阶段一模块一学习笔记
文章目录
- 阶段一模块一学习笔记
-
- @[toc]
- 一、自定义持久层框架
-
- 1. JDBC问题总结:
- 2. 问题解决思路
- 3. 自定义框架设计
- 4. 实际项目目录分析
- 5. 优化
-
- 5-1: 将测试类方法
- 5-2: 仍存在问题:
- 5-3: 解决方式
- 6.课后小结以及个人思考
- 二、mybatis
-
- 1.相关概念
- 2.具体实现
- 3、优化:
- 2. mybatis常用标签:
- 3.mybatis缓存
-
- 3-1. 缓存概念:
- 3-2. 验证一级缓存:
- 3-3. 一级缓存源码分析
- 3-4. 二级缓存
- 4. 二级缓存自定义
- 5. mybatis插件
- 三、Mybatis架构原理
-
- 1. 架构设计
- 2. 主要构件及其相互关系
- 3. 二级缓存源码优先级别
- 4. 二级缓存的存取机制
- 5. 延迟加载
-
- 5-1 延迟加载概念:
- 5-2 实现
- 5-3 通过以上配置延迟加载,实现如果只查询一级用户信息,二级查询则不会执行
- 5-4 全局延迟加载
- 四、设计模式:
-
- 1. mybatis中用到的设计模式
- 2. 构建者模式
-
- 2-1.构建者模式概念
- 2-2. 例:分别构建出电脑的各个组件
- 2-3. mybatis中体现
- 3.工厂模式
-
- 3-1.简单工厂模式概念
- 3-2.例子
- 3-3.mybatis中体现
- 4.代理模式
-
- 4-1.代理模式概念
- 4-2.例子
- 4-3.mybatis中体现
前言:由于一段时间的外包生活,觉得自己技术开始落后,很多基础知识和底层已经遗忘殆尽。对所有的框架都所谓“知其然而不知所以然”,焦虑袭上心头的时候发现了拉勾高薪课程。目前学习完mybatis源码实现和spring手写ioc和aop,感受颇多。此文结合讲师的设计模式解析。自己总结并结合身边实例,输出自己学习内容。
相关拉勾课程输出笔记:模块一:房屋租赁流程理解设计模式(单例模式,代理模式,工厂模式)
专栏地址:拉勾专栏(持续更新…)
一、自定义持久层框架
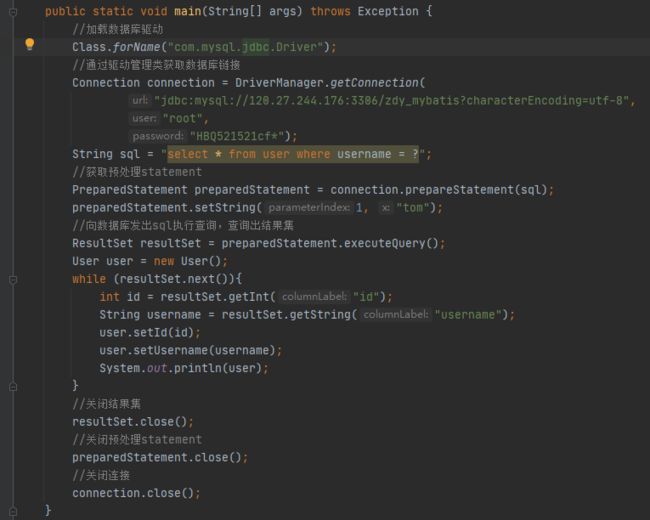
1. JDBC问题总结:
原始jdbc开发存在的问题如下:
- 数据库连接创建、释放频繁造成系统资源浪费,从而影响系统性能。
- Sql语句在代码中硬编码,造成代码不易维护,实际应用中sql变化的可能较大,sql变动需要改变
java代码。
- 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能
多也可能少,修改sql还要修改代码,系统不易维护。
- 对结果集解析存在硬编码(查询列名),sql变化导致解析代码变化,系统不易维护,如果能将数据 库
记录封装成pojo对象解析比较方便
2. 问题解决思路
- 使用数据库连接池初始化连接资源
- 将sql语句抽取到xml配置文件中
- 使用反射、内省等底层技术,自动将实体与表进行属性与字段的自动映射
3. 自定义框架设计
使用端:
提供核心配置文件:
- sqlMapConfig.xml : 存放数据源信息,引入mapper.xml
- Mapper.xml : sql语句的配置文件信息
框架端:
- 读取配置文件
读取完成以后以流的形式存在,我们不能将读取到的配置信息以流的形式存放在内存中,不好操作,可
以创建javaBean来存储
(1)Configuration : 存放数据库基本信息、Map<唯一标识,Mapper> 唯一标识:namespace + “.” +
id
(2)MappedStatement:sql语句、statement类型、输入参数java类型、输出参数java类型
- 解析配置文件
创建sqlSessionFactoryBuilder类:
if (connection != null) { try {connection.close(); } catch (SQLException e) { e.printStackTrace(); }} }
方法:sqlSessionFactory build():
第一:使用dom4j解析配置文件,将解析出来的内容封装到Configuration和MappedStatement中
第二:创建SqlSessionFactory的实现类DefaultSqlSession
- 创建SqlSessionFactory:
方法:openSession() : 获取sqlSession接口的实现类实例对象
- 创建sqlSession接口及实现类:主要封装crud方法
方法:selectList(String statementId,Object param):查询所有
selectOne(String statementId,Object param):查询单个
具体实现:封装JDBC完成对数据库表的查询操作
涉及到的设计模式:
Builder构建者设计模式、工厂模式、代理模式
4. 实际项目目录分析
- 使用端:
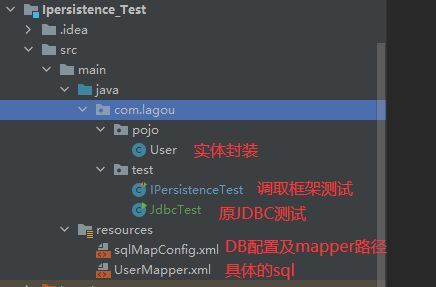
- 框架端:

- 源码:
git clone -b master1 https://gitee.com/idse666666/lagou.git
5. 优化
5-1: 将测试类方法

封装为分别的dao方法
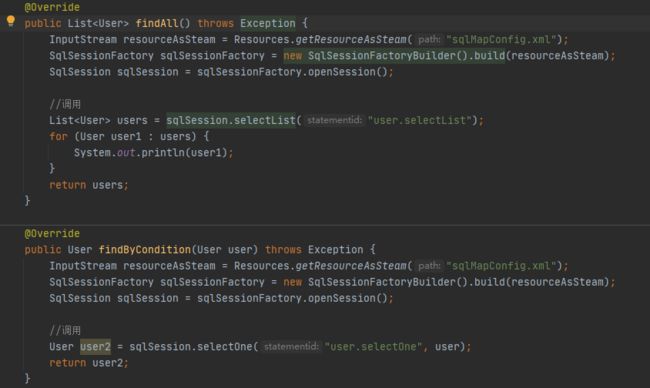
5-2: 仍存在问题:
- dao的实现类中存在重复的代码,整个操作的过程模板重复(加载配置文件、创建sqlsessionFactory,调用sqlsession方法)
- dao的实现类中存在硬编码,调用sqlsession的方法时,参数statement的id硬编码
5-3: 解决方式
- 使用代理模式生成dao层接口的代理实现类
- SqlSessionImpl中添加如下方法

- 使xml中的路径对应上到层路径,xml方法名对应dao层方法名,此时就可以删除UserDao的接口实现类了
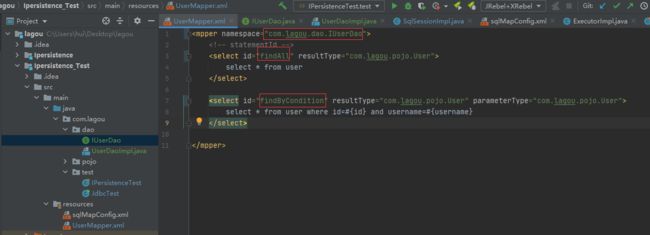

- 源码:
git clone -b master2 https://gitee.com/idse666666/lagou.git
6.课后小结以及个人思考
- 课后练习:

- 个人思考:mybatis的自定义实现是:xml配置方式记录数据库连接信息以及想要执行的sql->以文件流形式传入到框架端->框架端解析后利用其构建sqlsessionFactory工厂->使用工厂生产sqlsession->sqlsession实现具体的sql方法->有参数的sql需要使用对应工具类->优化过程使用代理模式,用dao层的包名.方法名巧妙映射xml中的namespace.id 从而解决了硬编码,代码重复问题
二、mybatis
1.相关概念
- ORM:ORM完成面向对象的编程语言到关系数据库的映射;ORM框架实现的效果:把对持久化对象的保存、修改、删除 等操作,转换为对数据库的操作
- 简介:MyBatis是一款优秀的基于ORM的半自动轻量级持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis可以使用简单的XML或注解来配置和映射原生类型、接口和Java对象为数据库中的记录。
- Mybatis的优势:Mybatis是一个半自动化的持久层框架,对开发人员开说,核心sql还是需要自己进行优化,sql和java编码进行分离,功能边界清晰,一个专注业务,一个专注数据。
2.具体实现
- 编写SqlMapperConfig.xml,其中配置mapper.xml信息

- UserMapper.xml信息

- 生产出sqlsession后调用其selectList接口即可,添加insert,修改update,删除delete。除了查询都需要提交事务。传递参数信息。

3、优化:
- 优化一:使用dao层实现,实则仍需要加载配置文件创建工厂以及生产sqlsession:

- 源码:
git clone -b master3 https://gitee.com/idse666666/lagou.git
- 省略掉dao层实现,直接将mapper.xml的namespace对应到dao的资源包

- 使用配置文件

2. mybatis常用标签:
- 一对一映射:association
- 一对多映射:collection
- 判断:if
- 循环:foreach
//例:
and u.depa_code in
#{item}
- 源码
git clone -b master4 https://gitee.com/idse666666/lagou.git
3.mybatis缓存
3-1. 缓存概念:
- 缓存就是内存中的数据,常常来自对数据库查询结果的保存,使用缓存,我们可以避免频繁的与数据库进行交互,进而提高响应速度
- 一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的
- 二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的

3-2. 验证一级缓存:
- 一级缓存验证


- 总结:
2-1. 第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从 数据
库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
2-2. 如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的 一级
缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
2-3. 第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直 接从
缓存中获取用户信息


3-3. 一级缓存源码分析
- 找到源码的存储结构为HashMap

- 在执行query方法时,判断缓存的存在状态,存在直接取出,不存在查询数据库

查询数据库得到结果后放入一级缓存中

3-4. 二级缓存
//sqlMapConfig.xml中
//mapper.xml中
//或者注解方式在mapper接口上方
@CacheNamespace
//同时要注意实体类需要序列化
User implements Serializable
验证
- 多个session在同一个mapper的namespace中,不同session会缓存数据

- 同一个mapper的namespace中有一个提交了增删改事务,二级缓存清空

二级缓存附加配置:mybatis中还可以配置userCache和flushCache等配置项
- useCache=true(默认)改为false时禁用该statement二级缓存
- flushCache=true(默认)改为false时禁用该statement提交事务后时刷新二级缓存(可能出现脏读)
4. 二级缓存自定义
- 因为mybatis自带的二级缓存无法在分布式环境下正常使用,选用redis作为分布式缓存
- 使用
@CacheNamespace(implementation = RedisCache.class)注解,使用redis缓存
- 查阅源码可知 redis配置文件名称固定:redis.properties;redisCache为HashMap
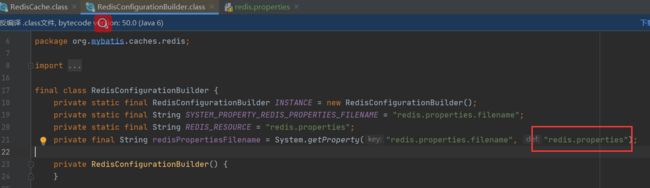
- 验证结果

5. mybatis插件
三、Mybatis架构原理
1. 架构设计

2. 主要构件及其相互关系


3. 二级缓存源码优先级别
二级缓存>一级缓存>数据库
4. 二级缓存的存取机制
-
只有提交了SqlSession.commit(),后二级缓存才被真正写入
-
存储二级缓存对象的时候是放到了TransactionalCache.entriesToAddOnCommit这个map中,但是每次查询的时候是直接从TransactionalCache.delegate中去查询的,所以这个二级缓存查询数据库后,设置缓存值是没有立刻生效的,主要是因为直接存到 delegate 会导致脏数据问题
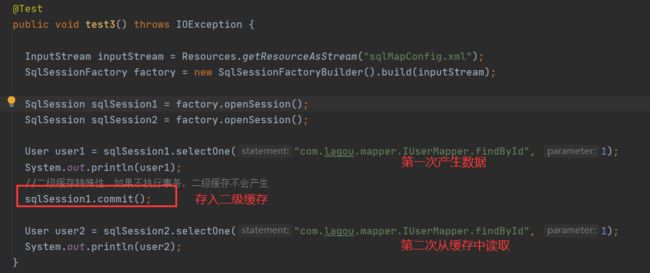
-
MyBatis二级缓存只适用于不常进行增、删、改的数据,比如国家行政区省市区街道数据。一但数据变更,MyBatis会清空缓存。因此二级缓存不适用于经常进行更新的数据。
-
源码 git clone -b master6 https://gitee.com/idse666666/lagou.git
5. 延迟加载
5-1 延迟加载概念:
- 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载。
- 优点:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表 速度要快。
- 缺点:因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗时 间,所以可能造成用户等待时间变长,造成用户体验下降
5-2 实现
//1.返回resultMap
//2.设置fetchType="lazy,并指定子查询的全路径和参数值
//3.子查询,需要id作为参数值

