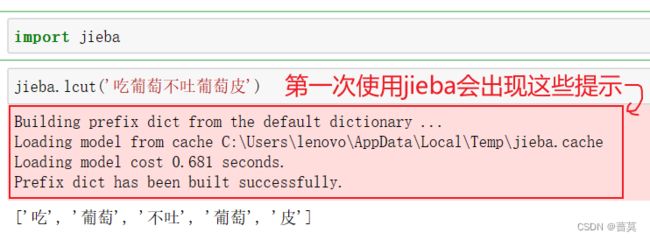
- 系统学习Python——并发模型和异步编程:进程、线程和GIL
分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种
- Flask框架入门:快速搭建轻量级Python网页应用
「已注销」
python-AIpython基础网站网络pythonflask后端
转载:Flask框架入门:快速搭建轻量级Python网页应用1.Flask基础Flask是一个使用Python编写的轻量级Web应用框架。它的设计目标是让Web开发变得快速简单,同时保持应用的灵活性。Flask依赖于两个外部库:Werkzeug和Jinja2,Werkzeug作为WSGI工具包处理Web服务的底层细节,Jinja2作为模板引擎渲染模板。安装Flask非常简单,可以使用pip安装命令
- Python Flask 框架入门:快速搭建 Web 应用的秘诀
Python编程之道
Python人工智能与大数据Python编程之道pythonflask前端ai
PythonFlask框架入门:快速搭建Web应用的秘诀关键词Flask、微框架、路由系统、Jinja2模板、请求处理、WSGI、Web开发摘要想快速用Python搭建一个灵活的Web应用?Flask作为“微框架”代表,凭借轻量、可扩展的特性,成为初学者和小型项目的首选。本文将从Flask的核心概念出发,结合生活化比喻、代码示例和实战案例,带你一步步掌握:如何用Flask搭建第一个Web应用?路由
- python_虚拟环境
阿_焦
python
第一、配置虚拟环境:virtualenv(1)pipvirtualenv>安装虚拟环境包(2)pipinstallvirtualenvwrapper-win>安装虚拟环境依赖包(3)c盘创建虚拟目录>C:\virtualenv>配置环境变量【了解一下】:(1)如何使用virtualenv创建虚拟环境a、cd到C:\virtualenv目录下:b、mkvirtualenvname>创建虚拟环境nam
- Python爱心光波
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
- Python流星雨
Want595
python开发语言
文章目录系列文章写在前面技术需求完整代码代码分析1.模块导入2.画布设置3.画笔设置4.颜色列表5.流星类(Star)6.流星对象创建7.主循环8.流星运动逻辑9.视觉效果10.总结写在后面系列文章序号直达链接表白系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python
- Python之七彩花朵代码实现
PlutoZuo
Pythonpython开发语言
Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl
- Python 脚本最佳实践2025版
前文可以直接把这篇文章喂给AI,可以放到AI角色设定里,也可以直接作为提示词.这样,你只管提需求,写脚本就让AI来.概述追求简洁和清晰:脚本应简单明了。使用函数(functions)、常量(constants)和适当的导入(import)实践来有逻辑地组织你的Python脚本。使用枚举(enumerations)和数据类(dataclasses)等数据结构高效管理脚本状态。通过命令行参数增强交互性
- (Python基础篇)了解和使用分支结构
EternityArt
基础篇python
目录一、引言二、Python分支结构的类型与语法(一)if语句(单分支)(二)if-else语句(双分支)(三)if-elif-else语句(多分支)三、分支结构的应用场景(一)提示用户输入用户名,然后再提示输入密码,如果用户名是“admin”并且密码是“88888”则提示正确,否则,如果用户名不是admin还提示用户用户名不存在,(二)提示用户输入用户名,然后再提示输入密码,如果用户名是“adm
- (Python基础篇)循环结构
EternityArt
基础篇python
一、什么是Python循环结构?循环结构是编程中重复执行代码块的机制。在Python中,循环允许你:1.迭代处理数据:遍历列表、字典、文件内容等。2.自动化重复任务:如批量处理数据、生成序列等。3.控制执行流程:根据条件决定是否继续或终止循环。二、为什么需要循环结构?假设你需要打印1到100的所有偶数:没有循环:需手动编写100行print()语句。print(0)print(2)print(4)
- (Python基础篇)字典的操作
EternityArt
基础篇python开发语言
一、引言在Python编程中,字典(Dictionary)是一种极具灵活性的数据结构,它通过“键-值对”(key-valuepair)的形式存储数据,如同现实生活中的字典——通过“词语(键)”快速查找“释义(值)”。相较于列表和元组的有序索引访问,字典的优势在于基于键的快速查找,这使得它在处理需要频繁通过唯一标识获取数据的场景中极为高效。掌握字典的操作,能让我们更高效地组织和管理复杂数据,是Pyt
- Python七彩花朵
Want595
python开发语言
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
- 用OpenCV标定相机内参应用示例(C++和Python)
下面是一个完整的使用OpenCV进行相机内参标定(CameraCalibration)的示例,包括C++和Python两个版本,基于棋盘格图案标定。一、目标:相机标定通过拍摄多张带有棋盘格图案的图像,估计相机的内参:相机矩阵(内参)K畸变系数distCoeffs可选外参(R,T)标定精度指标(如重投影误差)二、棋盘格参数设置(根据自己的棋盘格设置):棋盘格角点数:9x6(内角点,9列×6行);每个
- Anaconda 详细下载与安装教程
Anaconda详细下载与安装教程1.简介Anaconda是一个用于科学计算的开源发行版,包含了Python和R的众多常用库。它还包括了conda包管理器,可以方便地安装、更新和管理各种软件包。2.下载Anaconda2.1访问官方网站首先,打开浏览器,访问Anaconda官方网站。2.2选择适合的版本在页面中,你会看到两个主要的下载选项:AnacondaIndividualEdition:适用于
- python中 @注解 及内置注解 的使用方法总结以及完整示例
慧一居士
Pythonpython
在Python中,装饰器(Decorator)使用@符号实现,是一种修改函数/类行为的语法糖。它本质上是一个高阶函数,接受目标函数作为参数并返回包装后的函数。Python也提供了多个内置装饰器,如@property、@staticmethod、@classmethod等。一、核心概念装饰器本质:@decorator等价于func=decorator(func)执行时机:在函数/类定义时立即执行装饰
- Python中的静态方法和类方法详解
在Python中,`@staticmethod`和`@classmethod`是两种装饰器,它们用于定义类中的方法,但是它们的行为和用途有所不同。###@staticmethod`@staticmethod`装饰器用于定义一个静态方法。静态方法不接收类或实例的引用作为第一个参数,因此它不能访问类的状态或实例的状态。静态方法可以看作是与类关联的普通函数,但它们可以通过类名直接调用。classMath
- Python中类静态方法:@classmethod/@staticmethod详解和实战示例
在Python中,类方法(@classmethod)和静态方法(@staticmethod)是类作用域下的两种特殊方法。它们使用装饰器定义,并且与实例方法(deffunc(self))的行为有所不同。1.三种方法的对比概览方法类型是否访问实例(self)是否访问类(cls)典型用途实例方法✅是❌否访问对象属性类方法@classmethod❌否✅是创建类的替代构造器,访问类变量等静态方法@stati
- Python多版本管理与pip升级全攻略:解决冲突与高效实践
码界奇点
Pythonpythonpip开发语言python3.11源代码管理虚拟现实依赖倒置原则
引言Python作为最流行的编程语言之一,其版本迭代速度与生态碎片化给开发者带来了巨大挑战。据统计,超过60%的Python开发者需要同时维护基于Python3.6+和Python2.7的项目。本文将系统解决以下核心痛点:如何安全地在同一台机器上管理多个Python版本pip依赖冲突的根治方案符合PEP标准的生产环境最佳实践第一部分:Python多版本管理核心方案1.1系统级多版本共存方案Wind
- 基于Python的健身数据分析工具的搭建流程day1
weixin_45677320
python开发语言数据挖掘爬虫
基于Python的健身数据分析工具的搭建流程分数据挖掘、数据存储和数据分析三个步骤。本文主要介绍利用Python实现健身数据分析工具的数据挖掘部分。第一步:加载库加载本文需要的库,如下代码所示。若库未安装,请按照python如何安装各种库(保姆级教程)_python安装库-CSDN博客https://blog.csdn.net/aobulaien001/article/details/133298
- seaborn又一个扩展heatmapz
qq_21478261
#Python可视化matplotlib
推荐阅读:Pythonmatplotlib保姆级教程嫌Matplotlib繁琐?试试Seaborn!
- NGS测序基础梳理01-文库构建(Library Preparation)
qq_21478261
#生物信息生物学
本文介绍Illumina测序平台文库构建(LibraryPreparation)步骤,文库结构。写作时间:2020.05。推荐阅读:10W字《Python可视化教程1.0》来了!一份由公众号「pythonic生物人」精心制作的PythonMatplotlib可视化系统教程,105页PDFhttps://mp.weixin.qq.com/s/QaSmucuVsS_DR-klfpE3-Q10W字《Rg
- Python 常用内置函数详解(七):dir()函数——获取当前本地作用域中的名称列表或对象的有效属性列表
目录一、功能二、语法和示例一、功能dir()函数获取当前本地作用域中的名称列表或对象的有效属性列表。二、语法和示例dir()函数有两种形式,如果没有实参,则返回当前本地作用域中的名称列表。如果有实参,它会尝试返回该对象的有效属性列表。如果对象有一个名为__dir__()的方法,那么该方法将被调用,并且必须返回一个属性列表。dir()函数的语法格式如下:C:\Users\amoxiang>ipyth
- pythonjson中list操作_Python json.dumps 特殊数据类型的自定义序列化操作
场景描述:Python标准库中的json模块,集成了将数据序列化处理的功能;在使用json.dumps()方法序列化数据时候,如果目标数据中存在datetime数据类型,执行操作时,会抛出异常:TypeError:datetime.datetime(2016,12,10,11,04,21)isnotJSONserializable那么遇到json.dumps序列化不支持的数据类型,该怎么办!首先,
- Python 日期格式转json.dumps的解决方法
douyaoxin
pythonjson开发语言
classDateEncoder(json.JSONEncoder):defdefault(self,obj):ifisinstance(obj,datetime.datetime):returnobj.strftime('%Y-%m-%d%H:%M:%S')elifisinstance(obj,datetime.date):returnobj.strftime("%Y-%m-%d")json.d
- Python 爬虫实战:视频平台播放量实时监控(含反爬对抗与数据趋势预测)
西攻城狮北
python爬虫音视频
一、引言在数字内容蓬勃发展的当下,视频平台的播放量数据已成为内容创作者、营销人员以及行业分析师手中极为关键的情报资源。它不仅能够实时反映内容的受欢迎程度,更能在竞争分析、营销策略制定以及内容优化等方面发挥不可估量的作用。然而,视频平台为了保护自身数据和用户隐私,往往会设置一系列反爬虫机制,对数据爬取行为进行限制。这就向我们发起了挑战:如何巧妙地突破这些限制,同时精准地捕捉并预测播放量的动态变化趋势
- Python技能手册 - 模块module
金色牛神
Pythonpythonwindows开发语言
系列Python常用技能手册-基础语法Python常用技能手册-模块modulePython常用技能手册-包package目录module模块指什么typing数据类型int整数float浮点数str字符串bool布尔值TypeVar类型变量functools高阶函数工具functools.partial()函数偏置functools.lru_cache()函数缓存sorted排序列表排序元组排序
- Ubuntu基础(Python虚拟环境和Vue)
aaiier
ubuntupythonlinux
Python虚拟环境sudoaptinstallpython3python3-venv进入项目目录cdXXX创建虚拟环境python3-mvenvvenv激活虚拟环境sourcevenv/bin/activate退出虚拟环境deactivateVue安装Node.js和npm#安装Node.js和npm(Ubuntu默认仓库可能版本较旧,适合入门)sudoaptinstallnodejsnpm#验
- 苦练Python第9天:if-else分支九剑
python后端前端人工智能
苦练Python第9天:if-else分支九剑前言大家好,我是倔强青铜三。是一名热情的软件工程师,我热衷于分享和传播IT技术,致力于通过我的知识和技能推动技术交流与创新,欢迎关注我,微信公众号:倔强青铜三。欢迎点赞、收藏、关注,一键三连!!!欢迎来到100天Python挑战第9天!今天我们不练循环,改磨“分支剑法”——ifelse三式:单分支、双分支、多分支,以及嵌套和三元运算符,全部实战演练,让
- 苦练Python第8天:while 循环之妙用
python后端前端人工智能
苦练Python第8天:while循环之妙用原文链接:https://dev.to/therahul_gupta/day-9100-while-loops-with-real-world-examples-528f作者:RahulGupta译者:倔强青铜三前言大家好,我是倔强青铜三。是一名热情的软件工程师,我热衷于分享和传播IT技术,致力于通过我的知识和技能推动技术交流与创新,欢迎关注我,微信公众
- 苦练Python第5天:字符串从入门到格式化
python后端人工智能前端
苦练Python第5天:字符串从入门到格式化原文链接:https://dev.to/therahul_gupta/day-5100-working-with-strings-basics-to-formatting-2kkn作者:RahulGupta译者:倔强青铜三前言大家好,我是倔强青铜三。是一名热情的软件工程师,我热衷于分享和传播IT技术,致力于通过我的知识和技能推动技术交流与创新,欢迎关注我
- web报表工具FineReport常见的数据集报错错误代码和解释
老A不折腾
web报表finereport代码可视化工具
在使用finereport制作报表,若预览发生错误,很多朋友便手忙脚乱不知所措了,其实没什么,只要看懂报错代码和含义,可以很快的排除错误,这里我就分享一下finereport的数据集报错错误代码和解释,如果有说的不准确的地方,也请各位小伙伴纠正一下。
NS-war-remote=错误代码\:1117 压缩部署不支持远程设计
NS_LayerReport_MultiDs=错误代码
- Java的WeakReference与WeakHashMap
bylijinnan
java弱引用
首先看看 WeakReference
wiki 上 Weak reference 的一个例子:
public class ReferenceTest {
public static void main(String[] args) throws InterruptedException {
WeakReference r = new Wea
- Linux——(hostname)主机名与ip的映射
eksliang
linuxhostname
一、 什么是主机名
无论在局域网还是INTERNET上,每台主机都有一个IP地址,是为了区分此台主机和彼台主机,也就是说IP地址就是主机的门牌号。但IP地址不方便记忆,所以又有了域名。域名只是在公网(INtERNET)中存在,每个域名都对应一个IP地址,但一个IP地址可有对应多个域名。域名类型 linuxsir.org 这样的;
主机名是用于什么的呢?
答:在一个局域网中,每台机器都有一个主
- oracle 常用技巧
18289753290
oracle常用技巧 ①复制表结构和数据 create table temp_clientloginUser as select distinct userid from tbusrtloginlog ②仅复制数据 如果表结构一样 insert into mytable select * &nb
- 使用c3p0数据库连接池时出现com.mchange.v2.resourcepool.TimeoutException
酷的飞上天空
exception
有一个线上环境使用的是c3p0数据库,为外部提供接口服务。最近访问压力增大后台tomcat的日志里面频繁出现
com.mchange.v2.resourcepool.TimeoutException: A client timed out while waiting to acquire a resource from com.mchange.v2.resourcepool.BasicResou
- IT系统分析师如何学习大数据
蓝儿唯美
大数据
我是一名从事大数据项目的IT系统分析师。在深入这个项目前需要了解些什么呢?学习大数据的最佳方法就是先从了解信息系统是如何工作着手,尤其是数据库和基础设施。同样在开始前还需要了解大数据工具,如Cloudera、Hadoop、Spark、Hive、Pig、Flume、Sqoop与Mesos。系 统分析师需要明白如何组织、管理和保护数据。在市面上有几十款数据管理产品可以用于管理数据。你的大数据数据库可能
- spring学习——简介
a-john
spring
Spring是一个开源框架,是为了解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只能由EJB完成的事情。然而Spring的用途不仅限于服务器端的开发,从简单性,可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。其主要特征是依赖注入、AOP、持久化、事务、SpringMVC以及Acegi Security
为了降低Java开发的复杂性,
- 自定义颜色的xml文件
aijuans
xml
<?xml version="1.0" encoding="utf-8"?> <resources> <color name="white">#FFFFFF</color> <color name="black">#000000</color> &
- 运营到底是做什么的?
aoyouzi
运营到底是做什么的?
文章来源:夏叔叔(微信号:woshixiashushu),欢迎大家关注!很久没有动笔写点东西,近些日子,由于爱狗团产品上线,不断面试,经常会被问道一个问题。问:爱狗团的运营主要做什么?答:带着用户一起嗨。为什么是带着用户玩起来呢?究竟什么是运营?运营到底是做什么的?那么,我们先来回答一个更简单的问题——互联网公司对运营考核什么?以爱狗团为例,绝大部分的移动互联网公司,对运营部门的考核分为三块——用
- js面向对象类和对象
百合不是茶
js面向对象函数创建类和对象
接触js已经有几个月了,但是对js的面向对象的一些概念根本就是模糊的,js是一种面向对象的语言 但又不像java一样有class,js不是严格的面向对象语言 ,js在java web开发的地位和java不相上下 ,其中web的数据的反馈现在主流的使用json,json的语法和js的类和属性的创建相似
下面介绍一些js的类和对象的创建的技术
一:类和对
- web.xml之资源管理对象配置 resource-env-ref
bijian1013
javaweb.xmlservlet
resource-env-ref元素来指定对管理对象的servlet引用的声明,该对象与servlet环境中的资源相关联
<resource-env-ref>
<resource-env-ref-name>资源名</resource-env-ref-name>
<resource-env-ref-type>查找资源时返回的资源类
- Create a composite component with a custom namespace
sunjing
https://weblogs.java.net/blog/mriem/archive/2013/11/22/jsf-tip-45-create-composite-component-custom-namespace
When you developed a composite component the namespace you would be seeing would
- 【MongoDB学习笔记十二】Mongo副本集服务器角色之Arbiter
bit1129
mongodb
一、复本集为什么要加入Arbiter这个角色 回答这个问题,要从复本集的存活条件和Aribter服务器的特性两方面来说。 什么是Artiber? An arbiter does
not have a copy of data set and
cannot become a primary. Replica sets may have arbiters to add a
- Javascript开发笔记
白糖_
JavaScript
获取iframe内的元素
通常我们使用window.frames["frameId"].document.getElementById("divId").innerHTML这样的形式来获取iframe内的元素,这种写法在IE、safari、chrome下都是通过的,唯独在fireforx下不通过。其实jquery的contents方法提供了对if
- Web浏览器Chrome打开一段时间后,运行alert无效
bozch
Webchormealert无效
今天在开发的时候,突然间发现alert在chrome浏览器就没法弹出了,很是怪异。
试了试其他浏览器,发现都是没有问题的。
开始想以为是chorme浏览器有啥机制导致的,就开始尝试各种代码让alert出来。尝试结果是仍然没有显示出来。
这样开发的结果,如果客户在使用的时候没有提示,那会带来致命的体验。哎,没啥办法了 就关闭浏览器重启。
结果就好了,这也太怪异了。难道是cho
- 编程之美-高效地安排会议 图着色问题 贪心算法
bylijinnan
编程之美
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
public class GraphColoringProblem {
/**编程之美 高效地安排会议 图着色问题 贪心算法
* 假设要用很多个教室对一组
- 机器学习相关概念和开发工具
chenbowen00
算法matlab机器学习
基本概念:
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
开发工具
M
- [宇宙经济学]关于在太空建立永久定居点的可能性
comsci
经济
大家都知道,地球上的房地产都比较昂贵,而且土地证经常会因为新的政府的意志而变幻文本格式........
所以,在地球议会尚不具有在太空行使法律和权力的力量之前,我们外太阳系统的友好联盟可以考虑在地月系的某些引力平衡点上面,修建规模较大的定居点
- oracle 11g database control 证书错误
daizj
oracle证书错误oracle 11G 安装
oracle 11g database control 证书错误
win7 安装完oracle11后打开 Database control 后,会打开em管理页面,提示证书错误,点“继续浏览此网站”,还是会继续停留在证书错误页面
解决办法:
是 KB2661254 这个更新补丁引起的,它限制了 RSA 密钥位长度少于 1024 位的证书的使用。具体可以看微软官方公告:
- Java I/O之用FilenameFilter实现根据文件扩展名删除文件
游其是你
FilenameFilter
在Java中,你可以通过实现FilenameFilter类并重写accept(File dir, String name) 方法实现文件过滤功能。
在这个例子中,我们向你展示在“c:\\folder”路径下列出所有“.txt”格式的文件并删除。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
- C语言数组的简单以及一维数组的简单排序算法示例,二维数组简单示例
dcj3sjt126com
carray
# include <stdio.h>
int main(void)
{
int a[5] = {1, 2, 3, 4, 5};
//a 是数组的名字 5是表示数组元素的个数,并且这五个元素分别用a[0], a[1]...a[4]
int i;
for (i=0; i<5; ++i)
printf("%d\n",
- PRIMARY, INDEX, UNIQUE 这3种是一类 PRIMARY 主键。 就是 唯一 且 不能为空。 INDEX 索引,普通的 UNIQUE 唯一索引
dcj3sjt126com
primary
PRIMARY, INDEX, UNIQUE 这3种是一类PRIMARY 主键。 就是 唯一 且 不能为空。INDEX 索引,普通的UNIQUE 唯一索引。 不允许有重复。FULLTEXT 是全文索引,用于在一篇文章中,检索文本信息的。举个例子来说,比如你在为某商场做一个会员卡的系统。这个系统有一个会员表有下列字段:会员编号 INT会员姓名
- java集合辅助类 Collections、Arrays
shuizhaosi888
CollectionsArraysHashCode
Arrays、Collections
1 )数组集合之间转换
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
a)Arrays.asL
- Spring Security(10)——退出登录logout
234390216
logoutSpring Security退出登录logout-urlLogoutFilter
要实现退出登录的功能我们需要在http元素下定义logout元素,这样Spring Security将自动为我们添加用于处理退出登录的过滤器LogoutFilter到FilterChain。当我们指定了http元素的auto-config属性为true时logout定义是会自动配置的,此时我们默认退出登录的URL为“/j_spring_secu
- 透过源码学前端 之 Backbone 三 Model
逐行分析JS源代码
backbone源码分析js学习
Backbone 分析第三部分 Model
概述: Model 提供了数据存储,将数据以JSON的形式保存在 Model的 attributes里,
但重点功能在于其提供了一套功能强大,使用简单的存、取、删、改数据方法,并在不同的操作里加了相应的监听事件,
如每次修改添加里都会触发 change,这在据模型变动来修改视图时很常用,并且与collection建立了关联。
- SpringMVC源码总结(七)mvc:annotation-driven中的HttpMessageConverter
乒乓狂魔
springMVC
这一篇文章主要介绍下HttpMessageConverter整个注册过程包含自定义的HttpMessageConverter,然后对一些HttpMessageConverter进行具体介绍。
HttpMessageConverter接口介绍:
public interface HttpMessageConverter<T> {
/**
* Indicate
- 分布式基础知识和算法理论
bluky999
算法zookeeper分布式一致性哈希paxos
分布式基础知识和算法理论
BY
[email protected]
本文永久链接:http://nodex.iteye.com/blog/2103218
在大数据的背景下,不管是做存储,做搜索,做数据分析,或者做产品或服务本身,面向互联网和移动互联网用户,已经不可避免地要面对分布式环境。笔者在此收录一些分布式相关的基础知识和算法理论介绍,在完善自我知识体系的同
- Android Studio的.gitignore以及gitignore无效的解决
bell0901
androidgitignore
github上.gitignore模板合集,里面有各种.gitignore : https://github.com/github/gitignore
自己用的Android Studio下项目的.gitignore文件,对github上的android.gitignore添加了
# OSX files //mac os下 .DS_Store
- 成为高级程序员的10个步骤
tomcat_oracle
编程
What
软件工程师的职业生涯要历经以下几个阶段:初级、中级,最后才是高级。这篇文章主要是讲如何通过 10 个步骤助你成为一名高级软件工程师。
Why
得到更多的报酬!因为你的薪水会随着你水平的提高而增加
提升你的职业生涯。成为了高级软件工程师之后,就可以朝着架构师、团队负责人、CTO 等职位前进
历经更大的挑战。随着你的成长,各种影响力也会提高。
- mongdb在linux下的安装
xtuhcy
mongodblinux
一、查询linux版本号:
lsb_release -a
LSB Version: :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch:printing-4.0-amd64:printing-4.0-noa