GoLang
文章目录
- GoLang
-
- 1.GoLang工程文件夹分层模式
- 2.GoLang执行流程分析
-
- 2.1源码main.go及hello.go
- 2.2说明:两种执行流程的方式区别
- 2.3编译和运行的注意事项
- 2.4Go程序开发的注意事项
- 3.Go语言的转义字符
-
- 3.1常用转义字符
- 4.Golang官网
- 5.GoLang的变量与包与函数
-
- 5.1变量实例
-
- 5.1.1变量使用的注意事项
- 5.2包
- 5.3包的导入
- 5.4导出名
- 5.5函数与返回值
- 5.6基本类型
- 5.7零值
- 5.8类型转换
- 5.9常量
- 5.10数值常量
- 6.流程控制语句
-
- 6.1for循环
- 6.2if判断
- 6.3练习:循环与函数
- 6.4switch
- 6.5defer
- 7.更多类型:struct、slice和映射
-
- 7.1指针
- 7.2结构体
-
- 一般格式与c类似
- **访问方式**
- **使用指针的访问方式**
- **结构体文法**
- 7.3数组
- 7.4切片
-
- **切片文法**
- 切片的默认行为
- 切片的长度与容量
- 使用`make`创建切片
- 切片的切片
- 向切片追加元素
- 7.5Range(切片的循环)
- 7.6练习:切片
- 7.7映射
-
- **map的概念**
- 映射的文法
- 修改映射
- 7.8练习:映射
- 7.9函数值
-
- 函数的闭包
- 7.10练习:斐波那契闭包
- 8.方法和接口
-
- 8.1方法(函数)
- 8.2指针接收者
- 8.3方法与指针重定向
- 8.4 interface
-
- interface
-
- 什么是interface
- interface类型
- interface值
- 空interface
- interface函数参数
- interface变量存储的类型
- 嵌入interface
- 反射
- 9. 并发
- goroutine
- channels
- Buffered Channels
- Range和Close
- Select
- 超时
- runtime goroutine
GoLang
1.GoLang工程文件夹分层模式
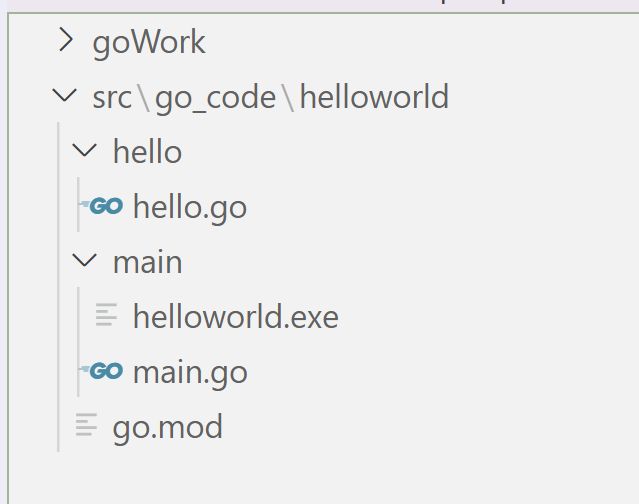
2.GoLang执行流程分析
2.1源码main.go及hello.go
hello.go
package hello
import (
"fmt"
)
func Hello() {
fmt.Println("hello world")
}
main.go
package main
import (
"test01/hello"
)
func main() {
hello.Hello()
}
2.2说明:两种执行流程的方式区别
1)如果先编译生成可执行文件,那么我们可以将该执行文件拷贝到没有go开发环境的机器上,依然可以运行。
2)如果我们直接使用go run go源代码,那么如果要在另一个机器上这么运行,也需要go开发环境,否则无法执行。
3)在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以可执行文件变大了很多。
2.3编译和运行的注意事项
1)有了go源文件,通过编译器将其编译成机器可以识别的二进制码文件。
2)在该源文件目录下,通过go build 对hello.go文件进行编译。可以指定生成的可执行文件名,在windows下,必须是.exe后缀。
go build -o myhello main.go
3)如果程序没有错误,没有任何提示,会在当前目录下出现一个可执行文件,该文件是二进制码文件,也是可执行的程序。
4)如果程序有错误,编译时,会在错误的那行报错。有助于程序员调试错误。
5)运行有两种形式
hello.exe
./hello
2.4Go程序开发的注意事项
1)扩展名以.go结尾。
2)Go应用程序的执行入口是main()函数。
3)Go语言严格区分大小写。
4)Go方法是由一条条语句构成的,每个语句后面不需要加分号(Go语言会自动在每行后自动加分号)。
5)Go编译器是一行一行编译的,因此我们一行就写一条语句,不能把多行写在同一个,否则报错。
6)Go语言定义的变量或者import的包如果没有使用到,代码不能编译通过。
7)大括号都是成对出现的,缺一不可。
3.Go语言的转义字符
3.1常用转义字符
- \t 制表符,实现对齐功能
- \n 换行符
- 双斜杠,表示单斜杠
- \r 回车
4.Golang官网
https://golang.org
5.GoLang的变量与包与函数
5.1变量实例
package main
import "fmt"
func main() {
//定义变量
var i int
//给i赋值
i = 10
//使用变量i
fmt.Print(i);
}

5.1.1变量使用的注意事项
1)变量表示内存中的一个存储区域。
2)该区域有自己的名称(变量名)和类型(数据类型)。
3)GoLang变量的使用有三种方式:
- 指定变量类型,声明后若不赋值,使用默认值
- 根据值自行判断变量类型(类型推导)
- 省略var,注意:=左侧的变量不应该是已经声明过的,否则会导致编译错误
num := 10
4)多变量声明
在变成过程中,有时我们需要一次性声明多个变量,Golang也提供了这样的语法
//1
var n1, n2, n3 int
//2
var name, age, add = "tom", 13, "tianjin"
//3 (**注意**不能再函数外使用)
name, age, add := "tom", 13, "tianjin"
如何一次性声明多个全局变量
var(
n1 = 100
n2 = 200
n3 = 300
)
5)该区域的数据值可以在同一类型范围内不断变化。
6)变量在同一作用域内不能重名。
7)变量 = 变量名 + 值 + 数据类型。
8)Golang的变量如果没有赋初值,编译器会使用默认值。
5.2包
1)每个 Go 程序都是由包构成的。
2)程序从 main 包开始运行。
package main
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("My favorite number is", rand.Intn(10))
}
3)本程序通过导入路径 "fmt" 和 "math/rand" 来使用这两个包。
4)按照约定,包名与导入路径的最后一个元素一致。例如,"math/rand" 包中的源码均以 package rand 语句开始。
注意: 此程序的运行环境是固定的,因此 rand.Intn 总是会返回相同的数字。 (要得到不同的数字,需为生成器提供不同的种子数,参见 rand.Seed。 练习场中的时间为常量,因此你需要用其它的值作为种子数。)
5.3包的导入
导入方式
//分组导入
import (
"fmt"
"math"
)
//分条导入
import "fmt"
import "math"
5.4导出名
***例:***有一个hello.go的文件和一个main.go的主文件,在main中import hello.go的包
import "helloworld/hello"
//helloworld为项目名称,与go.mod中的module同名,hello为hello.go中的package hello中的hello
hello.go中存在两个方法helloworld 和 Hello
func helloworld() {
fmt.Print("hello world")
}
func Hello() {
fmt.Print("hello world")
}
在main.go的main()函数中调用包"helloworld/hello" 的两个函数
hello.helloworld()
hello.Hello()
运行main()函数
go run .\main.go
运行结果

5.5函数与返回值
- 函数可以没有参数或接收多个参数
//不接受参数的参照上面的Hello
//接收一个参数没有返回值
func hello(str string) {
fmt.Print(str)
}
//接收多个参数没有返回值
func hello1(str string,str1 string) {
fmt.Print(str,str1)
}
//两个入参的数据类型相同时,第一个入参的数据类型可省略
func hello1(str, str1 string) {
fmt.Print(str,str1)
}
- Golang的返回值也可以没有返回值或有多个返回值
//没有返回值的函数可以参照上面的hello
//存在一个返回值的函数
func add(x, y int) int {
return x + y
}
//存在多个返回值的函数
func printXY(x, y int) (int, int) {
return x, y
}
-
命名返回值
- Go 的返回值可被命名,它们会被视作定义在函数顶部的变量。
- 返回值的名称应当具有一定的意义,它可以作为文档使用。
- 没有参数的
return语句返回已命名的返回值。也就是直接返回。 - 直接返回语句应当仅用在下面这样的短函数中。在长的函数中它们会影响代码的可读性。
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
func main() {
fmt.Println(split(17))
}
5.6基本类型
-
Go的基本类型有
- bool
- string
- int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr
- byte //uint8的别名
- rune //int32的别名,表示一个Unicode码点
- float32 float64
- complex64 complex128 //复数
-
int,uint和uintptr在 32 位系统上通常为 32 位宽,在 64 位系统上则为 64 位宽。 当你需要一个整数值时应使用int类型,除非你有特殊的理由使用固定大小或无符号的整数类型。
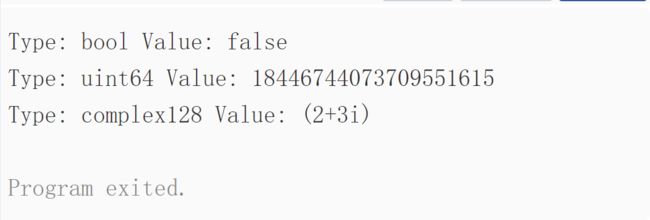
例:
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
func main() {
fmt.Printf("Type: %T Value: %v\n", ToBe, ToBe)
fmt.Printf("Type: %T Value: %v\n", MaxInt, MaxInt)
fmt.Printf("Type: %T Value: %v\n", z, z)
}
运行结果
5.7零值
没有明确初始值的变量声明会被赋予它们的 零值。
零值是:
- 数值类型为
0,- 布尔类型为
false,- 字符串为
""(空字符串)。
5.8类型转换
表达式
T(v)将值v转换为类型T。
对照
//c语言中的隐式转换
int i = 1;
float j = i;
//在go中不存在隐式转换,只能使用显式转换
var i int = 1
var j float64 = float64(i)
5.9常量
常量的声明与变量类似,只不过是使用
const关键字。常量可以是字符、字符串、布尔值或数值。
常量不能用
:=语法声明。
const Pi = 3.14
func main() {
const World = "世界"
fmt.Println("Hello", World)
fmt.Println("Happy", Pi, "Day")
const Truth = true
fmt.Println("Go rules?", Truth)
}
5.10数值常量
数值常量是一个高精度的***值***
一个未指定类型的常量由上下文来决定其类型
const (
// 将 1 左移 100 位来创建一个非常大的数字
// 即这个数的二进制是 1 后面跟着 100 个 0
Big = 1 << 100
// 再往右移 99 位,即 Small = 1 << 1,或者说 Small = 2
Small = Big >> 99
)
6.流程控制语句
6.1for循环
Go只有一种循环结构:for循环
For循环的基本格式
for 初始化语句;条件表达式;后置语句 {
}
for i := 1; i < 10; i ++ {
}
//省略初始语句和后置语句的循环(分号可以省略)
for ; i < 10; {
}
//省略三个构成部分后可以形成无限循环
for {
}
**注意:Go的for语句后面的三个构成部分没有小括号,但是大括号是必须的。
6.2if判断
***注意:***与Go中的for循环类似,在条件判断上不需要小括号,大括号是必须的
if i < 10 {
}else {
}
***if语句的特殊写法:***if语句可以在条件表达式前执行一个简单的语句,语句的作用域尽在if之内
k := 3
if v := 2; v < k {
return v
}else {
}
6.3练习:循环与函数
题目:为了练习函数与循环,我们来实现一个平方根函数:用牛顿法实现平方根函数。
计算机通常使用循环来计算 x 的平方根。从某个猜测的值 z 开始,我们可以根据 z² 与 x 的近似度来调整 z,产生一个更好的猜测:
z -= (z*z - x) / (2*z)重复调整的过程,猜测的结果会越来越精确,得到的答案也会尽可能接近实际的平方根。
package main
import "fmt"
func Sqrt(num float64) float64 {
z := num / 2
for i := 0; i < 10; i++ {
z -= (z * z - num) / (2 * z)
fmt.Print(z,"\t")
}
return num
}
func main() {
fmt.Println(Sqrt(3))
}
输出结果:
![]()
1.7320508075688772
6.4switch
switch是编写一连串if - else语句的简便方法。它运行第一个值等于条件表达式的 case 语句。
**区别:**Go 的 switch 语句类似于 C、C++、Java、JavaScript 和 PHP 中的,不过 Go 只运行选定的 case,而非之后所有的 case。 实际上,Go 自动提供了在这些语言中每个 case 后面所需的 break 语句。 除非以 fallthrough 语句结束,否则分支会自动终止。 Go 的另一点重要的不同在于 switch 的 case 无需为常量,且取值不必为整数。
**执行顺序:**顺次执行,当满足条件时不会在继续向下执行。
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.\n", os)
}
**没有条件的switch:**没有条件的switch同switch true 一样,这种形式能将一长串if-then-else写的更加清晰。
switch {
case s > 10 :
fmt.Println(s + 1)
case s < 5 :
fmt.Println(s - 1)
default :
fmt.Println(s)
}
6.5defer
defer 语句会将函数推迟到外层函数返回之后执行。
推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用。
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
运行结果:

输出顺序: 倒序
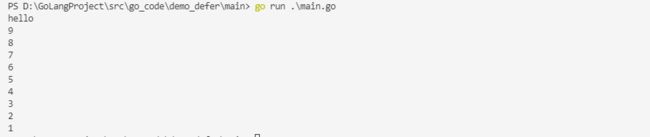
推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用。
func main() {
for i := 1; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("hello")
}
运行结果:
7.更多类型:struct、slice和映射
7.1指针
-
指针保存了值的内存地址;
-
类型*T是指向T类型值的指针,零值为nil;
-
&操作符会生成一个指向其操作数的指针
解释:
i := 21 p := &i向i赋值21,p := &i代表将i和p绑定到ide地址上,p为i的地址,*p为i的值,当修改 *p的值时,i的值也会发生改变
-
*操作表示指针指向的底层值;
-
与c不同,Go没有指针运算
7.2结构体
一般格式与c类似
type Ver struct {
X int
Y int
}
访问方式
v := Ver{1,2}//初始化
v.X//访问
v.Y
使用指针的访问方式
v := Ver{1,2}
p := &v//使用指针访问
p.X = 10//X为int类型,访问方式如同(*p).X
结构体文法
var (
v1 = Vertex{1, 2} // 创建一个 Vertex 类型的结构体
v2 = Vertex{X: 1} // Y:0 被隐式地赋予
v3 = Vertex{} // X:0 Y:0
p = &Vertex{1, 2} // 创建一个 *Vertex 类型的结构体(指针)
)
***赋值方式:***Name: 语法可以仅列出部分字段。
7.3数组
类型
[n]T表示拥有n个T类型的值的数组。
var a [10]int//创建一个长度为10的整型数组,数组的长度不能改变
a[0] = 1 //赋值,数组的下标从0开始,长度为10,则他的实际可用位置为0,1,2,3,4,5,6,7,8,9
b := [6]int{3,4,5,6,7,8}
7.4切片
每个数组的大小都是固定的。而切片则为数组元素提供动态大小的、灵活的视角。在实践中,切片比数组更常用。
类型 []T 表示一个元素类型为 T 的切片。
切片通过两个下标来界定,即一个上界和一个下界,二者以冒号分隔:
a[low : high]
它会选择一个半开区间,包括第一个元素,但排除最后一个元素。
以下表达式创建了一个切片,它包含 a 中下标从 1 到 3 的元素:
a[1:4]
a := [8]int{1,2,3,4,5,6,7,8}
var s []int = a[1:4]//s := a[1:4]
//s的输出结果为
[2 3 4]
- 切片就像数组的引用
- 切片并不存储任何数据,它只是描述了底层数组中的一段。
- 更改切片的元素会修改其底层数组中对应的元素。
- 与它共享底层数组的切片都会观测到这些修改。
切片文法
数组文法
[3]bool{true,true,false}
下面这样则会创建一个和上面相同的数组,然后构建一个引用了它的切片:
[]bool{true, true, false}
q := []int{2, 3, 5, 7, 11, 13}
fmt.Println(q)
r := []bool{true, false, true, true, false, true}
fmt.Println(r)
s := []struct {
i int
b bool
}{
{2, true},
{3, false},
{5, true},
{7, true},
{11, false},
{13, true},
}
fmt.Println(s)
切片的默认行为
在进行切片时,你可以利用它的默认行为来忽略上下界。
切片下界的默认值为
0,上界则是该切片的长度。对于数组
var a [10]int来说,以下切片是等价的:
a[0:10] a[:10] a[0:] a[:]
切片的长度与容量
切片拥有 长度 和 容量。
切片的长度就是它所包含的元素个数。
切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。
切片
s的长度和容量可通过表达式len(s)和cap(s)来获取。
func main() {
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
// 截取切片使其长度为 0
s = s[:0]
printSlice(s)
// 拓展其长度
s = s[:4]
printSlice(s)
// 舍弃前两个值
s = s[2:]
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}

***注意:***切片的零值是 nil。nil 切片的长度和容量为 0 且没有底层数组。
使用make创建切片
切片可以用内建函数
make来创建,这也是你创建动态数组的方式。
make 函数会分配一个元素为零值的数组并返回一个引用了它的切片:
a := make([]int, 5) // len(a)=5
要指定它的容量,需向 make 传入第三个参数:
b := make([]int, 0, 5) // len(b)=0, cap(b)=5
b = b[:cap(b)] // len(b)=5, cap(b)=5
b = b[1:] // len(b)=4, cap(b)=4
切片的切片
切片可以包含任何类型,甚至包含其他的切片
// 创建一个井字板(经典游戏)
board := [][]string{
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
}
// 两个玩家轮流打上 X 和 O
board[0][0] = "X"
board[2][2] = "O"
board[1][2] = "X"
board[1][0] = "O"
board[0][2] = "X"
for i := 0; i < len(board); i++ {
fmt.Printf("%s\n", strings.Join(board[i], " "))
}
向切片追加元素
为切片追加新的元素是种常用的操作,为此 Go 提供了内建的
append函数。内建函数的文档对此函数有详细的介绍。func append(s []T, vs ...T) []T
append的第一个参数s是一个元素类型为T的切片,其余类型为T的值将会追加到该切片的末尾。
append的结果是一个包含原切片所有元素加上新添加元素的切片。当
s的底层数组太小,不足以容纳所有给定的值时,它就会分配一个更大的数组。返回的切片会指向这个新分配的数组。
7.5Range(切片的循环)
for循环的range形式可遍历切片或映射。当使用
for循环遍历切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
var pow = []int{1,2,3,4,5,6}
func main() {
for i, v := range pow {
fmt.Println(i,v)//i切片下标,v对应下标i的切片值
}
}
//对下标和值的忽略
//使用_来忽略
for _, v := range pow
for i, _ := range pow
//对于只需要索引的情况可以忽略_
for i := range pow
7.6练习:切片
题目:实现
Pic。它应当返回一个长度为dy的切片,其中每个元素是一个长度为dx,元素类型为uint8的切片。当你运行此程序时,它会将每个整数解释为灰度值(好吧,其实是蓝度值)并显示它所对应的图像。
import "golang.org/x/tour/pic"
func Pic(dx, dy int) [][]uint8 {
picy := make([][]uint8, dy)
for i,_ := range picy {
picx := make([]uint8, dx)
for j,_ := range picx{
picx[j] = uint8((i + j) / 2)
}
picy[i] = picx
}
return picy
}
func main() {
pic.Show(Pic)
}
结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WBRIJdZz-1639449223819)(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAIAAADTED8xAAACaUlEQVR42uzVMRGAAAzAwLSHf8tgAAf95QVkyVNvNRN50FWBl10V6ABa0AFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIB6ADqEAHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdAA6gBZ0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIBSAcgHYB0ANIB6AAq0AFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgHQA0gFIByAdgA6gAh2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADSAUgHIB2AdADyxy8AAP//YSoDD5pLB7MAAAAASUVORK5CYII=)]
7.7映射
map的概念
map 是引用类型,可以使用如下方式声明:
var mapname map[keytype]valuetype
其中:
- mapname 为 map 的变量名。
- keytype 为键类型。
- valuetype 是键对应的值类型。
提示:[keytype] 和 valuetype 之间允许有空格。
在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 pair 的数目。
nil 映射既没有键,也不能添加键。
make 函数会返回给定类型的映射,并将其初始化备用。
【示例】
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m map[string]Vertex
func main() {
m = make(map[string]Vertex)
m["Bell Labs"] = Vertex{
40.68433, -74.39967,
}
fmt.Println(m["Bell Labs"])
}
映射的文法
映射的文法与结构体相似,不过必须有键名。
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": Vertex{
40.68433, -74.39967,
},
"Google": Vertex{
37.42202, -122.08408,
},
}
若顶级类型只是一个类型名,你可以在文法的元素中省略它。
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": {40.68433, -74.39967},
"Google": {37.42202, -122.08408},
}
修改映射
在映射 m 中插入或修改元素:
m[key] = elem
获取元素:
elem := m[key]
删除元素:
delete(m, key)
通过双赋值检测某个键是否存在:
elem, ok := m[key]
若 key 在 m 中,ok 为 true ;否则,ok 为 false。
若 key 不在映射中,那么 elem 是该映射元素类型的零值。
同样的,当从映射中读取某个不存在的键时,结果是映射的元素类型的零值。
7.8练习:映射
题目:实现
WordCount。它应当返回一个映射,其中包含字符串s中每个“单词”的个数。函数wc.Test会对此函数执行一系列测试用例,并输出成功还是失败。
import (
"golang.org/x/tour/wc"
"strings"
)
func WordCount(s string) map[string]int {
str := strings.Fields(s)
str = str[:]
m := make(map[string]int)
for _, values := range str {
elem, ok := m[string(values)]
if ok == true {
m[string(values)] = elem + 1
}else {
m[string(values)] = 1
}
}
return m
}
func main() {
wc.Test(WordCount)
}
结果:
PASS
f(“I am learning Go!”) =
map[string]int{“Go!”:1, “I”:1, “am”:1, “learning”:1}
PASS
f(“The quick brown fox jumped over the lazy dog.”) =
map[string]int{“The”:1, “brown”:1, “dog.”:1, “fox”:1, “jumped”:1, “lazy”:1, “over”:1, “quick”:1, “the”:1}
PASS
f(“I ate a donut. Then I ate another donut.”) =
map[string]int{“I”:2, “Then”:1, “a”:1, “another”:1, “ate”:2, “donut.”:2}
PASS
f(“A man a plan a canal panama.”) =
map[string]int{“A”:1, “a”:2, “canal”:1, “man”:1, “panama.”:1, “plan”:1}
Process finished with the exit code 0
7.9函数值
函数也是值。它们可以像其它值一样传递。
函数值可以用作函数的参数或返回值。
【示例】
func compute(fn func(float64, float64) float64) float64 {
return fn(3, 4)
}
func main() {
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(5, 12))
fmt.Println(compute(hypot))
fmt.Println(compute(math.Pow))
}
函数的闭包
Go 函数可以是一个闭包。闭包是一个函数值,它引用了其函数体之外的变量。该函数可以访问并赋予其引用的变量的值,换句话说,该函数被这些变量“绑定”在一起。
例如,函数
adder返回一个闭包。每个闭包都被绑定在其各自的sum变量上。
【示例】
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
7.10练习:斐波那契闭包
让我们用函数做些好玩的事情。
实现一个
fibonacci函数,它返回一个函数(闭包),该闭包返回一个斐波纳契数列(0, 1, 1, 2, 3, 5, ...)。
斐波那契数
斐波那契数(意大利语:Successione di Fibonacci),又译为菲波拿契数、菲波那西数、斐氏数、黄金分割数。所形成的数列称为斐波那契数列(意大利语:Successione di Fibonacci),又译为菲波拿契数列、菲波那西数列、斐氏数列、黄金分割数列。
在数学上,斐波那契数是以递归的方法来定义:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbUcXxDR-1639449223819)(https://wikimedia.org/api/rest_v1/media/math/render/svg/58ebe8b2d5551fb272cd4258940fe1e492592d02)]
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zt4S58oU-1639449223820)(https://wikimedia.org/api/rest_v1/media/math/render/svg/c374ba08c140de90c6cbb4c9b9fcd26e3f99ef56)]
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6tDPDmQj-1639449223820)(https://wikimedia.org/api/rest_v1/media/math/render/svg/4fa6d281e7a54e08aeffeef7458ddc0884333686)](n≧2)
用文字来说,就是斐波那契数列由0和1开始,之后的斐波那契数就是由之前的两数相加而得出。首几个斐波那契数是:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377 ,610, 987……(OEIS中的数列A000045)
特别指出:0不是第一项,而是第零项。
import "fmt"
// 返回一个“返回int的函数”
func fibonacci() func() int {
a := 0
b := 1
return func() int {
fi := a + b
a = b
b = fi
return fi
}
}
func main() {
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
结果:
1
2
3
5
8
13
21
34
55
89
Process finished with the exit code 0
8.方法和接口
8.1方法(函数)
Go没有类。
不过你可以为结构体类型定义方法。
方法就是一类带特殊的 接收者 参数的函数。
方法接收者在它自己的参数列表内,位于
func关键字和方法名之间。在此例中,
Abs方法拥有一个名为v,类型为Vertex的接收者。
【示例】
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := Vertex{3, 4}
fmt.Println(v.Abs())
}
你也可以为非结构体类型声明方法。
在此例中,我们看到了一个带
Abs方法的数值类型MyFloat。你只能为在同一包内定义的类型的接收者声明方法,而不能为其它包内定义的类型(包括
int之类的内建类型)的接收者声明方法。(译注:就是接收者的类型定义和方法声明必须在同一包内;不能为内建类型声明方法。)
【示例】
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
//错误案例
func (i int) Abs() int {
return 0
}
8.2指针接收者
你可以为指针接收者声明方法。
这意味着对于某类型
T,接收者的类型可以用*T的文法。(此外,T不能是像*int这样的指针。)
【示例】
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 4}
v.Scale(10)
fmt.Println(v.Abs())
}
说明:
函数scale,可以修改v所指向的值,当函数scale变为值引用方法时,借由scale修改的值只在函数内有效,不会修改函数外的值(v 真正的值)
修改Abs和Scale方法为函数
func Abs(v Vertex) float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func Scale(v *Vertex, f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 4}
Scale(&v, 10)
fmt.Println(Abs(v))
}
说明:
此时的Scale函数与之前的作用相同
8.3方法与指针重定向
比较前两个程序,你大概会注意到带指针参数的函数必须接受一个指针:
var v Vertex ScaleFunc(v, 5) // 编译错误! ScaleFunc(&v, 5) // OK而以指针为接收者的方法被调用时,接收者既能为值又能为指针:
var v Vertex v.Scale(5) // OK p := &v p.Scale(10) // OK对于语句
v.Scale(5),即便v是个值而非指针,带指针接收者的方法也能被直接调用。 也就是说,由于Scale方法有一个指针接收者,为方便起见,Go 会将语句v.Scale(5)解释为(&v).Scale(5)。
同样的事情也发生在相反的方向。
接受一个值作为参数的函数必须接受一个指定类型的值:
var v Vertex fmt.Println(AbsFunc(v)) // OK fmt.Println(AbsFunc(&v)) // 编译错误!而以值为接收者的方法被调用时,接收者既能为值又能为指针:
var v Vertex fmt.Println(v.Abs()) // OK p := &v fmt.Println(p.Abs()) // OK这种情况下,方法调用
p.Abs()会被解释为(*p).Abs()。
8.4 interface
interface
Go语言里面设计最精妙的应该算interface,它让面向对象,内容组织实现非常的方便,当你看完这一章,你就会被interface的巧妙设计所折服。
什么是interface
简单的说,interface是一组method签名的组合,我们通过interface来定义对象的一组行为。
我们前面一章最后一个例子中Student和Employee都能SayHi,虽然他们的内部实现不一样,但是那不重要,重要的是他们都能say hi
让我们来继续做更多的扩展,Student和Employee实现另一个方法Sing,然后Student实现方法BorrowMoney而Employee实现SpendSalary。
这样Student实现了三个方法:SayHi、Sing、BorrowMoney;而Employee实现了SayHi、Sing、SpendSalary。
上面这些方法的组合称为interface(被对象Student和Employee实现)。例如Student和Employee都实现了interface:SayHi和Sing,也就是这两个对象是该interface类型。而Employee没有实现这个interface:SayHi、Sing和BorrowMoney,因为Employee没有实现BorrowMoney这个方法。
interface类型
interface类型定义了一组方法,如果某个对象实现了某个接口的所有方法,则此对象就实现了此接口。详细的语法参考下面这个例子
type Human struct {
name string
age int
phone string
}
type Student struct {
Human //匿名字段Human
school string
loan float32
}
type Employee struct {
Human //匿名字段Human
company string
money float32
}
//Human对象实现Sayhi方法
func (h *Human) SayHi() {
fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone)
}
// Human对象实现Sing方法
func (h *Human) Sing(lyrics string) {
fmt.Println("La la, la la la, la la la la la...", lyrics)
}
//Human对象实现Guzzle方法
func (h *Human) Guzzle(beerStein string) {
fmt.Println("Guzzle Guzzle Guzzle...", beerStein)
}
// Employee重载Human的Sayhi方法
func (e *Employee) SayHi() {
fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name,
e.company, e.phone) //此句可以分成多行
}
//Student实现BorrowMoney方法
func (s *Student) BorrowMoney(amount float32) {
s.loan += amount // (again and again and...)
}
//Employee实现SpendSalary方法
func (e *Employee) SpendSalary(amount float32) {
e.money -= amount // More vodka please!!! Get me through the day!
}
// 定义interface
type Men interface {
SayHi()
Sing(lyrics string)
Guzzle(beerStein string)
}
type YoungChap interface {
SayHi()
Sing(song string)
BorrowMoney(amount float32)
}
type ElderlyGent interface {
SayHi()
Sing(song string)
SpendSalary(amount float32)
}
通过上面的代码我们可以知道,interface可以被任意的对象实现。我们看到上面的Men interface被Human、Student和Employee实现。同理,一个对象可以实现任意多个interface,例如上面的Student实现了Men和YoungChap两个interface。
最后,任意的类型都实现了空interface(我们这样定义:interface{}),也就是包含0个method的interface。
interface值
那么interface里面到底能存什么值呢?如果我们定义了一个interface的变量,那么这个变量里面可以存实现这个interface的任意类型的对象。例如上面例子中,我们定义了一个Men interface类型的变量m,那么m里面可以存Human、Student或者Employee值。
因为m能够持有这三种类型的对象,所以我们可以定义一个包含Men类型元素的slice,这个slice可以被赋予实现了Men接口的任意结构的对象,这个和我们传统意义上面的slice有所不同。
让我们来看一下下面这个例子:
package main
import "fmt"
type Human struct {
name string
age int
phone string
}
type Student struct {
Human //匿名字段
school string
loan float32
}
type Employee struct {
Human //匿名字段
company string
money float32
}
//Human实现SayHi方法
func (h Human) SayHi() {
fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone)
}
//Human实现Sing方法
func (h Human) Sing(lyrics string) {
fmt.Println("La la la la...", lyrics)
}
//Employee重载Human的SayHi方法
func (e Employee) SayHi() {
fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name,
e.company, e.phone)
}
// Interface Men被Human,Student和Employee实现
// 因为这三个类型都实现了这两个方法
type Men interface {
SayHi()
Sing(lyrics string)
}
func main() {
mike := Student{Human{"Mike", 25, "222-222-XXX"}, "MIT", 0.00}
paul := Student{Human{"Paul", 26, "111-222-XXX"}, "Harvard", 100}
sam := Employee{Human{"Sam", 36, "444-222-XXX"}, "Golang Inc.", 1000}
tom := Employee{Human{"Tom", 37, "222-444-XXX"}, "Things Ltd.", 5000}
//定义Men类型的变量i
var i Men
//i能存储Student
i = mike
fmt.Println("This is Mike, a Student:")
i.SayHi()
i.Sing("November rain")
//i也能存储Employee
i = tom
fmt.Println("This is tom, an Employee:")
i.SayHi()
i.Sing("Born to be wild")
//定义了slice Men
fmt.Println("Let's use a slice of Men and see what happens")
x := make([]Men, 3)
//这三个都是不同类型的元素,但是他们实现了interface同一个接口
x[0], x[1], x[2] = paul, sam, mike
for _, value := range x{
value.SayHi()
}
}
通过上面的代码,你会发现interface就是一组抽象方法的集合,它必须由其他非interface类型实现,而不能自我实现, Go通过interface实现了duck-typing:即"当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子"。
空interface
空interface(interface{})不包含任何的method,正因为如此,所有的类型都实现了空interface。空interface对于描述起不到任何的作用(因为它不包含任何的method),但是空interface在我们需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值。它有点类似于C语言的void*类型。
// 定义a为空接口
var a interface{}
var i int = 5
s := "Hello world"
// a可以存储任意类型的数值
a = i
a = s
一个函数把interface{}作为参数,那么他可以接受任意类型的值作为参数,如果一个函数返回interface{},那么也就可以返回任意类型的值。是不是很有用啊!
interface函数参数
interface的变量可以持有任意实现该interface类型的对象,这给我们编写函数(包括method)提供了一些额外的思考,我们是不是可以通过定义interface参数,让函数接受各种类型的参数。
举个例子:fmt.Println是我们常用的一个函数,但是你是否注意到它可以接受任意类型的数据。打开fmt的源码文件,你会看到这样一个定义:
type Stringer interface {
String() string
}
也就是说,任何实现了String方法的类型都能作为参数被fmt.Println调用,让我们来试一试
package main
import (
"fmt"
"strconv"
)
type Human struct {
name string
age int
phone string
}
// 通过这个方法 Human 实现了 fmt.Stringer
func (h Human) String() string {
return "❰"+h.name+" - "+strconv.Itoa(h.age)+" years - ✆ " +h.phone+"❱"
}
func main() {
Bob := Human{"Bob", 39, "000-7777-XXX"}
fmt.Println("This Human is : ", Bob)
}
现在我们再回顾一下前面的Box示例,你会发现Color结构也定义了一个method:String。其实这也是实现了fmt.Stringer这个interface,即如果需要某个类型能被fmt包以特殊的格式输出,你就必须实现Stringer这个接口。如果没有实现这个接口,fmt将以默认的方式输出。
//实现同样的功能
fmt.Println("The biggest one is", boxes.BiggestsColor().String())
fmt.Println("The biggest one is", boxes.BiggestsColor())
注:实现了error接口的对象(即实现了Error() string的对象),使用fmt输出时,会调用Error()方法,因此不必再定义String()方法了。
interface变量存储的类型
我们知道interface的变量里面可以存储任意类型的数值(该类型实现了interface)。那么我们怎么反向知道这个变量里面实际保存了的是哪个类型的对象呢?目前常用的有两种方法:
-
Comma-ok断言
Go语言里面有一个语法,可以直接判断是否是该类型的变量: value, ok = element.(T),这里value就是变量的值,ok是一个bool类型,element是interface变量,T是断言的类型。
如果element里面确实存储了T类型的数值,那么ok返回true,否则返回false。
让我们通过一个例子来更加深入的理解。
package main
import (
"fmt"
"strconv"
)
type Element interface{}
type List [] Element
type Person struct {
name string
age int
}
//定义了String方法,实现了fmt.Stringer
func (p Person) String() string {
return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)"
}
func main() {
list := make(List, 3)
list[0] = 1 // an int
list[1] = "Hello" // a string
list[2] = Person{"Dennis", 70}
for index, element := range list {
if value, ok := element.(int); ok {
fmt.Printf("list[%d] is an int and its value is %d\n", index, value)
} else if value, ok := element.(string); ok {
fmt.Printf("list[%d] is a string and its value is %s\n", index, value)
} else if value, ok := element.(Person); ok {
fmt.Printf("list[%d] is a Person and its value is %s\n", index, value)
} else {
fmt.Printf("list[%d] is of a different type\n", index)
}
}
}
是不是很简单啊,同时你是否注意到了多个if里面,还记得我前面介绍流程时讲过,if里面允许初始化变量。
也许你注意到了,我们断言的类型越多,那么if else也就越多,所以才引出了下面要介绍的switch。
-
switch测试
最好的讲解就是代码例子,现在让我们重写上面的这个实现
package main
import (
"fmt"
"strconv"
)
type Element interface{}
type List [] Element
type Person struct {
name string
age int
}
//打印
func (p Person) String() string {
return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)"
}
func main() {
list := make(List, 3)
list[0] = 1 //an int
list[1] = "Hello" //a string
list[2] = Person{"Dennis", 70}
for index, element := range list{
switch value := element.(type) {
case int:
fmt.Printf("list[%d] is an int and its value is %d\n", index, value)
case string:
fmt.Printf("list[%d] is a string and its value is %s\n", index, value)
case Person:
fmt.Printf("list[%d] is a Person and its value is %s\n", index, value)
default:
fmt.Println("list[%d] is of a different type", index)
}
}
}
这里有一点需要强调的是:`element.(type)`语法不能在switch外的任何逻辑里面使用,如果你要在switch外面判断一个类型就使用`comma-ok`。
嵌入interface
Go里面真正吸引人的是它内置的逻辑语法,就像我们在学习Struct时学习的匿名字段,多么的优雅啊,那么相同的逻辑引入到interface里面,那不是更加完美了。如果一个interface1作为interface2的一个嵌入字段,那么interface2隐式的包含了interface1里面的method。
我们可以看到源码包container/heap里面有这样的一个定义
type Interface interface {
sort.Interface //嵌入字段sort.Interface
Push(x interface{}) //a Push method to push elements into the heap
Pop() interface{} //a Pop elements that pops elements from the heap
}
我们看到sort.Interface其实就是嵌入字段,把sort.Interface的所有method给隐式的包含进来了。也就是下面三个方法:
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less returns whether the element with index i should sort
// before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
另一个例子就是io包下面的 io.ReadWriter ,它包含了io包下面的Reader和Writer两个interface:
// io.ReadWriter
type ReadWriter interface {
Reader
Writer
}
反射
Go语言实现了反射,所谓反射就是能检查程序在运行时的状态。我们一般用到的包是reflect包。如何运用reflect包,官方的这篇文章详细的讲解了reflect包的实现原理,laws of reflection
使用reflect一般分成三步,下面简要的讲解一下:要去反射是一个类型的值(这些值都实现了空interface),首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数)。这两种获取方式如下:
t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素
v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值
转化为reflect对象之后我们就可以进行一些操作了,也就是将reflect对象转化成相应的值,例如
tag := t.Elem().Field(0).Tag //获取定义在struct里面的标签
name := v.Elem().Field(0).String() //获取存储在第一个字段里面的值
获取反射值能返回相应的类型和数值
var x float64 = 3.4
v := reflect.ValueOf(x)
fmt.Println("type:", v.Type())
fmt.Println("kind is float64:", v.Kind() == reflect.Float64)
fmt.Println("value:", v.Float())
最后,反射的话,那么反射的字段必须是可修改的,我们前面学习过传值和传引用,这个里面也是一样的道理。反射的字段必须是可读写的意思是,如果下面这样写,那么会发生错误
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(7.1)
如果要修改相应的值,必须这样写
var x float64 = 3.4
p := reflect.ValueOf(&x)
v := p.Elem()
v.SetFloat(7.1)
9. 并发
有人把Go比作21世纪的C语言,第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持了并行。
goroutine
goroutine是Go并行设计的核心。goroutine说到底其实就是协程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
goroutine是通过Go的runtime管理的一个线程管理器。goroutine通过go关键字实现了,其实就是一个普通的函数。
go hello(a, b, c)
通过关键字go就启动了一个goroutine。我们来看一个例子
package main
import (
"fmt"
"runtime"
)
func say(s string) {
for i := 0; i < 5; i++ {
runtime.Gosched()
fmt.Println(s)
}
}
func main() {
go say("world") //开一个新的Goroutines执行
say("hello") //当前Goroutines执行
}
// 以上程序执行后将输出:
// hello
// world
// hello
// world
// hello
// world
// hello
// world
// hello
我们可以看到go关键字很方便的就实现了并发编程。 上面的多个goroutine运行在同一个进程里面,共享内存数据,不过设计上我们要遵循:不要通过共享来通信,而要通过通信来共享。
runtime.Gosched()表示让CPU把时间片让给别人,下次某个时候继续恢复执行该goroutine。
默认情况下,在Go 1.5将标识并发系统线程个数的runtime.GOMAXPROCS的初始值由1改为了运行环境的CPU核数。
但在Go 1.5以前调度器仅使用单线程,也就是说只实现了并发。想要发挥多核处理器的并行,需要在我们的程序中显式调用 runtime.GOMAXPROCS(n) 告诉调度器同时使用多个线程。GOMAXPROCS 设置了同时运行逻辑代码的系统线程的最大数量,并返回之前的设置。如果n < 1,不会改变当前设置。
channels
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。那么goroutine之间如何进行数据的通信呢,Go提供了一个很好的通信机制channel。channel可以与Unix shell 中的双向管道做类比:可以通过它发送或者接收值。这些值只能是特定的类型:channel类型。定义一个channel时,也需要定义发送到channel的值的类型。注意,必须使用make 创建channel:
ci := make(chan int)
cs := make(chan string)
cf := make(chan interface{})
channel通过操作符<-来接收和发送数据
ch <- v // 发送v到channel ch.
v := <-ch // 从ch中接收数据,并赋值给v
我们把这些应用到我们的例子中来:
package main
import "fmt"
func sum(a []int, c chan int) {
total := 0
for _, v := range a {
total += v
}
c <- total // send total to c
}
func main() {
a := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(a[:len(a)/2], c)
go sum(a[len(a)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x + y)
}
默认情况下,channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得Goroutines同步变的更加的简单,而不需要显式的lock。所谓阻塞,也就是如果读取(value := <-ch)它将会被阻塞,直到有数据接收。其次,任何发送(ch<-5)将会被阻塞,直到数据被读出。无缓冲channel是在多个goroutine之间同步很棒的工具。
Buffered Channels
上面我们介绍了默认的非缓存类型的channel,不过Go也允许指定channel的缓冲大小,很简单,就是channel可以存储多少元素。ch:= make(chan bool, 4),创建了可以存储4个元素的bool 型channel。在这个channel 中,前4个元素可以无阻塞的写入。当写入第5个元素时,代码将会阻塞,直到其他goroutine从channel 中读取一些元素,腾出空间。
ch := make(chan type, value)
当 value = 0 时,channel 是无缓冲阻塞读写的,当value > 0 时,channel 有缓冲、是非阻塞的,直到写满 value 个元素才阻塞写入。
我们看一下下面这个例子,你可以在自己本机测试一下,修改相应的value值
package main
import "fmt"
func main() {
c := make(chan int, 2)//修改2为1就报错,修改2为3可以正常运行
c <- 1
c <- 2
fmt.Println(<-c)
fmt.Println(<-c)
}
//修改为1报如下的错误:
//fatal error: all goroutines are asleep - deadlock!
Range和Close
上面这个例子中,我们需要读取两次c,这样不是很方便,Go考虑到了这一点,所以也可以通过range,像操作slice或者map一样操作缓存类型的channel,请看下面的例子
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 1, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x + y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
for i := range c能够不断的读取channel里面的数据,直到该channel被显式的关闭。上面代码我们看到可以显式的关闭channel,生产者通过内置函数close关闭channel。关闭channel之后就无法再发送任何数据了,在消费方可以通过语法v, ok := <-ch测试channel是否被关闭。如果ok返回false,那么说明channel已经没有任何数据并且已经被关闭。
记住应该在生产者的地方关闭channel,而不是消费的地方去关闭它,这样容易引起panic
另外记住一点的就是channel不像文件之类的,不需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的
Select
我们上面介绍的都是只有一个channel的情况,那么如果存在多个channel的时候,我们该如何操作呢,Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
select默认是阻塞的,只有当监听的channel中有发送或接收可以进行时才会运行,当多个channel都准备好的时候,select是随机的选择一个执行的。
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
x, y = y, x + y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
在select里面还有default语法,select其实就是类似switch的功能,default就是当监听的channel都没有准备好的时候,默认执行的(select不再阻塞等待channel)。
select {
case i := <-c:
// use i
default:
// 当c阻塞的时候执行这里
}
超时
有时候会出现goroutine阻塞的情况,那么我们如何避免整个程序进入阻塞的情况呢?我们可以利用select来设置超时,通过如下的方式实现:
func main() {
c := make(chan int)
o := make(chan bool)
go func() {
for {
select {
case v := <- c:
println(v)
case <- time.After(5 * time.Second):
println("timeout")
o <- true
break
}
}
}()
<- o
}
runtime goroutine
runtime包中有几个处理goroutine的函数:
-
Goexit
退出当前执行的goroutine,但是defer函数还会继续调用
-
Gosched
让出当前goroutine的执行权限,调度器安排其他等待的任务运行,并在下次某个时候从该位置恢复执行。
-
NumCPU
返回 CPU 核数量
-
NumGoroutine
返回正在执行和排队的任务总数
-
GOMAXPROCS
用来设置可以并行计算的CPU核数的最大值,并返回之前的值。