Linux(阿里云)安装Hadoop(详细教程+避坑)
Linux(阿里云)安装Hadoop(详细教程+避坑)
一:安装JDK
1.执行以下命令,下载JDK1.8安装包。
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2.执行以下命令,解压下载的JDK1.8安装包。
tar -zxvf jdk-8u151-linux-x64.tar.gz
3.移动并重命名JDK包。
mv jdk1.8.0_151/ /usr/java8
4.配置Java环境变量。
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
5.查看Java是否成功安装。
java -version
二:安装Hadoop
注:下载Hadoop安装包可以选择华为源(速度中等,可以接受,重点是版本全)、清华源(3.0.0以上版本下载速度太慢,版本也少)、北京外国语大学源(下载速度特快,但是版本比较少)——本人亲测
1. 执行以下命令,下载Hadoop安装包。
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. 执行以下命令,解压Hadoop安装包至/opt/hadoop。
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/
mv /opt/hadoop-3.1.3 /opt/hadoop
3. 执行以下命令,配置Hadoop环境变量。
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
4. 执行以下命令,修改配置文件yarn-env.sh和hadoop-env.sh。
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. 执行以下命令,测试Hadoop是否安装成功。
hadoop version
如果返回版本信息,则表示安装成功。
三:配置Hadoop
1. 修改Hadoop配置文件 core-site.xml。
a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/core-site.xml
b. 输入i进入编辑模式。
c. 在
hadoop.tmp.dir</name>
file:/opt/hadoop/tmp</value>
location to store temporary files</description>
</property>
fs.defaultFS</name>
hdfs://localhost:9000</value>
</property>
d. 按Esc键退出编辑模式,输入:wq保存退出。
2. 修改Hadoop配置文件 hdfs-site.xml。
a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. 输入i进入编辑模式。
c. 在
dfs.replication</name>
1</value>
</property>
dfs.namenode.name.dir</name>
file:/opt/hadoop/tmp/dfs/name</value>
</property>
dfs.datanode.data.dir</name>
file:/opt/hadoop/tmp/dfs/data</value>
</property>
d. 按Esc键退出编辑模式,输入:wq保存退出。
四:配置SSH免密登录
1. 执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa
2. 执行以下命令,将公钥添加到authorized_keys文件中。
cd ~
cd .ssh
cat id_rsa.pub >> authorized_keys
若报错,执行下面操作后重新执行上面两句命令;若没有报错直接进入第五步:
参考两种解决ERROR: Attempting to operate on hdfs namenode as root的方法
输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
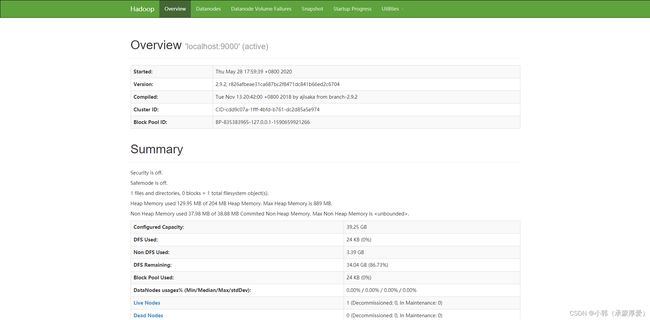
五:启动Hadoop
1. 执行以下命令,初始化namenode 。
hadoop namenode -format
2. 依次执行以下命令,启动Hadoop。
start-dfs.sh
若有选择Y/N的,选择Y;其他直接回车
start-yarn.sh
3. 启动成功后,执行以下命令,查看已成功启动的进程。
jps

正常会有6个进程;
若缺了DataNode进程,参考jps命令查看DataNode进程不见了(hadoop3.0亲测可用)
4. 打开浏览器访问http://