c++异步框架workflow分析
简述
workflow项目地址 : https://github.com/sogou/workflow
workflow是搜狗开源的一个开发框架。可以满足绝大多数日常服务器开发,性能优异,给上层业务提供了易于开发的接口,却只用了少量的代码,举重若轻,而且代码整洁干净易读。
搜狗官方宣传强调,workflow是一个异步任务调度编程范式,封装了6种异步资源:CPU计算、GPU计算、网络、磁盘I/O、定时器、计数器,以回调函数模式提供给用户使用,概括起来实际上主要是两个功能:1、屏蔽阻塞调用的影响,使阻塞调用的开发接口变为异步的,充分利用计算资源;2、框架管理线程池,使开发者迅速构建并行计算程序。
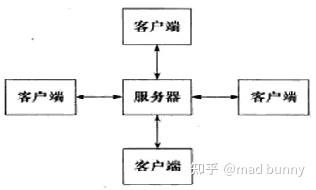
往往单台机器要服务于千千万万终端,我们最希望服务器资源都能充分利用,然而计算资源和I/O资源天然的效率不对等,使我们不得不采用一些其他技术手段实现基础资源充分利用。所谓I/O资源包括文件I/O和网络I/O,此外很多时候我们需要定时执行某段逻辑,同样不希望等待时间阻塞计算资源的使用。
所以框架最基础的功能,是要为上层开发人员屏蔽底层资源的不对称,使我们可以方便的开发业务逻辑而不需要把很多精力放在底层。
如何拟合计算资源和io资源
我们希望io等待或其他阻塞的时间,cpu还能充分利用,执行一些任务。这要求发起io的线程不能调用阻塞接口原地等待,而是要切出去,往往采用I/O多路复用或者异步I/O的方式,分别对应reactor模型和proactor模型
对于网络I/O,linux系统下缺乏对异步I/O的支持,即使近两年有了iouring,支持了异步io,但性能上相对epoll未必会有多少提升,而且一切都交给系统调度,可控性上大大降低;另外开发难度也更大。反观epoll,无论系统的支持还是相关设计模型都非常成熟了,所以近一二十年底层大都采用epoll,以reactor模式实现,reactor统一处理请求,将就绪的任务转给下游的处理器。根据业务不同,又有几种不同实现方式,有的就单线程之内调度,单线程循环处理(如redis),适合业务逻辑不复杂的场景;有的会单reactor处理请求,并通过消息队列把请求转发给下游多线程业务逻辑处理器处理;有的多线程多reactor处理请求,并通过消息队列将任务分发给下游handler,单reactor模式可以认为是这种模式的特例,workflow便以这种方式实现。
对于文件I/O,linux下有两种异步I/O的支持,posix aio(glibcaio)和linux 原生 aio,其中前者是一个通过多线程的异步,模拟的异步io,性能极差;linux 原生 aio是真正的aio,但是要求fd只能以O_DIRECT方式打开,所以只适用于文件I/O,workflow中支持了这种方式处理文件I/O。
对于定时器,常见的方式,有的通过epoll每次阻塞设置阻塞时间,用户态管理定时器(如redis);而epoll也支持时间事件,有的直接使用时间事件,workflow便采用这种方式。
提供给用户的接口
计算资源得以充分利用,还需要考虑给用户提供什么样的接口,让上层开发者能减少心智负担,比如,以协程的方式,让用户像开发串行程序一样开发异步程序,顺序的写逻辑;亦或者是提供让用户注册回调的方式开发异步程序。workflow中提出了子任务的概念,以任务的方式提供给用户。
子任务定义了一种管理回调的方式,用串行并行来组织子任务调度。用户可以把逻辑写在任务里,交给框架去调度。
把阻塞的任务交给epoll去异步调用,计算任务交给线程池去异步执行,以至于所有的任务都是异步调起的,这种设计思想,就是workflow被称为“异步任务调度框架”的原因。
代码分析
根据上面的分析,对一般服务器框架结构已经有了一个整体认识。下面按这个顺序,底层基础数据结构——》纯计算任务和Reactor层——》任务组织调度层——》用户接口层,分四个层次逐步分析一下workflow的实现。
基础数据结构
workflow使用到的基础数据结构:链表、红黑树、消息队列、线程池,workflow中这四个结构的设计都非常的精致。
链表(见文件 list.h)
workflow中的链表貌似引自linux内核,实现了一种非常非常灵活的链表,甚至链表串起的不同节点之间可以是不同的数据结构
一般来说一个普通的链表节点如下:
struct ListNode
{
ListNode * prev_ = nullptr;
ListNode * next_ = nullptr;
void * p_value_ = nullptr;
};定义节点时定义好数据段p_value_,这样的话数据结构的实现就会与业务逻辑结合在一起。
这里不使用模板也实现了预定义独立于业务逻辑的链表数据结构。
链表的节点:// 这是一个双链表
struct list_head {
list_head *next, *prev;
};可以把链表嵌入到任何一个数据结构中,
那如何通过链表节点拿到当前所在结构呢?
通过一个宏来实现:
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))简单解释下这个宏:ptr表示链表节点指针,type是当前节点数据结构类型名,member是链表节点在数据结构中的成员名
&((type *)0)->member)把指向地址空间起点的指针(空指针)转化成指向节点数据结构的指针,然后取链表节点成员名,再取地址,就可以取到链表节点在这个数据结构中的偏移量。
ptr是链表节点指针,按(char *)减去偏移量,就可以回退到结构起始位置。再把这个位置转化成(type *).就取到了指向当前数据结构的指针。
看接口甚至可以发现,当我想把当前数据结构从链表里删除的时候,甚至不需要拿到链表,而是直接通过list_del(list_head * current_node)函数传入当前节点就可以删除,灵活的一塌糊涂。
并且提供了遍历链表的接口宏:
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)每一行代码都极其简洁干净,妙到毫巅!
其他链表基础知识不多赘述。
红黑树(见rbtree.h/.c)
与链表类似,红黑树也使用了内核红黑树。
相同的风格,每个节点只有链接指针和节点颜色字段,而没有数据。
struct rb_node
{
struct rb_node *rb_parent;
struct rb_node *rb_right;
struct rb_node *rb_left;
char rb_color;
#define RB_RED 0
#define RB_BLACK 1
};当把红黑树node嵌入数据结构中之后,使用同样原理的宏,来获取节点所在结构的指针:
#define rb_entry(ptr, type, member) \ // 包含ptr的结构体指针
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))比较特别的是,由于节点不包含数据,数据结构不知道节点之间如何比较大小,所以需要用户自己定义查找、插入函数,但给出了例子。
消息队列(见msgqueue.h/.c)
这里实现了一个消息队列,也是正常的提供一个put接口,供生产者reactor生产数据插入消息,一个get接口,传递给下游handler消费,消息队列有消息上限,并提供阻塞和非阻塞两种模式,阻塞模式下,当消息超过上限生产线成阻塞,等待消息小于上限了再插入。通过条件变量使没有待处理的消息时,阻塞消费线程,于内核态等待消息出现。这里的生产者和消费者都是多线程的,所以需要考虑线程安全,消息队列的常见实现是一个数据存储段,一个锁,一个条件变量,而workflow中的消息队列的高妙之处就在于,他有两个锁,两个条件变量,两个数据空间,双倍快乐。
struct __msgqueue
{
size_t msg_max;
size_t msg_cnt;
int linkoff;
int nonblock;
void *head1;
void *head2;
void **get_head;
void **put_head;
void **put_tail;
pthread_mutex_t get_mutex;
pthread_mutex_t put_mutex;
pthread_cond_t get_cond;
pthread_cond_t put_cond;
};这里使用了一个小技巧,大幅提升消息队列性能,两个数据段一个专门用来get,一个专门用来put,两把锁两个条件变量,分别put时候和get时候使用。这样的好处就是get和put操作之间几乎互不干扰。put操作不会锁消费线程。get操作绝大多数情况下不会锁生产线程。
只有当get链表为空时,才会把put和get全锁住,对两个链表头进行交换,极大的减少了生产线程和消费线程之间争夺锁产生的相互影响。
这里还有一个点就是消息队列要求节点是自带链表字段的,并指定链接节点相对于结构头的偏移量(linkoff)。所以插进来的节点msg的结构是poller_result但是实际结构是poller_node强转过来的,再对比这两个结构体,发现前三个成员是一致的,而第四个成员就是链接节点。
struct poller_result
{
int state;
int error;
struct poller_data data;
};
struct __poller_node
{
int state;
int error;
struct poller_data data;
#pragma pack(1)
union
{
struct list_head list;
struct rb_node rb;
};
#pragma pack()
...
};相关视频推荐
一个撑起搜狗大部分后端服务的框架-workflow
c++ 异步框架 workflow 网络模块分析
搜狗C++后端服务框架workflow:如何高效处理海量异步任务
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

线程池(见thrdpool.h/.c)
线程池实现的功能往往是创建一系列工作线程,工作线程执行线程回调函数,从消息队列中取任务并执行,当消息队列中没有任务时,等待任务出现。
workflow中的线程池就是这样一个很标准的线程池,同时很灵活的让逻辑脱离于线程池,线程回调函数并非实际要执行的逻辑,而是从消息队列里get出的task,是一个包含了要执行的回调和上下文的task,线程回调函数执行了这个task。
struct thrdpool_task
{
void (*routine)(void *);
void *context;
};这样实现一个效果,就是可以运行时才动态决定要执行什么逻辑,即每个task可以是不同的任务,灵活度大大提升。
基础数据结构主要就这四种,这里只分析了其设计中比较可圈可点的部分,而没有仔细讲一些简单的基础细节。
纯计算任务和Reactor调度层
把阻塞的任务交给epoll去异步调用,计算任务交给线程池去异步执行,实现所有任务的异步调度,下面分别看看计算任务和reactor。
纯计算任务
WorkFlow由框架统一管理原始任务线程池,单例__ExecManager内有一个单的封装,优雅的实现对线程池的管理。
这一层有三个新概念:
ExecQueue是一个有锁链表队列;
ExecSession的execute()接口由派生出来的任务自己去定义需要执行的逻辑。
Executor类,创建并管理线程池,提供request()方法,request方法把对应任务放入到线程池去执行。request的参数有两个,分别是当前session和所在的ExecQueue,如果queue里面只有这一个session,则把这个session放入Executor管理的线程池里里执行,如果不是首个任务,则只要放入队列里就行了,线程routine会调度当前队列中所有的任务进入线程池执行,并用ExecQueue中的锁保持队列中任务调度的同步性。
Executor::executor_thread_routine是线程执行routine,一共做了两件事:
第一步会递归的调度所有当前Queue中的任务进线程池,并用ExecQueue中的锁保持队列中任务调度的同步性;
第二步是执行当前session,并由session自己保持数据同步。
Reactor:

这里主要涉及四个文件poller.h/.c mpoller.h/.c Communicator.h/.cc CommScheduler.h/.cc
其中poller是对epoll的封装,mpoller又集成多个poller线程;Communicator顾名思义,就是通信器,封装了mpoller和线程池;CommScheduler是对Communicator的封装,全局唯一,最后创建在__CommManager中,通过WFGlobal暴露出来。
这一层主要完成了右图所示的工作,poller线程把epoll事件做初加工处理,生成一个poller_result,设置需要handle的类型,然后把处理结果put()进消息队列,给工作线程去处理。handler线程等待任务,当队列里有任务时,根据任务的operation类型做相应处理。
poller
poller.h/.c提供了poller的创建、启动、stop、poller_add、poller_del、poller_mod和add_timer的接口。
poller_create创建了poller数据结构,分配了poller_node的指针数组nodes,这里的nodes是一个以fd为下标的数组,这时候只有一个指针数组,node还没有创建,node是在poller_add的时候创建的,创建node的时候会检查监听的操作是否需要result,需要的话同时分配result空间。但这时候poller线程还没有跑起来,执行poller_start时将poller线程跑起来;poller_add、poller_del、poller_mod分别是epoll的增加节点、删除节点、改变监听事件 三种操作的简单封装;add_timer增加时间事件,
前面说过消息队列里面装的是poller_result(poller_node),poller_result里面都会有一个poller_data。
#define PD_OP_READ 1
#define PD_OP_WRITE 2
#define PD_OP_LISTEN 3
#define PD_OP_CONNECT 4
#define PD_OP_SSL_READ PD_OP_READ
#define PD_OP_SSL_WRITE PD_OP_WRITE
#define PD_OP_SSL_ACCEPT 5
#define PD_OP_SSL_CONNECT 6
#define PD_OP_SSL_SHUTDOWN 7
#define PD_OP_EVENT 8
#define PD_OP_NOTIFY 9
#define PD_OP_TIMER 10
struct poller_data
{
short operation;
unsigned short iovcnt;
int fd;
union
{
SSL *ssl;
void *(*accept)(const struct sockaddr *, socklen_t, int, void *);
void *(*event)(void *);
void *(*notify)(void *, void *);
};
void *context;//CommService或CommConnEntry
union
{
poller_message_t *message;
struct iovec *write_iov;
void *result;
};
};poller_data封装了需要处理的fd、对应的操作(operation)、上下文(可能是CommService或CommConnEntry)。
poller的核心是poller_thread,poller_start的时候启动了是一个poller_thread,poller_thread处理的是epoll_event,主流程是一个经典的双循环,外层循环epoll_wait,每次最多处理256个fd,epoll返回后,再根据每个epoll_event事件的类型,循环处理每个类型的事件,从枚举可以看到对当前node的操作有读、写、listen、connect、timer等等,不管是什么类型的epoll事件,poller_thread处理的结果会生成一个.poller_result,并把这个结果插入到消息队列中。
具体的操作非常的多了,不适合静态分析,后面再动态分析请求的全流程。
poller的操作都是线程安全的,mpoller启动多个线程的时候也可以直接使用。
mpoller
可以看到实际上使用的并不是poller而是mpoller,mpoller是对多线程poller的封装,一个mpoller包括至少一个poller,实际配几个线程就创建几个poller,并统一分配poller_node,所有poller共享poller_node数组。实际使用的时候可以根据运算核心数和业务逻辑的复杂程度调整poller_thread和handler_thread的配比。mpoller的add、del、mod接口会对传入的fd对线程数求模,将fd均匀的分配到各个poller。
关于数据同步
可以看到对fd的[]操作并没有加锁,以mpoller_add为例
static inline int mpoller_add(const struct poller_data *data, int timeout,
mpoller_t *mpoller)
{
unsigned int index = (unsigned int)data->fd % mpoller->nthreads;
return poller_add(data, timeout, mpoller->poller[index]);
}第4行计算index,fd和nthreads都是不会发生变化,不会修改的,线程之间无冲突,所以不需要加锁。
第5行由poller_add来保证线程安全,每个poller中都有一个锁,poller_add、poller_del、poller_mod的操作都是加锁的,因为这三种操作都可能发生在不同的线程。
Communicator
Communicator是通讯器,是底层和业务层的枢纽,创建了mpoller和handler线程池,初始化时候启动两个线程池,bind的时候会把服务绑到communicator上,把服务创建的listen_fd放入到poller中开始监听。handler_thread就是在Communicator中启动的,handler_thread从消息队列里拿到的是poller_result,handler_thread做的是拿到任务以后根据poller_result::poller_data::operation类型做相应处理。
相关的结构有:
链接:
class WFConnection : public CommConnection 创建的链接
对端:
CommTarget通讯目标,封装了对端的地址、port、超时时间
消息:
struct __poller_message
{
int (*append)(const void *, size_t *, poller_message_t *);
char data[0]; // 柔性数组
};
class CommMessageIn : private __poller_message
{
private:
virtual int append(const void *buf, size_t *size) = 0;
struct CommConnEntry *entry;
};
class CommMessageOut
{
private:
virtual int encode(struct iovec vectors[], int max) = 0;
};很明显CommMessageIn是一次通信中的输入消息,CommMessageOut是返回的消息的基类,输入消息的基类是__poller_message,这里又使用了一个c程序员常用的小技巧,成员char data[0]是一个柔性数组,把__poller_message变成了一个变长结构体。
结构体中末尾成员是一个长度为0的char数组,这样声明看起来和char *data是一样的,但是这样写相对于char指针有一些优势。
对比如下结构,考虑__poller_message_test和__poller_message有什么区别
struct __poller_message_test
{
int (*append)(const void *, size_t *, poller_message_t *);
char *data; // char指针
};首先,数组长度是0,说明没分配空间。所以64位系统中,sizeof(struct __poller_message_test) == 16 而 sizeof(struct __poller_message) == 8。其次,如果使用一个char指针,需要为指针分配内存。而使用data[0]则不需要二次给指针分配内存,直接为结构分配适量大小内存即可,成员data会自动指向结构尾部的下一个字节。
输入消息有一个append的虚方法,子类自己去定义如何反序列化,输出消息有一个encode的虚方法,子类消息自己去定义序列化发送消息。基类__poller_message中的函数指针会被赋值为Communicator::append(const void *buf, size_t *size, poller_message_t *msg),实际运行时由函数指针append去调用各子类消息的virtual int append(const void *buf, size_t *size)对消息进行反序列化。
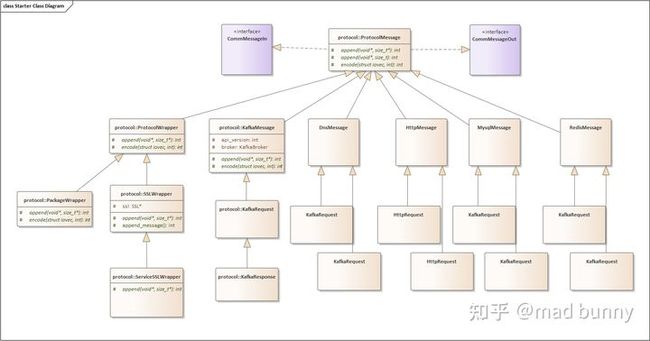
框架内已经定义好一些常用协议了:
会话:CommSession
CommSession封装了一次会话所有组成单位,包括输入/输出消息、CommConnection、CommTarget
定义了消息的生产方式
服务器:CommService
类图:

class WFServerBase : protected CommService 服务器的抽象。封装了服务器地址、监听套接字、活跃链接和连接数、服务器参数。
基类定义了newsession、newconnect接口。WFServerBase类中实现了服务启动start()、停止stop()、创建/删除链接newconnect()。
WFServer是一个模板类,模板参数是输入输出消息类型,可以实例化为各种类型的服务器,不同类型的服务器就是消息类型不同的服务器实例化,因为不同类型服务器实例消息类型不同,处理消息方式也不同,WFServer中保存了处理消息方式的回调——processer,并在服务创建的时候初始化。在WFServer中定义session创建方式new_session()的时候,会用processer来创建task,process实际上是task的处理方式。
服务Start()的时候会被bind()到全局的Communicator上,包括创建fd、bind、listen、放入epoll监听,成为epoll监听的第一个fd。服务实际上是交给Communicator创建的handler_thread线程池来驱动起来的。
Entry:CommConnEntry
打包了所有一次会话需要的上下文,包括poller、servide、session、target、socket等,处理accept事件(handle_listen_result)的时候由Communicator::accept_conn创建,创建后放在poller_data中,mpoller_add监听
Communicator:
有了上面这些基础结构,Communicator就是一个完全体了,Communicator初始化的时候,启动了poller_thread、handler_thread驱动服务进行消息处理。
以示例代码的hello_world程序为例,观察一次网络请求过程,看看poller_thread和handler_thread分别都做了什么。
从hello_world启服到线程工作:

这里特别看一下poller_add的时候创建了poller_node实体,poller_node中有一个成员struct __poller_node *res,__poller_data_get_event()的时候会返回一个bool值,表示是否需要创建res。可以看到操作类型为listen的情况。是需要res的。
经过这个过程,服务器就启动开始接受请求了,service创建listen_fd交由poller管理,当监听到有客户端链接时,accept+read。下面分析接收到一个请求时,poller_thread和handler_thread分别做了什么。
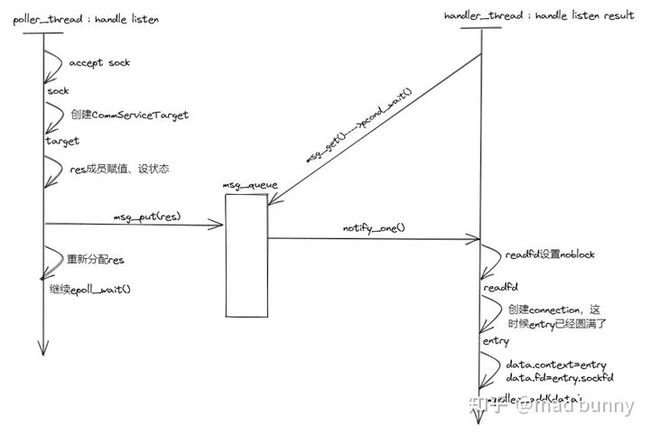
poller_thread知道listenfd可读,则accept一个readfd,创建了对端target,把这个poller_result(poller_node)放进消息队列。
handler_thread拿到这个poller_result之后,主要是创建了完整的CommConnEntry,并把负责read的poller_node放入epoll监听,等待内核缓冲区有数据可读。
这里有个细节,readfd是无阻塞模式,因为使用了epoll的边缘触发模式,即每个fd的状态变化只通知一次,这样的话需要把readfd上的数据全读完,所以readfd必须设置成无阻塞模式,否则循环读到最后肯定会被阻塞。
如果遇到errorno==EAGAIN则直接返回,因为对于fd阻塞调用eagain表示提示重试,对于非阻塞fd,errorno==EAGAIN则表示缓冲区已经写满,直接return本次处理结束。
readfd放入epoll之后,readfd上有数据到来后会被操作系统拷进内核缓冲区,然后epoll提示readfd可读。poller_thread会进入处理可读事件(handle_read)。
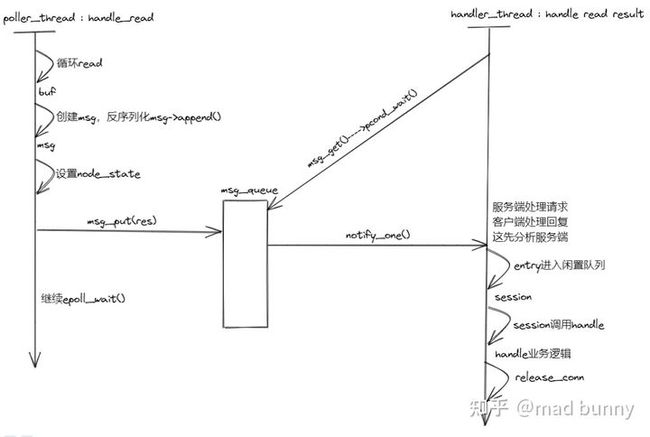
poller_thread对可读事件的处理主要是把字节流读出来,并反序列化,放入队列提供给handler_thread,handler_thread调service处理业务逻辑。
handler对收到的消息的处理分两种情况,如果是服务端,当做请求处理,如果是客户端,当回复处理,所以hello_world程序进入请求处理流程。
服务器对请求的处理是创建服务对应类型的CommRequest,helloworld中实际是执行了一个WFHttpServerTask。
继承关系:WFHttpServerTask——>WFServerTask——>WFNetworkTask——>CommRequest——>SubTask,CommSession。
SubTask和CommSession后面再仔细分析,这里先从字面理解,SubTask就是任务,就是处理自定义逻辑的过程,CommSession是会话。那handle的时候会先调用当前Task的processor.dispatch()执行任务,任务执行完自动subtask_done()的时候会调用scheduler->reply(),将结果返回 Send_message()。可以看到Send_message是先尝试同步写,如果同步写失败了,再尝试异步写,异步写的过程就是先把文件描述符加入epoll监听,等待可写信号出现后,再写入。写的时候使用iovec,聚集写尽量减少拷贝次数。
至此poller事件各种operation的处理,已经分析过PD_OP_READ、PD_OP_WRITE、PD_OP_LISTEN,再通过wget看一下PD_OP_CONNECT。
connect主要是处理客户端链接服务端时,服务端无法立刻建立链接时的等待,异步等待屏蔽等待时间。
request的时候会优先检查目标上有没有idle链接,如果有的话直接复用,如果没有会创建connect,conn_fd是非阻塞的,operation设置为PD_OP_CONNECT,放在epoll中管理,等待fd可用。

可以看到,是一个简单的发送请求,等待结果的过程。
poller事件共有10种operation,这里分析过读、写、connect、listen四种流程,PD_OP_SSL_ACCEPT、PD_OP_SSL_CONNECT、PD_OP_SSL_SHUTDOWN三个只是使用openssl库时的创建和关闭链接。还有另外两种事件:PD_OP_EVENT、PD_OP_NOTIFY,这两种分别是linux和mac环境下处理异步文件I/O用的。
异步文件I/O:
TODO
任务组织调度层
下面分析任务线程是如何执行任务的逻辑。这个层次有两个核心基础概念,一个是任务的抽象,一个是会话(session)的抽象,二者是所有执行逻辑的祖爷爷和祖奶奶。
任务:
前面看到对于请求的处理,实际是执行了CommRequest,CommRequest既是一个SubTask又是一个CommSession,最后是通过执行的是SubTask的接口dispatch()执行起来的,这里最重要的概念——子任务。workflow里面所有的逻辑,最后都是通过子任务执行起来的;子任务又可以通过各种组合关系,串并联的组织起来。
这里有四个重要的基本元素:
1,SubTask——子任务,是一切任务的祖先。
2、ParallelTask——并行任务,并行任务里面管理SubTask数组,启动时会把自己管理的SubTask一个一个全部dispatch一遍。
3、SeriesWork——串联工作组,里面管理了一个数组的子任务,逐个执行。
4、ParallelWork——并联工作组,里面管理了一个SeriesWork数组,其本身的祖先是一个SubTask,所以他可以被SeriesWork管理。
这样就实现了任务的串并联执行甚至以DAG的形式复合。
下面逐一分析:
SubTask:
class SubTask{
public:
virtual void dispatch() = 0;
private:
virtual SubTask *done() = 0;
protected:
void subtask_done();
private:
ParallelTask *parent;
SubTask **entry;
void *pointer;
};SubTask是一切执行任务的祖先,不同的任务实现,实现不同的dispatch()和done()接口,提供两个接口留给用户自定义:
1、dispatch()接口 就是执行任务,用户任务自定义执行逻辑,而在执行结束后,必须调用subtask_done()。
2、done()接口 在任务逻辑执行结束后,由subtask_done()调起done(),这个接口是用户自定义的结束回调,在done()接口里面回收资源,销毁任务。done()函数还会返回一个子任务的指针,当当前任务执行完还要执行下一个任务的时候,返回下一个任务,如果没有下一个任务,则返回nullptr。为什么这么约定呢?这需要看一下subtask_done()函数的工作方式。
需要知道成员变量的意思才能明白调度方式:
pointer 一般指向当前所在SeriesWork,SubWork最后也是放在SeriesWork之中启动起来的;
parent 当一个子任务被ParallelTask任务管理的时候,parent指向被管理的并行任务。
entry 指向待执行任务数组的首位。
subtask_done():仔细解读一下subtask_done()的工作方式:
void SubTask::subtask_done()
{
SubTask *cur = this;
ParallelTask *parent;
SubTask **entry;
while (1){
parent = cur->parent;
entry = cur->entry;
cur = cur->done();
if (cur){
cur->parent = parent;
cur->entry = entry;
if (parent)
*entry = cur;
cur->dispatch();
}
else if (parent) {
if (__sync_sub_and_fetch(&parent->nleft, 1) == 0) {
cur = parent;
continue;
}
}
break;
}
}可以看到先保存了当前任务的parent和entry,然后直接调用了当前任务的done()接口。如果又返回了一个子任务,则调用新任务的dispatch(),使其运行起来,dispatch()到最后必然又会调用新任务的subtask_done();从而递归执行这条线上所有任务,直至done()不会再返回任务;当不再返回任务时,说明parent的孩子都执行完,就可以继续再往上执行(parent也是一个SubTask),直至根任务执行完。
ParallelTask:
ParallelTask是SubTask的儿子,结构很简单,管理了一个SubTask数组,ParallelTask::dispatch()的时候会把数组内管理的所有SubTask逐一dispatch()一遍,这样的话就实现了同级任务的并列执行,特别注意并列执行不一定是并行,是否并行取决于调度。任务本身是顺序dispatch()的,如果dispatch调度的时候把任务放入线程池执行任务就是并行的。
SeriesWork:
SeriesWork是一个有锁的线程安全队列,队列中存储了需要按顺序执行的SubTask,预分配4个空间,如果入队时队列已满,则像vector一样拓展二倍空间。
SubTask都是放到SeriesWork中执行的。SeriesWork是怎么调度执行任务的?启动函数Start(),会从第一个SubTask开始dispatch(),可以看到多数任务Task的done()的实现都是返回return series->pop();意思就是当前任务执行完了,返回当前所在的SeriesWork中的下一个任务,继续执行,直至所有任务执行完。
注意SeriesWork本身不是一个SubTask,所以无法被SeriesWork管理。
ParallelWork:
ParallelWork稍微复杂一点

继承关系:ParallelWork——>ParallelTask——>SubTask
可见:1、ParallelWork是一个SubTask,所以可以被SeriesWork管理;2、ParallelWork同时也是一个ParallelTask,管理了一个数组的SubTask;3、ParallelWork管理了一个SeriesWork数组,这个数组的长度和SubTask数组的长度相同。并且让SubTask指向同索引SeriesWork的首个SubTask。
ParallelWork是怎样启动和调度任务的:
ParallelWork本身是一个SubTask,所以启动时把他放入一个SeriesWork,作为SeriesWork的firsttask被调起dispatch();然后ParallelWork本身是一个ParallelTask,dispatch的时候会把其下管理的所有的SubTask逐个启动dispatch();如图,SubTask指向的实际是管理的SeriesWork的first Task,所以实际上相当于启动了管理的所有SeriesWork。
这四个结构就是整个任务调度的基石,所有的逻辑都是作为任务执行起来的。并行任务管理串行任务,串行任务管理SubTask(并行任务也是SubTask),这套设定使任务可以自由复合DAG复合。
这时可以明白这个框架名字所谓WorkFlow,其核心就是组织任务的执行流,所有的执行逻辑都是任务。
会话(session):
想要执行的逻辑,通过成为SubTask可以启动起来,并按一定的顺序调度,那具体做的事,则被抽象为会话。
基础session有四种:CommSession、ExecSession、IOSession、SleepSession,分别代表网络操作、运算操作、I/O操作、睡眠操作,session都需要实现handle()接口,所有最后执行的任务都是这四种操作派生出来的。
SubTask这个大渣男分别和四种session结合生成了CommRequest、ExecRequest、SleepRequest、IORequest,使得所有的request都可以被作为子任务调度,都有state和error。
四种request分别派生出了WFNetWorkTask、WFThreadTask、WFTimerTask、WFFileTask。其中WFNetWorkTask和WFThreadTask都是两个参数的模板类。对通信任务来说,参数是请求消息和回复消息,对于计算任务来说参数是输入和输出,WFReduceTask、WFSortTask、WFMergeTask是不用参数的的实例化,WFHttpTask、WFRedisTask、WFMysqlTask、WFKafkaTask只不过是不同协议的WFNetWorkTask的实例化。
CommRequest派生了WFNetworkTask;ExecRequest派生了WFThreadTask,二者都加入了输入输出模板参数,和一些控制参数,提供了方便的启动多线程任务和网络任务的方式。更有WFMultiThreadTask任务,批量管理多线程任务。
这里还有一个WFTimerTask,实现了不占线程的定时功能.。
WFTimerTask:
WFTimerTask可以让任务休眠一定时长后执行,不占线程,达到时长之后返回执行回调,就是定时任务。
如果一个WFTimerTask被直接start(),则创建一个SeriesWork,并dispatch()起来,如果是串在其他的SeriesWork,当执行到这个task的时候直接dispatch()。
当SleepRequest被dispatch()时候,实际是调用当前scheduler(即communicator)的sleep(),实际是取出当前WFTimerTask的休眠时间,然后创建一个定时任务mpoller_add_timer交给epoll管理,等epoll提示时间到了,再切回来执行。
层次结构:
借用一张官图非常清楚的表达清楚任务之间的层次关系。
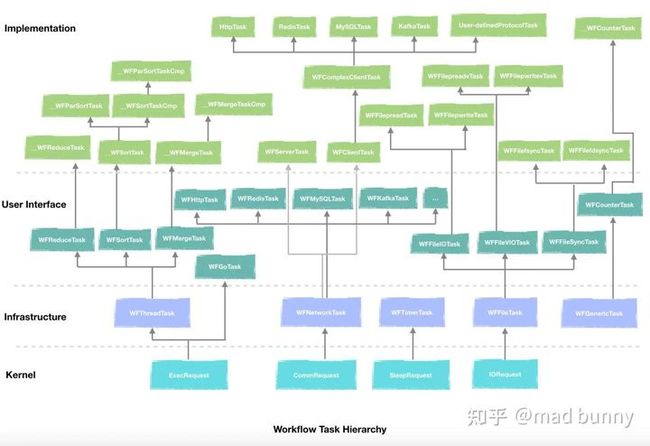
用户接口
至此,底层支持都分析过了,下面看看通过这些底层结构可以组织出什么花样。
其他Tasks
WFCounterTask:
CounterTask是一个计数器Task,任务里保存了一个原子的unsigned用来计数,初始化时候传入需要记的个数,每次任务被dispatch()的时候,计数器减一,直到计数器为0时,执行回调,配合一个阻塞信号量,可以实现一批并行任务的统一等待,如:WaitGroup。
可能是觉得手动创建CounterTask不够优雅,框架还创建了CounterTask管理器,用一个红黑树以名字为key统一管理CounterTask,可以通过名字全局操作CounterTask。
WaitGroup
既然说到了就顺便说一下WaitGroup。
WaitGroup实现了阻塞等待多个任务完成的效果。
WaitGroup由一个原子的等待个数,一个WFCounterTask和一个std::future组成。构造时创建一个std::promise,并绑定到future上;创建一个计数1的CounterTask并注册回调,回调中时给promise->setvalue()。
每次调用done会给剩余个数减一,当减完时,counter->done(),这时回调会告诉futrue,所有任务都完成了,阻塞结束。
WFGraphNode和WFGraphTask:
WFGraphTask实现了将任务迅速的组织成有向无环图的方法,一个WFGraphTask管理了一张由多个WFGraphNode组成。
WFGraphNode是一个WFCounterTask,并加入了一个WFGraphNode*列表:follower,follower表达了邻接关系,保存的就是依赖当前任务的下游节点。因为是counter任务,所以具有计数的功能,记的数就是当前Node的入度。在当前任务执行完之后,会把所有下游节点都dispatch(计数)一次,当计数减少到0时,说明当前Node所有依赖已经完成了,就把当前graphNode上挂的SeriesWork执行起来。
依赖处理:当一个node1依赖Node2时候,Node2的下游节点列表里加入Node1,Node1的入度自增。
执行处理:当Node2执行完,Node1的入度减一。
框架的重载了GraphNode的自增运算符和大于号、小于号,自增运算符返回Node本身。大于号、小于号运算符调用依赖关系函数。从而很形象的可以通过如下语法表达节点之间的依赖关系:
a-->b;
a-->c;
b-->d;
c-->d;是不是很秀?简直妙不可言
再说一个细节:DAG建立起来了,但是Node上是怎么挂的任务呢?
答:创建WFGraphNode通过统一接口:WFGraphNode& WFGraphTask::create_graph_node(SubTask *task),创建的时候传入你想要执行的任务,然后把要执行的任务和当前Counter任务串在一个Series里面。当当前Node计数器第一次变0的时候,会调到Done(),看一下关键的done()实现:
SubTask *WFGraphNode::done()
{
SeriesWork *series = series_of(this);
if (!this->user_data)//首次done会进这里
{
this->value = 1;//value=1使该任务再执行一次就可以达到结束状态
this->user_data = (void *)1;//下次再进来就不进这个分支了,而是直接delete this;
}
else
delete this;
return series->pop();
}首次done()的时候不析构,并将状态置为下次进来析构(value赋1&&user_data非空)。
然后将本series里面要执行的用户任务执行起来。当用户任务执行完,会再次执行到GraphNode->Done();这时侯,Node析构,并将所有follower->dispatch()起来。这就是图任务的整体执行路径。
WFRepeaterTask:
这是一个递归Task,继承自GenericTask,也就是说启动时,会创建一个Series,并把Series启动起来。创建的时候传入创建任务的回调Create,在dispatch()得时候,往当前Series里传入两个任务,一个是Create回调创建出来的新任务,一个是当前任务。这样的话,顺序任务的调度就变成:执行任务—》创建任务—》执行任务。。。
WFConditional:
WFConditional是条件任务包装器,可以把其他任务包装成条件任务,通过一个atomic
为了避免发送signal者持有条件任务的裸指针,框架还提供了全局的命名的条件任务,发送者可以根据名字给conditional发signal,内部是一个观察者模式,以cond的名字为key构建了一个红黑树管理,当signal某个key的时候,找到对应的条件任务发送signal()。
WFModuleTask:
WFModuleTask提供了一个模块级的封装,可以把一系列任务封装到一个模块里,可以注册一个模块的回调函数。WFModuleTask本质上还是一个SeriesWork,把一系列任务封装在一起,降低功能任务之间的耦合程度。
服务
基于workflow框架我们可以迅速的构建http服务器,只需要几行代码:
int main()
{
WFHttpServer server([](WFHttpTask *task) {
task->get_resp()->append_output_body("Hello World!");
});
if (server.start(8888) == 0) { // start server on port 8888
getchar(); // press "Enter" to end.
server.stop();
}
return 0;
}可以看到构造一个WFHttpServer,只要传入一个处理WFHttpTask的回调函数即可。
下面分别看 WFHttpServer 、WFServerTask
WFHttpServer
首先WFHttpServer是WFServer的http消息时的特化版本。WFServer在BaseServer的基础上增加了输入输出模板参数,并增加了一个可以处理WFNetworkTask的回调函数,同时重写了new_session方法;
poller在create_message的时候会调到new_session,创建WFServerTask;
Communicator并不知道Service是什么类型的service,在create_message的时候不管是什么类型的service,都调用service对应的new_session接口去生产session交给Poller去生成任务交由线程池执行。
WFServerTask
WFServerTask继承自WFHttpTask,WFServerTask内定义了两个局部类,Processor和Series。
前者Processor保存着服务初始化时传入的回调和当前WFServerTask的指针,dispatch时执行回调处理当前任务。
后者Series本质上是一个SeriesWork,把Processor和当前任务串起来,并先执行Processor,最后执行当前WFServerTask,当前任务负责reply。同时负责引用计数,让service知道有多少任务在引用。
服务小结
session是被动产生的,服务是静态定义的,服务定义了自己的服务类型、和产生任务的方法、处理任务的回调等等,然后在服务启动的时候绑定地址创建fd,把自己绑定到Communicator上,交给Reactor去调度。
服务治理
DOING。。。
未完待续