【Liunx】进程概念,查看进程,进程调用,创建子进程
进程
- 1.什么是进程
- 2.查看进程
- 3.常见进程调用
- 4.创建子进程
1.什么是进程
以前我们在书上或者其他途径了解到进程的概念。
一个运行起来(加载到内存)的的程序叫做进程。
在内存中的程序叫做进程。
进程与程序相比具有动态属性。
这里的概念比较抽象,没有那么容易理解,下面对进程到底是什么做了详细解答。
程序的本质是文件,文件是在磁盘上放着的。
当我们的可执行程序要运行的时候,会由磁盘将程序代码和数据加载到内存中,然后在由cpu去执行,如果只有一个程序还还好说,但是内存不可能只放一个程序的代码和数据。
内存中有太多加载进来的程序,操作系统要不要管理加载进来的多个程序呢?
肯定是要的。

怎么管理?
先描述,在组织。
进而引出了PCB(进程控制块),

然后在用特定的数据结构,把PCB连接起来。

所谓对进程的管理,变成了对进程对应的PCB进行相关的管理。
当cpu要这个程序时,就去pcb找然后把对应的代码和数据拿给cpu。当执行完这个程序时,再由pcb找到该进程对应的代码和数据,然后释放。最后在处理这个pcb。
注意struct tast_struct 这个内核结构体,是由操作系统提供的,用来描述进程的结构体,当程序加载到内存时,操作系统很快就生成进程对应的pcb,然后在链接起来。
总结:
进程 = 内核数据结构(task_struct)+ 进程对应的磁盘代码
为什么会有PCB结构体呢?
上述内容就可以回答这个问题。
2.查看进程
ls /proc //查看所有进程

ps ajx //查看所有进程
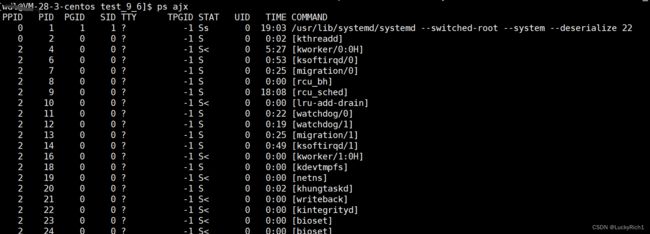
ps ajx | grep 'mytest' //查看指定进程

ps ajx | head -1 //查看进程属性
![]()
ps ajx | head -1 && ps ajx | grep 'mytest' //常用查看进程指令

kill -9 进程编号 //杀死进程

进程在调度运行的时候,进程具有动态属性
3.常见进程调用
进程id(PID)
父进程id(PPID)
getpid() //获得进程id
getppid() //获得父进程id
#include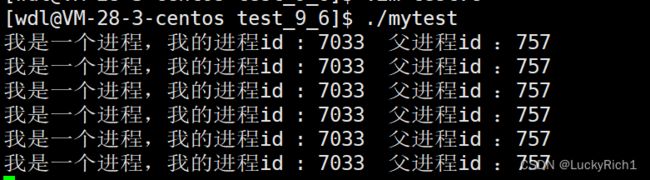

对比上面两张图片,发现父进程的id没有变。
pid是进程id,ppid是父进程id;那么父进程到底是谁呢?

命令行上启动的进程,都是子进程,一般它的父进程没有特殊情况的话,都是bash(命令行解释器shell)
当我们登录linux时,操作系统就给我指定了一个shell,主要怕进程出现了问题导致shell不能用了,所以如果子进程出现问题,就会提示,不会影响到shell,那么就可以通过shell去修改。
4.创建子进程
我们来通过man fork认识一下fork

fork创建一个子进程,返回值是pid_t。
那我们来用一下这个函数。
fork是一个函数----函数执行前,只有一个进程;函数执行后,父进程+子进程
int main()
{
pid_t id=fork();
if(id == 0)
{
//子进程
while(1)
{
printf("我是子进程,我的id : %d, 父进程id : %d, ret : %d\n",getpid(),getppid(),id);
sleep(1);
}
}
else if(id > 0)
{
//父进程
while(1)
{
printf("我是父进程,我的id : %d, 父进程id : %d, ret : %d\n",getpid(),getppid(),id);
sleep(3);
}
}
else
{
perror("fork fail\n");
return 1;
}
return 0;
}

![]()
成功创建子进程,子进程的id就会返回给父进程,0返回给子进程,创建失败,返回错误。
看到这里大家马上就有疑问了
1.根据前面掌握C语言的知识,if else语句只能执行一次,并且while是一个死循环,怎么能跳出循环执行其它的?
2.同一个变量id,在后续没有修改的情况下,竟然有不同内容!
在后面进程地址空间没有讲,这里没有办法解释清楚,到那里在讲。
这里浅浅总结一下:
1.fork之后,会有父进程+子进程两个进程在执行后续代码
2.fork后续的代码,被父子进程共享
3.通过返回值不同,让父子进程执行后续共享代码的一部分。
通过fork我们就可以进行多线程的任务了。