计算机竞赛 基于深度学习的视频多目标跟踪实现
文章目录
- 1 前言
- 2 先上成果
- 3 多目标跟踪的两种方法
-
- 3.1 方法1
- 3.2 方法2
- 4 Tracking By Detecting的跟踪过程
-
- 4.1 存在的问题
- 4.2 基于轨迹预测的跟踪方式
- 5 训练代码
- 6 最后
1 前言
优质竞赛项目系列,今天要分享的是
基于深度学习的视频多目标跟踪实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 先上成果
3 多目标跟踪的两种方法
3.1 方法1
基于初始化帧的跟踪,在视频第一帧中选择你的目标,之后交给跟踪算法去实现目标的跟踪。这种方式基本上只能跟踪你第一帧选中的目标,如果后续帧中出现了新的物体目标,算法是跟踪不到的。这种方式的优点是速度相对较快。缺点很明显,不能跟踪新出现的目标。
3.2 方法2
基于目标检测的跟踪,在视频每帧中先检测出来所有感兴趣的目标物体,然后将其与前一帧中检测出来的目标进行关联来实现跟踪的效果。这种方式的优点是可以在整个视频中跟踪随时出现的新目标,当然这种方式要求你前提得有一个好的“目标检测”算法。
学长主要分享Option2的实现原理,也就是Tracking By Detecting的跟踪方式。
4 Tracking By Detecting的跟踪过程
**Step1:**使用目标检测算法将每帧中感兴趣的目标检测出来,得到对应的(位置坐标, 分类, 可信度),假设检测到的目标数量为M;
**Step2:**通过某种方式将Step1中的检测结果与上一帧中的检测目标(假设上一帧检测目标数量为N)一一关联起来。换句话说,就是在M*N个Pair中找出最像似的Pair。
对于Step2中的“某种方式”,其实有多种方式可以实现目标的关联,比如常见的计算两帧中两个目标之间的欧几里得距离(平面两点之间的直线距离),距离最短就认为是同一个目标,然后通过匈牙利算法找出最匹配的Pair。当让,你还可以加上其他的判断条件,比如我用到的IOU,计算两个目标Box(位置大小方框)的交并比,该值越接近1就代表是同一个目标。还有其他的比如判断两个目标的外观是否相似,这就需要用到一种外观模型去做比较了,可能耗时更长。
在关联的过程中,会出现三种情况:
1)在上一帧中的N个目标中找到了本次检测到的目标,说明正常跟踪到了;
2)在上一帧中的N个目标中没有找到本次检测到的目标,说明这个目标是这一帧中新出现的,所以我们需要把它记录下来,用于下下一次的跟踪关联;
3)在上一帧中存在某个目标,这一帧中并没有与之关联的目标,那么说明该目标可能从视野中消失了,我们需要将其移除。(注意这里的可能,因为有可能由于检测误差,在这一帧中该目标并没有被检测到)

4.1 存在的问题
上面提到的跟踪方法在正常情况下都能够很好的工作,但是如果视频中目标运动得很快,前后两帧中同一个目标运动的距离很远,那么这种跟踪方式就会出现问题。
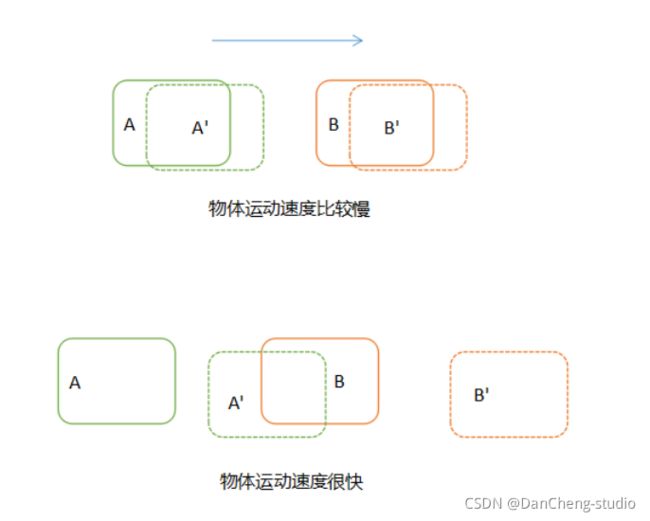
如上图,实线框表示目标在第一帧的位置,虚线框表示目标在第二帧的位置。当目标运行速度比较慢的时候,通过之前的跟踪方式可以很准确的关联(A, A’)和(B,
B’)。但是当目标运行速度很快(或者隔帧检测)时,在第二帧中,A就会运动到第一帧中B的位置,而B则运动到其他位置。这个时候使用上面的关联方法就会得到错误的结果。
那么怎样才能更加准确地进行跟踪呢?
4.2 基于轨迹预测的跟踪方式
既然通过第二帧的位置与第一帧的位置进行对比关联会出现误差,那么我们可以想办法在对比之前,先预测目标的下一帧会出现的位置,然后与该预测的位置来进行对比关联。这样的话,只要预测足够精确,那么几乎不会出现前面提到的由于速度太快而存在的误差
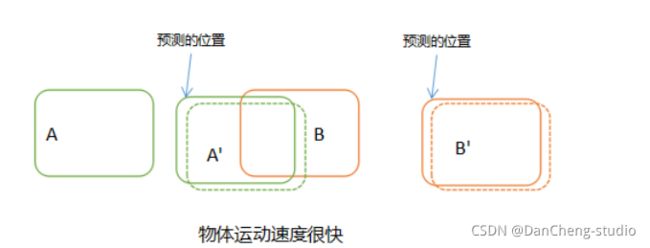
如上图,我们在对比关联之前,先预测出A和B在下一帧中的位置,然后再使用实际的检测位置与预测的位置进行对比关联,可以完美地解决上面提到的问题。理论上,不管目标速度多么快,都能关联上。那么问题来了,怎么预测目标在下一帧的位置?
方法有很多,可以使用卡尔曼滤波来根据目标前面几帧的轨迹来预测它下一帧的位置,还可以使用自己拟合出来的函数来预测下一帧的位置。实际过程中,我是使用拟合函数来预测目标在下一帧中的位置。

如上图,通过前面6帧的位置,我可以拟合出来一条(T->XY)的曲线(注意不是图中的直线),然后预测目标在T+1帧的位置。具体实现很简单,Python中的numpy库中有类似功能的方法。
5 训练代码
这里记录一下训练代码,来日更新
if FLAGS.mode == 'eager_tf':
# Eager mode is great for debugging
# Non eager graph mode is recommended for real training
avg_loss = tf.keras.metrics.Mean('loss', dtype=tf.float32)
avg_val_loss = tf.keras.metrics.Mean('val_loss', dtype=tf.float32)
for epoch in range(1, FLAGS.epochs + 1):
for batch, (images, labels) in enumerate(train_dataset):
with tf.GradientTape() as tape:
outputs = model(images, training=True)
regularization_loss = tf.reduce_sum(model.losses)
pred_loss = []
for output, label, loss_fn in zip(outputs, labels, loss):
pred_loss.append(loss_fn(label, output))
total_loss = tf.reduce_sum(pred_loss) + regularization_loss
grads = tape.gradient(total_loss, model.trainable_variables)
optimizer.apply_gradients(
zip(grads, model.trainable_variables))
logging.info("{}_train_{}, {}, {}".format(
epoch, batch, total_loss.numpy(),
list(map(lambda x: np.sum(x.numpy()), pred_loss))))
avg_loss.update_state(total_loss)
for batch, (images, labels) in enumerate(val_dataset):
outputs = model(images)
regularization_loss = tf.reduce_sum(model.losses)
pred_loss = []
for output, label, loss_fn in zip(outputs, labels, loss):
pred_loss.append(loss_fn(label, output))
total_loss = tf.reduce_sum(pred_loss) + regularization_loss
logging.info("{}_val_{}, {}, {}".format(
epoch, batch, total_loss.numpy(),
list(map(lambda x: np.sum(x.numpy()), pred_loss))))
avg_val_loss.update_state(total_loss)
logging.info("{}, train: {}, val: {}".format(
epoch,
avg_loss.result().numpy(),
avg_val_loss.result().numpy()))
avg_loss.reset_states()
avg_val_loss.reset_states()
model.save_weights(
'checkpoints/yolov3_train_{}.tf'.format(epoch))
6 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate