptr_size) * 8
index = 0
ndelta = 0
nlbins = 0 # max lookup table size
nbins = 0
ntiny = 0
lg_tiny_maxclass = 0
# tiny size is 2^n enlarging
while lg_base < lg_quantum:
sc = SC(index, lg_base, lg_delta, ndelta, lg_page, lg_ngroup, lg_max_lookup)
scs[index] = sc
if sc.lg_delta_lookup:
nlbins = index + 1
if sc.is_small:
nbins += 1
ntiny += 1
lg_tiny_maxclass = lg_base
index += 1
lg_delta = lg_base
lg_base += 1
if ntiny != 0:
# first non tiny sc
# use base/delta = quatum-1 rather than base = quatum and delta = 0
lg_base -= 1
first_non_tiny_sc = SC(lg_max_lookup, lg_page, lg_ngroup, index, lg_base, lg_delta, 1)
scs[index] = first_non_tiny_sc
lg_base += 1
index += 1
lg_delta += 1
if sc.is_small:
nbins += 1
while ndelta < ngroup:
sc = SC(lg_max_lookup, lg_page, lg_ngroup, index, lg_base, lg_delta, ndelta)
scs[index] = sc
index += 1
ndelta += 1
if sc.is_small:
nbins += 1
# other groups
lg_base = lg_base + lg_ngroup
while lg_base < ptr_bits - 1:
ndelta = 1
ndelta_limit = ngroup - 1 if lg_base == (ptr_bits - 2) else ngroup
while ndelta <= ndelta_limit:
sc = SC(lg_max_lookup, lg_page, lg_ngroup, index, lg_base, lg_delta, ndelta)
scs[index] = sc
if sc.lg_delta_lookup:
nlbins = index + 1
lookup_maxclass = (1 << lg_base) + (ndelta << lg_delta)
if sc.is_small:
nbins += 1
small_maxclass = (1 << lg_base) + (ndelta << lg_delta)
lg_large_minclass = lg_base + 1 if lg_ngroup > 0 else lg_base + 2
large_maxclass = (1 << lg_base) + (ndelta << lg_delta)
print("large_maxclass:", lg_base, ndelta, lg_delta, large_maxclass)
index += 1
ndelta += 1
lg_base += 1
lg_delta += 1
print(f"""ntiny: {ntiny}
nlbins: {nlbins}
nbins: {nbins}
n: {index}
lg_tiny_maxclass: {lg_tiny_maxclass}
lookup_maxclass: {lookup_maxclass}
small_maxclass: {small_maxclass}
lg_large_minclass: {lg_large_minclass}
large_minclass: {1 << lg_large_minclass}
large_maxclass: {large_maxclass}
""")
indexs = []
bases = []
deltas = []
unit_sizes = []
is_small = []
pages = []
print("""index\tbase\tdelta\tunit_size\tis_small\tpages""")
for i in range(1,1024):
if scs[i] is None:
break
sc = scs[i]
indexs.append(i)
bases.append(sc.lg_base)
deltas.append(sc.ndelta << sc.lg_delta)
unit_sizes.append(sc.unit_size)
is_small.append("yes" if sc.is_small else "no")
pages.append(sc.pages)
print(f"""{i}\t{1 << sc.lg_base}\t{sc.ndelta << sc.lg_delta}\t{sc.unit_size}\t{"yes" if sc.is_small else "no"}\t{sc.pages}""")
LG_SIZEOF_PTR = 3
LG_QUANTUM = 4
SC_LG_TINY_MIN = 3
SC_LG_MAX_LOOKUP = 12
LG_PAGE = 12
SC_LG_NGROUP = 2
size_classes(LG_SIZEOF_PTR, LG_QUANTUM, SC_LG_TINY_MIN, SC_LG_MAX_LOOKUP, LG_PAGE, SC_LG_NGROUP)
SC_NTINY = (LG_QUANTUM - SC_LG_TINY_MIN)
SC_NGROUP = (1 << SC_LG_NGROUP)
SC_NPSEUDO = SC_NGROUP
SC_LG_FIRST_REGULAR_BASE = (LG_QUANTUM + SC_LG_NGROUP)
SC_NBINS = SC_NTINY + SC_NPSEUDO + SC_NGROUP * (LG_PAGE + SC_LG_NGROUP - SC_LG_FIRST_REGULAR_BASE)
print("SC_NBINS is :", SC_NBINS)
cache 的 gc
tcache 大概是这样的:
bound --------full---------waterline----empty
|------------------|----------------|-------------|
其中当数量超过full时,触发一次flush,将一半的对象还回去,剩余的数量称为waterline。(除此之外好像在flush后,又分配对象,然后又释放对象,重回到waterline 以后,比waterline 多的对象作为detach 的对象也可以被flush 走,但没看太懂,不太确定)
大小对象的分配与释放
无论大小对象都是先从tcache分配,检查bitmap 看对应大小的对象有没有剩余,如果有直接拿,如果没有才去arena 分配。
小对象(<8k)
小对象分配是在arena 的 bin 上,每个大小的bin都对应着一系列的slab。分配时先从cur_slab分配,如果cur_slab没有了,就取一个nonfull list的slab放在cur_slab上 分配,如果nonfull list 也没有了,就去pac或hpa重新分配slab,挂在cur_slab上分配。当cur_slab分配没了,就会挂在full slab上,在释放时发现它在full slab 上,则放回到nonfull slab 上。分配的指针与 arena 还有 size 的映射存在arena_emap_global 上。

大对象(>8k)
直接走 pac 或 hpa 分配和释放。分配后挂在arena->large_list 上。有arena_emap_global来维护指针到large_list上edata 元素的映射。释放时也是直接从 large list 上拿走。
internal 分配器
arena 有两种:普通+huge。大于 8m(oversize_threshold) 的对象是在 huge arena 上分配的,小于 8m 的在自己绑定的普通 arena 上分配(除非是用户指定了arena,这时才不会自动转到 huge arena 上分配)。
无论哪种分配器,在分配时都会先尝试用 hpa(hpa 最多 hold 一个大页以下的内存,一般linux 配置是2m),如果超出 hpa 的能力才去普通 pac 分配。
hpa 分配器
hpa 在第一次分配时会申请 128 个 hugepage放在empty list 中。分配时先从 psset 缓存找对应大小的 bitmap,看有没有空闲,如果有就从这个大小的pairing heap上拿最小空闲的一个huge page 下来(这个最小空闲指在这个huge page 上最大的一段连续内存的大小,在所有同组huge page 中是最小的
),如果没有空闲就找下一个更大大小的组,直到找到一个 huge page。根据 huge page的bitmap找到对应的位置,并更新这个 huge page 上最大的没分配范围。
分配出来的内存由edata来记录,并放在shard->emap 上,这是一个前缀树,可以在释放时根据前缀树找到是否有相邻的释放内存,并对它们做合并。
分配后的 huge page 会根据剩余的最大内存重新挂回到psset 上。
释放时内存先从emap 上摘下来,然后在如果它的回归能够让huge page 的最大空闲更新,则把huge page 插入到更合适的 bin 中。释放时如果发现一页完全空了,则可以添加回到psset->empty list中。这些做完后还要标记这个范围到psset->to_purge,会在合适的时间触发purge(实际是提示操作系统不再使用madvice(NONEED))

pac 分配器
pac 也有类似的缓存,但过程不全相同。pac 的页合并不像huge page 那样用bitmap,而是借助 shard_map (见上图) 。pac 在分配时会先找完全满足的bin去分配,如果配置的bin没有空闲,它会找更大一点的bin来split,但只会向上找最多opt_lg_extent_max_active_fit个bin。如果新分配出来的内存对extent 做了切割,那么切割剩的extent 会加入到retained 缓存中。
pac 有三个缓存,dirty / muzzy / retained。分配时先去 dirty cache 找匹配的或能切割的,再去 muzzy 找,如果都找不到,会去 retained 中找,retained 中找不到时才真正去 base 分配,并在切割后将剩余的放到retained 中。
之所以新分配的内存还是有切割可能,是因为pac 每次去 base 进货的单位内存是不断增加的,进货的单位内存有一个 pac->exp_grow 来维护(它有一个增长到的最大 limit值,但应该不起作用,因为limit 值设置为了最大object class size,而这个值对于64位的指针来说就是2^63。)
muzzy 与 dirty 内存的区别: muzzy 的 lazy purge 的时间会更久,dirty 内存在 purge 时,会检查一下可否转为 muzzy,如果能转,则它 purge 的时间会更 delay。这样可以避免频繁向操作系统申请和释放。
base 分配器
base 真正分配 block 时也像 pac 一样有一个申请内存的单位不断增长的机制(由 base->pind_last记录上一次分配的大小级别,下次分配只能比这个级别相等或更大)
真实的分配是由sbrk(dss方式) 或 mmap 系统调用来分配的,默认是先用 mmap 分配(DSS_DEFAULT =“secondary”),用户可以调整。
dss 比 mmap 快,但没有 mmap 灵活。
bitmap
为了加速查找,bitmap 采用的是多层的形式,对当于一个bit-skip-list。