MQ解决重复消费问题
1. 消息重复消费概述
重复消费一直是行业内重视的问题,在当下的互联网时代,追求的是高效,安全,准确的数据交互。对于大型项目来讲,数据量数以亿计,那么这些数据如何确保安全准确,同时又不失效率的传输是很重要的。目前的服务器数据交互设计,大体上可以是前后端数据交互,Rpc(远程过程调用)或者是通过消息中间件(MQ)来进行的,本次解决方案,我们就从这几个角度出发,讨论如何高效准确的解决企业级重复消费问题。
2. 幂等性概述
处理重复消费的问题,幂等性是必要理解的,所谓幂等性是指任意多次执行所产生的影响均与一次执行的影响相同。就例如前端重复提交选中的数据,后台只产生对应这个数据的一个反应结果。我们不仅要在前后端数据交互式考虑幂等性问题,在服务端与服务端进行数据交互式,也需要考虑到这个问题,不然会影响到最终的数据结果。
3. 常见的幂等性问题
- 前段表单的重复提交
- 用户恶意进行刷单
- 接口调用重试
- 消息重复消费
4. Http中重复请求的问题
在系统中,Http请求和远程调用是很常见的数据交互手段,例如订单服务调用商品服务扣减库存,如果因为订单服务的网络问题,导致调用过程重试,但是商品服务在短时间内接收到相同的请求,那么会做相同的数据库库存扣减,导致了数据不一致的问题,也是属于重复问题,那么我们再接口设计上面,需要保证幂等性

首先是做写操作的接口(特别是新增和修改接口),不要设置重试机制,避免出现这样的问题
其次是可以针对特定的接口做区分对待,例如上面的案例,可以使用订单号来保证唯一性,一个订单的库存扣减只能发生一次。
再者可以设计一个通用的方案: 如图
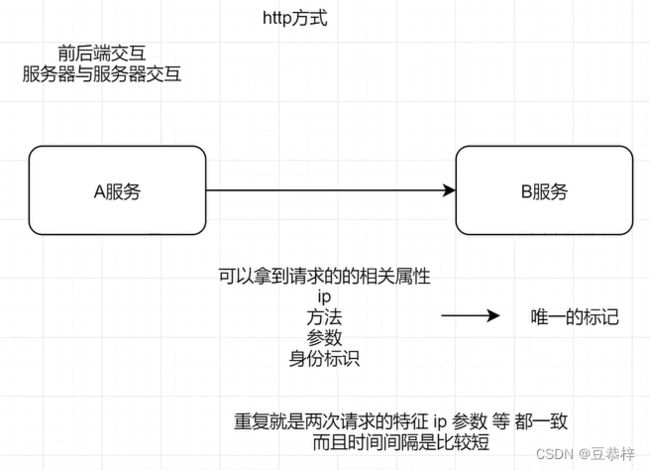

我以redis实现接口的幂等性为例说明。可以自定义一个幂等注解,然后配合AOP进行方法拦截,对拦截的请求信息(包括ip+方法名+参数名+参数值)根据固定的规则去生成一个key,然后调用redis的setnx方法,如果返回ok,则正常调用方法,否则就是重复调用了。这样可以保证重复请求接口在一定时间内只会被成功处理一次。至于锁的有效时长要根据业务情况而定的。
4.1 创建幂等性注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited //可继承
public @interface Idempotence {
}
4.2 获取IP的工具类
public static String getIp() {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
String ip = request.getHeader("x-forwarded-for");
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("WL-Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_CLIENT_IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_X_FORWARDED_FOR");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
return ip.equals("0:0:0:0:0:0:0:1") ? "127.0.0.1" : ip;
}
4.3 创建幂等性切面
@Component
@Aspect
public class IdemAspect {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 接口幂等的环绕通知
* 将请求ip,方法名,参数等作为唯一标记
* 使用redis的setnx命令做业务控制
*
* @param joinPoint
* @return
*/
@Around(value = "@annotation(com.powernode.anno.Idempotence)")
public Object IdemAround(ProceedingJoinPoint joinPoint) {
// 拿到参数以及方法名称和ip
String ip = ServletUtil.getIp();
// 获取参数
Object[] args = joinPoint.getArgs();
String argStr = JSON.toJSONString(args);
// 获取方法的全限定类名
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
String methodName = method.getName();
// 获取类名
Class<?> aClass = method.getDeclaringClass();
String typeName = aClass.getTypeName();
// 构建唯一的标识
String uniqueId = ip + ":" + typeName + "." + methodName + ":" + argStr;
// 使用setnx方式 并且设置过期时间1s 根据业务来控制 例如 1s内不能出现多次相同的参数请求
Boolean flag = redisTemplate.opsForValue().setIfAbsent("Idempotence:" + uniqueId, "", Duration.ofSeconds(1));
if (flag) {
// 执行目标方法
try {
return joinPoint.proceed(args);
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}
// 走到这里说明有重复请求
return "重复请求";
}
}
上述解决调用的重复问题,核心是找到一个唯一的标识,从而判断是否为重复操作
5. 消息中间件中的重复问题
消息中间件的重复问题,就比较经典而且也有一定历史了,市面上常见的Mq都会存在一些重复消费的问题,主要是分为两个方面,一个是生产者的重发,一个是消费者的重复消费。
5.1 生产者出现重复投递问题
生产者已把消息发送到mq,在mq给生产者返回ack的时候网络中断,故生产者未收到确定信息,生产者认为消息未发送成功,但实际情况是,mq已成功接收到了消息,在网络重连后,生产者会重新发送刚才的消息,造成mq接收了重复的消息
5.2 消费者重复消费问题
消费者在消费mq中的消息时,mq已把消息发送给消费者,消费者在给mq返回ack时网络中断,故mq未收到确认信息,该条消息会重新发给其他的消费者,或者在网络重连后再次发送给该消费者,但实际上该消费者已成功消费了该条消息,造成消费者消费了重复的消息;
6. 解决方案
我们再发送消息的时候,给消息带上一个标记,这个标记就是这条消息的唯一标识,可以通过业务代码去控制唯一性(例如雪花算法,或者redis自增等操作),那么我们再消费的时候,就要先判断这个标记是否存在过,如果存在则不进行消费,直接签收删除掉,如果不存在,则消费后存入到一个容器中,这样就可以解决重复消费的问题了。
6.1 设计难点
如何选定一个容器可以存储海量消息,并且能够快速判断是否重复呢?
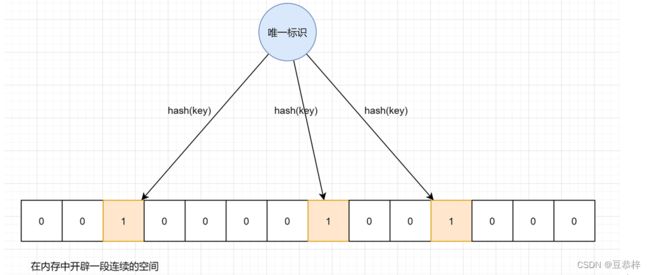
因为在生成环境,消息量是非常庞大的,随便都是千万上亿条。那么如何选择一个容器来进行存储而且他的去重时间复杂度比较低,是我们一直想找寻的方案。例如redis的string类型,我们知道redis的key插槽目前是16384个,显然不够。那么我们可以使用位图这一数据结构来解决这样的问题。这就是布隆过滤器的经典思路。
6.2 使用布隆过滤器解决重复消费思路
我们可以先初始化一个位图,可以认为是0和1组成的连续空间,我们将数据的唯一标识进行散列算法,计算出相应的点位,然后将点位存放在位图中,那么就可以通过一系列点位,对应出一个数据,这样的做法既能占用空间少,并且也可以在很少的时间复杂度上,筛选出重复的元素,这正是我们想要的结果。
7. 布隆过滤器的实现和用法
市面上有很多实现布隆过滤器的产品,比如谷歌的guava包下就有实现,但是这个产品的实现是基于内存的,数据容易丢失,或者是不容易拓展集群。我们可以选择redisson的实现方案,是基于redis的bitMap数据结构,可以持久化数据,而且性能也比较好。
但是我们也需要考虑到布隆过滤器的碰撞问题,因为我们对目标特征做散列算法,就会出现hash碰撞,那么我们可以权衡位图的大小和散列的次数。
7.1 添加redisson的依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.1</version>
</dependency>
7.2 创建redisson配置类
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
@Bean
public RBloomFilter<String> bloomFilter() {
RBloomFilter<String> bloomFilter = redissonClient().getBloomFilter("mq-bloom");
// 预计判断一亿数据,误差率在2个左右 这个误差率已经是很低了
bloomFilter.tryInit(100000000L, 0.000000002);
return bloomFilter;
}
}
7.3 创建消费者
@Component
public class MsgListener {
@Autowired
private RBloomFilter<String> bloomFilter;
@RabbitListener(queues = "test.queue")
public void handleMsg(Message message, Channel channel) {
String msg = new String(message.getBody());
String messageId = message.getMessageProperties().getMessageId();
long deliveryTag = message.getMessageProperties().getDeliveryTag();
// 判断是否存在
if (bloomFilter.contains(messageId)) {//已存在
System.out.println("这个消息存在过,也可能是误判,需要额外处理:" + msg);
try {
channel.basicAck(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
return;
}
//不存在 做业务操作
System.out.println("做业务操作");
// 存放过滤器
bloomFilter.add(messageId);
try {
channel.basicAck(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
}
}
7.4 创建生产者
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
void contextLoads() throws Exception {
rabbitTemplate.convertAndSend("test.queue", "测试消息", (message) -> {
String msgId = UUID.randomUUID().toString();
System.out.println(msgId);
message.getMessageProperties().setMessageId(msgId);
return message;
});
System.in.read();
}
8. 总结
在重复消费的问题上,去重是关键,去重的核心是要找到**唯一的标识,**难点在于数据量巨大的情况下,要具备高效和准确性,那么redis和布隆过滤器是较好的选择,不过还是需要看具体的业务场景来做具体处理。