3分钟学会用Arthas排查java服务各种问题
目录
简介
前置操作:attach 进程
dashboard查看java进程总体情况
thread命令
jvm命令
函数耗时监控trace
监控某方法monitor
watch命令观察指定方法
黑科技redefine/retransform
简介
arthas 是阿里开源的一个java问题排查工具,可以在不重启,无代码侵入的情况下做很多事情,有了arthas,很多平时排查起来很麻烦的问题都可以迅速定位,下面给大家介绍几个常用的操作以及场景
(官网地址:https://arthas.aliyun.com/doc/index.html)
前置操作:attach 进程
使用arthas需要首先attach进程
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar下载arthas的jar包后直接启动,(需要注意操作的账号需要和启动attach目标的用户是一样的,要不然会有权限问题)
启动arthas后直接选择进程号,然后回车即可

如上图所示,直接按3然后回车,就能attach进程号为11843的进程

出现上图情况,就说明成功了
dashboard查看java进程总体情况
dashboard是最基础的命令,可以直接查看当前attach的进程的一些基础情况,下图是截图的上半部分,上半部分主要可以看进程里面的一些线程状态

上图各字段含义如下:
- ID: Java级别的线程ID,注意这个ID不能跟jstack中的nativeID一一对应。
- NAME: 线程名
- GROUP: 线程组名
- PRIORITY: 线程优先级, 1~10之间的数字,越大表示优先级越高
- STATE: 线程的状态
- CPU%: 线程的cpu使用率。比如采样间隔1000ms,某个线程的增量cpu时间为100ms,则cpu使用率=100/1000=10%
- DELTA_TIME: 上次采样之后线程运行增量CPU时间,数据格式为秒
- TIME: 线程运行总CPU时间,数据格式为分:秒
- INTERRUPTED: 线程当前的中断位状态
- DAEMON: 是否是daemon线程
下半部分如下,可以看到jvm堆内存和非堆内存的使用情况,堆内存可以看到eden,survivor,old区的内存情况,可以做个简单分析,这是一个活动项目,所以临时请求比较多,大部分对象都处于年轻代新生区,可以看出这个项目新生代使用了ParNew,老年代使用了CMS,gc.parnew.count字段记录了minor gc的次数,通过dashboard的几次刷新,可以看到年轻代gc次数较多。结合启动参数-Xms1024m -Xmx3500m -Xmn512m ,可以看出年轻代设置的有点小,老年代只用了200m,有点空虚。可以适当调大年轻代的大小。tomcat的信息并没有显示,因为只有用Ali-tomcat才会显示

thread命令
dashboard可以查看大概的进程面板,如果需要进一步排查线程方面的问题,则可以使用thread命令
-
输入thread会显示所有线程的状态信息
-
输入thread -n 3会显示当前最忙的3个线程,可以用来排查线程CPU消耗
-
输入thread -b 会显示当前处于BLOCKED状态的线程,可以排查线程锁的问题
-
thread id, 显示指定线程的运行堆栈
-thread --state ,查看指定状态的线程,如thread --state WAITING
jvm命令
输入jvm回车可以看到jvm面板,比dashboard稍微详细一些,没什么好说的

函数耗时监控trace
排查一个接口耗时,可以使用trace去排查,这个命令是性能优化神技。执行trace 类路径+类名 方法名,如 trace com.ss.ss.testController login ,然后会显示下图
稍微耐心等待后,就会有该类的该方法的内部具体耗时。如图

可以看到该次请求耗时363.747871ms,并且下面调动的好几个方法耗时较长,看了下是数据库操作,总体看这个接口其实是没有问题的。如果线上或者压测的时候发现性能有问题,可以通过这个命令去逐个方法排查。
监控某方法monitor
上个命令trace可以监控具体的方法调用路径耗时,但是监控的是一次一次的请求,如果怀疑线上某个方法有可能有问题耗时慢,可以使用monitor命令。
使用monitor -c 60 com.ss.ss.testController login 可以统计60秒为周期的方法监控面板

| 监控项 | 说明 |
|---|---|
| timestamp | 时间戳 |
| class | Java类 |
| method | 方法(构造方法、普通方法) |
| total | 调用次数 |
| success | 成功次数 |
| fail | 失败次数 |
| rt | 平均RT |
| fail-rate | 失败率 |
watch命令观察指定方法
使用watch命令可以观察到指定方法的调用情况。能观察到的范围为:返回值、抛出异常、入参
- watch 命令定义了4个观察事件点,即 -b 方法调用前,-e 方法异常后,-s 方法返回后,-f 方法结束后
- 4个观察事件点 -b、-e、-s 默认关闭,-f 默认打开,当指定观察点被打开后,在相应事件点会对观察表达式进行求值并输出
- 这里要注意方法入参和方法出参的区别,有可能在中间被修改导致前后不一致,除了 -b 事件点 params 代表方法入参外,其余事件都代表方法出参
- 当使用 -b 时,由于观察事件点是在方法调用前,此时返回值或异常均不存在
示例:watch com.ss.ss.testController login "{params,returnObj}" -x 3 表示查看testController 类的login方法的入参和返回,-x 3表示入参和返回值的深度
返回:
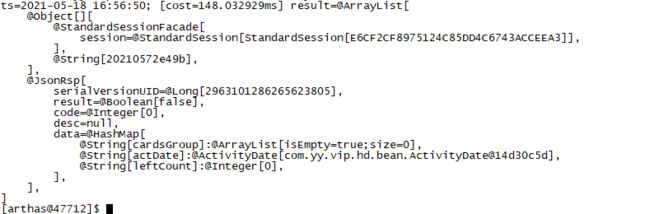
可以看到深度为3的时候hashMap会显示里面的内容
如果把深度改为4 ,则会有如下内容

可以看出,比3的深度要更加详细。
在生产问题排查中,经常也会有程序抛了异常中断没有日志的情况,也可以通过watch命令来查看异常堆栈。
例: watch com.ss.ss.testController login "{params[0],throwExp}" -e -x 2
如果有异常抛出,就能看见堆栈。
"{params[0],throwExp}"为OGNL表达式。
总体来说watch命令还是非常强大的,本文仅抛砖引玉介绍一种排查的手段,具体参数命令可以查看arthas官网。
黑科技redefine/retransform
使用redefine/retransform命令可以重新加载外部的class, edefine/retransform class文件在机器的路径 ,就可以把类热加载。限制如下
- 不允许新增加field/method
- 正在跑的函数,没有退出不能生效,比如下面新增加的System.out.println,只有run()函数里的会生效
使用示例:redefine /usr/home/xxxx/HelloWorld.class或者retransform /usr/home/xxxx/HelloWorld.class
成功了会显示
当线上有点小问题的时候,或者是漏了重要的东西又不方便发版本的时候,可以使用这个命令来做一个小的补丁。不过需要注意的是如果进程重启,redefine/retransform的类会恢复成以前的。
总之,慎用这个功能,不要依赖。附带一个官网介绍的小技巧
