5.Flink对接Kafka入门
Flink Connector Kafka
- 1. Kafka
-
- 1.1. [Kafka官网](http://kafka.apache.org/)
- 1.2. Kafka 简述
- 1.3. Kafka特性
- 1.4. kafka的应用场景
- 1.5. kafka-manager的部署
- 1.6. `使用Kafka Connect导入/导出数据`
- 1.7. [Kafka日志存储原理](https://blog.csdn.net/shujuelin/article/details/80898624)
- 2. Kafka与Flink的融合
-
- 2.1. kafka连接flink流计算,实现flink消费kafka的数据
- 2.2. flink 读取kafka并且自定义水印再将数据写入kafka中
- 3. Airbnb 是如何通过 balanced Kafka reader 来扩展 Spark streaming 实时流处理能力的
- 4. 寄语:海阔凭鱼跃,天高任鸟飞
1. Kafka
1.1. Kafka官网
1.2. Kafka 简述

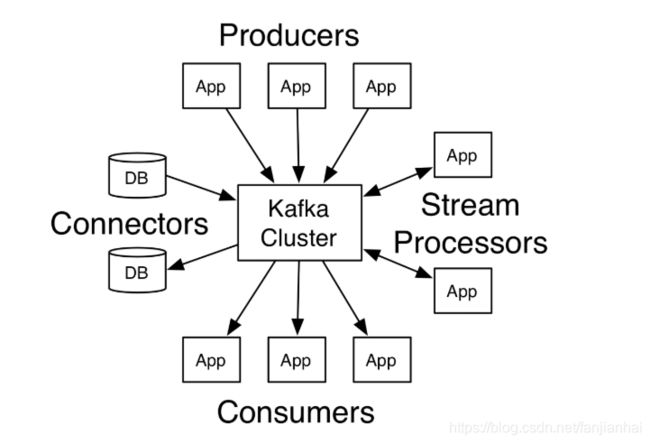
- Kafka 是一个分布式消息系统:具有生产者、消费者的功能。它提供了类似于JMS 的特性,但是在设计实现上完全不同,此外它并不是JMS 规范的实现。
1.3. Kafka特性
消息持久化:基于文件系统来存储和缓存消息高吞吐量多客户端支持:核心模块用Scala语言开发,Kafka 提供了多种开发语言的接入,如Java 、Scala、C 、C++、Python 、Go 、Erlang 、Ruby 、Node. 等安全机制通过SSL 和SASL(Kerberos), SASL/PLA时验证机制支持生产者、消费者与broker连接时的身份认证;支持代理与ZooKeeper 连接身份验证通信时数据加密客户端读、写权限认证Kafka 支持与外部其他认证授权服务的集成
数据备份轻量级消息压缩
1.4. kafka的应用场景
Kafka作为消息传递系统

Kafka 作为存储系统

Kafka用做流处理

消息,存储,流处理结合起来使用

1.5. kafka-manager的部署
Kafka Manager 由 yahoo 公司开发,该工具可以方便查看集群 主题分布情况,同时支持对 多个集群的管理、分区平衡以及创建主题等操作。
-
Centos7安装kafka-manager
-
启动脚本bin/cmak -Dconfig.file=conf/application.conf -java-home /usr/lib/jdk-11.0.6 -Dhttp.port=9008 &
-
界面效果
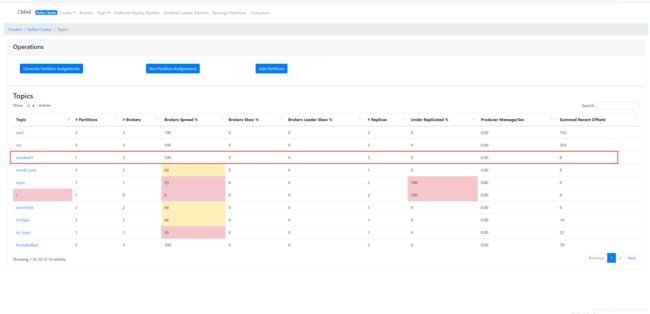
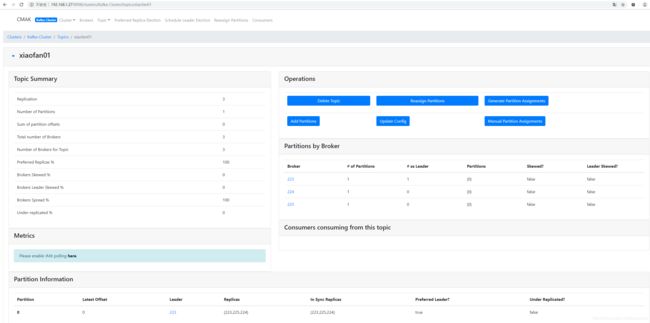
-
注意
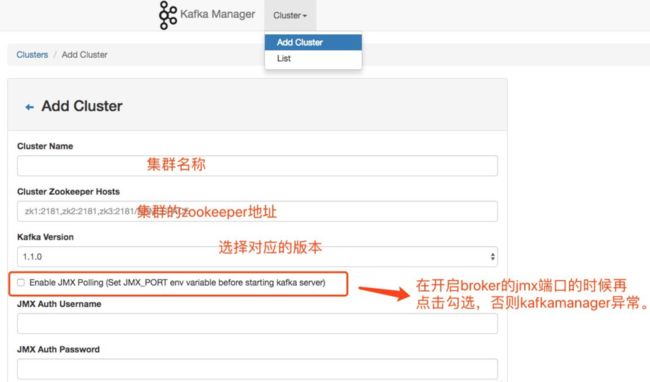
1.6. 使用Kafka Connect导入/导出数据
- 替代Flume——Kafka Connect
集群模式注意: 在集群模式下,配置并不会在命令行传进去,而是需要REST API来创建,修改和销毁连接器。- 通过一个示例了解kafka connect连接器
- kafka connect简介以及部署
1.7. Kafka日志存储原理
Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性
-
查看分区.index文件
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files kafka-logs/t2-2/00000000000000000000.index -
查看log文件
/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files t1-1/00000000000000000000.log --print-data-log -
查看TimeIndex文件
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files t1-2/00000000000000000000.timeindex --verify-index-only -
引入时间戳的作用
2. Kafka与Flink的融合
Flink 提供了专门的 Kafka 连接器,向 Kafka topic 中读取或者写入数据。Flink Kafka Consumer 集成了 Flink 的 Checkpoint 机制,可提供 exactly-once 的处理语义。为此,Flink 并不完全依赖于跟踪 Kafka 消费组的偏移量,而是在内部跟踪和检查偏移量。
2.1. kafka连接flink流计算,实现flink消费kafka的数据
-
创建flink项目
sbt new tillrohrmann/flink-project.g8 -
配置sbt
ThisBuild / resolvers ++= Seq( "Apache Development Snapshot Repository" at "https://repository.apache.org/content/repositories/snapshots/", Resolver.mavenLocal ) name := "FlinkKafkaProject" version := "1.0" organization := "com.xiaofan" ThisBuild / scalaVersion := "2.12.6" val flinkVersion = "1.10.0" val kafkaVersion = "2.2.0" val flinkDependencies = Seq( "org.apache.flink" %% "flink-scala" % flinkVersion % "provided", "org.apache.kafka" %% "kafka" % kafkaVersion % "provided", "org.apache.flink" %% "flink-connector-kafka" % flinkVersion, "org.apache.flink" %% "flink-streaming-scala" % flinkVersion % "provided") lazy val root = (project in file(".")). settings( libraryDependencies ++= flinkDependencies ) assembly / mainClass := Some("com.xiaofan.Job") // make run command include the provided dependencies Compile / run := Defaults.runTask(Compile / fullClasspath, Compile / run / mainClass, Compile / run / runner ).evaluated // stays inside the sbt console when we press "ctrl-c" while a Flink programme executes with "run" or "runMain" Compile / run / fork := true Global / cancelable := true // exclude Scala library from assembly assembly / assemblyOption := (assembly / assemblyOption).value.copy(includeScala = false) -
源代码
package com.xiaofan import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic} import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer /** * 用flink消费kafka * * @author xiaofan */ object ReadingFromKafka { val ZOOKEEPER_HOST = "192.168.1.23:2181,192.168.1.24:2181,192.168.1.25:2181" val KAFKA_BROKER = "192.168.1.23:9091,192.168.1.24:9091,192.168.1.25:9091" val TRANSACTION_GROUP = "com.xiaofan.flink" def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.enableCheckpointing(1000) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) // configure kafka consumer val kafkaProps = new Properties() kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST) kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKER) kafkaProps.setProperty("group.id", TRANSACTION_GROUP) val transaction: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("xiaofan01", new SimpleStringSchema(), kafkaProps)) transaction.print env.execute() } } -
启动kafka集群,运行结果
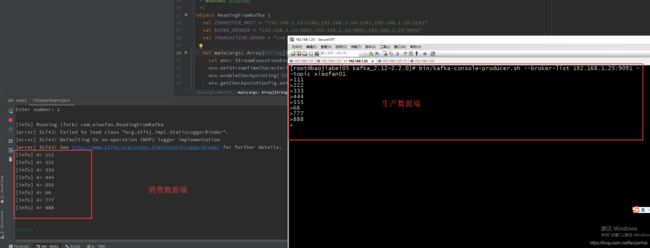
2.2. flink 读取kafka并且自定义水印再将数据写入kafka中
-
需求说明(自定义窗口,每分钟的词频统计)
- 从kafka中读取数据(topic:t1)
- kafka中有event time时间值,通过该时间戳来进行时间划分,窗口长度为10秒,窗口步长为5秒
- 由于生产中可能会因为网络或者其他原因导致数据延时,比如 00:00:10 时间的数据可能 00:00:12 才会传入kafka中,所以在flink的处理中应该设置延时等待处理,这里设置的2秒,可以自行修改。
- 结果数据写入kafka中(topic:t2)(数据格式
time:时间 count:每分钟的处理条数)
-
准备环境flink1.10.0 + kafka2.2.0
-
创建topic
bin/kafka-topics.sh --create --bootstrap-server 192.168.1.25:9091 --replication-factor 2 --partitions 3 --topic t1bin/kafka-topics.sh --create --bootstrap-server 192.168.1.25:9091 --replication-factor 2 --partitions 3 --topic t2 -
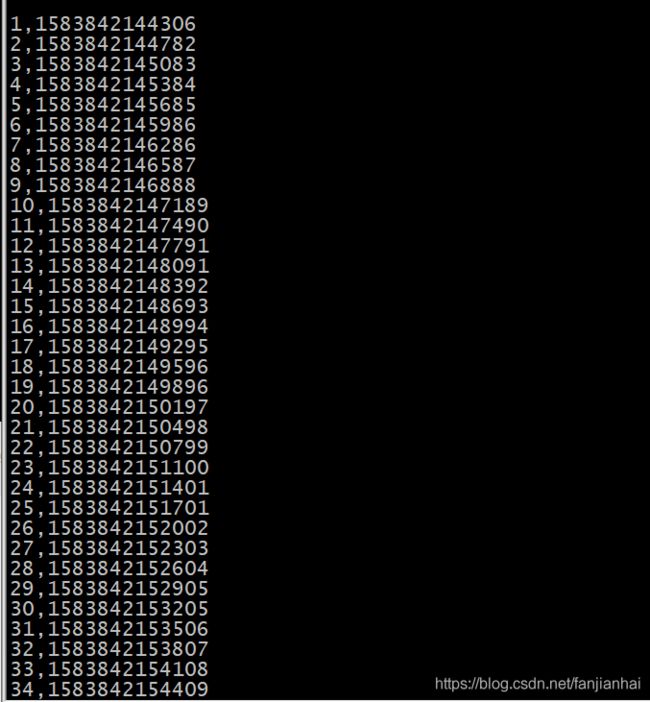
向t1中生产数据
package com.xiaofan import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} object ProduceData { def main(args: Array[String]): Unit = { val props = new Properties() props.put("bootstrap.servers", "192.168.1.25:9091") props.put("acks", "1") props.put("retries", "3") props.put("batch.size", "16384") // 16K props.put("linger.ms", "1") props.put("buffer.memory", "33554432") // 32M props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") val producer = new KafkaProducer[String, String](props) var i = 0 while (true) { i += 1 // 模拟标记事件时间 val record = new ProducerRecord[String, String]("t1", i + "," + System.currentTimeMillis()) // 只管发送消息,不管是否发送成功 producer.send(record) Thread.sleep(300) } } } -
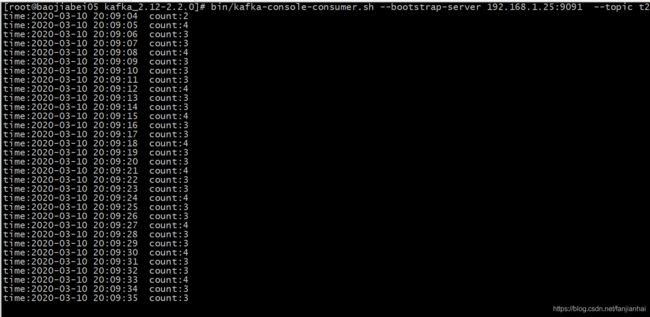
消费t1数据,处理后再次传入kafka t2
package com.xiaofan import java.text.SimpleDateFormat import java.util.{Date, Properties} import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer} /** * Watermark 案例 * 根据自定义水印定义时间,计算每秒的消息数并且写入 kafka中 */ object StreamingWindowWatermarkScala { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val topic = "t1" val prop = new Properties() prop.setProperty("bootstrap.servers","192.168.1.25:9091") prop.setProperty("group.id","con1") val myConsumer = new FlinkKafkaConsumer[String](topic,new SimpleStringSchema(),prop) // 添加源 val text = env.addSource(myConsumer) val inputMap = text.map(line=>{ val arr = line.split(",") (arr(0),arr(1).trim.toLong) }) // 添加水印 val waterMarkStream = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] { var currentMaxTimestamp = 0L var maxOutOfOrderness = 3000L// 最大允许的乱序时间是10s val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); override def getCurrentWatermark = new Watermark(currentMaxTimestamp - maxOutOfOrderness) override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long) = { val timestamp = element._2 currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp) val id = Thread.currentThread().getId println("currentThreadId:"+id+",key:"+element._1+",eventtime:["+element._2+"|"+sdf.format(element._2)+"],currentMaxTimestamp:["+currentMaxTimestamp+"|"+ sdf.format(currentMaxTimestamp)+"],watermark:["+getCurrentWatermark().getTimestamp+"|"+sdf.format(getCurrentWatermark().getTimestamp)+"]") timestamp } }) val window = waterMarkStream.map(x=>(x._2,1)).timeWindowAll(Time.seconds(1),Time.seconds(1)).sum(1).map(x=>"time:"+tranTimeToString(x._1.toString)+" count:"+x._2) // .window(TumblingEventTimeWindows.of(Time.seconds(3))) //按照消息的EventTime分配窗口,和调用TimeWindow效果一样 val topic2 = "t2" val props = new Properties() props.setProperty("bootstrap.servers","192.168.1.25:9091") //使用支持仅一次语义的形式 val myProducer = new FlinkKafkaProducer[String](topic2,new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE) window.addSink(myProducer) env.execute("StreamingWindowWatermarkScala") } def tranTimeToString(timestamp:String) :String={ val fm = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") val time = fm.format(new Date(timestamp.toLong)) time } } -
运行效果
3. Airbnb 是如何通过 balanced Kafka reader 来扩展 Spark streaming 实时流处理能力的
- 参考链接1
- 参考链接2