数据库基础
1 数据库简介
1.1 简介
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合。
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
数据库软件应该为数据库管理系统,数据库是通过数据库管理系统创建和操作的。
数据库:存储、维护和管理数据的集合。
1.2 常见数据库
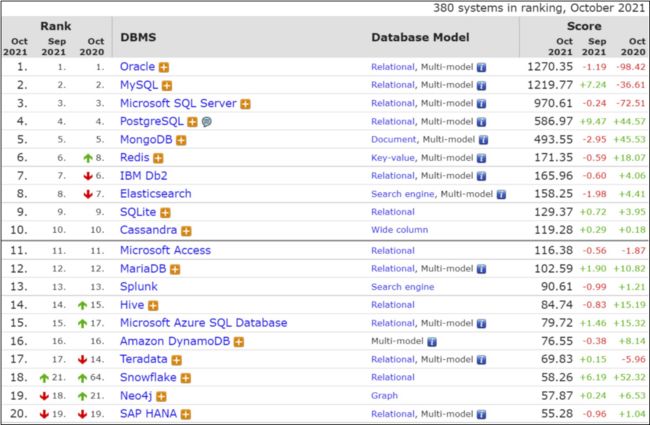
1 排名
目前互联网上常见的数据库管理软件有Oracle、MySQL、MS SQL Server、DB2、PostgreSQL、Access、Sybase、Informix这几种。以下是2021年DB-Engines Ranking 对各数据库受欢迎程度进行调查后的统计结果:(查看数据库最新排名: https://db-engines.com/en/ranking)
2 常见数据库系统介绍
- Oracle
- 1979 年,Oracle 2 诞生,它是第一个商用的 RDBMS(关系型数据库管理系统)。随着 Oracle 软件的名气越来越大,公司也改名叫 Oracle 公司。
- 2007年,总计85亿美金收购BEA Systems。
- 2009年,总计74亿美金收购SUN。此前的2008年,SUN以10亿美金收购MySQL。意味着Oracle同时拥有了MySQL 的管理权,至此 Oracle 在数据库领域中成为绝对的领导者。
- 2013年,甲骨文超越IBM,成为继Microsoft后全球第二大软件公司。
- 如今 Oracle 的年收入达到了 400 亿美金,足以证明商用(收费)数据库软件的价值。
- SQL Server
- SQL Server 是微软开发的大型商业数据库,诞生于 1989 年。C#、.net等语言常使用,与WinNT完全集成,也可以很好地与Microsoft BackOffice产品集成。
- DB2
- IBM公司的数据库产品,收费的。常应用在银行系统中。
- PostgreSQL
- PostgreSQL 的稳定性极强,最符合SQL标准,开放源码,具备商业级DBMS质量。PG对数据量大的文本以及SQL处理较快
- SQLite
- 嵌入式的小型数据库,应用在手机端。 零配置,SQlite3不用安装,不用配置,不用启动,关闭或者配置数据库实例。当系统崩溃后不用做任何恢复操作,再下次使用数据库的时候自动恢复。
- informix
- IBM公司出品,取自Information 和Unix的结合,它是第一个被移植到Linux上的商业数据库产品。仅运行于unix/linux平台,命令行操作。 性能较高,支持集群,适应于安全性要求极高的系统,尤其是银行,证券系统的应用
1.3 MySQL介绍
1 概述
- MySQL是一个 开放源代码的关系型数据库管理系统 ,由瑞典MySQL AB(创始人MichaelWidenius)公司1995年开发,迅速成为开源数据库的 No.1。
- 2008被 Sun 收购(10亿美金),2009年Sun被 Oracle 收购。 MariaDB 应运而生。(MySQL 的创造者担心 MySQL 有闭源的风险,因此创建了 MySQL 的分支项目 MariaDB)
- MySQL6.x 版本之后分为 社区版 和 商业版 。
- MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL是开源的,所以你不需要支付额外的费用。
- MySQL是可以定制的,采用了 GPL(GNU General Public License) 协议,你可以修改源码来开发自己的MySQL系统。
- MySQL支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持 4GB ,64位系统支持最大的表文件为 8TB 。
- MySQL使用 标准的SQL数据语言 形式。
- MySQL可以允许运行于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP和Ruby等。
2 MySQL的版本
- MySQL Community Server 社区版本,开源免费,自由下载,但不提供官方技术支持,适用于大多数普通用户。
- MySQL Enterprise Edition 企业版本,需付费,不能在线下载,可以试用30天。提供了更多的功能和更完备的技术支持,更适合于对数据库的功能和可靠性要求较高的企业客户。
- MySQL Cluster 集群版,开源免费。用于架设集群服务器,可将几个MySQL Server封装成一个Server。需要在社区版或企业版的基础上使用。
- MySQL Cluster CGE 高级集群版,需付费。
3 关于MySQL8.0
MySQL从5.7版本直接跳跃发布了8.0版本 ,可见这是一个令人兴奋的里程碑版本。MySQL 8版本在功能上做了显著的改进与增强,开发者对MySQL的源代码进行了重构,最突出的一点是多MySQL Optimizer优化器进行了改进。不仅在速度上得到了改善,还为用户带来了更好的性能和更棒的体验。
- 开放源代码,使用成本低。
- 性能卓越,服务稳定。
- 软件体积小,使用简单,并且易于维护。
- 历史悠久,社区用户非常活跃,遇到问题可以寻求帮助。
- 许多互联网公司在用,经过了时间的验证。
4 Oracle vs MySQL
- Oracle 更适合大型跨国企业的使用,因为他们对费用不敏感,但是对性能要求以及安全性有更高的要求。
- MySQL 由于其体积小、速度快、总体拥有成本低,可处理上千万条记录的大型数据库,尤其是开放源码这一特点,使得很多互联网公司、中小型网站选择了MySQL作为网站数据库(Facebook,Twitter,YouTube,阿里巴巴/蚂蚁金服,去哪儿,美团外卖,腾讯)。
1.4 关系型数据库基本概念
一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。表具有一些特性,这些特性定义了数据在表中如何存储,类似Java和Python中 “类”的设计。
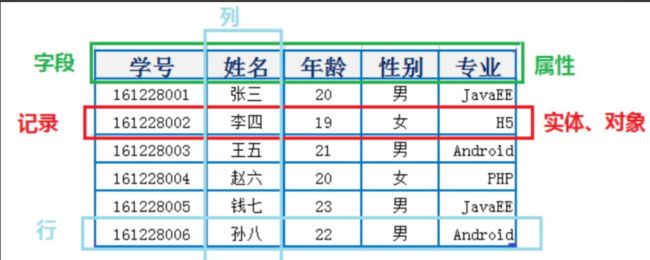
1 表、记录、字段
- E-R(entity-relationship,实体-联系)模型中有三个主要概念是: 实体集 、 属性 、 联系集 。
- 一个实体集(class)对应于数据库中的一个表(table),一个实体(instance)则对应于数据库表中的一行(row),也称为一条记录(record)。一个属性(attribute)对应于数据库表中的一列(column),也称为一个字段(field)。
ORM思想 (Object Relational Mapping)体现: - 数据库中的一个表 <—> Java或Python中的一个类
- 表中的一条数据 <—> 类中的一个对象(或实体)
- 表中的一个列 <----> 类中的一个字段、属性(field)
2 表的关联关系
- 表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。
- 四种:一对一关联、一对多关联、多对多关联
1) 一对一关联(one-to-one)
- 举例:设计 学生表 :学号、姓名、手机号码、班级、系别、身份证号码、家庭住址、籍贯、紧急联系人、…
- 拆为两个表:两个表的记录是一一对应关系。
- 基础信息表 (常用信息):学号、姓名、手机号码、班级、系别
- 档案信息表 (不常用信息):学号、身份证号码、家庭住址、籍贯、紧急联系人、…
- 两种建表原则:
- 外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一。
- 外键是主键:主表的主键和从表的主键,形成主外键关系。
2) 一对多关系(one-to-many)
- 常见实例场景: 客户表和订单表 , 分类表和商品表 , 部门表和员工表 。
- 举例:
- 员工表:编号、姓名、…、所属部门
- 部门表:编号、名称、简介
- 一对多建表原则:在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
3) 多对多(many-to-many)
要表示多对多关系,必须创建第三个表,该表通常称为 联接表 ,它将多对多关系划分为两个一对多关系。将这两个表的主键都插入到第三个表中。
- 举例:用户-角色
多对多关系建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。
2 MySQL8 环境搭建
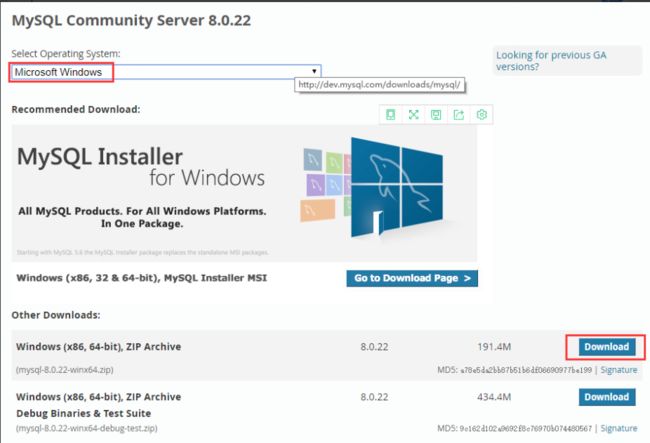
2.1 Mysql的下载
下载地址:https://dev.mysql.com/downloads/mysql/
Windows下载:
mac下载:
无账户下载时:
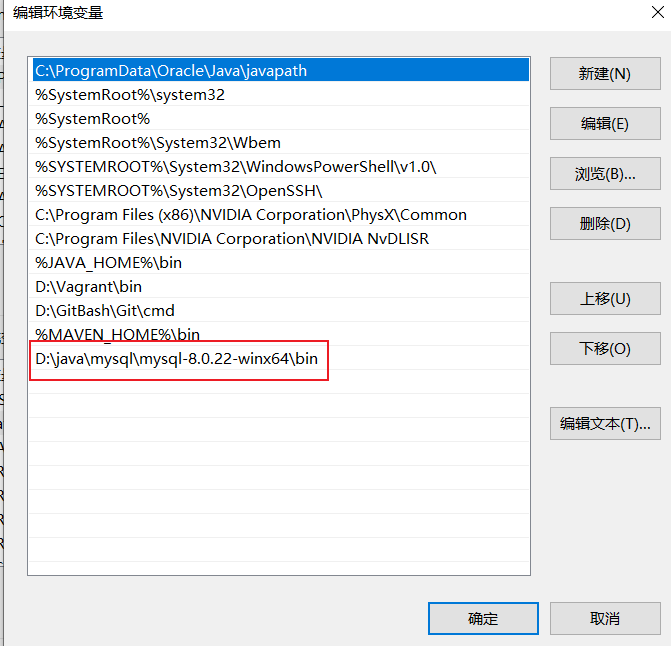
2.2 配置环境变量
在非C盘下,创建mysql文件夹,解压压缩包
将解压文件夹下的bin路径添加到变量值中,前后以 ; 开头结尾
2.3 配置MySQL配置文件
在mysql文件夹下找到my.ini或my-default.ini,如果没有.ini结尾的文件,直接创建该文件。新增内容为
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=d:\java\mysql\mysql-8.0.22-winx64
# 设置mysql数据库的数据的存放目录
datadir=d:\java\mysql\mysql-8.0.22-winx64\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8
在windows的mysql文件目录下新增一个文件data文件夹
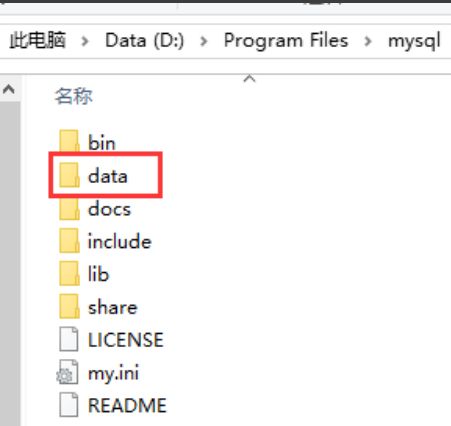
2.4 安装mysql
在mysql的安装目录中,打开bin文件夹,运行cmd.执行初始化数据库的指令:
mysqld --initialize --console
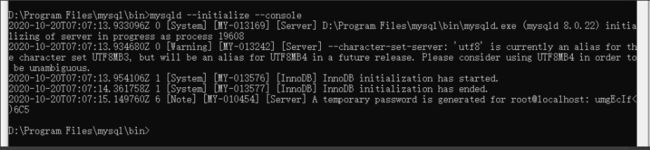
最后一行为root用户的初始化密码:
![]()
注意:若不小心关掉cmd,或者没记住,那也没事,删掉初始化的 datadir 目录,再执行一遍初始化命令,又会重新生成的。
2.5 安装任务
在MySQL安装目录的 bin 目录下执行命令:
mysqld --install mysql8
若安装错误,重启cmd,以管理员身份打开

安装成功
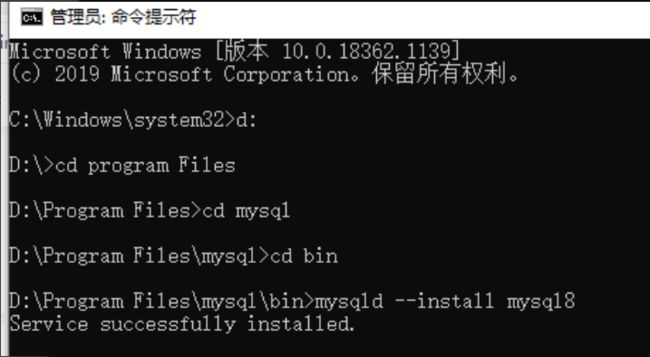
安装成功后开启服务
net start mysql8
关闭服务
net stop mysql8
注意:安装时,卸载其他版本的mysql数据库
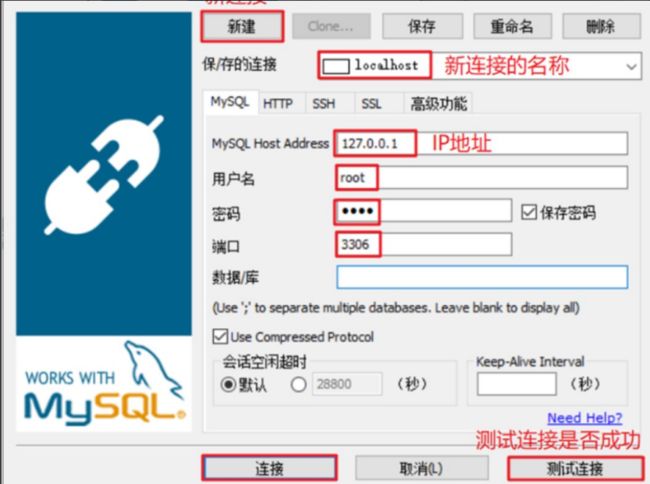
2.6 连接数据库
格式:
mysql -h 主机名 -P 端口号 -u 用户名 -p密码
以root身份启动:
mysql -u root -p
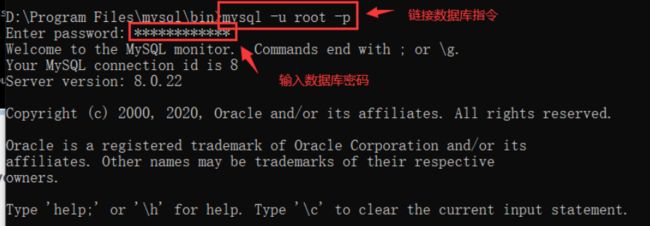
修改账户密码为123456:
alter user 'root'@'localhost' identified with mysql_native_password BY '123456';
退出数据库
quit
或者
exit
2.7 查看mysql版本信息
c:\> mysql -V
c:\> mysql --version
或者
mysql> select version();
查看mysql数据库信息
mysql> show databases;
- “information_schema”是 MySQL 系统自带的数据库,主要保存 MySQL 数据库服务器的系统信息,比如数据库的名称、数据表的名称、字段名称、存取权限、数据文件 所在的文件夹和系统使用的文件夹,等等
- “performance_schema”是 MySQL 系统自带的数据库,可以用来监控 MySQL 的各类性能指标。“sys”数据库是 MySQL 系统自带的数据库,主要作用是以一种更容易被理解的方式展示
- MySQL 数据库服务器的各类性能指标,帮助系统管理员和开发人员监控MySQL 的技术性能。
- “mysql”数据库保存了 MySQL 数据库服务器运行时需要的系统信息,比如数据文件夹、当前使用的字符集、约束检查信息等等
2.8 mysql的卸载
1. 使用管理员身份运行cmd,关闭mysql服务
net stop mysql8
2. 删除mysql服务
mysqld remove mysql8
#或者
sc delete mysql8
3. 刪除mysqlDB目录文件
删除安裝mysql时my.ini指定的目录
3 MySQL图形化管理工具
3.1 Navicat
Navicat MySQL是一个强大的MySQL数据库服务器管理和开发工具。它可以与任何3.21或以上版本的MySQL一起工作,支持触发器、存储过程、函数、事件、视图、管理用户等,对于新手来说易学易用。其精心设计的图形用户界面(GUI)可以让用户用一种安全简便的方式来快速方便地创建、组织、访问和共享信息。Navicat支持中文,有免费版本提供。 下载地址:http://www.navicat.com/
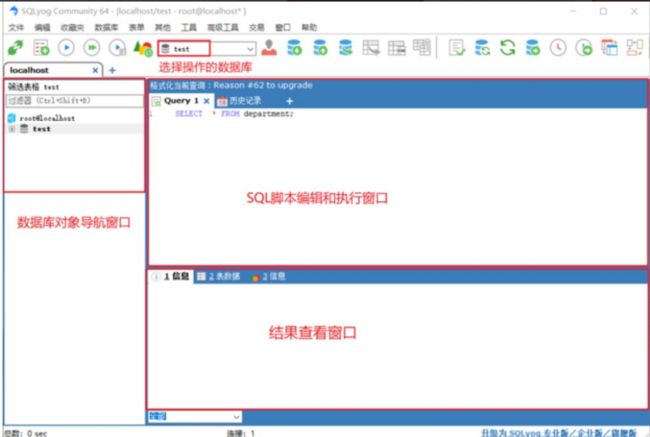
3.2 SQLyog
SQLyog 是业界著名的 Webyog 公司出品的一款简洁高效、功能强大的图形化 MySQL 数据库管理工具。这款工具是使用C++语言开发的。该工具可以方便地创建数据库、表、视图和索引等,还可以方便地进行插入、更新和删除等操作,同时可以方便地进行数据库、数据表的备份和还原。该工具不仅可以通过SQL文件进行大量文件的导入和导出,还可以导入和导出XML、HTML和CSV等多种格式的数据。 下载地址:http://www.webyog.com/
4 SQL语言
4.1 概述
SQL:Structure Query Language(结构化查询语言),SQL被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准,后来被国际化标准组织(ISO)采纳为关系数据库语言的国际标准。
各数据库厂商都支持ISO的SQL标准,普通话
各数据库厂商在标准的基础上做了自己的扩展,方言
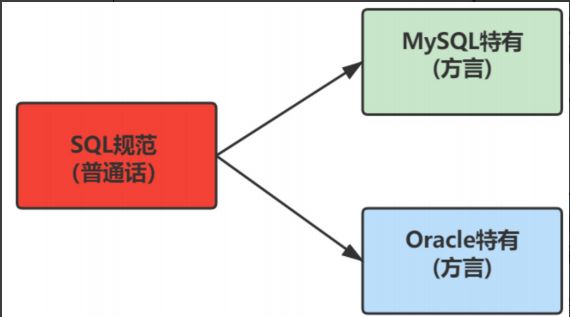
SQL 是一种标准化的语言,它允许你在数据库上执行操作,如创建项目,查询内容,更新内容,并删除条目等操作。
Create, Read, Update, and Delete 通常称为CRUD操作。
4.2 SQL语句分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。
- 主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据)增删改。
- 主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等
- SELECT是SQL语言的基础,最为重要
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
- 主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)查询。
- 因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语
言)。
- 因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语
- TCL (Transaction Control Language,事务控制语言)
- 单独将 COMMIT 、 ROLLBACK 取出来称为TCL
4.3 SQL语言的规则与规范
- SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
- 每条命令以 ; 或 \g 或 \G 结束
- 关键字不能被缩写也不能分行
- 关于标点符号
- 必须保证所有的()、单引号、双引号是成对结束的
- 必须使用英文状态下的半角输入方式
- 字符串型和日期时间类型的数据可以使用单引号(’ ')表示
- 列的别名,尽量使用双引号(" "),而且不建议省略as
- MySQL 在 Windows 环境下是大小写不敏感的
- MySQL 在 Linux 环境下是大小写敏感的
- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
- 推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
system cls #清屏
use mysql;
select * from user \g
select * from user;
select * from user \G
4.4 注释
单行注释:#注释文字(MySQL特有的方式)
单行注释:-- 注释文字(--后面必须包含一个空格。)
多行注释:/* 注释文字 */
4.5 命名规则
数据命名规范,可以参考阿里开发规约(嵩山版),基本规则如下:
- 数据库、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来
- 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
#以下两句是一样的,不区分大小写
show databases;
SHOW DATABASES;
#创建表格
#create table student info(...); #表名错误,因为表名有空格
create table student_info(...);
#其中order使用``飘号,因为order和系统关键字或系统函数名等预定义标识符重名了
CREATE TABLE `order`();
select id as "编号", `name` as "姓名" from t_stu; #起别名时,as都可以省略
select id as 编号, `name` as 姓名 from t_stu; #如果字段别名中没有空格,那么可以省
略""
select id as 编 号, `name` as 姓 名 from t_stu; #错误,如果字段别名中有空格,那么不
能省略""
4.6 数据导入命令
mysql> source d:\mysqldb.sql
5 基本的select语句
5.1 select … from
1 语法
SELECT 标识选择哪些列
FROM 标识从哪个表中选择
2 不带from子句
select 1;
select 9/2;
select 1 from dual;
select null = null; # null,所以规定使用is null判断Null
SELECT * FROM employees WHERE manager_id IS NULL;
3 *代表打印所有数据
select * from departments;
一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符‘*’。使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率。通配符的优势是,当不知道所需要的列的名称时,可以通过它获取它们。
在生产环境下,不推荐你直接使用 SELECT * 进行查询。
4 选择特定的列
SELECT department_id, location_id FROM departments;
MySQL中的SQL语句是不区分大小写的,因此SELECT和select的作用是相同的,但是,许多开发人员习惯将关键字大写、数据列和表名小写,读者也应该养成一个良好的编程习惯,这样写出来的代码更容易阅读和维护。
5.2 列的别名
- 重命名一个列
- 便于计算
- 紧跟列名,也可以在列名和别名之间加入关键字AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。
- AS 可以省略
- 建议别名简短,见名知意
举例如下:
SELECT last_name AS name, commission_pct comm FROM employees;
SELECT last_name "name", salary*12 "annual_salary" FROM employees;
5.3 去除重复行
默认情况下,查询会返回全部行,包括重复行。
SELECT department_id FROM employees;
在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT department_id FROM employees;
多列去重
SELECT DISTINCT department_id,salary FROM employees;
注意:
- DISTINCT 需要放到所有列名的前面,如果写成 SELECT salary, DISTINCT department_id FROMemployees 会报错。
- DISTINCT 其实是对后面所有列名的组合进行去重,你能看到最后的结果是 74 条,因为这 74 个部门id不同,都有 salary 这个属性值。如果你想要看都有哪些不同的部门(department_id),只需要写 DISTINCT department_id 即可,后面不需要再加其他的列名了。
5.4 空值参与运算
所有运算符或列值遇到null值,运算的结果都为null
select null + 1; # null
select null >=1; # null;
select null = nul; #null
SELECT commission_pct FROM employees WHERE commission_pct = NULL; #错误
SELECT commission_pct FROM employees WHERE commission_pct is NULL; #
SELECT employee_id,salary,commission_pct, 12 * salary * (1 + commission_pct)
"annual_sal" FROM employees;
在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
5.5 着重号
//ORDER报错
mysql> SELECT * FROM ORDER;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'ORDER' at line 1
//`ORDER`不报错
mysql> SELECT * FROM `ORDER`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM `order`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对"``"(着重号)引起来。
5.6 查询常数
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
你可能会问为什么我们还要对常数进行查询呢?
SQL 中的 SELECT 语法的确提供了这个功能,一般来说我们只从一个表中查询数据,通常不需要增加一个固定的常数列,但如果我们想整合不同的数据源,用常数列作为这个表的标记,就需要查询常数。
比如说,我们想对 employees 数据表中的员工姓名进行查询,同时增加一列字段 corporation ,这个字段固定值为“日知录”,可以这样写:
SELECT 'yy' as corporation, last_name FROM employees;
5.7 过滤条件
语法
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
举例
SELECT employee_id, last_name, job_id, department_id FROM employees WHERE
department_id = 90;
5.8 显示表结构
语法
DESCRIBE 表名;
或 DESC 表名;
举例
DESCRIBE employees;
或 DESC employees;
参数介绍
- Field:表示字段名称。
- Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
- Null:表示该列是否可以存储NULL值。
- Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
- Default:表示该列是否有默认值,如果有,那么值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
6 运算符
6.1 算数运算符
算术运算符主要用于数学运算,其可以连接运算符前后的两个数值或表达式,对数值或表达式进行加(+)、减(-)、乘(*)、除(/)和取模(%)运算。
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| + | 加法运算符 | 计算两个值或表达式的和 | SELECT A + B |
| - | 减法运算符 | 计算两个值或表达式的差 | SELECT A - B |
| * | 乘法运算符 | 计算两个值或表达式的乘积 | SELECT A * B |
| /或DIV | 除法运算符 | 计算两个值或表达式的商 | SELECT A / B或SELECT A DIV B |
| %或MOD | 求模(求商)法运算符 | 计算两个值或表达式的余数 | SELECT A % B或SELECT A MOD B |
案例:
# 查询1+1
select 1+1;
# 查询1-1
select 1-1;
#查询工资乘以医保比率
SELECT salary * commission_pct FROM employees
#筛选出employee_id是偶数的员工
SELECT * FROM employees WHERE employee_id MOD 2 = 0;
6.2 比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| = | 等于运算符 | 判断两个值、字符串或表达式是否相等 | SELECT C FROM TABLE WHERE A = B |
| <=> | 安全等于运算符 | 安全的判断两个值、字符串或表达式是否相等 | SELECT C FROM TABLE WHERE A <=> B |
| <>(!=) | 不等于运算符 | 判断两个值、字符串或表达式是否不相等 | SELECT C FROM TABLE WHERE A <> B 或 SELECT C FROM TABLE WHERE A != B |
| < | 小于运算符 | 判断前面的值、字符串或表达式是否小于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A < B |
| <= | 小于等于运算符 | 判断前面的值、字符串或表达式是否小于等于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A <= B |
| > | 大于运算符 | 判断前面的值、字符串或表达式是否大于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A > B |
| >= | 大于等于运算符 | 判断前面的值、字符串或表达式是否大于等于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A >= B |
| IS NULL | 为空运算符 | 判断值、字符串或表达式是否为空 | SELECT B FROM TABLE WHERE A IS NULL |
| ISNULL | 为空运算符 | 判断值、字符串或表达式是否为空 | SELECT B FROM TABLE WHERE A ISNULL |
| IS NOT NULL | 不为空运算符 | 判断值、字符串或表达式是否不为空 | SELECT B FROM TABLE WHERE A IS NOT NULL |
| LEAST | 最小值运算符 | 在多个值中返回最小值 | SELECT D FROM TABLE WHERE C LEAST(A,B) |
| GREATEST | 最大值运算符 | 在多个值中返回最大值 | SELECT D FROM TABLE WHERE C GREATEST(A,B) |
| BETWEEN AND | 两值之间的运算符 | 判断一个值是否在两个值之间 | SELECT D FROM TABLE WHERE C BETWEEN A AND B |
| IN | 属于运算符 | 判断一个值是否为列表中的任意一个值 | SELECT D FROM TABLE WHERE C IN (A,B) |
| NOT IN | 不属于运算符 | 判断一个值是否不为列表中的任意一个值 | SELECT D FROM TABLE WHERE C NOT IN (A,B) |
| LIKE | 模糊匹配运算符 | 判断一个值是否符合模糊匹配规则 | SELECT C FROM TABLE WHERE A LIKE B |
| REGEXP | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | SELECT C FROM TABLE WHERE A REGEXP B |
| RLIKE | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | SELECT C FROM TABLE WHERE A RLIKE B |
举例:
#工资大于10000的员工
SELECT * FROM employees WHERE salary > 10000
#查询department_id是90和60的员工
SELECT * FROM employees WHERE department_id IN (90, 60);
#模糊查询
SELECT * FROM employees WHERE first_name LIKE '%ex%' #是否区分大小写,看操作系统或
者字符集
SELECT * FROM employees WHERE first_name like binary '%ex%' # 区分大小写
6.3 逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。
MySQL中支持4种逻辑运算符如下:
| 运算符 | 作用 | 示例 |
|---|---|---|
| NOT 或 ! | 逻辑非 | SELECT NOT A |
| AND 或 && | 逻辑与 | SELECT A AND B 或 SELECT A && B |
| OR 或 || | 逻辑或 | SELECT A OR B 或 SELECT A || B |
| XOR | 逻辑异或 | SELECT A XOR B |
案例:
SELECT employee_id, last_name, job_id, salary FROM employees WHERE salary>=10000 AND job_id LIKE %MAN%';
#查询基本薪资不在9000-12000之间的员工编号和基本薪资
SELECT employee_id,salary FROM employees WHERE NOT (salary >= 9000 AND salary <= 12000);
SELECT employee_id,salary FROM employees WHERE salary <9000 OR salary > 12000;
SELECT employee_id,salary FROM employees WHERE salary NOT BETWEEN 9000 AND 12000;
#正则运算符
SELECT * FROM employees WHERE first_name REGEXP '^A';
6.4 位运算
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数。
MySQL支持的位运算符如下:
| 运算符 | 作用 | 示例 |
|---|---|---|
| & | 按位与(位AND) | SELECT A & B |
| | | 按位或(位OR) | SELECT A | B |
| ^ | 按位异或(位XOR) | SELECT A ^ B |
| ~ | 按位取反 | SELECT A ~ B |
| >> | 按位右移 | SELECT A >> B |
| << | 按位右移 | SELECT A << B |
7 排序与分页
7.1 排序数据
- 使用 ORDER BY 子句排序
- ASC(ascend): 升序
- DESC(descend):降序
- ORDER BY 子句在SELECT语句的结尾
实例:
SELECT last_name, job_id, department_id, hire_date FROM employees ORDER BY hire_date ;
SELECT last_name, job_id, department_id, hire_date FROM employees ORDER BY hire_date DESC ;
SELECT employee_id, last_name, salary*12 annsal FROM employees ORDER BY annsal;
#多列排序
SELECT last_name, department_id, salary FROM employees ORDER BY department_id, salary DESC;
7.2 分页
语法
LIMIT [位置偏移量,] 行数
举例
--前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
--第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
--第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
注:MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT4,3;”返回的结果相同。
分页显式公式:(当前页数-1)*每页条数,每页条数
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize;
8 多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
8.1 笛卡尔积(交叉连接)
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
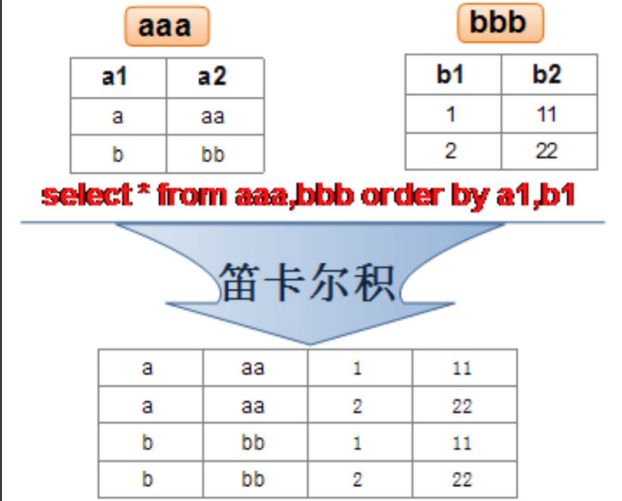
#查询员工姓名和所在部门名称
SELECT last_name,department_name FROM employees,departments;
SELECT last_name,department_name FROM employees CROSS JOIN departments;
SELECT last_name,department_name FROM employees INNER JOIN departments;
SELECT last_name,department_name FROM employees JOIN departments;
为了避免笛卡尔积, 可以在 WHERE 加入有效的连接条件。
#案例:查询员工的姓名及其部门名称
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
8.2 多表关联的分类
8.2.1 等值连接和非等值连接
1 等值连接
SELECT employees.employee_id, employees.last_name,
employees.department_id, departments.department_id,
departments.location_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
按照阿里规约规定,多表关联应该强制使用别名
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
2 非等值连接
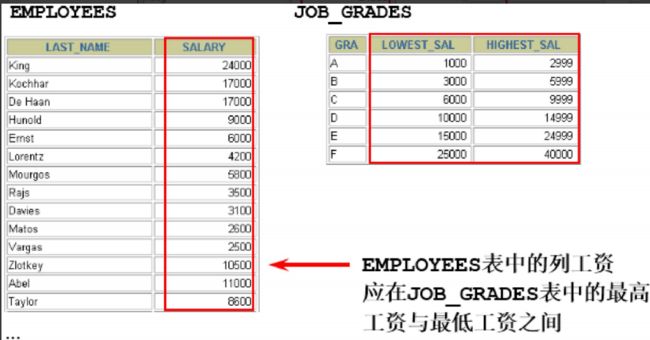
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;
8.2.2 自连接和非自连接
1 自连接
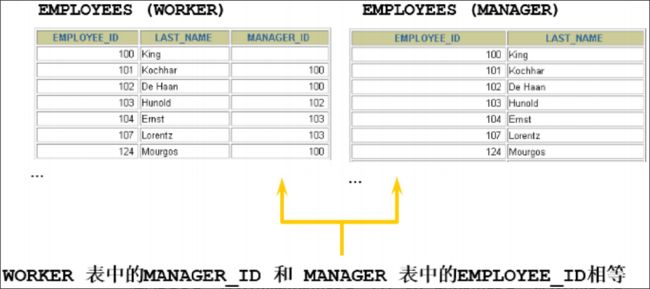
SELECT CONCAT(worker.last_name ,' works for '
, manager.last_name)
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;
2 非自连接
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
8.2.3 内连接和外连接
除了查询满足条件的记录以外,外连接还可以查询某一方不满足条件的记录。
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。 没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
- 如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表
8.3 SQL92与SQL99语法多表查询
8.3.1 SQL92标准对于外连接的处理
- 在 SQL92 中采用(+)代表从表所在的位置。即左或右外连接中,(+) 表示哪个是从表。
- Oracle 对 SQL92 支持较好,而 MySQL 则不支持 SQL92 的外连接
- 而且在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接
#左外连接
SELECT last_name,department_name
FROM employees ,departments
WHERE employees.department_id = departments.department_id(+);
#右外连接
SELECT last_name,department_name
FROM employees ,departments
WHERE employees.department_id(+) = departments.department_id;
8.3.2 SQL99语法实现多表查询
语法:
SELECT table1.column, table2.column,table3.column
FROM table1
JOIN table2 ON table1 和 table2 的连接条件
JOIN table3 ON table2 和 table3 的连接条件
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
- 关键字 JOIN、INNER JOIN、CROSS JOIN 的含义是一样的,都表示内连接
1 内连接(INNER JOIN)
语法:
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
案例一:
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id);
案例二:
SELECT employee_id, city, department_name
FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l
ON d.location_id = l.location_id;
2 左外连接(LEFT OUTER JOIN)
查询左边表所有数据(包括满足条件和不满足条件的数据)
语法:
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
案例:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
3 右外连接(RIGHT OUTER JOIN)
查询右边表所有数据(包括满足条件和不满足条件的数据)
语法:
SELECT 字段列表
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
案例:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
4 满外连接(FULL OUTER JOIN)
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN,但是可以用 LEFT JOIN UNION RIGHT join代替。
8.4 UNION的使用
合并查询结果 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。 各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
8.4.1 UNION操作符
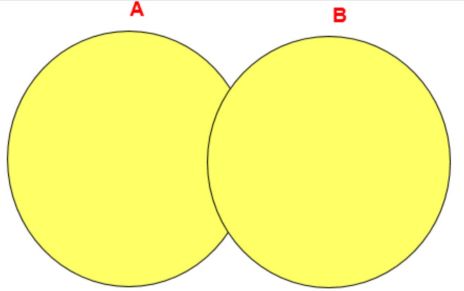
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
8.4.2 UNION ALL操作符
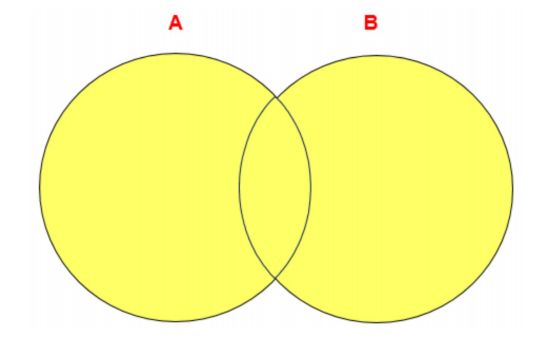
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION
ALL语句,以提高数据查询的效率。
8.4.3 案例:查询部门编号>90或邮箱包含a的员工信息
#方式1
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
#方式2
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
8.5 7种SQL JOINS的实现
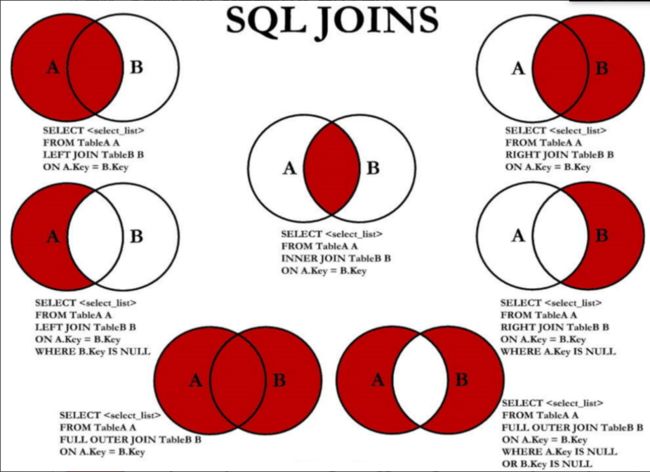
案例:
#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#左下图:满外连接
# 左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
注意:我们要 控制连接表的数量 。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时, 保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。 来源:阿里巴巴《Java开发手册》
9 单行函数
9.1 函数的理解
9.1.1 什么是函数
函数在计算机语言的使用中贯穿始终,函数的作用是什么呢?它可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既 提高了代码效率 ,又 提高了可维护性 。在 SQL 中我们也可以使用函数对检索出来的数据进行函数操作。使用这些函数,可以极大地 提高用户对数据库的管理效率 。
从函数定义的角度出发,我们可以将函数分成 内置函数 和 自定义函数 。在 SQL 语言中,同样也包括了内置函数和自定义函数。内置函数是系统内置的通用函数,而自定义函数是我们根据自己的需要编写的,本章及下一章讲解的是 SQL 的内置函数。
9.1.2 不同DBMS函数的差异
我们在使用 SQL 语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即DBMS。DBMS 之间的差异性很大,远大于同一个语言不同版本之间的差异。 实际上,只有很少的函数是被 DBMS 同时支持的。比如,大多数 DBMS 使用(||)或者(+)来做拼接符,而在 MySQL 中的字符串拼接函数为concat()。大部分 DBMS 会有自己特定的函数,这就意味着采用 SQL 函数的代码可移植性是很差的, 因此在使用函数的时候需要特别注意。
9.1.3 MySQL的内置函数及分类
MySQL提供了丰富的内置函数,这些函数使得数据的维护与管理更加方便,能够更好地提供数据的分析与统计功能,在一定程度上提高了开发人员进行数据分析与统计的效率。
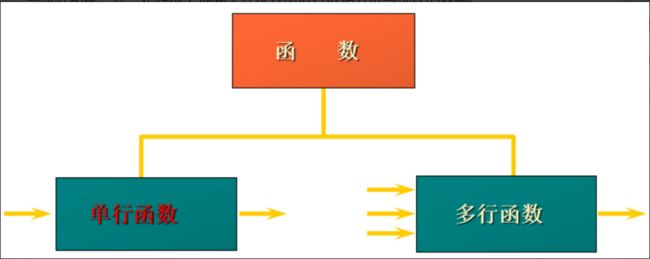
MySQL提供的内置函数从 实现的功能角度 可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MySQL信息函数、聚合函数等。这里,我将这些丰富的内置函数再分为两类: 单行函数 、 聚合函数(或分组函数) 。
9.2 字符串函数
| 函数 | 用法 |
|---|---|
| ASCII(S) | 返回字符串S中的第一个字符的ASCII码值 |
| CHAR_LENGTH(s) | 返回字符串s的字符数。作用与CHARACTER_LENGTH(s)相同 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| CONCAT(s1,s2,…,sn) | 连接s1,s2,…,sn为一个字符串 |
| CONCAT_WS(x,s1,s2,…,sn) | 同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上x |
| INSERT(str, idx, len,replacestr) | 将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr |
| REPLACE(str, a, b) | 用字符串b替换字符串str中所有出现的字符串a |
| UPPER(s) 或 UCASE(s) | 将字符串s的所有字母转成大写字母 |
| LOWER(s) 或LCASE(s) | 将字符串s的所有字母转成小写字母 |
| LEFT(str,n) | 返回字符串str最左边的n个字符 |
| RIGHT(str,n) | 返回字符串str最右边的n个字符 |
| LPAD(str, len, pad) | 用字符串pad对str最左边进行填充,直到str的长度为len个字符 |
| RPAD(str ,len, pad) | 用字符串pad对str最右边进行填充,直到str的长度为len个字符 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始与结尾的空格 |
| TRIM(s1 FROM s) | 去掉字符串s开始与结尾的s1 |
| TRIM(LEADING s1 FROM s) | 去掉字符串s开始处的s1 |
| TRIM(TRAILING s1 FROM s) | 去掉字符串s结尾处的s1 |
| REPEAT(str, n) | 返回str重复n次的结果 |
| SPACE(n) | 返回n个空格 |
| STRCMP(s1,s2) | 比较字符串s1,s2的ASCII码值的大小 |
| SUBSTR(s,index,len) | 返回从字符串s的index位置其len个字符,作用与SUBSTRING(s,n,len)、 MID(s,n,len)相同 |
| LOCATE(substr,str) | 返回字符串substr在字符串str中首次出现的位置,作用于POSITION(substr IN str)、INSTR(str,substr)相同。未找到,返回0 |
| ELT(m,s1,s2,…,sn) | 返回指定位置的字符串,如果m=1,则返回s1,如果m=2,则返回s2,如 果m=n,则返回sn |
| FIELD(s,s1,s2,…,sn) | 返回字符串s在字符串列表中第一次出现的位置 |
| FIND_IN_SET(s1,s2) | 返回字符串s1在字符串s2中出现的位置。其中,字符串s2是一个以逗号分 隔的字符串 |
| REVERSE(s) | 返回s反转后的字符串 |
| NULLIF(value1,value2) | 比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1 |
案例:
mysql> SELECT
FIELD('mm','hello','msm','amma'),FIND_IN_SET('mm','hello,mm,amma')
FROM DUAL;
+----------------------------------+-----------------------------------+
| FIELD('mm','hello','msm','amma') | FIND_IN_SET('mm','hello,mm,amma') |
+----------------------------------+-----------------------------------+
| 0 | 2 |
+----------------------------------+-----------------------------------+
1 row in set (0.00 sec)
mysql> SELECT NULLIF('mysql','mysql'),NULLIF('mysql', '');
+-------------------------+---------------------+
| NULLIF('mysql','mysql') | NULLIF('mysql', '') |
+-------------------------+---------------------+
| NULL | mysql |
+-------------------------+---------------------+
1 row in set (0.00 sec)
9.3 日期和时间函数
9.3.1 获取日期,时间
| 函数 | 用法 |
|---|---|
| CURDATE() ,CURRENT_DATE() | 返回当前日期,只包含年、 月、日 |
| CURTIME() , CURRENT_TIME() | 返回当前时间,只包含时、 分、秒 |
| NOW() / SYSDATE() / CURRENT_TIMESTAMP() /LOCALTIME() /LOCALTIMESTAMP() | 返回当前系统日期和时间 |
| UTC_DATE() | 返回UTC(世界标准时间) 日期 |
| UTC_TIME() | 返回UTC(世界标准时间) 时间 |
SELECT
CURDATE(),CURTIME(),NOW(),SYSDATE()+0,UTC_DATE(),UTC_DATE()+0,UTC_TIME(),UTC_
TIME()+0
FROM DUAL;
9.3.2 日期与时间戳的转换
| 函数 | 用法 |
|---|---|
| UNIX_TIMESTAMP() | 以UNIX时间戳的形式返回当前时间。SELECTUNIX_TIMESTAMP() - >1634348884 |
| UNIX_TIMESTAMP(date) | 将时间date以UNIX时间戳的形式返回。 |
| FROM UNIXTIME(timestamp) | 将UNIX时间戳的时间转换为普通格式的时间 |
案例:
mysql> SELECT UNIX_TIMESTAMP(now());
+-----------------------+
| UNIX_TIMESTAMP(now()) |
+-----------------------+
| 1576380910 |
+-----------------------+
1 row in set (0.01 sec)
mysql> SELECT UNIX_TIMESTAMP(CURDATE());
+---------------------------+
| UNIX_TIMESTAMP(CURDATE()) |
+---------------------------+
| 1576339200 |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT UNIX_TIMESTAMP(CURTIME());
+---------------------------+
| UNIX_TIMESTAMP(CURTIME()) |
+---------------------------+
| 1576380969 |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT UNIX_TIMESTAMP('2011-11-11 11:11:11')
+---------------------------------------+
| UNIX_TIMESTAMP('2011-11-11 11:11:11') |
+---------------------------------------+
| 1320981071 |
+---------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT FROM_UNIXTIME(1576380910);
+---------------------------+
| FROM_UNIXTIME(1576380910) |
+---------------------------+
| 2019-12-15 11:35:10 |
+---------------------------+
1 row in set (0.00 sec)
9.3.3 获取月份、星期、星期数、天数等函数
| 函数 | 用法 |
|---|---|
| YEAR(date) / MONTH(date) / DAY(date) | 返回具体的日期值 |
| HOUR(time) / MINUTE(time) /SECOND(time) | 返回具体的时间值 |
| MONTHNAME(date) | 返回月份:January,… |
| DAYNAME(date) | 返回星期几:MONDAY,TUESDAY…SUNDAY |
| WEEKDAY(date) | 返回周几,注意,周1是0,周2是1…周日 |
| 是6 | |
| QUARTER(date) | 返回日期对应的季度,范围为1~4 |
| WEEK(date) , WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFYEAR(date) | 返回日期是一年中的第几天 |
| DAYOFMONTH(date) | 返回日期位于所在月份的第几天 |
| DAYOFWEEK(date) | 返回周几,注意:周日是1,周一是2…周六是7 |
案例:
SELECT YEAR(CURDATE()),MONTH(CURDATE()),DAY(CURDATE()),
HOUR(CURTIME()),MINUTE(NOW()),SECOND(SYSDATE())
FROM DUAL;
SELECT MONTHNAME('2021-10-26'),DAYNAME('2021-10-26'),WEEKDAY('2021-10-26'),
QUARTER(CURDATE()),WEEK(CURDATE()),DAYOFYEAR(NOW()),
DAYOFMONTH(NOW()),DAYOFWEEK(NOW())
FROM DUAL;
9.3.4 日期的操作函数
| 函数 | 用法 |
|---|---|
| EXTRACT(type FROM date) | 返回指定日期中特定的部分,type指定返回的值 |
EXTRACT(type FROM date)函数中type的取值与含义 :
| type取值 | 含义 |
|---|---|
| YEAR | 提取年份部分 |
| MONTH | 提取月份部分 |
| DAY | 提取日期部分 |
| HOUR | 提取小时部分 |
| MINUTE | 提取分钟部分 |
| SECOND | 提取秒钟部分 |
| MICROSECOND | 提取微秒部分(仅支持到秒级别的精度) |
| QUARTER | 提取季度部分 |
| WEEK | 提取周数部分 |
| DAYOFWEEK 或 WEEKDAY | 提取星期几部分(1 表示星期日,2 表示星期一,以此类推) |
| DAYOFYEAR | 提取一年中的天数 |
| LAST_DAY(date) | 返回给定日期所在月份的最后一天 |
SELECT EXTRACT(MINUTE FROM NOW()),EXTRACT( WEEK FROM NOW()),
EXTRACT( QUARTER FROM NOW()),EXTRACT( MINUTE_SECOND FROM NOW())
FROM DUAL;
9.3.4 时间和秒钟转换的函数
| 函数 | 用法 |
|---|---|
| TIME_TO_SEC(time) | 将 time 转化为秒并返回结果值。转化的公式为: 小时3600+分钟60+秒 |
| SEC_TO_TIME(seconds) | 将 seconds 描述转化为包含小时、分钟和秒的时间 |
mysql> SELECT TIME_TO_SEC(NOW());
+--------------------+
| TIME_TO_SEC(NOW()) |
+--------------------+
| 78774 |
+--------------------+
1 row in set (0.00 sec)
mysql> SELECT SEC_TO_TIME(78774);
+--------------------+
| SEC_TO_TIME(78774) |
+--------------------+
| 21:52:54 |
+--------------------+
1 row in set (0.12 sec)
9.3.6 计算日期和时间的函数
| 函数 | 用法 |
|---|---|
| DATE_ADD(datetime, INTERVAL expr type),ADDDATE(date,INTERVAL expr type) | 返回与给定日期时间相差INTERVAL时间段的日期时间 |
| DATE_SUB(date,INTERVAL expr type),SUBDATE(date,INTERVAL expr type) | 返回与date相差INTERVAL时间间隔的日期 |
type的取值:
| 间隔类型 | 含义 |
|---|---|
| HOUR | 小时 |
| MINUTE | 分钟 |
| SECOND | 秒 |
| YEAR | 年 |
| MONTH | 月 |
| DAY | 日 |
| YEAR_MONTH | 年和月 |
| DAY_HOUR | 日和小时 |
| DAY_MINUTE | 日和分钟 |
| DAY_SECOMD | 日和秒 |
| HOUR_MINUTE | 小时和分钟 |
| HOUR_SECOND | 小时和秒 |
| MINUTE_SECOND | 分钟和秒 |
SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) AS col1,DATE_ADD('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col2,
ADDDATE('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col3,
DATE_ADD('2021-10-21 23:32:12',INTERVAL '1_1' MINUTE_SECOND) AS col4,
DATE_ADD(NOW(), INTERVAL -1 YEAR) AS col5, #可以是负数
DATE_ADD(NOW(), INTERVAL '1_1' YEAR_MONTH) AS col6 #需要单引号
FROM DUAL;
SELECT DATE_SUB('2021-01-21',INTERVAL 31 DAY) AS col1,
SUBDATE('2021-01-21',INTERVAL 31 DAY) AS col2,
DATE_SUB('2021-01-21 02:01:01',INTERVAL '1 1' DAY_HOUR) AS col3
FROM DUAL;
| 函数 | 用法 |
|---|---|
| ADDTIME(time1,time2) | 返回time1加上time2的时间。当time2为一个数字时,代表的是 秒 ,可以为负数 |
| SUBTIME(time1,time2) | 返回time1减去time2后的时间。当time2为一个数字时,代表的 是 秒 ,可以为负数 |
| DATEDIFF(date1,date2) | 返回date1 - date2的日期间隔天数 |
| TIMEDIFF(time1, time2) | 返回time1 - time2的时间间隔 |
| FROM_DAYS(N) | 返回从0000年1月1日起,N天以后的日期 |
| TO_DAYS(date) | 返回日期date距离0000年1月1日的天数 |
| LAST_DAY(date) | 返回date所在月份的最后一天的日期 |
| MAKEDATE(year,n) | 针对给定年份与所在年份中的天数返回一个日期 |
| MAKETIME(hour,minute,second) | 将给定的小时、分钟和秒组合成时间并返回 |
| PERIOD_ADD(time,n) | 返回time加上n后的时间 |
mysql> SELECT ADDTIME(NOW(), 50);
+---------------------+
| ADDTIME(NOW(), 50) |
+---------------------+
| 2019-12-15 22:17:47 |
+---------------------+
1 row in set (0.00 sec)
mysql> SELECT ADDTIME(NOW(), '1:1:1');
+-------------------------+
| ADDTIME(NOW(), '1:1:1') |
+-------------------------+
| 2019-12-15 23:18:46 |
+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT MAKEDATE(2020,1);
+------------------+
| MAKEDATE(2020,1) |
+------------------+
| 2020-01-01 |
+------------------+
1 row in set (0.00 sec)
mysql> SELECT MAKETIME(1,1,1);
+-----------------+
| MAKETIME(1,1,1) |
+-----------------+
| 01:01:01 |
+-----------------+
1 row in set (0.00 sec)
9.3.7 日期的格式化与解析
| 函数 | 用法 |
|---|---|
| DATE_FORMAT(date,fmt) | 按照字符串fmt格式化日期date值 |
| TIME_FORMAT(time,fmt) | 按照字符串fmt格式化时间time值 |
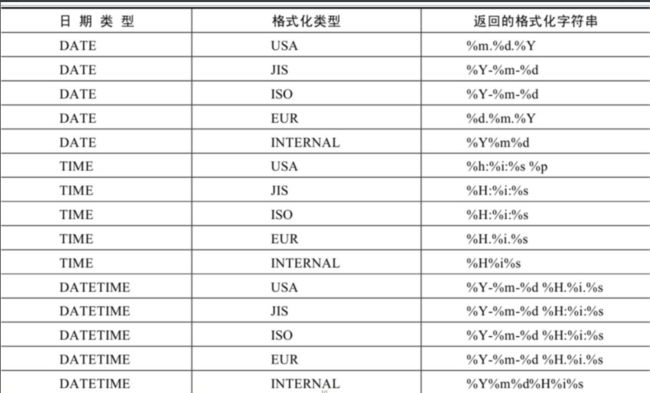
| GET_FORMAT(date_type,format_type) | 返回日期字符串的显示格式 |
| STR_TO_DATE(str, fmt) | 按照字符串fmt对str进行解析,解析为一个日期 |
非GET_FORMAT 函数中fmt参数常用的格式符:
| 格式符 | 说明 | 格式符 | 说明 |
|---|---|---|---|
| %Y | 4位数字表示年份 | %y | 表示两位数字表示年份 |
| %M | 月名表示月份(January,…) | %m | 两位数字表示月份(01,02,03。。。) |
| %b | 缩写的月名(Jan.,Feb.,…) | ||
| %c | 数字表示月份(1,2,3,…) | ||
| %D | 英文后缀表示月中的天数(1st,2nd,3rd,…) | %d | 两位数字表示月中的天数(01,02…) |
| %e | 数字形式表示月中的天数(1,2,3,4,5…) | ||
| %H | 两位数字表示小数,24小时制(01,02…) | %h和%I | 两位数字表示小时,12小时制(01,02…) |
| %k | 数字形式的小时,24小时制(1,2,3) | ||
| %l | 数字形式表示小时,12小时制(1,2,3,4…) | %i | 两位数字表示分钟(00,01,02) |
| %S和%s | 两位数字表示秒(00,01,02…) | ||
| %W | 一周中的星期名称(Sunday…) | %w | 以数字表示周中的天数(0=Sunday,1=Monday…) |
| %a | 一周中的星期缩写(Sun.,Mon.,Tues.,…) | ||
| %j | 以3位数字表示年中的天数(001,002…) | ||
| %U | 以数字表示年中的第几周,(1,2,3。。)其中Sunday为周中第一 天 | %u | 以数字表示年中的第几周,(1,2,3。。)其中Monday为周中第一天 |
| %T | 24小时制 | %r | 12小时制 |
| %p | AM或PM | %% | 表示% |
GET_FORMAT函数中date_type和format_type参数取值如下:
mysql> SELECT DATE_FORMAT(NOW(), '%H:%i:%s');
+--------------------------------+
| DATE_FORMAT(NOW(), '%H:%i:%s') |
+--------------------------------+
| 22:57:34 |
+--------------------------------+
1 row in set (0.00 sec)
SELECT STR_TO_DATE('09/01/2009','%m/%d/%Y') FROM DUAL;
SELECT STR_TO_DATE('20140422154706','%Y%m%d%H%i%s') FROM DUAL;
SELECT STR_TO_DATE('2014-04-22 15:47:06','%Y-%m-%d %H:%i:%s') FROM DUAL;
mysql> SELECT STR_TO_DATE('2020-01-01 00:00:00','%Y-%m-%d');
+-----------------------------------------------+
| STR_TO_DATE('2020-01-01 00:00:00','%Y-%m-%d') |
+-----------------------------------------------+
| 2020-01-01 |
+-----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
9.4 数值函数
9.4.1 基本函数
| 函数 | 用法 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SIGN(X) | 返回X的符号。正数返回1,负数返回-1,0返回0 |
| PI() | 返回圆周率的值 |
| CEIL(x),CEILING(x) | 返回大于或等于某个值的最小整数 |
| FLOOR(x) | 返回小于或等于某个值的最大整数 |
| LEAST(e1,e2,e3…) | 返回列表中的最小值 |
| GREATEST(e1,e2,e3…) | 返回列表中的最大值 |
| MOD(x,y) | 返回X除以Y后的余数 |
| RAND() | 返回0~1的随机值 |
| RAND(x) | 返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机数 |
| ROUND(x) | 返回一个对x的值进行四舍五入后,最接近于X的整数 |
| ROUND(x,y) | 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| SQRT(x) | 返回x的平方根。当X的值为负数时,返回NULL |
SELECT
ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(
32.32),
FLOOR(-43.23),MOD(12,5)
FROM DUAL;
SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
FROM DUAL;
SELECT
ROUND(12.33),ROUND(12.343,2),ROUND(12.324,-1),TRUNCATE(12.66,1),TRUNCATE(12.
66,-1)
FROM DUAL;
9.4.2 三角函数
| 函数 | 用法 |
|---|---|
| SIN(x) | 返回x的正弦值,其中,参数x为弧度值 |
| ASIN(x) | 返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| COS(x) | 返回x的余弦值,其中,参数x为弧度值 |
| ACOS(x) | 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) | 返回x的正切值,其中,参数x为弧度值 |
| ATAN(x) | 返回x的反正切值,即返回正切值为x的值 |
| ATAN2(m,n) | 返回两个参数的反正切值 |
| COT(x) | 返回x的余切值,其中,X为弧度值 |
SELECT
SIN(RADIANS(30)),DEGREES(ASIN(1)),TAN(RADIANS(45)),DEGREES(ATAN(1)),DEGREES(A
TAN2(1,1)
FROM DUAL;
9.4.3 角度与弧度互换函数
| 函数 | 用法 |
|---|---|
| RADIANS(x) | 将角度转化为弧度,其中,参数x为角度值 |
| DEGREES(x) | 将弧度转化为角度,其中,参数x为弧度值 |
9.4.4 三角函数
| 函数 | 用法 |
|---|---|
| SIN(x) | 返回x的正弦值,其中,参数x为弧度值 |
| ASIN(x) | 返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| COS(x) | 返回x的余弦值,其中,参数x为弧度值 |
| ACOS(x) | 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) | 返回x的正切值,其中,参数x为弧度值 |
| ATAN(x) | 返回x的反正切值,即返回正切值为x的值 |
| ATAN2(m,n) | 返回两个参数的反正切值 |
| COT(x) | 返回x的余切值,其中,X为弧度值 |
9.4.5 指数和对数
| 函数 | 用法 |
|---|---|
| POW(x,y),POWER(X,Y) | 返回x的y次方 |
| EXP(X) | 返回e的X次方,其中e是一个常数,2.718281828459045 |
| LN(X),LOG(X) | 返回以e为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG10(X) | 返回以10为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG2(X) | 返回以2为底的X的对数,当X <= 0 时,返回NULL |
9.4.6 进制间的转换
| 函数 | 用法 |
|---|---|
| BIN(x) | 返回x的二进制编码 |
| HEX(x) | 返回x的十六进制编码 |
| OCT(x) | 返回x的八进制编码 |
| CONV(x,f1,f2) | 返回f1进制数变成f2进制数 |
9.5 流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数
| 函数 | 用法 |
|---|---|
| IF(value,value1,value2) | 如果value的值为TRUE,返回value1, 否则返回value2 |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否 则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 … [ELSE resultn] END | 相当于Java的if…else if…else… |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1THEN 值1 … [ELSE 值n] END | 相当于Java的switch…case |
SELECT IF(1 > 0,'正确','错误')
->正确
SELECT IFNULL(null,'Hello Word')
->Hello Word
SELECT CASE 1
WHEN 1 THEN '我是1'
WHEN 2 THEN '我是2'
ELSE '你是谁'
SELECT oid,`status`, CASE `status` WHEN 1 THEN '未付款'
WHEN 2 THEN '已付款'
WHEN 3 THEN '已发货'
WHEN 4 THEN '确认收货'
ELSE '无效订单' END
FROM t_order;
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;
9.6 加密与解密函数
加密与解密函数主要用于对数据库中的数据进行加密和解密处理,以防止数据被他人窃取。这些函数在保证数据库安全时非常有用
| 函数 | 用法 |
|---|---|
| PASSWORD(str) | 返回字符串str的加密版本,41位长的字符串。加密结果 不可逆 ,常用于用户的密码加密 |
| MD5(str) | 返回字符串str的md5加密后的值,也是一种加密方式。若参数为 NULL,则会返回NULL |
| SHA(str) | 从原明文密码str计算并返回加密后的密码字符串,当参数为NULL时,返回NULL。 SHA加密算法比MD5更加安全 。 |
| ENCODE(value,password_seed) | 返回使用password_seed作为加密密码加密value |
| DECODE(value,password_seed) | 返回使用password_seed作为加密密码解密value |
mysql> SELECT PASSWORD('mysql'), PASSWORD(NULL);
+-------------------------------------------+----------------+
| PASSWORD('mysql') | PASSWORD(NULL) |
+-------------------------------------------+----------------+
| *E74858DB86EBA20BC33D0AECAE8A8108C56B17FA | |
+-------------------------------------------+----------------+
1 row in set, 1 warning (0.00 sec)
SELECT md5('123')
->202cb962ac59075b964b07152d234b70
SELECT SHA('Tom123')
->c7c506980abc31cc390a2438c90861d0f1216d50
mysql> SELECT ENCODE('mysql', 'mysql');
+--------------------------+
| ENCODE('mysql', 'mysql') |
+--------------------------+
| íg ¼ ìÉ |
+--------------------------+
1 row in set, 1 warning (0.01 sec)
mysql> SELECT DECODE(ENCODE('mysql','mysql'),'mysql');
+-----------------------------------------+
| DECODE(ENCODE('mysql','mysql'),'mysql') |
+-----------------------------------------+
| mysql |
+-----------------------------------------+
1 row in set, 2 warnings (0.00 sec)
9.7 MySQL信息函数
MySQL中内置了一些可以查询MySQL信息的函数,这些函数主要用于帮助数据库开发或运维人员更好地对数据库进行维护工作。
| 函数 | 用法 |
|---|---|
| VERSION() | 返回当前MySQL的版本号 |
| CONNECTION_ID() | 返回当前MySQL服务器的连接数 |
| DATABASE(),SCHEMA() | 返回MySQL命令行当前所在的数据库 |
| USER(),CURRENT_USER()、SYSTEM_USER(), SESSION_USER() | 返回当前连接MySQL的用户名,返回结果格式为 “主机名@用户名” |
| CHARSET(value) | 返回字符串value自变量的字符集 |
| COLLATION(value) | 返回字符串value的比较规则 |
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| test |
+------------+
1 row in set (0.00 sec)
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| test |
+------------+
1 row in set (0.00 sec)
mysql> SELECT USER(), CURRENT_USER(), SYSTEM_USER(),SESSION_USER();
+----------------+----------------+----------------+----------------+
| USER() | CURRENT_USER() | SYSTEM_USER() | SESSION_USER() |
+----------------+----------------+----------------+----------------+
| root@localhost | root@localhost | root@localhost | root@localhost |
+----------------+----------------+----------------+----------------+
mysql> SELECT CHARSET('ABC');
+----------------+
| CHARSET('ABC') |
+----------------+
| utf8mb4 |
+----------------+
1 row in set (0.00 sec)
mysql> SELECT COLLATION('ABC');
+--------------------+
| COLLATION('ABC') |
+--------------------+
| utf8mb4_general_ci |
+--------------------+
1 row in set (0.00 sec)
10 聚合函数
10.1 聚合函数介绍
10.1.1 什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
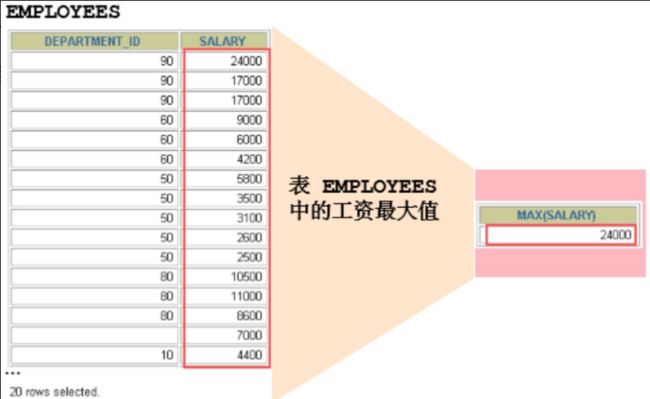
10.1.2 聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
10.1.3 聚合函数语法

10.1.4 AVG和SUM函数
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
可以对数值型数据使用AVG 和 SUM 函数。
10.1.5 MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;
10.1.6 COUNT函数
COUNT()返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
COUNT(expr) 返回expr不为空的记录总数。
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
- 用count(*),count(1),count(列名)谁好呢?
- 其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
- 能不能使用count(列名)替换count(*)?
- 不要使用 count(列名)来替代 count() , count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
- 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
10.2 GROUP BY
10.2.1 基本使用
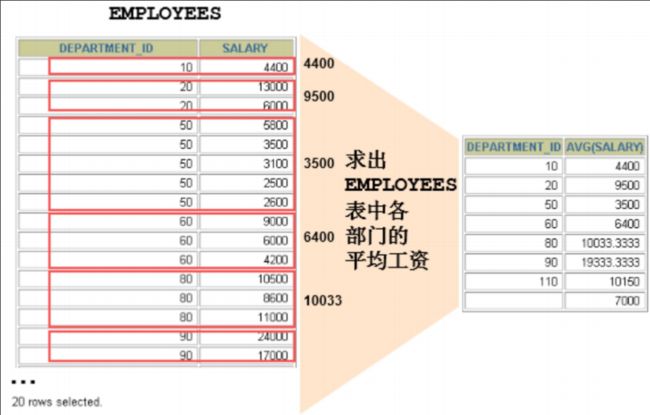
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
注意: WHERE一定放在FROM后面
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
10.2.2 使用多个列分组
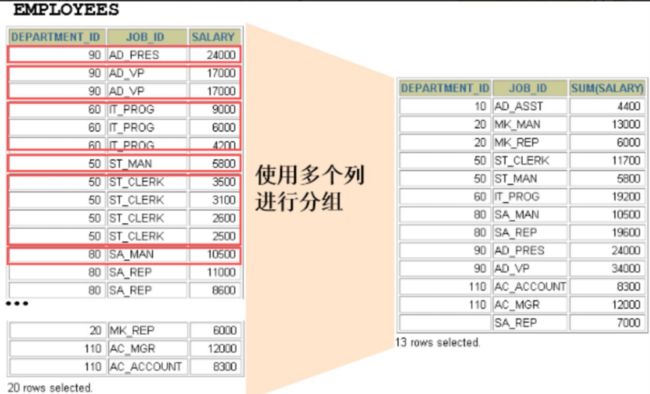
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;
10.2.3 GROUP BY中使用WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT department_id,AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;
注意: 当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
10.3 HAVING
10.3.1 基本使用
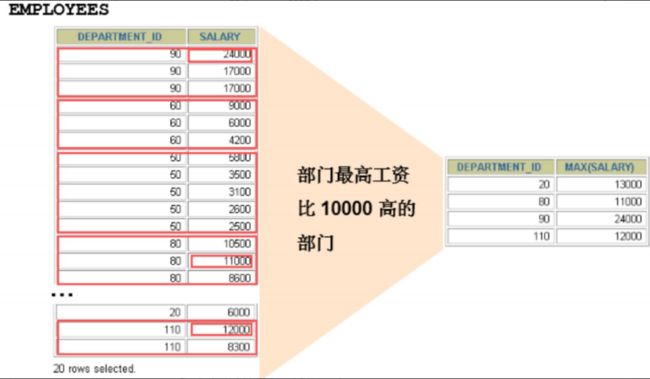
过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。

ELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000
GROUP BY department_id;
#报错
10.3.2 WHERE和HAVING的对比
- 区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。 这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
- 区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。 因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
| 参数 | 优点 | 缺点 |
|---|---|---|
| WHERE | 先筛选数据再关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率较低 |
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
10.4 SELECT的执行过程
10.4.1 查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分
10.4.2 SELECT执行顺序
- 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT... 1
- SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
案例演示:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个 虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入。 需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
11 子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入。
SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
11.1 子查询简介
案例:有谁比Abel工资高
#方式一:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
#方式二:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
#方式三:子查询
SELECT last_name,salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
11.1.2 子查询的基本使用
子查询的基本语法结构:
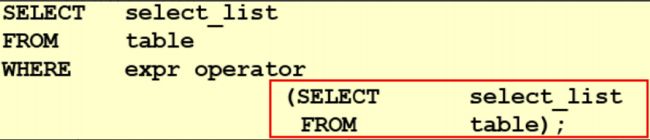
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
11.1.3 子查询的分类
按内查询的结果返回一条还是多条记录,将子查询分为 单行子查询 、 多行子查询 。
-
单行子查询

-
多行子查询

11.2 单行子查询
11.2.1 单行比较操作符
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
案例演示
案例一:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name, job_id, salary
FROM employees
WHERE job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 141)
AND salary >
(SELECT salary
FROM employees
WHERE employee_id = 143);
案例二:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees);
11.2.2 HAVING中使用子查询
案例:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) >
(SELECT MIN(salary)
FROM employees
WHERE department_id = 50);
11.3 多行子查询
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
案例:查询平均工资最低的部门id
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
)
12 创建和管理表
12.1 基础知识
12.1.1 一条数据存储的过程
存储数据是处理数据的第一步 。只有正确地把数据存储起来,我们才能进行有效的处理和分析。否则,只能是一团乱麻,无从下手。
那么,怎样才能把用户各种经营相关的、纷繁复杂的数据,有序、高效地存储起来呢? 在 MySQL 中,一个完整的数据存储过程总共有 4 步,分别是创建数据库、确认字段、创建数据表、插入数据。

从系统架构的层次上看,MySQL 数据库系统从大到小依次是 数据库服务器 、 数据库 、 数据表 、数据表的 行与列 。
MySQL 数据库服务器之前已经安装。所以,我们就从创建数据库开始。
12.1.2 标识符命名规则
- 数据库名、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来
- 保持字段名和类型的一致性:在命名字段并为其指定数据类型的时候一定要保证一致性,假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
12.1.3 MySQL中的数据类型
| 类型 | 类型举例 |
|---|---|
| 整数类型 | TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT |
| 浮点类型 | FLOAT、DOUBLE |
| 定点数类型 | DECIMAL |
| 位类型 | BIT |
| 日期时间类型 | YEAR、TIME、DATE、DATETIME、TIMESTAMP |
| 文本字符串类型 | CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT |
| 枚举类型 | ENUM |
| 集合类型 | SET |
| 二进制字符串类 型 | BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB |
| JSON类型 | JSON对象、JSON数组 |
| 空间数据类型 | 单值:GEOMETRY、POINT、LINESTRING、POLYGON; 集合:MULTIPOINT、MULTILINESTRING、MULTIPOLYGON、 GEOMETRYCOLLECTION |
常用的几类类型如下:
| 数据类型 | 描述 |
|---|---|
| INT | 从-231到231-1的整型数据。存储大小为 4个字节 |
| CHAR(size) | 定长字符数据。若未指定,默认为1个字符,最大长度255 |
| VARCHAR(size) | 可变长字符数据,根据字符串实际长度保存,必须指定长度 |
| FLOAT(M,D) | 单精度,占用4个字节,M=整数位+小数位,D=小数位。D<=M<=255,0<=D<=30, 默认M+D<=6 |
| DOUBLE(M,D) | 双精度,占用8个字节,D<=M<=255,0<=D<=30,默认M+D<=15 |
| DECIMAL(M,D) | 高精度小数,占用M+2个字节,D<=M<=65,0<=D<=30,最大取值范围与DOUBLE 相同。 |
| DATE | 日期型数据,格式’YYYY-MM-DD’ |
| BLOB | 二进制形式的长文本数据,最大可达4G |
| TEXT | 长文本数据,最大可达4G |
12.2 创建和管理数据库
12.2.1 创建数据库
方式1:创建数据库
CREATE DATABASE 数据库名;
方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
方式3:判断数据库是否已经存在,不存在则创建数据库( 推荐 )
CREATE DATABASE IF NOT EXISTS 数据库名;
如果MySQL中已经存在相关的数据库,则忽略创建语句,不再创建数据库。
注意: DATABASE 不能改名。一些可视化工具可以改名,它是建新库,把所有表复制到新库,再删旧库完成的。
12.2.2 使用数据库
查看当前所有的数据库
SHOW DATABASES; #有一个S,代表多个数据库
查看当前正在使用的数据库
SELECT DATABASE(); #使用的一个 mysql 中的全局函数
查看指定库下所有的表
SHOW TABLES FROM 数据库名;
查看数据库的创建信息
SHOW CREATE DATABASE 数据库名;
或者:
SHOW CREATE DATABASE 数据库名\G
使用/切换数据库
USE 数据库名;
注意:要操作表格和数据之前必须先说明是对哪个数据库进行操作,否则就要对所有对象加上“数据库名.”。
12.2.3 修改数据库
更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
12.2.4 删除数据库
方式1:删除指定的数据库
DROP DATABASE 数据库名;
方式2:删除指定的数据库( 推荐 )
DROP DATABASE IF EXISTS 数据库名;
12.3 创建表
12.3.1 创建方式一
- 必须具备:
- CREATE TABLE权限
- 存储空间
- 语法格式:
CREATE TABLE [IF NOT EXISTS] 表名(
字段1, 数据类型 [约束条件] [默认值],
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
加上了IF NOT EXISTS关键字,则表示:如果当前数据库中不存在要创建的数据表,则创建数据表;如果当前数据库中已经存在要创建的数据表,则忽略建表语句,不再创建数据表。
- 必须指定:
- 表名
- 列名(或字段名),数据类型,长度
- 可选指定:
- 约束条件
- 默认值
- 创建表举例1:
-- 创建表
CREATE TABLE emp (
-- int类型
emp_id INT,
-- 最多保存20个中英文字符
emp_name VARCHAR(20),
-- 总位数不超过15位
salary DOUBLE,
-- 日期类型
birthday DATE
);
MySQL在执行建表语句时,将id字段的类型设置为int(11),这里的11实际上是int类型指定的显示宽度,默认的显示宽度为11。也可以在创建数据表的时候指定数据的显示宽度。
- 创建表举例2:
CREATE TABLE dept(
-- int类型,自增
deptno INT(2) AUTO_INCREMENT,
dname VARCHAR(14),
loc VARCHAR(13),
-- 主键
PRIMARY KEY (deptno)
);
在MySQL 8.x版本中,不再推荐为INT类型指定显示长度,并在未来的版本中可能去掉这样的语法。
12.3.2 创建方式二
使用 AS subquery 选项,将创建表和插入数据结合起来

- 指定的列和子查询中的列要一一对应
- 通过列名和默认值定义列
CREATE TABLE emp1 AS SELECT * FROM employees;
CREATE TABLE emp2 AS SELECT * FROM employees WHERE 1=2; -- 创建的emp2是空表
CREATE TABLE dept80
AS
SELECT employee_id, last_name, salary*12 ANNSAL, hire_date
FROM employees
WHERE department_id = 80;
DESCRIBE dept80;
12.3.3 查看数据表结构
在MySQL中创建好数据表之后,可以查看数据表的结构。MySQL支持使用 DESCRIBE/DESC 语句查看数据表结构,也支持使用 SHOW CREATE TABLE 语句查看数据表结构。
语法格式:
SHOW CREATE TABLE 表名\G
使用SHOW CREATE TABLE语句不仅可以查看表创建时的详细语句,还可以查看存储引擎和字符编码。
12.4 修改表
修改表指的是修改数据库中已经存在的数据表的结构。
使用 ALTER TABLE 语句可以实现:
- 向已有的表中添加列
- 修改现有表中的列
- 删除现有表中的列
- 重命名现有表中的列
12.4.1 追加一个列
语法格式
ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
案例
ALTER TABLE dept80
ADD job_id varchar(15);
12.4.2 修改一个列
- 可以修改列的数据类型,长度、默认值和位置
语法格式
ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER字段名2】;
案例
ALTER TABLE dept80 MODIFY last_name VARCHAR(30);
ALTER TABLE dept80 MODIFY salary double(9,2) default 1000;
- 对默认值的修改只影响今后对表的修改
- 此外,还可以通过此种方式修改列的约束。
12.4.3 重命名一个列
- 使用 CHANGE old_column new_column dataType子句重命名列。
语法格式
ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
案例
ALTER TABLE dept80 CHANGE department_name dept_name varchar(15);
12.4.4 删除一个列
- 删除表中某个字段
语法格式
ALTER TABLE 表名 DROP 【COLUMN】字段名
案例
ALTER TABLE dept80 DROP COLUMN job_id;
12.5 重命名表
方式一:使用RENAME
RENAME TABLE emp TO myemp;
方式二:
ALTER table dept RENAME [TO] detail_dept; -- [TO]可以省略
注意:必须是对象的拥有者
12.6 删除表
- 在MySQL中,当一张数据表 没有与其他任何数据表形成关联关系 时,可以将当前数据表直接删除。
- 数据和结构都被删除
- 所有正在运行的相关事务被提交
- 所有相关索引被删除
- 语法格式:
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
IF EXISTS 的含义为:如果当前数据库中存在相应的数据表,则删除数据表;如果当前数据库中不存在相应的数据表,则忽略删除语句,不再执行删除数据表的操作。
- 案例:
DROP TABLE dept80;
- DROP TABLE 语句不能回滚
12.7 清空表
- TRUNCATE TABLE语句:
- 删除表中所有的数据
- 释放表的存储空间
- 举例:
TRUNCATE TABLE detail_dept;
- TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
阿里开发规范: 【参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但TRUNCATE无事务且不触发 TRIGGER,有可能造成事故,故不建议在开发代码中使用此语句。 说明:TRUNCATE TABLE
在功能上与不带 WHERE 子句的 DELETE 语句相同。
12.8 内容拓展
12.8.1 阿里巴巴《Java开发手册》之MySQL字段命名
- 【 强制 】表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
- 正例:aliyun_admin,rdc_config,level3_name
- 反例:AliyunAdmin,rdcConfig,level_3_name
- 【 强制 】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
- 【 强制 】表必备三字段:id, gmt_create, gmt_modified。
- 说明:其中 id 必为主键,类型为BIGINT UNSIGNED、单表时自增、步长为 1。gmt_create,gmt_modified 的类型均为 DATETIME 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新
- 【 推荐 】表的命名最好是遵循 “业务名称_表的作用”。
- 正例:alipay_task 、 force_project、 trade_config
- 【 推荐 】库名与应用名称尽量一致。
- 【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。
- 正例:无符号值可以避免误存负数,且扩大了表示范围。
12.8.2 拓展2:如何理解清空表、删除表等操作需谨慎?!
表删除 操作将把表的定义和表中的数据一起删除,并且MySQL在执行删除操作时,不会有任何的确认信息提示,因此执行删除操时应当慎重。在删除表前,最好对表中的数据进行 备份 ,这样当操作失误时可以对数据进行恢复,以免造成无法挽回的后果。
同样的,在使用 ALTER TABLE 进行表的基本修改操作时,在执行操作过程之前,也应该确保对数据进行完整的 备份 ,因为数据库的改变是 无法撤销 的,如果添加了一个不需要的字段,可以将其删除;相同的,如果删除了一个需要的列,该列下面的所有数据都将会丢失。
13 数据处理之增删改
13.1 插入数据
13.1.1 VALUES的方式添加
使用这种语法一次只能向表中插入一条数据。
情况1:为表的所有字段按默认顺序插入数据
INSERT INTO 表名
VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
案例:
INSERT INTO departments
VALUES (70, 'Pub', 100, 1700);
INSERT INTO departments
VALUES (100, 'Finance', NULL, NULL);
情况2:为表的指定字段插入数据
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
在 INSERT子句中随意列出列名,但是一旦列出,VALUES中要插入的value1,…valuen需要与column1,…columnn列一一对应。如果类型不同,将无法插入,并且MySQL会产生错误。
案例:
INSERT INTO departments(department_id, department_name)
VALUES (80, 'IT');
情况3:同时插入多条记录
INSERT语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号分隔开,基本语法格式如下:
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
或者
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
案例:
mysql> INSERT INTO emp(emp_id,emp_name)
-> VALUES (1001,'shkstart'),
-> (1002,'atguigu'),
-> (1003,'Tom');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
使用INSERT同时插入多条记录时,MySQL会返回一些在执行单行插入时没有的额外信息,这些信息的含义如下:
- Records:表明插入的记录条数。
- Duplicates:表明插入时被忽略的记录,原因可能是这些记录包含了重复的主键值。
- Warnings:表明有问题的数据值,例如发生数据类型转换。
13.1.2 将查询结果插入到表中
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入多行。
基本语法格式如下:
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
案例:
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
13.2 更新数据
使用 UPDATE 语句更新数据。语法如下:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
- 使用 WHERE 子句指定需要更新的数据。
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
- 如果省略 WHERE 子句,则表中的所有数据都将被更新。
UPDATE copy_emp
SET department_id = 110;
13.3 删除数据
DELETE FROM departments
WHERE department_name = 'Finance';
DELETE FROM departments
WHERE department_id = 60;
14 约束(constraint)
14.1 约束概述
14.1.1 1. 为什么需要约束
数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。
为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制。从以下四个方面考虑:
- 实体完整性(Entity Integrity) :例如,同一个表中,不能存在两条完全相同无法区分的记录
- 域完整性(Domain Integrity) :例如:年龄范围0-120,性别范围“男/女”
- 引用完整性(Referential Integrity) :例如:员工所在部门,在部门表中要能找到这个部门
- 用户自定义完整性(User-defined Integrity) :例如:用户名唯一、密码不能为空等,本部门经理的工资不得高于本部门职工的平均工资的5倍。
14.1.2 什么是约束
约束是表级的强制规定。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。
14.1.3 3. 约束的分类
- 根据约束数据列的限制,约束可分为:
- 单列约束:每个约束只约束一列
- 多列约束:每个约束可约束多列数据
- 根据约束的作用范围,约束可分为:
- 列级约束:只能作用在一个列上,跟在列的定义后面
- 表级约束:可以作用在多个列上,不与列一起,而是单独定义
- 根据约束起的作用,约束可分为:
- NOT NULL 非空约束,规定某个字段不能为空
- UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
- PRIMARY KEY 主键(非空且唯一)约束
- FOREIGN KEY 外键约束
- CHECK 检查约束
- DEFAULT 默认值约束
14.2 非空约束
14.2.1 建表时
语法格式
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);
案例
CREATE TABLE emp(
id INT(10) NOT NULL,
NAME VARCHAR(20) NOT NULL,
sex CHAR NULL
);
CREATE TABLE student(
sid int,
sname varchar(20) not null,
tel char(11) ,
cardid char(18) not null
);
insert into student values(1,'张三','13710011002','110222198912032545'); #成功
insert into student values(2,'李四','13710011002',null);#身份证号为空
ERROR 1048 (23000): Column 'cardid' cannot be null
insert into student values(2,'李四',null,'110222198912032546');#成功,tel允许为空
insert into student values(3,null,null,'110222198912032547');#失败
ERROR 1048 (23000): Column 'sname' cannot be null
14.2.2 建表后
语法规范
alter table 表名称 modify 字段名 数据类型 not null;
案例
ALTER TABLE emp MODIFY sex VARCHAR(30) NOT NULL;
alter table student modify sname varchar(20) not null;
14.2.3 删除非空约束
ALTER TABLE emp MODIFY sex VARCHAR(30) NULL;
ALTER TABLE emp MODIFY NAME VARCHAR(15) DEFAULT 'abc' NULL;
14.3 唯一性约束
14.3.1 建表时
语法规范
create table 表名称(
字段名 数据类型,
字段名 数据类型 unique,
字段名 数据类型 unique key,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] unique key(字段名)
);
案例
create table student(
sid int,
sname varchar(20),
tel char(11) unique,
cardid char(18) unique key
);
CREATE TABLE t_course(
cid INT UNIQUE,
cname VARCHAR(100) UNIQUE,
description VARCHAR(200)
);
CREATE TABLE USER(
id INT NOT NULL,
NAME VARCHAR(25),
PASSWORD VARCHAR(16),
-- 使用表级约束语法
CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD)
);
insert into student values(1,'张三','13710011002','101223199012015623');
insert into student values(2,'李四','13710011003','101223199012015624');
insert into student values(3,'王五','13710011004','101223199012015624'); #身份证号重复
ERROR 1062 (23000): Duplicate entry '101223199012015624' for key 'cardid'
insert into student values(3,'王五','13710011003','101223199012015625');
ERROR 1062 (23000): Duplicate entry '13710011003' for key 'tel
14.3.2 建表后指定唯一键约束
语法规范
#字段列表中如果是一个字段,表示该列的值唯一。如果是两个或更多个字段,那么复合唯一,即多个字段的组合是唯一的
#方式1:
alter table 表名称 add unique key(字段列表);
#方式2:
alter table 表名称 modify 字段名 字段类型 unique;
案例
create table student(
sid int primary key,
sname varchar(20),
tel char(11) ,
cardid char(18)
);
alter table student add unique key(tel);
alter table student add unique key(cardid);
14.3.3 关于复合唯一约束
语法规范
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
unique key(字段列表) #字段列表中写的是多个字段名,多个字段名用逗号分隔,表示那么是复合唯一,即多个字段的组合是唯一的
);
案例
#学生表
create table student(
sid int, #学号
sname varchar(20), #姓名
tel char(11) unique key, #电话
cardid char(18) unique key #身份证号
);
#课程表
create table course(
cid int, #课程编号
cname varchar(20) #课程名称
);
#选课表
create table student_course(
id int,
sid int,
cid int,
score int,
unique key(sid,cid) #复合唯一
);
insert into student values(1,'张三','13710011002','101223199012015623');#成功
insert into student values(2,'李四','13710011003','101223199012015624');#成功
insert into course values(1001,'Java'),(1002,'MySQL');#成功
insert into student_course values
(1, 1, 1001, 89),
(2, 1, 1002, 90),
(3, 2, 1001, 88),
(4, 2, 1002, 56);#成功
insert into student_course values (5, 1, 1001, 88);#失败
14.3.4 删除唯一约束
SELECT * FROM information_schema.table_constraints WHERE table_name = '表名';
#查看都有哪些约束
#删除唯一索引
ALTER TABLE USER DROP INDEX uk_name_pwd;
14.4 PRIMARY KEY 约束
14.4.1 作用
用来唯一标识表中的一行记录。
14.4.2 关键字
primary key
14.4.3 特点
主键约束相当于唯一约束+非空约束的组合,主键约束列不允许重复,也不允许出现空值。

- 一个表最多只能有一个主键约束,建立主键约束可以在列级别创建,也可以在表级别上创建。
- 主键约束对应着表中的一列或者多列(复合主键)
- 如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复。
- MySQL的主键名总是PRIMARY,就算自己命名了主键约束名也没用。
- 当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引(能够根据主键查询的,就根据主键查询,效率更高)。如果删除主键约束了,主键约束对应的索引就自动删除了。
- 需要注意的一点是,不要修改主键字段的值。因为主键是数据记录的唯一标识,如果修改了主键的值,就有可能会破坏数据的完整性。
14.4.4 添加主键约束
建表时指定主键约束
语法规范
create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] primary key(字段名) #表级模式
);
案例
create table temp(
id int primary key,
name varchar(20)
)
mysql> desc temp;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
insert into temp values(1,'张三');#成功
insert into temp values(2,'李四');#成功
mysql> select * from temp;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 李四 |
+----+------+
2 rows in set (0.00 sec)
insert into temp values(1,'张三');#失败
ERROR 1062 (23000): Duplicate(重复) entry(键入,输入) '1' for key 'PRIMARY'
insert into temp values(1,'王五');#失败
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
insert into temp values(3,'张三');#成功
mysql> select * from temp;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 张三 |
+----+------+
3 rows in set (0.00 sec)
insert into temp values(4,null);#成功
insert into temp values(null,'李琦');#失败
ERROR 1048 (23000): Column 'id' cannot be null
列级约束
CREATE TABLE emp4(
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR(20)
)
表级约束
CREATE TABLE emp5(
id INT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20),
pwd VARCHAR(15),
CONSTRAINT emp5_id_pk PRIMARY KEY(id)
);
建表后增加主键约束
语法规范
ALTER TABLE 表名称 ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字段,如果是多个字段的话,是复合主键
案例
ALTER TABLE student ADD PRIMARY KEY (sid);
ALTER TABLE emp5 ADD PRIMARY KEY(NAME,pwd);
关于复合主键
语法规范
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
primary key(字段名1,字段名2) #表示字段1和字段2的组合是唯一的,也可以有更多个字段
);
案例
#学生表
create table student(
sid int primary key, #学号
sname varchar(20) #学生姓名
);
#课程表
create table course(
cid int primary key, #课程编号
cname varchar(20) #课程名称
);
#选课表
create table student_course(
sid int,
cid int,
score int,
primary key(sid,cid) #复合主键
);
insert into student values(1,'张三'),(2,'李四');
insert into course values(1001,'Java'),(1002,'MySQL');
mysql> select * from student;
+-----+-------+
| sid | sname |
+-----+-------+
| 1 | 张三 |
| 2 | 李四 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> select * from course;
+------+-------+
| cid | cname |
+------+-------+
| 1001 | Java |
| 1002 | MySQL |
+------+-------+
2 rows in set (0.00 sec)
insert into student_course values(1, 1001, 89),(1,1002,90),(2,1001,88),(2,1002,56);
mysql> select * from student_course;
+-----+------+-------+
| sid | cid | score |
+-----+------+-------+
| 1 | 1001 | 89 |
| 1 | 1002 | 90 |
| 2 | 1001 | 88 |
| 2 | 1002 | 56 |
+-----+------+-------+
4 rows in set (0.00 sec)
insert into student_course values(1, 1001, 100);
ERROR 1062 (23000): Duplicate entry '1-1001' for key 'PRIMARY'
删除主键约束
语法规范
alter table 表名称 drop primary key;
案例
ALTER TABLE student DROP PRIMARY KEY;
ALTER TABLE emp5 DROP PRIMARY KEY;
14.5 自增列:AUTO_INCREMENT
14.5.1 作用
某个字段的值自增
14.5.2 关键字
auto_increment
14.5.3 特点和要求
- 一个表最多只能有一个自增长列
- 当需要产生唯一标识符或顺序值时,可设置自增长
- 自增长列约束的列必须是键列(主键列,唯一键列)
- 自增约束的列的数据类型必须是整数类型
- 如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值。
14.5.4 如何指定自增约束
建表时
语法规范
create table 表名称(
字段名 数据类型 primary key auto_increment,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 unique key auto_increment,
字段名 数据类型 not null default 默认值,,
primary key(字段名)
);
案例
create table employee(
eid int primary key auto_increment,
ename varchar(20)
);
mysql> desc employee;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| eid | int(11) | NO | PRI | NULL | auto_increment |
| ename | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
建表后
语法规范
alter table 表名称 modify 字段名 数据类型 auto_increment;
案例
create table employee(
eid int primary key ,
ename varchar(20)
)
alter table employee modify eid int auto_increment;
mysql> desc employee;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| eid | int(11) | NO | PRI | NULL | auto_increment |
| ename | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
14.5.5 如何删除自增约束
alter table 表名称 modify 字段名 数据类型; #去掉auto_increment相当于删除
alter table employee modify eid int;
mysql> desc employee;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| eid | int(11) | NO | PRI | NULL | |
| ename | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
14.5.6 重置auto_increment
#方式一
delete from tb1;
ALTER TABLE tbl AUTO_INCREMENT = 100;
#方式二
truncate tb1; #(好处, 简单, AUTO_INCREMENT 值重新开始计数.)
14.6 FOREIGN KEY 约束
14.6.1 作用
限定某个表的某个字段的引用完整性。
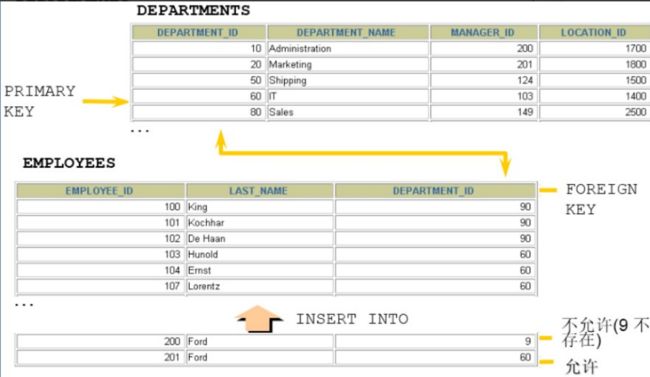
比如:员工表的员工所在部门的选择,必须在部门表能找到对应的部分。
14.6.2 关键字
FOREIGN KEY
14.6.3 主表和从表/父表和子表
主表(父表):被引用的表,被参考的表
从表(子表):引用别人的表,参考别人的表
例如:员工表的员工所在部门这个字段的值要参考部门表:部门表是主表,员工表是从表。
例如:学生表、课程表、选课表:选课表的学生和课程要分别参考学生表和课程表,学生表和课程表是
主表,选课表是从表。
14.6.4 特点
(1)从表的外键列,必须引用/参考主表的主键或唯一约束的列
(2)在创建外键约束时,如果不给外键约束命名,默认名不是列名,而是自动产生一个外键名(例如student_ibfk_1;),也可以指定外键约束名。
(3)创建(CREATE)表时就指定外键约束的话,先创建主表,再创建从表
(4)删表时,先删从表(或先删除外键约束),再删除主表
(5)当主表的记录被从表参照时,主表的记录将不允许删除,如果要删除数据,需要先删除从表中依赖
该记录的数据,然后才可以删除主表的数据
(6)在“从表”中指定 外键约束,并且一个表可以建立多个外键约束
(7)从表的外键列与主表被参照的列名字可以不相同,但是数据类型必须一样,逻辑意义一致。如果类型不一样,创建子表时,就会出现错误“ERROR 1005 (HY000): Can’t create table’database.tablename’(errno: 150)”。
(8)当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是外键的约束名。(根据外键查询效率很高)
(9)删除外键约束后,必须 手动 删除对应的索引
14.6.5 添加外键约束
建表时
语法规范
create table 主表名称(
字段1 数据类型 primary key,
字段2 数据类型
);
create table 从表名称(
字段1 数据类型 primary key,
字段2 数据类型,
[CONSTRAINT <外键约束名称>] FOREIGN KEY(从表的某个字段) references 主表名(被参考字段)
);
#(从表的某个字段)的数据类型必须与主表名(被参考字段)的数据类型一致,逻辑意义也一样
#(从表的某个字段)的字段名可以与主表名(被参考字段)的字段名一样,也可以不一样
-- FOREIGN KEY: 在表级指定子表中的列
-- REFERENCES: 标示在父表中的列
案例
create table dept( #主表
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(#从表
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) #在从表中指定外键约束
#emp表的deptid和和dept表的did的数据类型一致,意义都是表示部门的编号
);
说明:
(1)主表dept必须先创建成功,然后才能创建emp表,指定外键成功。
(2)删除表时,先删除从表emp,再删除主表dept
建表后
一般情况下,表与表的关联都是提前设计好了的,因此,会在创建表的时候就把外键约束定义好。不过,如果需要修改表的设计(比如添加新的字段,增加新的关联关系),但没有预先定义外键约束,那么,就要用修改表的方式来补充定义。
语法规范
ALTER TABLE 从表名 ADD [CONSTRAINT 约束名] FOREIGN KEY (从表的字段) REFERENCES 主表名(被引用字段) [on update xx][on delete xx];
案例
ALTER TABLE emp1 ADD [CONSTRAINT emp_dept_id_fk] FOREIGN KEY(dept_id)REFERENCES dept(dept_id);
create table dept(
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int #员工所在的部门
);
#这两个表创建时,没有指定外键的话,那么创建顺序是随意
alter table emp add foreign key (deptid) references dept(did);
14.6.6 约束等级
- Cascade方式 :在父表上update/delete记录时,同步update/delete掉子表的匹配记录
- Set null方式 :在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not null
- No action方式 :如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
- Restrict方式 :同no action, 都是立即检查外键约束
- Set default方式 (在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别
- 如果没有指定等级,就相当于Restrict方式。
14.6.7 阿里开发规范
【 强制 】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新
学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于
单机低并发 ,不适合 分布式 、 高并发集群 ;级联更新是强阻塞,存在数据库 更新风暴 的风险;外键
影响数据库的 插入速度 。
14.7 DEFAULT约束
14.7.1 作用
给某个字段/某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。
14.7.2 关键字
DEFAULT
如何给字段加默认值
建表时
语法规范
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
案例
create table employee(
eid int primary key,
ename varchar(20) not null,
gender char default '男',
tel char(11) not null default '' #默认是空字符串
);
insert into employee(eid,ename) values(2,'天琪'); #成功
mysql> select * from employee;
+-----+-------+--------+-------------+
| eid | ename | gender | tel |
+-----+-------+--------+-------------+
| 1 | 汪飞 | 男 | 13700102535 |
| 2 | 天琪 | 男 | |
+-----+-------+--------+-------------+
2 rows in set (0.00 sec)
建表后
语法规范
alter table 表名称 modify 字段名 数据类型 default 默认值;
#如果这个字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#同理,在给某个字段加非空约束也一样,如果这个字段原来有默认值约束,你想保留,也要在modify语句中保留默认值约束,否则就删除了
alter table 表名称 modify 字段名 数据类型 default 默认值 not null;
案例
create table employee(
eid int primary key,
ename varchar(20),
gender char,
tel char(11) not null
);
alter table employee modify gender char default '男'; #给gender字段增加默认值约束
alter table employee modify tel char(11) default ''; #给tel字段增加默认值约束