C++学习笔记(堆栈、指针、命名空间、编译步骤)
C++
- 1、堆和栈
- 2、指针
-
- 2.1、指针的本质
- 2.2、指针的意义
- 2.3、清空指针
- 2.4、C++类中的this
- 3、malloc and new
- 4、命名空间
-
- 4.1、创建命名空间
- 4.2、使用命名空间
- 5、编译程序的四个步骤
-
- 5.1、预处理
- 5.2、编译
- 5.3、汇编
- 5.4、链接
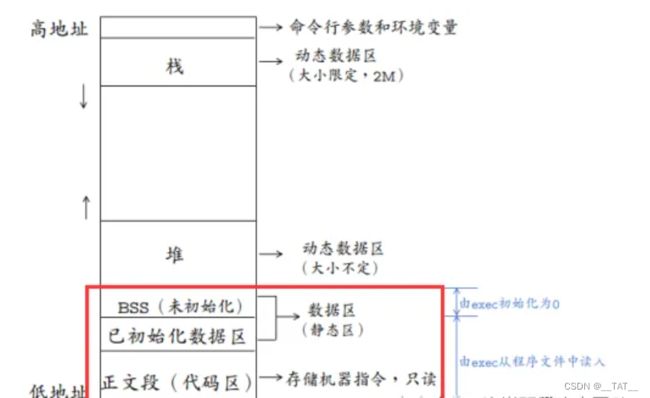
1、堆和栈
堆(heap)和栈(stack)都是一种内存空间。
栈空间的分配是由系统自动完成的,用来存放各种变量和寄存器,无论是全局变量还是局部变量,都存储在其中。同时每个程序线程都有属于自己的栈空间,用以保证之间互不干扰。
而在一个线程当中的每一个函数在被调用的时候,也会被分配一些属于自己的栈空间,用以存放该函数所用到的局部变量和一些必要的寄存器信息。当函数被调用结束,其对应的栈的空间也会被释放。因此,局部变量的生存周期终止于栈空间被释放。
堆空间的分配则需要人为干涉了,它可以用来存放一些临时变量,其空间相来说也大一些。更加不同于栈的一点是,堆是任何函数都可以访问的,不存在局限性。
2、指针
指针是C语言学习的时候用到,但这里再次记录一下,以便理解后面的内容。
2.1、指针的本质
指针是一种存放地址的特殊变量,它也有属于自己的地址。因此,指针并不等于地址!!!
我们可以通过以下代码查看指针存放的地址,以及指针本身的地址。
void main()
{
int *point;
printf("point's value is %p\n",point);
printf("point's address is %p\n",&point);
}
再通过以下几个例子可以进一步了解指针本质。
错误示例:
int *p;
*p = 9;
错误原因:这里p指针存放的是NULL的地址,所以这句代码相当于让NULL地址对应的变量(NULL)去存放9这个数。而NULL即是空,让空去存放东西,显然是错误的。
正确示例1:
int *p;
int a;
p = &a;
a = 9;
正确示例2:
int *p;
int a;
p = &a;
*p = 9;
正确原因:通过p=&a;这句代码让p指针存放a变量的地址,那么无论是直接修改a,还是通过地址索引a再修改之,结果都是一样的。
此外,由于在32为计算机,地址则占4个字节,在64位计算机中,地址占6个字节或8个字节的缘故,指针的大小也是其对应地址所占的空间。
2.2、指针的意义
指针可以说是C语言的灵魂,即便在C++当中也发挥着巨大的作用。以下对于指针的意义仅是我个人学习过程中的所感所获。
意义一:在大部分程序语言中,函数的返回值一般分为两种情况,一种是返回一个值,另一种则是返回一个地址。我们称之为传值和传址。而传址的目的,还是为了获得目标值,所以此时用到的就是指针的解引用功能。
当然,一般不再用return,也是在函数内直接调用另外一个目标函数,然后把地址作为参数传进去。如下例子。这样做的原因是为了避免在return之后,局部变量的生命中止,原地址被释放。
意义二:指针的存在,相当于提供了一个访问变量的新通道,通过指针,我们可以跨栈区去范围变量,当然也可以访问堆。下面讲malloc和new的时候会用到。
#include
void function_1(void);
void function_2(int *);
void function_1()
{
int i,temp[10];
for(i=0;i<10;i++)
{
temp[i] = i;
}
function_2(temp);
}
void function_2(int *temp)
{
printf("the value is %d \n",temp[5]);
}
int main()
{
function_1();
return 0;
}
2.3、清空指针
再次强调,指针其实一种存放地址的特殊变量,所以清空指针,是让地址不指向任何值的意思。那么让其指向NULL即可。
*point = NULL;
2.4、C++类中的this
this是每一个对象(类的实例化)都有的一个隐含参数,它是对象本身的地址,作用域也在仅限于对象自身。
注:声明一个东西,无论是类还是其他变量,它本身的变量不占空间的,只有实例化之后才开始占据内存,才有所谓的地址。
举个例子:
class Car
{
public:
int temp1;
Car(int num){
cout<<"the license plate of this car is:"<temp1; //访问对象的temp1属性,当然在这里不加这个this也是可以的。用->是因为this是指针。
}
private:
int temp2;
};
3、malloc and new
malloc和new都是用来分配堆空间的函数指令,其返回值都是一个地址。
其中malloc的函数定义是:void * malloc(unsigned int size); 可以看出,malloc为程序申请了一个size字节大小的控制,并返回一个这个空间的首地址。
使用方法:
int *p = malloc(4);
float *p = malloc(4);
...
free(p); //malloc和free是成对出现的,使用完内存,要用free把内存还回去。
new则常用于C++为类分配内存空间,可以理解为malloc的进化版。new的实现过程可以分为两步,第一步和malloc一样,向堆申请空间。第二步则是执行构造器,对类进行初始化。
#include
using namespace std;
class Car
{
public:
Car(int num){
cout<<"the license plate of this car is:"<temp1 = 5;
//mycar->temp2 = 5; ×,即便指针,也不能访问私有变量
delete(mycar); //delate和new成对出现,也是为了释放已经使用完毕的堆空间,反正内存泄漏。
mycar = NULL; //最好还是清空一下指针
return 0;
}
其中,Car *mycar = new Car(888)意思是向堆申请一块可以存放这个类所有成员函数和变量的空间,返回这个空间的首地址。那么当然得用指向这个类的指针去接收这个地址了。而由于mycar此时已经是一个指针,那么要去访问类里面的成员变量就要用到’->‘而不是’.'了。
mycar->temp1 等于 (*mycar).temp1
4、命名空间
4.1、创建命名空间
一般把命名空间放在头文件里,不同的命名空间也是使用不同的栈区,这使得它们即使有相同名字的变量也毫不冲突。
在以下的这个例子里,假设我们创建了一个myspace.h文件,然把命名空间到定义放在.h文件中。
#ifndef MY_SPACE // ifndef == if no define。防止多次引用头文件的时候,重复执行以下代码
#define MY_SPACE
namespace myspace
{
....
}
#endif
4.2、使用命名空间
#include "myspace.h" //引用自己创建的头文件用“”号,引用系统的文件的时候用<>号。
using namespace myspace;
用了以上这句代码,就可以在该源文件中使用myspace里的所有函数和类。这其实和之前用到的using namespace std是一样的原理。但如果怕不同命名空间在这个文件中出现同名函数或同名变量冲突,可以不使用using namespace …,在需要用到该空间函数或变量的时候再使用以下语句。
myspace::函数or变量
5、编译程序的四个步骤
5.1、预处理
将所有头文件拉取进来,并读取程序所有宏定义,将#if、#ifndef等指令执行完,留下需要用到的代码块。
5.2、编译
检查程序是否有错误。
5.3、汇编
将程序转化为机器能读懂的汇编指令。
5.4、链接
将多个源文件链接起来。