HTTP基础知识
http属于TCP/IP协议族的一个子集
http的作用:
用来生成针对Wed服务器的HTTP请求报文
URI:标识互联网上的资源
URL:标识互联网资源的地址
URL(URI)(网址)的格式:
http://登录信息@域名:端口号文件路径(查询字符串#片段标识符)
登录信息包含用户名和密码,用来在服务端登录使用。
http请求报文的构成:
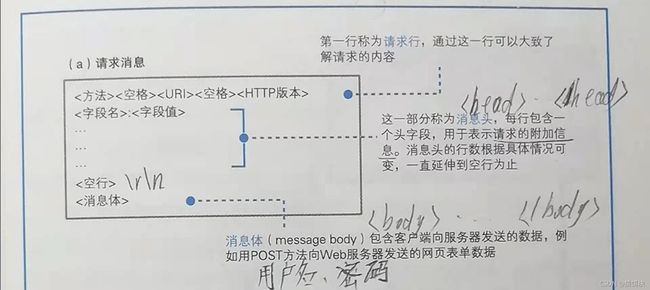
注意:这里的空格不一定是单一个空格,而是空格或者'\t'

HTTP各部分的连接
想要正确解析HTTP请求,一定要知道各部分之间的连接字符
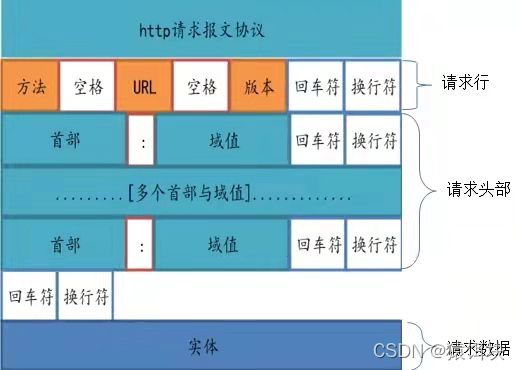
可见,HTTP每一行都以”回车换行“符(\r\n)结尾,
而消息头和消息体之间有两个回车换行符,也就是多出一个空行
请求行:
协议版本现在基本上都是1.1版本的,1.0,0.9的基本不用了
消息头:
消息头中的信息类型由首部标识
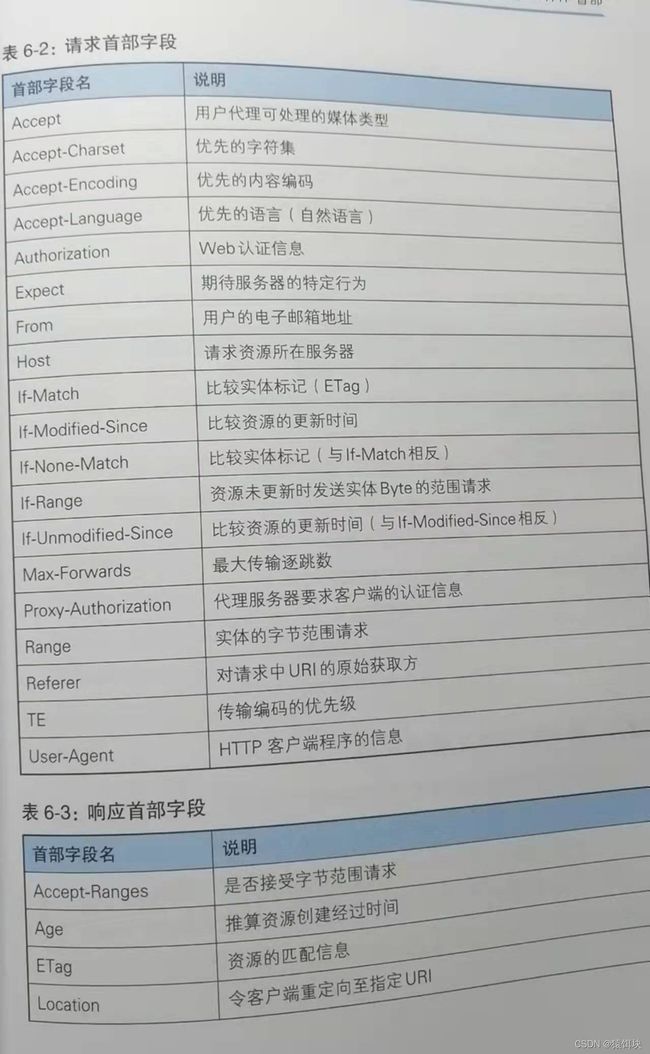
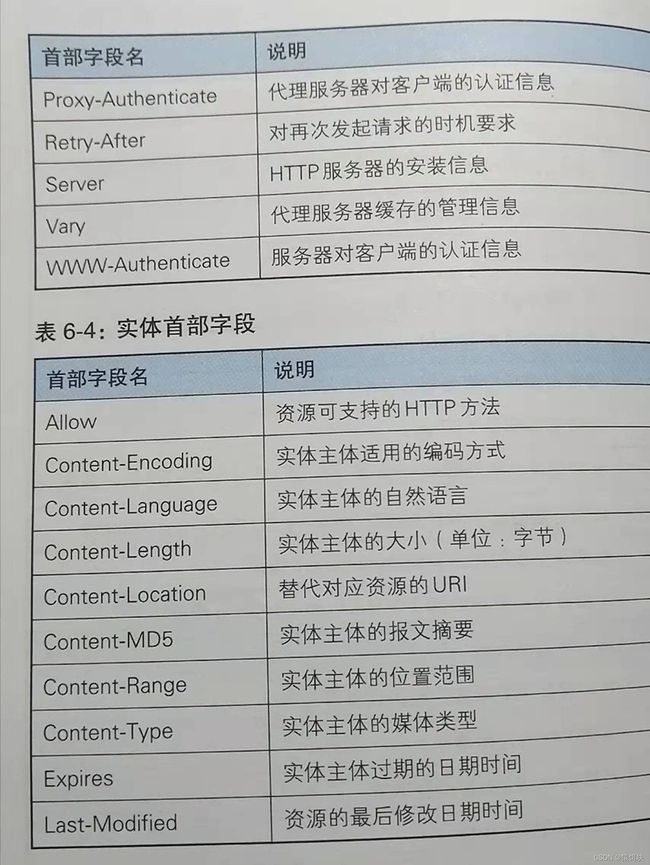
HTTP首部组成:
字段名:字段值
host:
是要访问的服务器主机,字段值是主机域名
connection:
是否需要保持连接的设置
如果字段值为:keep-alive
那就是要求保持持久连接
Content-Type:
是消息体的对象类型
Content-Length:
消息体内容的长度()。
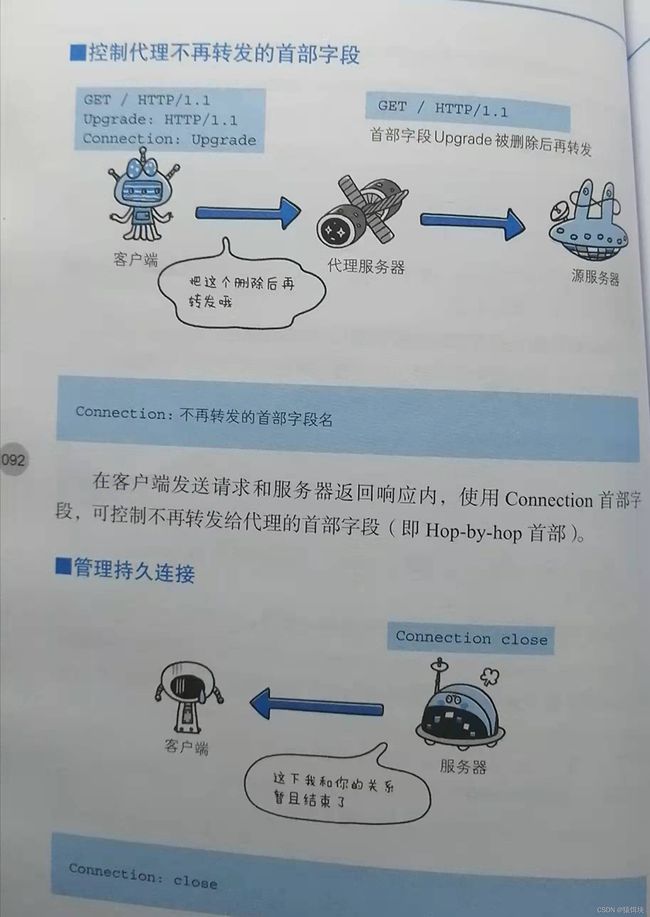
HTTP首部字段:

实体主体就是这报文
还有其他HTTP首部,需要时可 查阅。


http响应报文的构成:
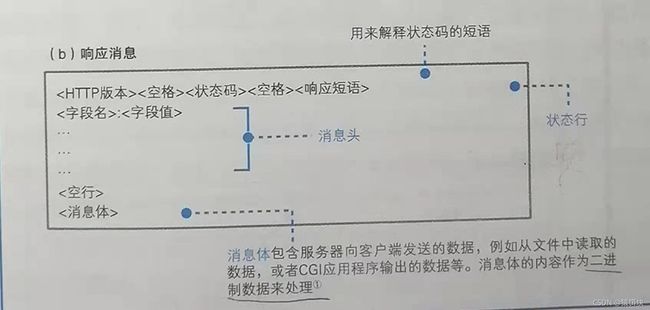
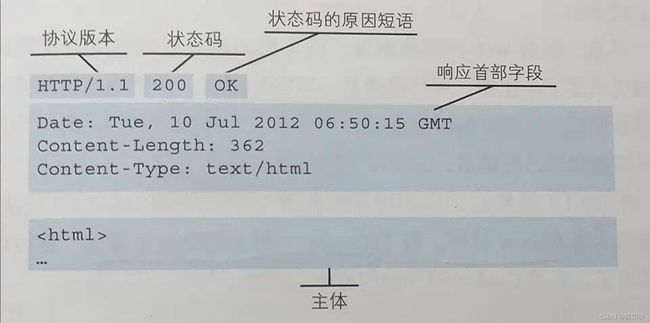
响应行:
状态码和状态原因短语:
状态码告知客户端从服务器返回的请求结果
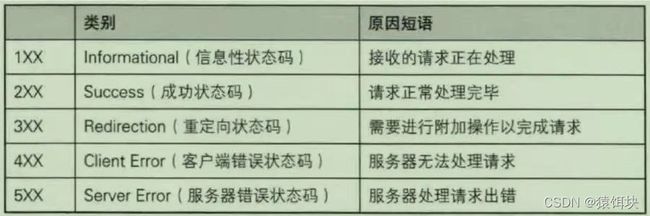
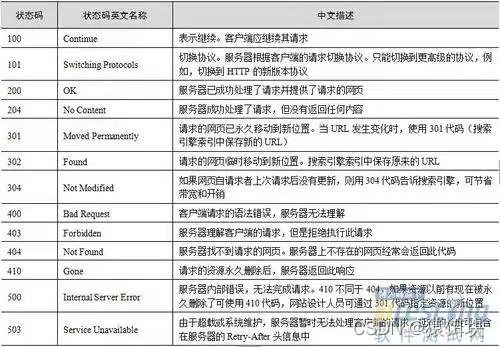
比较重要的:
200
304:通过在请求头中加上首部(eg:If -Modified-Since,If-None-Match),告诉服务器,如果客户端本次要请求的数据上次请求过,将服务器的这个数据和上一次请求的数据作比较,如果没有改动,那么就无需要返回这个数据,直接使用客户端缓存中的数据就可以了。
响应头:
Date:创建HTTP响应报文的时间和日期
http的持久连接和Cookie状态管理:
非持久的http连接:
请求一次数据,建立一次连接
持久的http连接:
建立一次连接,可以请求多次数据,直到一方发起连接关闭。
持久连接的基础上,http还可以进行“管线化”数据传输:从前发送请求需要等待接收到响应才可以发送下一个请求,管线化技术可以并行发送多个请求
Cookie状态管理:
http协议是无状态协议,即不记录之前发生过的请求和响应的状态。但是很多情况下,有需要之前请求和响应的数据状态,所以产生了Cookie技术。
Cookie技术通过在请求和响应的报文中写入Cookie信息来控制和记录客户端的状态
Cookie会根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie,当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。
服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
cookie 可以用于标识一个用户。用户首次访问一个站点时,可能需要提供一个用户标识(可能是名字)。在后继会话中,浏览器向服务器传递一个cookie首部,从而向该服务器标识了用户。因此cookie可以在无状态的HTTP之上建立一个用户会话层。例如,当用户向一个基于Web的电子邮件系统(如Hotmail)注册时,浏览器向服务器发送cookie信息,允许该服务器在用户与应用程序会话的过程中标识该用户。
S:我已经记住你了,记得把你在我这的OD号记下来,下次来记得带上,我就知道你是谁了
C:好的好的。
http方法:
GET:获取服务器的资源,(也可以传输数据)
POST:传输数据或者文件(比如登陆的用户名和密码)
HEAD:和GET一样,但是只需要返回响应报文的头部,不需要响应报文的主体
PUT:传输文件
DELETE:删除文件
OPTIONS:查看服务器允许使用 的HTTP方法
get和post的区别----
1、url可见性:
get,参数url可见;
post,url参数不可见
2、参数传输的位置:
get的参数通过拼接在url中传输;
post的参数通过body消息体传输;
3、数据缓存性:
因为get请求一般只是获取数据,不会修改数据,而post除了可以获取,还可以提交也就是修改,所以:
get请求是可以缓存的
post请求不可以缓存
什么是http缓存?\nhttp缓存指的是:当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。\n常见的http缓存只能缓存get请求响应的资源,对于其他类型的响应无能为力。
4、后退页面的反应
get请求页面后退时,不产生影响
post请求页面后退时,会重新提交请求
5、传输数据的大小
get一般传输数据大小不超过2k-4k(根据浏览器不同,限制不一样,但相差不大)
post请求传输数据的大小可以设定,也可以无限大。
6、安全性
这个也是最不好分析的,原则上post肯定要比get安全,毕竟传输参数时url不可见,但也挡不住部分人闲的没事在那抓包玩。安全性个人觉得是没多大区别的,防君子不防小人就是这个道理。对传递的参数进行加密,其实都一样。
7、数据包
GET产生一个TCP数据包;POST产生两个TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
管线化:
可以并行发送多个请求,不用等待一个请求得到响应再发送下一个请求
MIME type:
客户端请求的资源的类型。(媒体类型)
媒体类型通常是通过 HTTP 协议,由 Web 服务器告知浏览器的,更准确地说,是通过 Content-Type 来表示的,例如:
Content-Type: text/HTML
HTTP服务器程序需要做哪些处理:
想知道需要进行哪些处理,我需要知道,一个URL从客户端被发送到服务端,在服务端获取数据再将内容显示在客户端的整个过程:
http处理请求的步骤过程:
接收URL,对URL进行拆分,检测,对检测的结果进程处理,对处理的结果进行打包发送。
1 建立Tcp连接
注意linux下建立web服务器需要80端口号,需要root用户权限访问
2 读取http请求
3 解析http请求数据
处理的过程大致是把请求的信息解析出来,想要知道怎么处理HTTP请求,就要知道:
(1):接收到的数据(文件名)是什么
url的类型:
(静态文件)静态资源:
可以理解为前端的固定页面,这里面包含HTML、CSS、JS、图片等等,不需要查数据库也不需要程序处理,直接将文件复制发送给客户端,直接就能够显示的页面,如果想修改内容则必须修改页面,但是访问效率相当高。
(静态文件)动态资源:
需要程序处理或者从数据库中读取的数据(总之不是简单的读取数据,而是需要运行程序),将程序处理之后的数据返回给客户端
静态文件和动态文件如何区分和识别:
利用文件的拓展名
.html这些是静态文件
.cgi, .php是程序文件(动态文件)
(2):http请求报文的组成
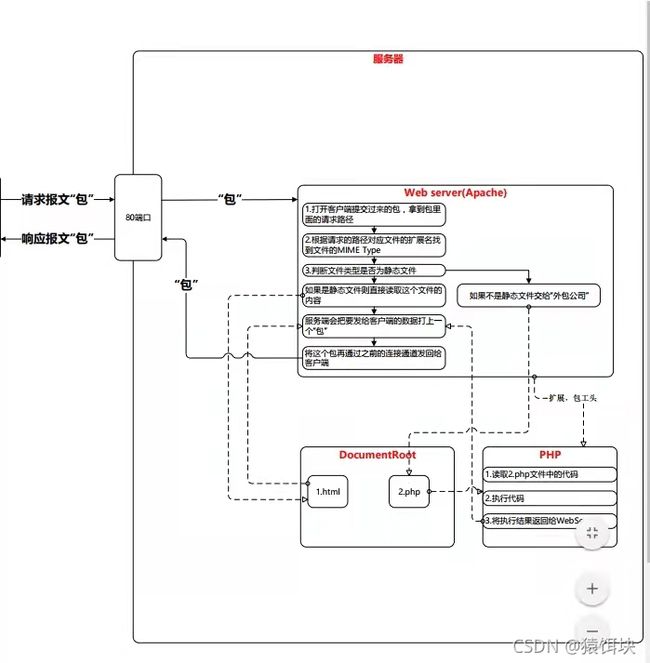
4 访问资源
访问资源可以是访问静态资源,这个就直接根据url地址去服务器里寻找,然后发送给客户端就好了。
访问动态资源的话要经过一个叫CGI的东西,再用服务端脚本处理,再返回给前端。如下图所示

5 构建响应
要是找到资源,则构建响应信息,包括响应的对象类型,长度,状态码。
另一个情况是重定向响应,就是直接返回一个重定向,客户端看到之后,立刻再向重定向的地址发起请求。重定向的响应的状态码一般是3xx。
6 发送响应
把构建的响应发送给客户端
7 记录日志
服务端对这个请求响应过程进行记录。
状态机:
有限状态机:
定义:很多东西(数据)的模型就是有限状态机。
实现方式:
1,switch
2,if---else
3,enum