Java面试准备(四)——Java8特性
Java8特性
- 一、Lambda表达式
-
- 1. 理解函数式编程思想
- 2. 函数式接口(Functional Interface)
-
- 1)什么是函数式接口
- 2)常见的函数式接口
-
- 1. Supplier接口
- 2. Consumer接口
- 3. Predicate接口
- 4. Function接口
- 3. Lambda表达式
-
- 1)Lambda表达式介绍
- 2)Lambda表达式语法
-
- 1. **基本语法**
- 2. **方法引用语法**
- 二、Stream
-
- 1. Stream流概述
- 2. Stream流的操作分类
- 3. Stream流的用法
-
- 1)创建Stream流
- 2)流的中间操作
- 3)流的终止操作
- 4. Stream流的使用实例
- 三、Optional类
-
- 1. Optional存在的意义
- 2. Optional的常用方法
- 四、Date-Time API
-
- 1. java.time包中的主要类
- 2. 用法
-
- 1)LocalDate, LocalTime, LocalDateTime
- 2)Instant 时间戳,
- 3)Duration, Period
- 4)TemporalAdjusters 时间校正器
- 5)DateTimeFormatter 格式化日期
- 6)ZonedDateTime, ZoneId 时区
一、Lambda表达式
1. 理解函数式编程思想
-
面向对象编程是对数据进行抽象;函数式编程是对行为进行抽象。
-
函数式编程是Java8的一大特色,也就是将函数作为一个参数传递给指定方法。函数式编程的目的是使用函数来抽象作用在数据之上的控制流和操作
-
函数式编程思想与面向对象思想的比较:
//面向对象思想 new Thread(new Runnable(){ @Override public void run(){ System.out.println("111"); } }); //函数式编程思想 new Thread(()->{ System.out.println("111");});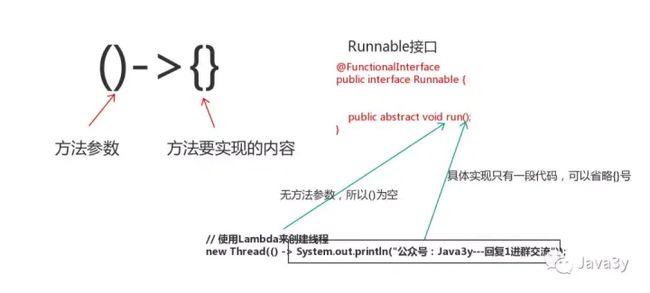
2. 函数式接口(Functional Interface)
1)什么是函数式接口
-
函数式接口,就是适用于函数式编程场景的接口。
-
【定义】函数式接口在java中是指 有且只有一个抽象方法(但可以有多个非抽象方法)的接口, 所以又叫SAM接口(Single Abstract Method Interface) 。
-
Java 8增加了**@FunctionalInterface注解来标注函数式接口**。
使用@FunctionalInterface注解标注的接口必须是函数式接口,也就是说该接口中只能声明一个抽象方法,如果声明多个抽象方法就会报错。但是默认方法和静态方法不属于抽象方法,因此在函数式接口中也可以定义默认方法和静态方法。
-
在 java 8 中专门有一个包放函数式接口java.util.function,该包下的所有接口都有 @FunctionalInterface 注解,提供函数式编程。在其他包中也有函数式接口,其中一些没有@FunctionalInterface 注解,但是只要符合函数式接口的定义就是函数式接口,与是否有@FunctionalInterface注解无关,注解只是能够更好地让编译器进行检查,也能提高代码的可读性。
-
例:
//定义函数式接口 @FunctionalInterface interface InterfaceDemo { //唯一的一个抽象方法 void method(int a); static void staticMethod() { ... } default void defaultMethod() { ... } } //函数式接口作为方法的参数 startThread(() -> System.out.println(Thread.currentThread().getName()+"线程启动")); //函数式接口作为方法的返回值 private static Comparator<String> getComparator(){ return (s1,s2) -> s1.length()-s1.length(); }
2)常见的函数式接口
消费型函数式接口 Consumer 常用于遍历 void accpet(T t)
供给型函数式接口 Supplier 用于产生数据 T get()
断言型函数式接口 Predicate 用于判断 boolean test(T t)
函数型函数式接口 Function
1. Supplier接口
2. Consumer接口
3. Predicate接口
4. Function接口
Java基础篇–函数式接口_哈喽姥爷的博客-CSDN博客_java 函数接口
java 函数式接口 详解_王胖子总叫我减肥的博客-CSDN博客
3. Lambda表达式
1)Lambda表达式介绍
- Lambda 表达式简化了匿名内部类的形式,并且可以达到同样的效果(当然Lambda 要优雅得多)。虽然最终达到的效果是一样的,但其底层实现原理却并不相同。匿名内部类在编译之后会创建一个新的匿名内部类出来,而 Lambda 是调用 JVM invokedynamic指令实现的,并不会产生新类。
- ⚠️Lambda表达式返回的是接口对象实例。
- 使用 Lambda 表达式可以使代码变的更加简洁紧凑。让 java 也能支持简单的函数式编程。把函数作为参数传递进方法中。
2)Lambda表达式语法
1. 基本语法
-
-> 是Lambda运算符,英文名是 goes to
(方法参数列表) -> { 方法体 }; -
基本语法 共6种情况,接口方法无返回值和有返回值分2种,其中无参数、单个参数和多个参数又分3种。
public class Test { public static void main(String[] args) { I01 i01 = () -> { System.out.println("无返回值、无参数"); }; I02 i02 = (int a) -> { System.out.println("无返回值,单个参数。a=" + a); }; I03 i03 = (int a, int b) -> { System.out.println("无返回值,多个参数。a=" + a + ",b=" + b); }; I04 i04 = () -> { System.out.println("有返回值、无参数"); return 4; }; I05 i05 = (int a) -> { System.out.println("有返回值,单个参数。a=" + a); return 5; }; I06 i06 = (int a, int b) -> { System.out.println("有返回值,多个参数。a=" + a + ",b=" + b); return 6; }; i01.method(); i02.method(5); i03.method(5,10); System.out.println(i04.method()); System.out.println(i05.method(5)); System.out.println(i06.method(5, 10)); } } interface I01 { void method(); } interface I02 { void method(int a); } interface I03 { void method(int a, int b); } interface I04 { int method(); } interface I05 { int method(int a); } interface I06 { int method(int a, int b); } -
精简语法
-
参数类型可以省略
比如
I02 i02 = (int a) -> {System.out.println(...);};可以写成I02 i02 = (a) -> {System.out.println(...);}; -
假如只有一个参数,那么
()括号可以省略比如
I02 i02 = (a) -> {System.out.println(...);};可以写成I02 i02 = a -> {System.out.println(...);}; -
假如方法体只有一条语句,那么语句后的
;分号和方法体的{}大括号可以一起省略比如
I02 i02 = a -> {System.out.println(...);};可以写成I02 i02 = a -> System.out.println(...); -
如果方法体中唯一的语句是return返回语句,那么在省略第3种情况的同时,
return也必须一起省略比如
I05 i05 = a -> {return 1;};可以写成``I05 i05 = a -> 1;`
-
2. 方法引用语法
-
用方法引用来进一步简化Lambda表达式,有三种使用情况。(虽然两者底层实现略有不同,但在实际使用中完全可以等价)
- 如果是实例方法:
对象名::实例方法名 - 如果是静态方法:
类名::实例方法名 - 如果是构造方法:
类名::new
- 如果是实例方法:
-
用
::关键字来传递方法或者构造函数引用,无论如何,表达式返回的类型必须是函数式接口。 -
方法引用的使用条件:在lambda的条件基础上,返回的 函数式接口的唯一抽象方法的 参数列表和返回值类型,必须和 具体的方法体实现中的方法的 参数列表和返回值类型 一致,则可以用方法引用
@Test public void test01(){ //使用lambda代替接口的方法体 Student stu = new Student("张三",123); Supplier<String> sp = ()->stu.getName(); System.out.println(sp.get()); //使用方法引用代替接口的方法 Supplier<String> sp2 = stu::getName; System.out.println(sp2.get()); } /* 理解test01: 1.Supplier函数式接口的唯一抽象方法:T get();是无参返回String类型的方法 2.Student类的方法:String getName();也是无参返回String类型的方法 3.满足方法引用使用的条件,两个方法的参数列表和返回值类型一致。 */ //静态方法引用 @Test public void test02(){ //使用lambda比较两个整型的大小 Comparator<Integer> cpr = (x,y)->Integer.compare(x,y); System.out.println(cpr.compare(10,12)); //使用方法引用比较两个整型的大小 Comparator<Integer> cpr2 = Integer::compare; System.out.println(cpr2.compare(10,12)); } //实例方法引用 @Test public void test03(){ //使用lambda表达式比较两个字符串 BiPredicate<String,String> bp1 = (x,y)->x.equals(y); System.out.println(bp1.test("12a","12a")); //使用方法引用比较两个字符串 BiPredicate<String,String> bp2 = String::equals; System.out.println(bp2.test("12a","12a")); } //无参构造 @Test public void test04(){ // Lambda形式 Supplier<Apple> apple = () -> new Apple(); System.out.println(apple.get()); //com.uucoding.java.entity.Apple@305fd85d // 构造方法引用形式 Supplier<Apple> appleNew = Apple::new; System.out.println(appleNew.get()); //com.uucoding.java.entity.Apple@11438d26 } //有参构造 @Test public void test05(){ // Lambda形式 Function<String, Person> person = (name) -> new Person(name); System.out.println(person.apply("卡诺")); // // 构造方法引用形式 Function<String, Person> personNew = Person::new; // Person(name=卡诺) System.out.println(personNew.apply("卡诺New")); // Person(name=卡诺New) }-
理解为什么Comparator接口有两个抽象方法compare和equals,却可以用Lambda?看Comparator源码
Comparator接口有两抽象方法,一个是compare,另一个是equals方法,这与函数式接口定义有冲突。
因为在用lambda表达式调用Comparator接口中都是实现了compare方法,并没有实现equals,而equals是Object中的方法,所用的类都继承Object类,所以equals继承了Object中是实现。
所以函数式接口(Functional Interface)就是一个有且仅有一个(除和Object中方法有相同签名的外)抽象方法,但是可以有多个非抽象方法的接口。
-
二、Stream
1. Stream流概述
- Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。
- 它的源数据可以是 Collection, Array 等。由于它的方法参数都是函数式接口类型,一般和 Lambda 配合使用
- 特点:
- 不是数据结构,不会保存数据。
- 不会修改原来的数据源,它会将操作后的数据保存到另一个对象。(保留:peek方法可以修改流中元素)
- 惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
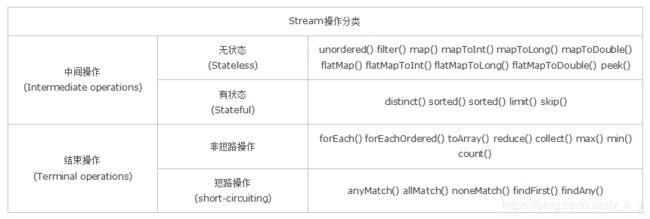
2. Stream流的操作分类
-
中间操作:可以有多个,每次返回一个新的流,可进行链式操作
- 无状态:指元素的处理不受之前元素的影响;
- 有状态:指该操作只有拿到所有元素之后才能继续下去。
-
结束操作:只能有一个,每次执行完,这个流也就用光光了,无法执行下一个操作,因此只能放在最后。
-
非短路操作:指必须处理所有元素才能得到最终结果;
-
短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B。
例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vz2OfkBz-1668694317604)(C:\Users\zhangna\AppData\Roaming\Typora\typora-user-images\1668584582330.png)]
-
3. Stream流的用法
- Stream的三个步骤:创建Stream流 -> 一系列中间操作 -> 结束操作
1)创建Stream流
-
集合。 使用Collection下的 stream() 和 parallelStream() 方法
List<String> list = new ArrayList<>(); Stream<String> stream = list.stream(); //获取一个顺序流 Stream<String> parallelStream = list.parallelStream(); //获取一个并行流 -
数组。 使用Arrays 中的 stream() 方法,将数组转成流
Integer[] nums = new Integer[10]; Stream<Integer> stream = Arrays.stream(nums); -
使用Stream中的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1,2,3,4,5,6); Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6); stream2.forEach(System.out::println); // 0 2 4 6 8 10 Stream<Double> stream3 = Stream.generate(Math::random).limit(2); stream3.forEach(System.out::println); -
使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt")); Stream<String> lineStream = reader.lines(); lineStream.forEach(System.out::println); -
使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(","); Stream<String> stringStream = pattern.splitAsStream("a,b,c,d"); stringStream.forEach(System.out::println);
2)流的中间操作
-
筛选与切片
-
filter:过滤流中符合条件的某些元素。接受一个Predicate函数式接口的参数
-
limit(n):获取n个元素。
-
skip(n):跳过n个元素,配合limit(n)可实现分页
-
distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
//1.创建流 Stream<Integer> stream = Stream.of(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14); //2.流的中间操作 Stream<Integer> newStream = stream.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14 .distinct() //6 7 9 8 10 12 14 .skip(2) //9 8 10 12 14 .limit(2); //9 8 //3.流的结束操作 newStream.forEach(System.out::println);
-
-
映射
-
map:接收一个函数作为参数,该函数会被应用到每个元素上,把每个元素都映射成一个新的元素。
-
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
List<String> list = Arrays.asList("a,b,c", "1,2,3"); //将每个元素转成一个新的且不带逗号的元素 Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", "")); s1.forEach(System.out::println); // abc 123 Stream<String> s3 = list.stream().flatMap(s -> { //将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s2 = Arrays.stream(split); return s2; }); s3.forEach(System.out::println); // a b c 1 2 3 //提取对象的属性 List<String> list = employees.stream() .map(Employee::getName) .collect(Collectors.toList()); list.foreach(System.out::println);
-
-
排序
-
sorted():自然排序,流中元素需实现Comparable接口
-
sorted(Comparator com):定制排序,自定义Comparator排序器
List<String> list = Arrays.asList("aa", "ff", "dd"); //String 类自身已实现Compareable接口 list.stream().sorted().forEach(System.out::println);// aa dd ff Student s1 = new Student("aa", 10); Student s2 = new Student("bb", 20); Student s3 = new Student("aa", 30); Student s4 = new Student("dd", 40); List<Student> studentList = Arrays.asList(s1, s2, s3, s4); //自定义排序:先按姓名升序,姓名相同则按年龄升序 studentList.stream().sorted((o1, o2) -> { if (o1.getName().equals(o2.getName())) { return o1.getAge() - o2.getAge(); } else { return o1.getName().compareTo(o2.getName()); } }).forEach(System.out::println);
-
-
消费
-
peek:如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。 peek会改变源数据中的值
Student s1 = new Student("aa", 10); Student s2 = new Student("bb", 20); List<Student> studentList = Arrays.asList(s1, s2); studentList.stream() .peek(o -> o.setAge(100)) .forEach(System.out::println); //结果: //Student{name='aa', age=100} //Student{name='bb', age=100}
-
3)流的终止操作
-
匹配、聚合操作
-
allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false
-
noneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false
-
anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false
-
findFirst:返回流中第一个元素
-
findAny:返回流中的任意元素
-
count:返回流中元素的总个数
-
max:返回流中元素最大值
-
min:返回流中元素最小值
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); boolean allMatch = list.stream().allMatch(e -> e > 10); //false boolean noneMatch = list.stream().noneMatch(e -> e > 10); //true boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true Integer findFirst = list.stream().findFirst().get(); //1 Integer findAny = list.stream().findAny().get(); //1 long count = list.stream().count(); //5 Integer max = list.stream().max(Integer::compareTo).get(); //5 Integer min = list.stream().min(Integer::compareTo).get(); //1
-
-
规约操作
-
reduce(T identity, BinaryOperator) / reduce(BinaryOperator) 可以将流中元素反复结合起来得到一个值
//例一 List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10); Integer sum = list.stream() .reduce(0, (x, y) -> x + y); System.out.println(sum); //55 /* 理解reduce两个参数:第一个参数是操作的起始值,第二个参数是一个二元操作函数式接口 1.先让初始值0作为x,从流中取出第一个元素1作为y,进行二元运算得到t1 2.再让t1作为x,从流中取出下一个元素2作为y,进行二元运算得到t2 3.再让t2作为x,从流中取出下一个元素3作为y,进行二元运算……依次下去最后得到55 */ //例二 Optional<Double> op = employees.stream() .map(Employee::getSalary) .reduce(Double::sum); System.out.println(op.get()); /* 理解例一和例二的返回值不同: 因为例一reduce有初始值,所以返回值一定不为空,所以是什么就返回什么 而例二reduce没有初始化,所以返回值有可能为空,要封装到Optional里面判空 T reduce(T identity, BinaryOperatoraccumulator) Optional reduce(BinaryOperator accumulator) */ -
注:map和reduce的连接通常称为map-reduce模式
-
-
收集操作
-
collect:将流转换为其他形式。接收一个Collector接口的实现, 将流中元素收集成指定数据结构。
-
提供了一个Collectors工具类,用来返回指定类型的Collector接口的实现
//收集成指定数据结构 //1.收集成List List<String> list = employees.stream() .map(Employee::getName) .collect(Collectors.toList()); list.foreach(System.out::println); //2.收集成set Set<String> set = employees.stream() .map(Employee::getName) .collect(Collectors.toSet()); //3.收集成hashset指定集合 HashSet<String> hs = employees.stream() .map(Employee::getName) .collect(Collectors.toCollection(HashSet::new)); //聚合操作 //1.学生总数 Long count = list.stream().collect(Collectors.counting()); // 3 //2.最大年龄 (最小的minBy同理) Integer maxAge = list.stream() .map(Student::getAge) .collect(Collectors.maxBy(Integer::compare)).get(); // 20 //3.所有人的年龄 Integer sumAge = list.stream() .collect(Collectors.summingInt(Student::getAge)); // 40 //4.平均年龄 Double averageAge = list.stream() .collect(Collectors.averagingDouble(Student::getAge)); // 13.333333333333334 //分组 Map<Integer, List<Student>> ageMap = list.stream() .collect(Collectors.groupingBy(Student::getAge)); //多重分组,先根据类型分再根据年龄分 Map<Integer, Map<Integer, List<Student>>> typeAgeMap = list.stream() .collect(Collectors.groupingBy(Student::getType, Collectors.groupingBy(Student::getAge))); //分区 //分成两部分,一部分大于10岁,一部分小于等于10岁 Map<Boolean, List<Student>> partMap = list.stream() .collect(Collectors.partitioningBy(v -> v.getAge() > 10)); //规约 Integer allAge = list.stream() .map(Student::getAge) .collect(Collectors.reducing(Integer::sum)).get(); //40
-
4. Stream流的使用实例
(下面这些例子可以之后自己写一下练一练)
public class TestTransaction {
List<Transaction> transaction=null;
@Before
public void before(){
Trader raoul=new Trader("Raoul","Cambridge");
Trader mario=new Trader("Mario","Milan");
Trader alan=new Trader("Alan","Cambridge");
Trader brian=new Trader("Brian","Cambridge");
transaction=Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
}
//1.找出2011年发生的所有交易,并按交易额排序(从低到高)
@Test
public void test1(){
transaction.stream()
.filter((e)->e.getYear()==2011)
.sorted((e1,e2)->Integer.compare(e1.getValue(), e2.getValue()))
.forEach(System.out::println);
}
//2.交易员都在哪些不同的城市工作过?
@Test
public void test2(){
transaction.stream()
.map((e)->e.getTrader().getCity())
.distinct()//去重
.forEach(System.out::println);
}
//3.查找所有来自剑桥的交易员,并按姓名排序
@Test
public void test3(){
transaction.stream()
.filter((e)->e.getTrader().getCity().equals("Cambridge"))
.map(Transaction::getTrader)
.sorted((e1,e2)->e1.getName().compareTo(e2.getName()))
.distinct()
.forEach(System.out::println);
}
//4.返回所有交易员的姓名字符串,按字母顺序排序
@Test
public void test4(){
transaction.stream()
.map(Transaction::getTrader)
.map(Trader::getName)
.distinct()
.sorted()
.forEach(System.out::println);
System.out.println("-------------------------");
String str=transaction.stream()
.map((e)->e.getTrader().getName())
.distinct()
.sorted()
.reduce("", String::concat);
System.out.println(str);//AlanBrianMarioRaoul
System.out.println("-------------------------");
transaction.stream()
.map((t)->t.getTrader().getName())
.flatMap(TestTransaction::filterCharacter)//返回的每个String合成一个流
.sorted((s1,s2)->s1.compareToIgnoreCase(s2))
.forEach(System.out::print);//aaaaaAaBiiilllMMnnoooorRRrruu
}
public static Stream<String> filterCharacter(String str){
List<String> list=new ArrayList<>();
for(Character ch:str.toCharArray()){
list.add(ch.toString());
}
return list.stream();
}
//5.有没有交易员是在米兰工作的?
@Test
public void test5(){
boolean b1=transaction.stream()
.anyMatch((t)->t.getTrader().getCity().equals("Milan"));
System.out.println(b1);
}
//6.打印生活在剑桥的交易员的所有交易额
@Test
public void test6(){
Optional<Integer> sum=transaction.stream()
.filter((e)->e.getTrader().getCity().equals("Cambridge"))
.map(Transaction::getValue)
.reduce(Integer::sum);
System.out.println(sum.get());
}
//7.所有交易中,最高的交易额是多少
@Test
public void test7(){
Optional<Integer> max=transaction.stream()
.map((t)->t.getValue())
.max(Integer::compare);
System.out.println(max.get());
}
//8.找到交易额最小的交易
@Test
public void test8(){
Optional<Transaction> op=transaction.stream()
.min((t1,t2)->Integer.compare(t1.getValue(), t2.getValue()));
System.out.println(op.get());
}
}
三、Optional类
1. Optional存在的意义
在阿里巴巴开发手册关于 Optional 的介绍中这样写到:
防止 NPE,是程序员的基本修养,注意 NPE 产生的场景:
1) 返回类型为基本数据类型,return 包装数据类型的对象时,自动拆箱有可能产生 NPE。
反例:public int f() { return Integer 对象}, 如果为 null,自动解箱抛 NPE。
2) 数据库的查询结果可能为 null。
3) 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null。
4) 远程调用返回对象时,一律要求进行空指针判断,防止 NPE。
5) 对于 Session 中获取的数据,建议进行 NPE 检查,避免空指针。
6) 级联调用 obj.getA().getB().getC();一连串调用,易产生 NPE。
正例:使用 JDK8 的 Optional 类来防止 NPE 问题。
用 Optional 解决 NPE(NullPointerException)问题,其中可以包含空值或非空值。
2. Optional的常用方法
-
of
of方法通过工厂方法创建Optional类。需要注意的是,创建对象时传入的参数不能为null。如果传入参数为null,则抛出NullPointerException 。
//调用工厂方法创建Optional实例 Optional<String> name = Optional.of("Sanaulla"); //传入参数为null,抛出NullPointerException. Optional<String> someNull = Optional.of(null); -
ofNullable
为指定的值创建一个Optional,如果指定的值为null,则返回一个空的Optional。
//下面创建了一个不包含任何值的Optional实例 //例如,值为'null' Optional empty = Optional.ofNullable(null); -
isPresent: 如果值存在返回true,否则返回false。
//isPresent方法用来检查Optional实例中是否包含值 if (name.isPresent()) { //在Optional实例内调用get()返回已存在的值 System.out.println(name.get());//输出Sanaulla } -
get: 如果Optional有值则将其返回,否则抛出NoSuchElementException。
-
ifPresent: 如果Optional实例有值则为其调用consumer,否则不做处理
//ifPresent方法接受lambda表达式作为参数。 //lambda表达式对Optional的值调用consumer进行处理。 name.ifPresent((value) -> { System.out.println("The length of the value is: " + value.length()); }); -
orElse: 如果Optional实例有值则将其返回,否则返回orElse方法传入的参数
//如果值不为null,orElse方法返回Optional实例的值。 //如果为null,返回传入的消息。 //输出: There is no value present! System.out.println(empty.orElse("There is no value present!")); //输出: Sanaulla System.out.println(name.orElse("There is some value!")); -
orElseGet
-
orElseGet与orElse方法类似,区别在于得到的默认值。
-
orElse方法将传入的字符串作为默认值,orElseGet方法可以接受Supplier接口的实现用来生成默认值。
//orElseGet与orElse方法类似,区别在于orElse传入的是默认值, //orElseGet可以接受一个lambda表达式生成默认值。 //输出: Default Value System.out.println(empty.orElseGet(() -> "Default Value")); //输出: Sanaulla System.out.println(name.orElseGet(() -> "Default Value"));
-
-
orElseThrow: 如果有值则将其返回,否则抛出supplier接口创建的异常。
try { //orElseThrow与orElse方法类似。与返回默认值不同, //orElseThrow会抛出lambda表达式或方法生成的异常 empty.orElseThrow(ValueAbsentException::new); } catch (Throwable ex) { //输出: No value present in the Optional instance System.out.println(ex.getMessage()); } -
map
map用来对Optional实例的值执行一系列操作。通过一组实现了Function接口的lambda表达式传入操作。
//map方法执行传入的lambda表达式参数对Optional实例的值进行修改。 //为lambda表达式的返回值创建新的Optional实例作为map方法的返回值。 Optional<String> upperName = name.map((value) -> value.toUpperCase()); -
flatMap
//flatMap与map(Function)非常类似,区别在于传入方法的lambda表达式的返回类型。 //map方法中的lambda表达式返回值可以是任意类型,在map函数返回之前会包装为Optional。 //但flatMap方法中的lambda表达式返回值必须是Optionl实例。 Optional<String> upperName = name .flatMap((value) -> Optional.of(value.toUpperCase())); System.out.println(upperName.orElse("No value found"));//输出SANAULLA -
filter
//filter通过传入限定条件对Optional实例的值进行过滤。 //如果有值并且满足断言条件返回包含该值的Optional,否则返回空Optional。 Optional<String> longName = name.filter((value) -> value.length() > 6);
四、Date-Time API
java.time包中的类是不可变且线程安全的。新的时间及日期API位于java.time包中
1. java.time包中的主要类
-
Instant——它代表的是时间戳
-
LocalDate——不包含具体时间的日期,比如2014-01-14。它可以用来存储生日,周年纪念日,入职日期等。
-
LocalTime——它代表的是不含日期的时间
-
LocalDateTime——它包含了日期及时间,不过还是没有偏移信息或者说时区。
-
ZonedDateTime——这是一个包含时区的完整的日期时间,偏移量是以UTC/格林威治时间为基准的。
新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。
2. 用法
1)LocalDate, LocalTime, LocalDateTime
给人看的时间(三个用法类似,就以LocalDateTime为例)
//1.获取目前的日期时间
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt); //2022-11-17T20:34:08.638
//2.获取指定的日期时间
LocalDateTime ldt2 = LocalDateTime.of(2022, 11, 17, 20, 32, 59);
System.out.println(ldt2); //2022-11-17T20:32:59
//3.日期时间的加减操作
LocalDateTime ldt3 = ldt.plusYears(2);
System.out.println(ldt3); //2024-11-17T20:37:43.740
LocalDateTime ldt4 = ldt.minusMonths(3);
System.out.println(ldt4); //2022-08-17T20:37:43.740
//4.获取日期时间其中某一个位置上的数
System.out.println(ldt.getYear()); //2022
System.out.println(ldt.getMonthValue()); //11
System.out.println(ldt.getDayOfMonth()); //17
System.out.println(ldt.getHour()); //20
System.out.println(ldt.getMinute()); //41
System.out.println(ldt.getSecond()); //19
//5.LocalDateTime和另两个LocalDate, LocalTime之间的互相转换
//5.1 调用 LocalDate的atTime()方法 或 LocalTime的atDate()方法 合并成一个LocalDateTime
LocalDate localDate = LocalDate.of(2017, Month.JANUARY, 4);
LocalTime localTime = LocalTime.of(17, 23, 52);
LocalDateTime ldt5 = localDate.atTime(localTime);
LocalDateTime ldt6 = localTime.atDate(localDate);
System.out.println(ldt5); //2017-01-04T17:23:52
System.out.println(ldt6); //2017-01-04T17:23:52
//5.2 LocalDateTime向LocalDate和LocalTime的转化
LocalDate date = ldt.toLocalDate();
LocalTime time = ldt.toLocalTime();
//6.localDate可以判断是否为闰年
boolean leapYear = localDate.isLeapYear();
2)Instant 时间戳,
机器看的(以Unix元年:1970年1月1日00:00:00到某个时间之间的毫秒值)
//1.获取时间戳
Instant ins1 = Instant.now(); //默认获取UTC时区的时间戳
System.out.println(ins1); //2022-11-17T13:08:37.109Z
OffsetDateTime odt = ins1.atOffset(ZoneOffset.ofHours(8)); //中国跟UTC时区的时间差8个小时
System.out.println(odt); //2022-11-17T21:08:37.109+08:00
//2.将时间戳转换成毫秒表示
System.out.println(ins1.toEpochMilli()); //1668690517109
//3.对时间戳运算:下面这个代表从Unix元年+60s创建一个时间戳
Instant ins2 = Instant.ofEpochSecond(60);
System.out.println(ins2); //1970-01-01T00:01:00Z
3)Duration, Period
- Duration:计算两个”时间“之间的间隔
//计算两个时间戳之间的间隔
Instant ins1 = Instant.now();
Thread.sleep(1000);
Instant ins2 = Instant.now();
Duration duration = Duration.between(ins1, ins2);
System.out.println(duration.toMillis()); //1003,注意获取秒是toxx,获取年月日时分是getxx
//计算两个LocalTime之间的间隔
LocalTime lt1 = LocalTime.now();
Thread.sleep(1000);
LocalTime lt2 = LocalTime.now();
Duration duration1 = Duration.between(lt1, lt2);
System.out.println(duration1.toMillis()); //1003
- Period:计算两个“日期”之间的间隔
LocalDate ld1 = LocalDate.of(2021, 1, 1);
LocalDate ld2 = LocalDate.now();
Period period = Period.between(ld1, ld2);
System.out.println(period); //P1Y10M16D
System.out.println(period.getYears()); //1
System.out.println(period.getMonths()); //10
System.out.println(period.getDays()); //16
4)TemporalAdjusters 时间校正器
-
给定的日期/时间,给她修改其中的年/月/日,或者给她增加或减少某位数
LocalDate date = LocalDate.of(2017, 1, 5); // 2017-01-05 LocalDate date1 = date.withYear(2016); // 修改为 2016-01-05 LocalDate date2 = date.withMonth(2); // 修改为 2017-02-05 LocalDate date3 = date.withDayOfMonth(1); // 修改为 2017-01-01 LocalDate date4 = date.plusYears(1); // 增加一年 2018-01-05 LocalDate date5 = date.minusMonths(2); // 减少两个月 2016-11-05 LocalDate date6 = date.plus(5, ChronoUnit.DAYS); // 增加5天 2017-01-10 -
面临更复杂的修改情况时,比如将时间调到下一个工作日,或者是下个月的最后一天,这时候我们可以使用
with()方法的另一个重载方法,它接收一个TemporalAdjuster参数,可以更加灵活的调整日期public LocalDate with(TemporalAdjuster adjuster) {……}- TemporalAdjusters 是 TemporalAdjuster 接口的工具类
- TemporalAdjuster 是一个函数式接口,可以自定义实现
LocalDateTime ldt = LocalDateTime.now(); //下个星期日 LocalDateTime ldt2 = ldt.with(TemporalAdjusters.next(DayofWeek.SUNDAY)); //自定义实现下一个工作日 LocalDateTime ldt3 = ldt.with((l) -> { LocalDateTime ldt4 = (LocalDateTime) l; DayOfWeek dow = ldt4.getDayOfWeek(); if (dow.equals(DayOfWeek.FRIDAY)) { return ldt4.plusDays(3); } else if (dow.equals(DayOfWeek.SATURDAY)) { return ldt4.plusDays(2); } else { return ldt4.plusDays(1); } });
5)DateTimeFormatter 格式化日期
-
DateTimeFormatter类用于处理日期格式化操作,它被包含在java.time.format包中, -
Java 8的日期类有一个
format()方法将日期格式化为字符串,该方法接收一个DateTimeFormatter类型参数LocalDateTime dateTime = LocalDateTime.now(); String strDate1 = dateTime.format(DateTimeFormatter.BASIC_ISO_DATE); // 20170105 String strDate2 = dateTime.format(DateTimeFormatter.ISO_LOCAL_DATE); // 2017-01-05 String strDate3 = dateTime.format(DateTimeFormatter.ISO_LOCAL_TIME); // 14:20:16.998 String strDate4 = dateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd")); // 2017-01-05 String strDate5 = dateTime.format(DateTimeFormatter.ofPattern("今天是:YYYY年 MMMM DD日 E", Locale.CHINESE)); // 今天是:2017年 一月 05日 星期四 -
将一个字符串解析成一个日期对象
String strDate6 = "2017-01-05";
String strDate7 = "2017-01-05 12:30:05";
LocalDate date = LocalDate.parse(strDate6, DateTimeFormatter.ofPattern("yyyy-MM-dd"));
LocalDateTime dateTime1 =
LocalDateTime.parse(strDate7, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
6)ZonedDateTime, ZoneId 时区
-
Java 8中的时区类
java.time.ZoneId是原有的java.util.TimeZone类的替代品。 -
ZoneId对象可以通过ZoneId.of()方法创建,也可以通过ZoneId.systemDefault()获取系统默认时区:ZoneId shanghaiZoneId = ZoneId.of("Asia/Shanghai"); ZoneId systemZoneId = ZoneId.systemDefault();of()方法接收一个“区域/城市”的字符串作为参数,- 可以通过
getAvailableZoneIds()方法获取所有合法的“区域/城市”字符串:
SetzoneIds = ZoneId.getAvailableZoneIds(); -
对于老的时区类
TimeZone,Java 8也提供了转化方法:ZoneId oldToNewZoneId = TimeZone.getDefault().toZoneId(); -
有了
ZoneId,就可以将一个LocalDate、LocalTime或LocalDateTime对象转化为ZonedDateTime对象:LocalDateTime localDateTime = LocalDateTime.now(); ZonedDateTime zonedDateTime = ZonedDateTime.of(localDateTime, shanghaiZoneId);-
将
zonedDateTime打印到控制台为:2017-01-05T15:26:56.147+08:00[Asia/Shanghai]示例ZonedDateTime对象由两部分构成,LocalDateTime和ZoneId,其中2017-01-05T15:26:56.147部分为LocalDateTime,+08:00[Asia/Shanghai]部分为ZoneId。
-
-
另一种表示时区的方式是使用
ZoneOffset,它是以当前时间和**世界标准时间(UTC)/格林威治时间(GMT)**的偏差来计算,例如:ZoneOffset zoneOffset = ZoneOffset.of("+09:00"); LocalDateTime localDateTime = LocalDateTime.now(); OffsetDateTime offsetDateTime = OffsetDateTime.of(localDateTime, zoneOffset);
Date-Time参考 [java8新特性七-Date Time API - WatermelonRoad - 博客园 (cnblogs.com)](https://www.cnblogs.com/wxhbk/p/11612496.html#:~:text=Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。 在旧版的 Java,中,日期时间 API 存在诸多问题,其中有: 非线程安全 − java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java日期类最大的问题之一。)