YOLOv5:对yolov5n模型进一步剪枝压缩
YOLOv5:对yolov5n模型进一步剪枝压缩
- 前言
- 前提条件
- 相关介绍
- 具体步骤
-
- 修改yolov5n.yaml配置文件
- 单通道数据(黑白图片)
-
- 修改models/yolo.py文件
- 修改train.py文件
- 剪枝后模型大小
- 参考
前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
- 剪枝是一种通过去除网络中冗余的channels,filters, neurons, or layers以得到一个更轻量级的网络,同时不影响性能的方法。
具体步骤
修改yolov5n.yaml配置文件
- YOLOv5相关YAML配置里面参数含义,可查阅YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层:
https://blog.csdn.net/FriendshipTang/article/details/130375883- 这里顺带解释一下,
depth_multiple和width_multiple参数含义。
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
- nc: 8 代表数据集中的类别数目。
- depth_multiple: 0.33
- 用来控制模型的深度,仅在number≠1时启用。
- 如第一个C3层的参数设置为[-1, 3, C3, [128]],其中number=3,表示在yolov5s中含有 3 × 0.33 ≈ 1个C3。
- width_multiple: 0.50
- 用来控制模型的宽度,主要作用于args中的channel_out。
- 如第一个Conv层,输出通道数channel_out=64,那么在yolov5s中,会将卷积过程中的卷积核设置为 64 × 0.50 = 32,所以会输出 32 通道的特征图。
将
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
改为
depth_multiple: 0.16 # model depth multiple
width_multiple: 0.125 # layer channel multiple
即可达到减少卷积层数的目的。

单通道数据(黑白图片)
- 如果数据集是单通道数据,即黑白图片数据集,还可以修改训练时输入的通道数
(yolov5默认输入通道数ch=3,我们可以修改ch=1),减少训练参数。- 如果是彩色图片数据集,可跳过此部分的内容。
修改models/yolo.py文件
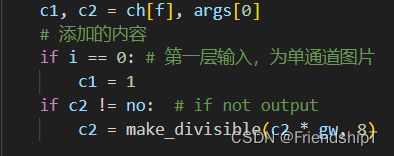
- 在
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
添加:
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
# 添加的内容
if i == 0: # 第一层输入,为单通道图片
c1 = 1
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
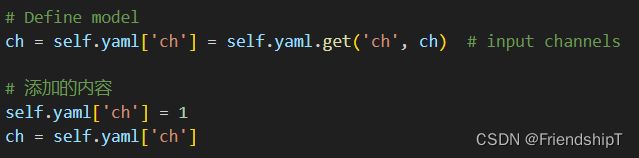
- 在
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
添加:
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
# 添加的内容
self.yaml['ch'] = 1
ch = self.yaml['ch']
修改train.py文件
- 将
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
改为
# 修改的内容
# model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
model = Model(cfg or ckpt['model'].yaml, ch=1, nc=nc, anchors=hyp.get('anchors')).to(device) # create
![]()
- 将
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
改为
# 修改的内容
# model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
model = Model(cfg, ch=1, nc=nc, anchors=hyp.get('anchors')).to(device) # create

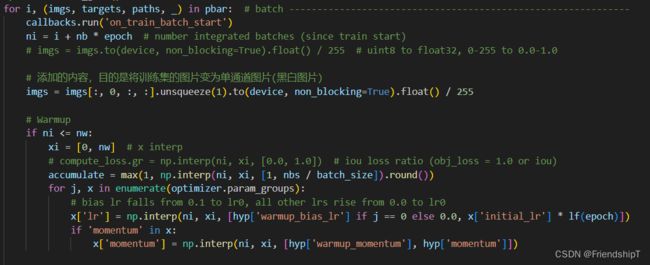
- 在
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
callbacks.run('on_train_batch_start')
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
添加:
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
callbacks.run('on_train_batch_start')
ni = i + nb * epoch # number integrated batches (since train start)
# imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# 添加的内容,目的是将训练集的图片变为单通道图片(黑白图片)
imgs = imgs[:, 0, :, :].unsqueeze(1).to(device, non_blocking=True).float() / 255
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
剪枝后模型大小
- 原来的yolo5n模型大小为3.5m,剪枝训练后的yolo5n模型大小为2.6m。
参考
[1] https://github.com/ultralytics/yolov5
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目