Nebula分布式集群
2022年9月15日18:47:38
文章目录
- Nebula
-
- 1.安装:
- 2.数据模型
- 3.NebulaGraph 架构总览
- 4.基本命令文档
-
- 4.0 数据类型
- 4.1 spaces图空间
-
- CREATE SPACE
- DROP SPACE
- CLEAR SPACE
- SHOW SPACES
- DESC SPACE
- 4.2 Tag
- 4.3 edge
- 4.4 点语句
-
- INSERT VERTEX
- DELETE VERTEX
- UPDATE VERTEX
- UPSERT VERTEX
- 4.5 边语句
-
- INSER EDGE
- DELETE EDGE
- UPDATE EDGE
- UPSERT EDGE
- 4.6 通用查询
-
- MATCH
-
- 匹配连接的点
- 匹配路径
- 匹配边
- 匹配 Edge type
- 匹配边的属性
- 匹配多条边
- 匹配定长路径
- 匹配变长路径
- 匹配最短路径
- 多MATCH检索
- LOOKUP
-
- 检索点
- 检索边
- 通过 Tag 列出所有的对应的点/通过 Edge type 列出边
- 统计点或边
- GO
- FETCH
-
- 获取点的属性值
- 获取边的属性值
- 4.7 状态查询
-
- 集群信息
- 图空间信息
- 索引信息
- 分片信息
- 统计信息
- 查询 TAG、EDGE
- 查询创建索引状态
- 查询快照
- 5.索引介绍:
-
- 创建索引
- 查询索引
- 重建索引
- 删除索引
- 6.数据压力测试
- 7.集群的搭建
Nebula
NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集。
从设计上来看,没有做设计约束。也就是理论上点边可以更大,当然也不太好说无限,毕竟真到了无限,肯定会受制于某个系统中的短板,如存储、网络、数据长度等等。我们在文档中描述的千亿点,万亿边,是客户已经有到了这个量级的系统规模。如果再上个量级,支持起来问题也不大。从目前客户遇到的规模来看,千亿点,万亿边已经属于很大的集群了,基本都能满足大部分客户的规模诉求!
https://discuss.nebula-graph.com.cn/t/topic/7220
文档手册:https://docs.nebula-graph.com.cn/3.2.0/
NebulaGraph 是针对 NVMe SSD 进行设计和实现的,所有默认参数都是基于 SSD 设备进行调优,要求极高的 IOPS 和极低的 Latency。
-
不建议使用 HDD;因为其 IOPS 性能差,随机寻道延迟高;会遇到大量问题。(storage 的 rocksdb_block_cache,可以调整到内存的 1/3,让读的话少走磁盘,尽量走缓存)
-
不要使用远端存储设备(如 NAS 或 SAN),不要外接基于 HDFS 或者 Ceph 的虚拟硬盘。
-
不要使用磁盘阵列(RAID)。
-
使用本地 SSD 设备;或 AWS Provisioned IOPS SSD 或等价云产品。
1.安装:
NebulaGraph:
下载地址:https://nebula-graph.com.cn/download
下载安装包:
centos8
wget https://oss-cdn.nebula-graph.com.cn/package/3.2.1/nebula-graph-3.2.1.el8.x86_64.rpm
sudo rpm -ivh nebula-graph-3.2.0.el7.x86_64.rpm
NebulaGraph Studio:
#默认安装路径为/usr/local/nebula-graph-studio
wget https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.4.1/nebula-graph-studio-3.4.1.x86_64.rpm
sudo rpm -i nebula-graph-studio-3.4.1.x86_64.rpm
sudo rpm -i nebula-graph-studio-3.4.1.x86_64.rpm --prefix=<path>
# 不要用127.0.0.1和localhost
http://:7001
NebulaGraph Console:
wget https://github.com/vesoft-inc/nebula-console/releases/download/v3.2.0/nebula-console-linux-amd64-v3.2.0
./nebula-console -addr 192.168.10.8 -port 9669 -u root -p Joespassword
NebulaGraph Importer:
docker run --rm -ti --privileged=true \
--network=host \
-v /usr/local/nebula/tools/loadcsv/:/usr/local/nebula/tools/loadcsv/ \
-v /usr/local/nebula/tools/loadcsv/:/usr/local/nebula/tools/loadcsv/ \
vesoft/nebula-importer
--config /usr/local/nebula/tools/loadcsv/config.yaml
config.yaml配置模板
# 连接的 NebulaGraph 版本,连接 3.x 时设置为 v3。
version: v3
# 是否删除临时生成的日志和错误数据文件。
removeTempFiles: false
clientSettings:
# nGQL 语句执行失败的重试次数。
retry: 3
# NebulaGraph 客户端并发数。
concurrency: 10
# 每个 NebulaGraph 客户端的缓存队列大小。
channelBufferSize: 128
# 指定数据要导入的 NebulaGraph 图空间。
space: neo4j
# 连接信息。
connection:
user: root
password: nebula
address: 127.0.0.1:9669
postStart:
# 配置连接 NebulaGraph 服务器之后,在插入数据之前执行的一些操作。
commands: |
UPDATE CONFIGS storage:wal_ttl=3600;
UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = true };
DROP SPACE IF EXISTS neo4j;
CREATE SPACE IF NOT EXISTS neo4j(partition_num=5, replica_factor=1, vid_type=FIXED_STRING(64));
USE neo4j;
DROP TAG IF EXISTS person;
CREATE TAG IF NOT EXISTS person(name string,is_comfirmaed bool);
DROP EDGE IF EXISTS 同居;
CREATE EDGE IF NOT EXISTS 同居(start_time float, end_time float);
# 执行上述命令后到执行插入数据命令之间的间隔。
afterPeriod: 8s
preStop:
# 配置断开 NebulaGraph 服务器连接之前执行的一些操作。
commands: |
UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = false };
UPDATE CONFIGS storage:wal_ttl=86400;
# 错误等日志信息输出的文件路径。
logPath: ./err/import.log
# CSV 文件相关设置。
files:
# 数据文件的存放路径,如果使用相对路径,则会将路径和当前配置文件的目录拼接。本示例第一个数据文件为点的数据。
- path: ./person.csv
# 插入失败的数据文件存放路径,以便后面补写数据。
failDataPath: ./err/
# 单批次插入数据的语句数量。
batchSize: 100
# 读取数据的行数限制。
limit: null
# 是否按顺序在文件中插入数据行。如果为 false,可以避免数据倾斜导致的导入速率降低。
inOrder: true
# 文件类型,当前仅支持 csv。
type: csv
csv:
# 是否有表头。
withHeader: false
# 是否有 LABEL。
withLabel: false
# 指定 csv 文件的分隔符。只支持一个字符的字符串分隔符。
#delimiter: ","
schema:
# Schema 的类型,可选值为 vertex 和 edge。
type: vertex
vertex:
# 点 ID 设置。
vid:
# 点 ID 对应 CSV 文件中列的序号。CSV 文件中列的序号从 0 开始。
index: 0
# 点 ID 的数据类型,可选值为 int 和 string,分别对应 NebulaGraph 中的 INT64 和 FIXED_STRING。
type: string
# Tag 设置。
tags:
# Tag 名称。
- name: person
# Tag 内的属性设置。
props:
# 属性名称。
- name: name
# 属性数据类型。
type: string
# 属性对应 CSV 文件中列的序号。
index: 1
- name: is_comfirmaed
type: bool
index: 2
# 本示例第二个数据文件为边的数据。
- path: ./person_livewith.csv
failDataPath: ./err/
batchSize: 100
limit: null
inOrder: true
type: csv
csv:
withHeader: false
withLabel: false
#delimiter: ","
schema:
# Schema 的类型为 edge。
type: edge
edge:
# Edge type 名称。
name: 同居
# 是否包含 rank。
withRanking: false
# 起始点 ID 设置。
srcVID:
# 数据类型。
type: string
# 起始点 ID 对应 CSV 文件中列的序号。
index: 0
# 目的点 ID 设置。
dstVID:
type: string
index: 1
rank: null
# Edge type 内的属性设置。
props:
# 属性名称。
- name: start_time
# 属性数据类型。
type: float
# 属性对应 CSV 文件中列的序号。
index: 2
- name: end_time
type: float
index: 3
2.数据模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0zzPat9H-1686046185434)(image/dataset-for-crud.png)]
-
图空间(Space)
图空间用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
如 mysql 的数据库概念, use xxx;
-
点(Vertex)
点用来保存实体对象,特点:
- 点是用点标识符(
VID)标识的。VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)。 - 点可以有 0 到多个 Tag。
如 neo4j 的 node 概念
- 点是用点标识符(
-
边(Edge)
- 两点之间可以有多条边。
- 边是有方向的,不存在无向边。
- 四元组
<起点 VID、Edge type、边排序值 (rank)、终点 VID>用于唯一标识一条边。边没有 EID。 - 一条边有且仅有一个 Edge type。
- 一条边有且仅有一个 Rank,类型为 int64,默认值为 0。
Rank 可以用来区分 Edge type、起始点、目的点都相同的边。该值完全由用户自己指定。
- 标签(Tag) (点的 table schema)
- Tag 由一组事先预定义的属性构成。
- 边类型(Edge type) 边的 table schema
- Edge type 由一组事先预定义的属性构成。
- 属性(Property)
- 属性是指以键值对(Key-value pair)形式表示的信息
Note:
NebulaGraph 中没有无向边,只支持有向边。(边需要有方向)

3.NebulaGraph 架构总览
NebulaGraph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
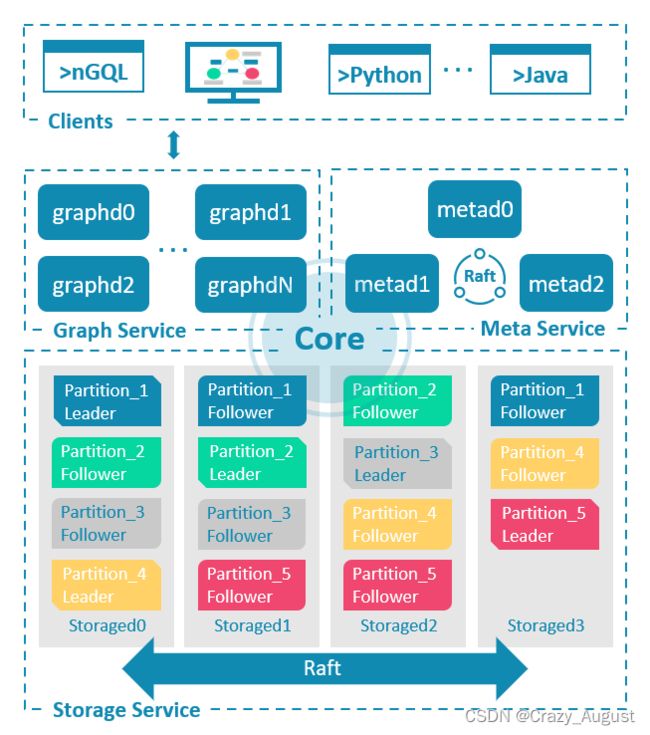
Meta 服务:
负责数据管理,如Schema操作,集群管理,和用户权限管理
Graph服务:
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤
Storage服务:
具体数据相关的存储
数据分片:
NebulaGraph 采用边分割的方式。并存储在不同逻辑分片(Partition)上,会发生切边与存储放大.
角色: 基于 Raft 协议的集群 leader follower
leader 是由多数派选举出来,只有 leader 能够对客户端或其他组件提供服务,其他 follower 作为候补,如果 leader 出现故障,会在所有 follower 中选举出新的 leader。

分片算法:
分片策略采用静态 Hash 的方式,即对点 VID 进行取模操作,同一个点的所有 Tag、出边和入边信息都会存储到同一个分片,这种方式极大地提升了查询效率。
创建图空间时需指定分片数量,分片数量设置后无法修改,建议设置时提前满足业务将来的扩容需求。
vid = hash(id.data()); # 将vid字符串求哈希
pId = vid % numParts + 1;

例如有 100 个分片,VID为 1、101 和 1001 的三个点将会存储在相同的分片。分片 ID 和机器地址之间的映射是随机的,所以不能假定任何两个分片位于同一台机器上。
4.基本命令文档
https://docs.nebula-graph.com.cn/3.2.1/2.quick-start/6.cheatsheet-for-ngql-command/#_7
4.0 数据类型
数值:
整数: INT64(INT)、INT32、INT16 和INT8。
浮点数: 精度浮点(FLOAT)和双精度浮点(DOUBLE),不支持 MySQL 中的 DECIMAL 数据类型。
当使用 nGQL 语句读取整形类型的属性时,获取到的值的类型是 INT64 ,读取浮点数,都被转为 DOUBLE
布尔:
true 或 false
字符串:
STRING变长字符串,FIXED_STRING() 定长字符串
日期和时间类型:
DATE、TIME、DATETIME、TIMESTAMP 和 DURATION
NULL:
插入点或边时,属性值可以为NULL,用户也可以设置属性值不允许为NULL(NOT NULL)
复合数据类型(例如 List、Set、Map)不能存储为点或边的属性。
列表:
数组 [1,2,3]
集合(Set):
集合中的元素是无序的,且不允许重复。 set{1, 2, 1}
映射 (Map):
一个映射是一组键值对(Key-Value)的无序集合,Key 是字符串类型,Value 可以是任何数据类型。map{key1: ‘Value1’, Key2: ‘Value2’}
地理位置:
Point、LineString 和 Polygon 三种地理形状。
4.1 spaces图空间
创建 spaces
CREATE SPACE
CREATE SPACE IF NOT EXISTS neo4j (partition_num=15, replica_factor=1,vid_type=FIXED_STRING(30)) comment="测试图空间";
graph_space_name,partition_num,replica_factor,vid_type,comment设置后就无法改变。要想改变就先删除在创建
删除 SPASCE
DROP SPACE
DROP SPACE IF EXISTS SPACE_NAME
删除 spaces 的点和边 (不包括 tag、edge schema信息)
CLEAR SPACE
下面信息不会被删除:
- Tag 信息。
- Edge type 信息。
- 原生索引和全文索引的元数据。
但所有的点和边都没了。
CLEAR SPACE IF EXISTS SPACE_NAME
查询 spaces
SHOW SPACES
DESC SPACE
# 查看所有数据库 show databases;
show spaces;
# 查看指定数据库
DESC SPACE ;
# 查看创建图空间语句
SHOW CREATE SPACE ;
4.2 Tag
创建 tag
# 创建有 name,age属性的tag
create tag if not exists tag_name (name string,age int)
# 创建没有属性的 Tag。
CREATE TAG IF NOT EXISTS tag_name();
# 创建包含默认值的 Tag。
CREATE TAG IF NOT EXISTS tag_name(name string, age int DEFAULT 20);
删除 tag
删除 Tag 操作仅删除 Schema 数据,硬盘上的文件或目录不会立刻删除,而是在下一次 Compaction 操作时删除。
确保 Tag 不包含任何索引,否则DROP TAG时会报冲突错误 [ERROR (-1005)]: Conflict!
DROP TAG tag_name
修改 tag
nebula> CREATE TAG IF NOT EXISTS t1 (p1 string, p2 int);
nebula> ALTER TAG t1 ADD (p3 int, p4 string);
nebula> ALTER TAG t1 TTL_DURATION = 2, TTL_COL = "p2";
nebula> ALTER TAG t1 COMMENT = 'test1';
nebula> ALTER TAG t1 ADD (p5 double NOT NULL DEFAULT 0.4 COMMENT 'p5') COMMENT='test2';
查询 tag
# 显示图空间的 tag
SHOW TAGS;
# 显示指定 Tag 的详细信息,例如字段名称、数据类型等。
DESCRIBE TAG tag_name;
删除指定点上的指定 Tag
DELETE TAG FROM ;
+------------------------------------------------------------+
| v |
+------------------------------------------------------------+
| ("test" :test1{p1: "123", p2: 1} :test2{p3: "456", p4: 2}) |
+------------------------------------------------------------+
nebula> DELETE TAG test1 FROM "test";
nebula> FETCH PROP ON * "test" YIELD vertex AS v;
+-----------------------------------+
| v |
+-----------------------------------+
| ("test" :test2{p3: "456", p4: 2}) |
+-----------------------------------+
# 对应的neo4j
remove v:label
4.3 edge
edge和tag类似
nebula> CREATE EDGE IF NOT EXISTS edge_name(degree int);
# 创建没有属性的 Edge type。
nebula> CREATE EDGE IF NOT EXISTS edge_name();
# 创建包含默认值的 Edge type。
nebula> CREATE EDGE IF NOT EXISTS edge_name(degree int DEFAULT 20);
# 对字段 p2 设置 TTL 为 100 秒。
nebula> CREATE EDGE IF NOT EXISTS edge_name(p1 string, p2 int, p3 timestamp) \
TTL_DURATION = 100, TTL_COL = "p2";
SHOW PARTS语句显示图空间中指定分片或所有分片的信息。
SHOW PARTS
4.4 点语句
INSERT VERTEX
指定图空间中插入一个或多个点。
# 正常插入
INSERT VERTEX person (name, age) VALUES "t_1":("肖在毅", 18);
# 一次插入 2 个点。
INSERT VERTEX person (name, age) VALUES "t_2":("肖在毅", 18),"t_3":("小明",18);
# 插入不包含 Tag 的点。
INSERT VERTEX VALUES "t_4'":();
# 插入不包含属性的点。
INSERT VERTEX person () VALUES "t_5":(),"t_6":()
IF NOT EXISTS仅检测 VID + Tag 的值是否相同,不会检测属性值。IF NOT EXISTS会先读取一次数据是否存在,因此对性能会有明显影响。
插入相同的语句,以最后一次为准 (后面把前面覆盖)
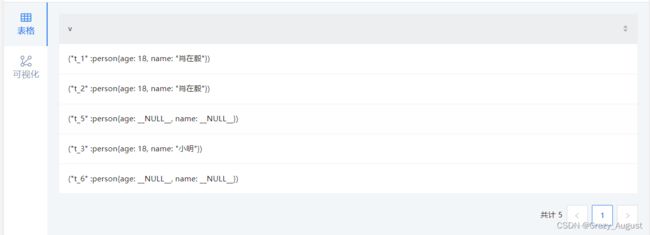
DELETE VERTEX
可以删除点,但是默认不删除该点关联的出边和入边。此时将默认存在悬挂边。
悬挂边:起点或者终点不存在与数据库中的边
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EvbRpuna-1686046185438)(image/image-20220921185118151.png)]](http://img.e-com-net.com/image/info8/0a1dbd6c96c94ce191cb4882535ce55c.jpg)
# 删除 VID 为 `t_5` 的点,不删除该点关联的出边和入边。
DELETE VERTEX "t_5"
# 删除 VID 为 `t_6` 的点,并删除该点关联的出边和入边。
DELETE VERTEX "t_6" WITH EDGE;
# 结合管道符,删除符合条件的点。可以一次删除多个点
UPDATE VERTEX
可以修改点上 Tag 的属性值。
# 无条件
UPDATE VERTEX ON person "t_1" SET age = age + 1
# 有条件
UPDATE VERTEX ON person "t_1" SET age = age + 1 WHEN name == "肖xxx"
# 修改并指定输出内容
UPDATE VERTEX ON person "t_1" SET age = age + 1 WHEN name == "肖xxx" YIELD name as name,age as age
UPSERT VERTEX
结合UPDATE和INSERT,如果点存在,会修改点的属性值;如果点不存在,会插入新的点。
UPSERT VERTEX ON person "t_7" SET age = 30,name = "小红" YIELD name AS Name, age AS Age;
4.5 边语句
INSER EDGE
在图空间中插入一条或多条边。边是有方向的,从起始点(src_vid)到目的点(dst_vid)。行方式为覆盖式插入。如果已有 Edge type、起点、终点、rank 都相同的边,则覆盖原边。
rank:可选项。边的 rank 值。默认值为0。
# 插入不包含属性的边。
CREATE EDGE IF NOT EXISTS e1();
INSERT EDGE e1 () VALUES "10"->"11":();
# 插入 rank 为 1 的边。
INSERT EDGE e1 () VALUES "10"->"11"@1:();
#属性
CREATE EDGE IF NOT EXISTS e2 (name string, age int);
INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 1);
# 一次插入 2 条边。
INSERT EDGE e2 (name, age) VALUES "12"->"13":("n1", 1), "13"->"14":("n2", 2);
- NebulaGraph 3.2.1 允许存在悬挂边(Dangling edge)。可以在起点或者终点存在前,先写边;此时就可以通过
或._src 获取到(尚未写入的)点 VID(不建议这样使用)。._dst
DELETE EDGE
删除边。一次可以删除一条或多条边。
DELETE EDGE e1 "10"->"11"@0;
#多条删除
DELETE EDGE e1 "10"->"11"@1,"11"->"12"@0;
如果不指定 rank,则仅仅删除 rank 为 0 的边。
UPDATE EDGE
可以修改边上 Edge type 的属性。
UPDATE EDGE ON e1 "10"->"11"@0
SET start_year = start_year + 1
WHEN end_year > 2010
YIELD start_year, end_year;
UPSERT EDGE
结合UPDATE和INSERT,如果边存在,会更新边的属性;如果边不存在,会插入新的边。
UPDATE EDGE ON e1 "10"->"11"@0
SET start_year = start_year + 1
WHEN end_year > 2010
YIELD start_year, end_year;
插入不存在的边
如果边不存在,无论
WHEN子句的条件是否满足,都会插入边,同时执行SET子句,因此新插入的边的属性值取决于:1.SET子句 2.属性是否有默认值。
4.6 通用查询
MATCH
注意: 以下三种情况之外,请确保
MATCH语句有至少一个索引可用。 1.WHERE 子句使用 id() 函数指定了点的 VID
2.遍历所有点边时,例如
MATCH (v) RETURN v LIMIT N使用LIMIT限制输出结果数量 3.遍历指定 Tag 的点或指定 Edge Type 的边时,
MATCH (v:player) RETURN v LIMIT N,使用LIMIT限制输出结果数量
目前 MATCH 语句无法查询到悬挂边。
# 匹配点
MATCH (v) RETURN v LIMIT 3;
# 匹配 Tag
MATCH (v:person) RETURN v LIMIT 3;
MATCH (v:player:person) RETURN v LIMIT 3;
# 匹配Tag的属性, 此操作需要先建立索引
MATCH (v:person{name:"肖xxx"}) RETURN v;
("t_1" :person{age: 22, name: "肖xxx"})
# 匹配点id
MATCH (v) WHERE id(v) == 't_1' RETURN v;
("t_3" :person{age: 18, name: "小明"})
# 匹配多个点的 ID --符号表示出边或入边
MATCH (v:person { name: '小明' })--(v2) WHERE id(v2) IN ["t_1", "t_2"] RETURN v2;
匹配连接的点
--符号表示两个方向的边,< > 符号指定边的方向。 与 neo4j 语法一致
MATCH (v:person { name: '小明' })--(v2) RETURN v2;
MATCH (v:person{name: '小明'})-->(v2:player) RETURN v2.player.name AS Name;
MATCH (v:person{name:"小明"})-->(v2)<--(v3) RETURN v3.player.name AS Name;
匹配路径
与 neo4j 语法一致
MATCH p=(v:person{name:"小明"})-->(v2) RETURN p;
匹配边
MATCH ()<-[e]-() RETURN e LIMIT 3;
匹配 Edge type
MATCH ()-[e:follow]->() RETURN e limit 3;
匹配边的属性
MATCH (v:person{name:"小明"})-[e:like{likeness:95.0}]->(v2) RETURN e;
# 匹配多个 Edge type,同时匹配多个 Tag 和多个 Edge type 时,不支持进行属性过滤。
MATCH (v:person{name:"小明"})-[e: like|:serve ]->(v2) RETURN e;
匹配多条边
MATCH (v:person{name:"小明"})-[]->(v2)<-[e:like]-(v3) RETURN v2, v3;
匹配定长路径
可以在模式中使用:
MATCH p=(v:person{name:"陈凤英"})-[e:同居*2]->(v2) RETURN e
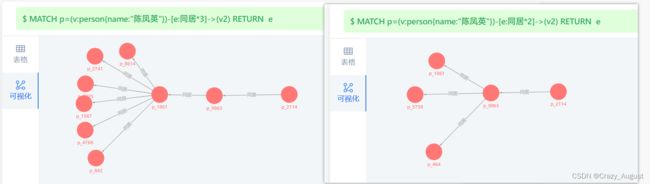
匹配变长路径
可以在模式中使用:
如果未指定minHop和maxHop,仅设置了:,则二者都应用默认值,即minHop为 1,maxHop为无穷大。
如果未设置
maxHop可能会导致 graph 服务 OOM
MATCH p=(v:person{name:"陈凤英"})-[e:同居*]->(v2) RETURN e
#等价于
MATCH p=(v:person{name:"陈凤英"})-[e:同居*1..]->(v2) RETURN e
MATCH p=(v:person{name:"陈凤英"})-[e:同居*1..3]->(v2) RETURN e
# 可以使用 DISTINCT 关键字聚合重复结果。
MATCH p=(v:person{name:"陈凤英"})-[e:同居*1..3]->(v2) RETURN DISTINCT e, count(v2);

# 匹配多个 Edge type 的变长路径
MATCH p=(v:person{name:"陈凤英"})-[e:同居|密接*1..3]->(v2) RETURN DISTINCT e, count(v2);
匹配多个模式
MATCH (v1:person{name:"陈凤英"}), (v2:student{name:"Spurs"}) RETURN v1,v2;
匹配最短路径
MATCH p = shortestPath( (v:person{name:"陈凤英"})-[e:同居*1..3]-(v2) ) RETURN p;
多MATCH检索
MATCH (m)-[]->(n) WHERE id(m)=="p_2114"
MATCH (n)-[]->(l) WHERE id(n)=="p_9863"
RETURN id(m),id(n),id(l);

MATCH总结:
NebulaGraph 3.2.1 中MATCH语句的性能和资源占用得到了优化.但对性能要求较高时,仍建议使用 GO, LOOKUP, | 和 FETCH 等来替代MATCH。
LOOKUP
LOOKUP根据索引遍历数据。使用LOOKUP实现如下功能:
-
根据
WHERE子句搜索特定数据。 -
通过 Tag 列出点:检索指定 Tag 的所有点 ID。
-
通过 Edge type 列出边:检索指定 Edge type 的所有边的起始点、目的点和 rank。
-
统计包含指定 Tag 的点或属于指定 Edge type 的边的数量。
条件:
确保LOOKUP语句有至少一个索引可用。
如果已经存在相关的点、边或属性,必须在新创建索引后重建索引,才能使其生效。
检索点
LOOKUP ON person WHERE person.name == "Tony Parker" YIELD id(vertex);
LOOKUP ON person WHERE person.name == "韦超"
YIELD properties(vertex).name AS name, properties(vertex).age AS age;
检索边
LOOKUP ON 同居 WHERE 同居.degree == 90 YIELD edge AS e;
LOOKUP ON follow WHERE follow.degree == 90 YIELD properties(edge).degree;
通过 Tag 列出所有的对应的点/通过 Edge type 列出边
LOOKUP ON person YIELD id(vertex),properties(vertex);
LOOKUP ON e1 YIELD edge AS e;
统计点或边
统计 Tag 为 person 的点和 Edge type 为 e1 的边。
LOOKUP ON person YIELD id(vertex) | YIELD COUNT(*) AS personr_Number;
LOOKUP ON e1 YIELD edge as e | YIELD COUNT(*) AS e1_Number;
SHOW STATS
GO
GO从给定起始点开始遍历图。GO语句采用的路径类型是walk,即遍历时点和边都可以重复。
REVERSELY | BIDIRECT:默认情况下检索的是的出边(正向),REVERSELY表示反向,即检索入边;BIDIRECT为双向,即检索正向和反向,通过返回字段判断方向,其正数为正向,负数为反向。._type
# 返回 player102 所属队伍。
GO FROM "player102" OVER serve YIELD dst(edge);
# 返回距离 p_1008 5 跳的朋友。
GO 5 STEPS FROM "p_1008" OVER 同居 yield dst(edge),properties(edge)
#添加过滤条件
GO 2 STEPS FROM "p_1008","p_6234" OVER 同居
WHERE properties(edge).start_time > 0.642652416e+09
yield dst(edge),properties(edge)
# 返回 p_1008 入方向的邻居点。
GO FROM "p_1008" OVER 同居 REVERSELY YIELD src(edge) AS destination;
#等价于
MATCH (v)<-[e:同居]-(v2) WHERE id(v) == 'p_1008'
RETURN id(v2) AS destination;
# 查询 p_1008 的同居的同居。
GO FROM "p_1008" OVER 同居 REVERSELY
YIELD src(edge) AS id |
GO FROM $-.id OVER 同居
YIELD properties($^).name AS Start, properties($$).name AS End;
等价于
MATCH (v)<-[e:同居]-(v2)-[e2:同居]->(v3)
WHERE id(v) == 'p_1008'
RETURN v2.person.name AS Start, v3.person.name AS End;
# 查询 p_1008 1~2 跳内的同居。
GO 1 TO 2 STEPS FROM "p_1008" OVER 同居
YIELD dst(edge) AS destination;
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
MATCH (v) -[e:同居*1..2]->(v2)
WHERE id(v) == "p_1008"
RETURN id(v2) AS destination;
# 复合查询
LOOKUP ON person WHERE person .name == "刘建华" YIELD id(vertex) as verID |
GO FROM $-.verID over 同居 where 同居.start_time == 1643256418.0 YIELD edge as e ;
FETCH
FETCH可以获取指定点或边的属性值。
获取点的属性值
# 基于 Tag 获取点的属性值
FETCH PROP ON person "p_1" YIELD properties(vertex);
# 获取点的指定属性值
FETCH PROP ON person "p_1"
YIELD properties(vertex).name AS name;
# 获取多个点的属性值
FETCH PROP ON person "p_1","p_2"
YIELD properties(vertex).name;
# 基于 Tag person 和 person1 获取点 p_1 上的属性值。
FETCH PROP ON person, person1 "p_1" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
+----------------------------------------------------------------------------+
# 在所有标签中获取点的属性值,在FETCH语句中使用*获取当前图空间所有标签里,点的属性值。
FETCH PROP ON * "p_1", "p_2", "c_1" YIELD vertex AS v;
获取边的属性值
# 获取边的所有属性值
FETCH PROP ON 同居 "p1" -> "p3" YIELD properties(edge);
# 获取边的指定属性值
FETCH PROP ON 同居 "p1" -> "p3" YIELD properties(edge).start_time;
# 获取多条边的属性值
FETCH PROP ON 同居 "p1" -> "p3", "p3" -> "p4" YIELD edge AS e;
# 基于 rank 获取属性值
# 默认返回 rank 为 0 的边。
FETCH PROP ON 同居 "p1" -> "p3" YIELD edge AS e;
# rank 为 10 的边。
FETCH PROP ON 同居 "p1" -> "p3"@10 YIELD edge AS e;
总结:
基本 nGQL 查询
- GO ,沿着给定的点进行一步或者多步拓展,返回最后一跳的起点,边,或者终点
- LOOKUP,从属性的条件反查点或者边,相应地,需要创建对应的点或者边上对应属性的的索引才行
- FETCH,直接取给定的点、边上的属性
路径子图 nGQL
- FIND PATH,查找两点间的路径
- GET SUBGRAPH,从一个点出发获得子图
Cypher DQL
- MATCH, 按照模式去查询,如果模式的起点条件里不能得出给定的 VID,大多数情况下像 LOOKUP 一样需要索引
4.7 状态查询
集群信息
SHOW HOSTS 语句可以显示集群信息,包括端口、状态、leader、分片、版本等信息,或者指定显示 Graph、Storage、Meta 服务主机信息。
SHOW HOSTS [GRAPH | STORAGE | META];
图空间信息
SHOW CREATE SPACE语句显示指定图空间的创建语句。
SHOW CREATE SPACE ;
SHOW CREATE {TAG | EDGE };
SHOW SPACES语句显示现存的图空间。
SHOW SPACES;
索引信息
SHOW INDEXES语句可以列出当前图空间内的所有 Tag 和 Edge type(包括属性)的索引。
SHOW {TAG | EDGE} INDEXES;
分片信息
SHOW PARTS语句显示图空间中指定分片或所有分片的信息。
SHOW PARTS [];
统计信息
SHOW STATS 查询图空间统计信息
条件:
在需要查看统计信息的图空间中先执行 SUBMIT JOB STATS
SUBMIT JOB STATS #会返回作业 id 号
SHOW JOB ID;
SHOW STATS;
查询 TAG、EDGE
SHOW {TAGS | EDGES};
查询创建索引状态
SHOW INDEX STATUS 语句显示重建原生索引的作业状态,以便确定重建索引是否成功。
SHOW {TAG | EDGE} INDEX STATUS;
查询快照
SHOW SNAPSHOTS语句显示所有快照信息。
SHOW SNAPSHOTS;
5.索引介绍:
NebulaGraph 支持两种类型索引:原生索引 和 全文索引。索引会导致写性能大幅下降
索引并不用于查询加速。只用于:根据属性定位到点或边,或者统计点边数量。
长索引会降低 Storage 服务的扫描性能,以及占用更多内存。建议将索引长度设置为和要被索引的最长字符串相同。索引长度最长为 256。
介绍文档:https://www.siwei.io/nebula-index-explained/#%E5%88%B0%E5%BA%95-nebula-graph-%E7%B4%A2%E5%BC%95%E6%98%AF%E4%BB%80%E4%B9%88
使用索引步骤:
1.初次导入数据至 NebulaGraph。
2.创建索引。
3.重建索引。 (REBUILD {TAG | EDGE} INDEX [
4.使用 LOOKUP 或 MATCH 语句查询数据。
创建索引,或者删除并再次创建同名索引后,必须
REBUILD INDEX。否则无法在 MATCH 和 LOOKUP 语句中返回这些数据。
创建索引
CREATE INDEX 语句用于对 Tag、EdgeType 或其属性创建原生索引。通常分别称为“Tag 索引”、“Edge type 索引”和“属性索引”。
# Tag 索引
CREATE TAG INDEX IF NOT EXISTS person_index on person();
# Tag 属性索引
CREATE TAG INDEX IF NOT EXISTS person_name_index on person(name(20));
# Edge type 索引
CREATE EDGE INDEX IF NOT EXISTS follow_index on follow();
# Edge type 属性索引
CREATE EDGE INDEX IF NOT EXISTS follow_time_index on follow(time(10));
#创建复合索引
CREATE TAG INDEX IF NOT EXISTS person_name_age_index on person(name(20),age);
查询索引
SHOW {TAG | EDGE} INDEXES;
DESCRIBE {TAG | EDGE} INDEX ;
重建索引
为什么要重建索引?
原因:
1.索引功能不会自动对其创建之前已存在的存量数据生效
2.索引的重建未完成时,依赖索引的查询仅能使用部分索引,因此不能获得准确结果。
REBUILD {TAG | EDGE} INDEX [];
例如:
REBUILD TAG INDEX person_index
REBUILD EDGE INDEX follow_index
# 查看是否执行成功
SHOW {TAG | EDGE} INDEX STATUS
可以一次重建多个索引,索引名称之间用英文逗号(,)分隔。如果没有指定索引名称,将会重建所有索引。
通过修改配置文件中的
rebuild_index_part_rate_limit和snapshot_batch_size两个参数,可优化重建索引的速度,另外,更大参数可能会导致更高的内存和网络占用
删除索引
DROP TAG INDEX IF EXISTS person_index;
6.数据压力测试
导入数据
使用 LDBC 数据集
地址:https://github.com/vesoft-inc/nebula-bench/blob/master/README_cn.md
git clone https://github.com/vesoft-inc/nebula-bench.git
cd nebula-bench
pip3 install -r requirements.txt
python3 run.py --help
# 生成 LDBC 数据
python3 run.py data
会自动下载 Hadoop,然后使用 ldbc_snb_datagen 生成数据。 为了方便 importer 导入,将生成后的文件拆分了一个带头的 header 文件,再去掉原有文件第一行。 默认生成的文件在 ${PWD}/target/data/test_data/。
7.集群的搭建
192.168.0.186 192.168.0.187 192.168.0.188
免密配置:
ssh-keygen -t rsa
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id 192.168.0.186
ssh-copy-id 192.168.0.187
ssh-copy-id 192.168.0.188
文件分发配置
#!/bin/bash
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
for host in 192.168.0.186 192.168.0.187 192.168.0.188 # 循环读取主机
do
echo ==================== $host ==================== # 得到主机名
for file in $@ #遍历所有目录,挨个发送
do
# 判断文件是否存在
if [ -e $file ]
then
# 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
# 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
下载安装包:
wget https://oss-cdn.nebula-graph.com.cn/package/3.3.0/nebula-graph-3.3.0.el7.x86_64.tar.gz
安装:注意相关版本更新
tar -xvzf nebula-graph-3.3.0.el7.x86_64.tar.gz -C /usr/local
mv nebula-graph-3.3.0.el7.x86_64 nebula
修改配置文件 nebula-graphd.conf , nebula-storaged.conf , nebula-metad.conf
--meta_server_addrs=192.168.0.186:9559,192.168.0.187:9559,192.168.0.188:9559
--local_ip=192.168.0.186
分别启动三台服务
nebula.service start all
nebula.service start all
nebula.service status all
操作ADD HOSTS
ADD HOSTS 192.168.0.186:9779,192.168.0.187:9779,192.168.0.188:9779
show HOSTS

进行密码修改:
ALTER USER root WITH PASSWORD 'xxxx.111';
scp -r twitter [email protected]:/usr/local/nebula/importcsv
xxxwxxcl.D11