VL系列 Exchanging-based Multimodal Fusion with Transformer 论文阅读笔记
多模态融合 Exchanging-based Multimodal Fusion with Transformer 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 深度多模态融合
- 四、方法
-
- 4.1 低维投影和 embedding 归一化
-
- 低维投影
- Embedding 归一化
- 4.2 多模态交换
-
- Transformer 基础
- CrossTransformer
- 4.3 训练目标
- 五、实验
-
- 5.1 多模态命名实体识别部署
-
- 实施
- 结果
- 5.2 多模态情感分析
-
- 实施
- 结果
- 5.3 消融研究
- 5.4 超参数敏感分析
-
- 交换率 θ \theta θ
- 初始层 μ \mu μ
- 终止层 η \eta η
- 六、结论
写在前面
又是一个周末 & 教师节,祝老师们节日快乐呀。依惯例,论文读起来~
这是一篇多模态融合的文章,也算是这些年新出的一种方式了,具体还不知道啥情况,代码已开源,一试便知。
- 论文地址:Exchanging-based Multimodal Fusion with Transformer
- 代码地址:https://github.com/RecklessRonan/MuSE
- 预计投稿于:三大顶会之一。
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
最近有提出基于交换的方法用于视觉-视觉融合,旨在交换学习到的 embedding 到另一个模态,然而大多数方法将多模态输入特征投影到低维空间中且不能应用于序列数据。于是本文提出一种基于交换多模态 Transformer 模型 MuSE 用于文本-视觉融合。首先使用两个独立的编码器将多模态特征映射到低维空间上,然后应用两个解码器来归一化 embedding 并将其推入到相同的空间。基于这些 embedding,提出 CrossTransformer,使用两个共享参数的 Transformer 编码器作为 Backbone 模型来交换多模态的知识。具体来说,CrossTransformer 首先学习输入的全局上下文信息,之后选择某一模态中的 tokenss,用另一模态的平均 embedding 来代替。实验在 Multimodal Named Entity Recognition 多模态命名实体识别任务和 Multimodal Sentiment Analysis 多模态情感分析任务上进行。
二、引言
多模态融合很火,提出了一系列方法,例如 Multimodal Named Entity
Recognition (MNER)、Multimodal Sentiment Analysis (MSA)。早期的方法可划分为基于聚合的方法:首先用子网络表示每个模态,然后用不同的操作来聚合这些表示,例如拼接、自注意力等;基于对齐的方法:应用归一化的损失来对题不同子网络的 embedding。
最近基于交换的方法 CEN 提出解决模态内处理和模态间融合的权衡。然而此方法仅特定用于视觉-视觉融合,其通道交换不能直接应用在其他的多模态场景中,例如文本-视觉融合。主要存在两个挑战:一方面,CEN 隐式地假设两个模态均在相同的低维度 embedding 空间内,但文本和图像模态的距离太远,通常会对应到不同的空间上;另一方面,基于 CNN 通道的交换模式不能直接应用于文本,因为文本是 3 维序列,图像 4D 平面。于是有问题出现了,能够提出基于交换的模型用于融合文本和视觉?
于是本文提出基于交换的多模态融合方法 Multimodal fuSion method based on Exchanging(MuSE)。几种融合方式的比较如下图所示:
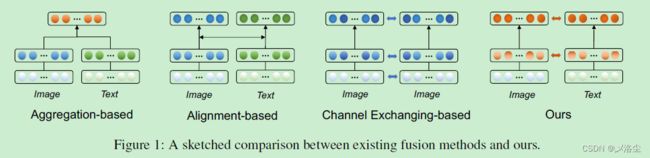
由于引言部分的最后一些内容与摘要重合,且详细版本在第三节里面,遂引言部分整体精简一些。
本文贡献总结如下:
- 将基于交换的方法从视觉-视觉融合泛化到文本-视觉融合,提出一种基于交换的方法,MuSE。
- 应用图像字幕任务和文本-图像生成任务来捕捉文本和图像的关联,联合归一化多模态 embedding,将其推到同一空间上。进一步设计 CrossTransformer,能够交换文本和图像间的知识。
- 在 MNER 和 MSA 任务上进行大量的实验,效果很好。
三、相关工作
3.1 深度多模态融合
早期的方法划分为两类:基于聚合的方法、基于对齐的方法。前者单独学习每个模态的表示,并从不同模态直接聚合这些学习到的表示,于是缺失了模态内交互信息。相比之下,基于对齐的方法采用归一化来对齐不同模态的分布,然而忽略了模态内的特性。有一些工作联合聚合和对齐的方法,但是需要精炼层级的设计,于是 可能会引入额外的计算损失。不同于上面这些方法,CEN 提出用于多模态,能够解决模态内的处理及模态间的权衡,而一些其他 CEN 的拓展方法,都受限于通道交换以及视觉-视觉融合。
四、方法
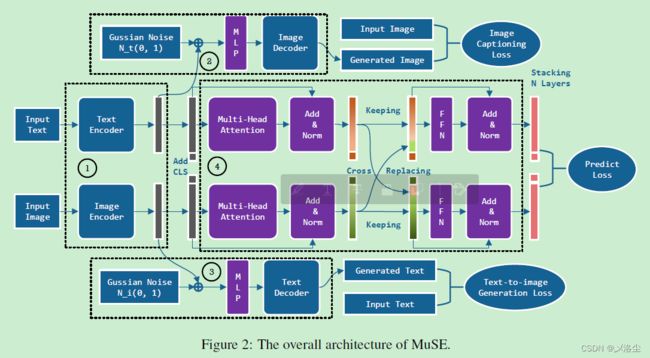
如上图所示,MuSE 主要由四个部分组成,①②③④。①将输入的文本和图像投影到低维度空间,其包含一个文本编码器和图像编码器。考虑到多模态数据可能会被映射到不同的空间上,于是提出两个 embedding 归一化 (两个解码器) ②③,将多模态输入的 embedding 推到同一空间上,分别执行文本-图像生成任务和图像字幕任务。在多模态输入的 embedding 生成后,将其输出到 ④,由一个基于 Transformer 的模块组成,称之为 CrossTransformer。CrossTransformer 执行多模态信息交换,最终聚合融合后的 embedding。
4.1 低维投影和 embedding 归一化
使用两个编码器-解码器的结构将输入的文本 T T T 和视觉 I I I 模态投影到相同的 embeding 空间上。
低维投影
T e = TextEncoder ( T ) I e = ImageEncoder ( I ) \begin{aligned} \mathbf{T}_{\mathbf{e}} & =\text { TextEncoder }(T)\\ \mathbf{I}_{\mathbf{e}} & =\text { ImageEncoder }(I) \end{aligned} TeIe= TextEncoder (T)= ImageEncoder (I)其中 TextEncoder 是一个典型的文本表示模型,例如 BERT,ImageEncoder 则是一个典型的 CNN 模型,例如 ResNet。具体来说,设置 T e \mathbf{T}_{\mathbf{e}} Te, I e ∈ R n × d \mathbf{I}_{\mathbf{e}}\in\mathbb{R}^{n\times d} Ie∈Rn×d,其中 n n n 为文本长度, d d d 为 embedding 维度。
Embedding 归一化

如上图所示,文本可以描述图像的字幕,而图像可以根据文本生成。为了捕捉文本和图像间的联系,设计了一个图像字幕任务和一个文本-图像生成任务。这两个任务通过两个解码器实施,旨在归一化编码器的 embeddings。对于图像字幕任务,编码器以图像 embedding 为输入,生成字幕文本。对于文本-图像生成任务,则是取反操作。整体流程总结如下:首先给文本和图像 embedding 增加随机噪声来增强模型的生成能力:
T n = MLP ( T e + N t ( 0 , 1 ) ) I n = MLP ( I e + N i ( 0 , 1 ) ) \begin{aligned} \mathbf{T}_{\mathbf{n}} & =\operatorname{MLP}\left(\mathbf{T}_{\mathbf{e}}+\mathcal{N}_{t}(0,1)\right)\\ \mathbf{I}_{\mathbf{n}} & =\operatorname{MLP}\left(\mathbf{I}_{\mathbf{e}}+\mathcal{N}_{i}(0,1)\right) \end{aligned} TnIn=MLP(Te+Nt(0,1))=MLP(Ie+Ni(0,1))其中 N t ( 0 , 1 ) \mathcal{N}_{t}(0,1) Nt(0,1) 和 N i ( 0 , 1 ) \mathcal{N}_{i}(0,1) Ni(0,1) 为高斯随机噪声。然后使用两个解码器生成图像 I ^ \hat I I^ 和文本 T ^ \hat T T^:
I ^ = I m a g e Decoder ( T n ) ( 5 ) T ^ = T e x t Decoder ( I n ) ( 6 ) \begin{aligned}\hat{I}&=\mathrm{Image}\text{Decoder}(\mathrm{T_n})\quad&(5)\\\hat{T}&=\mathrm{Text}\text{Decoder}(\mathrm{I_n})\quad&(6)\end{aligned} I^T^=ImageDecoder(Tn)=TextDecoder(In)(5)(6)其中 ImageDecoder 通常是个文本-图像生成模型,例如 PixelCNN,而 TextDecoder 是个图像字幕模型,例如 NIC。基于生成的图像和文本,将其与输入进行比较,并构建文本-图像生成损失 L t i \mathcal{L}_{ti} Lti 和图像字幕损失 L i t \mathcal{L}_{it} Lit,通过编码器,这俩损失归一化生成的文本和图像 embedding。相对于主任务来说,这俩都是辅助任务。
4.2 多模态交换
在得到文本和视觉模态的 embedding T e \mathbf{T}_{\mathbf{e}} Te 和 I e \mathbf{I}_{\mathbf{e}} Ie 后,接下来就是多模态交换过程。
Transformer 基础
这个老生常谈的话题,略过,只给出一些公式:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V \mathrm{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})=\mathrm{Softmax}(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}})\mathbf{V} Attention(Q,K,V)=Softmax(dkQKT)V在本文中仅使用 Transformer 编码器。
CrossTransformer
基于 Transformer,提出 CrossTransformer,使用两个共享参数的 Transformer 编码器来学习文本和视觉模态的 embeddings,并在其中交换多模态的信息。
CrossTransformer 如图 2 中的 ④ 所示。首先在文本和图像编码器输出的 embedding 上添加一个 clc,作为 CrossTransformer 的输入。之后输入向量的全局上下文信息首先要被学习,然后才进行交换。CrossTransformer 设定其浅层作为正常的 Transformer 编码器层,后面跟着一些交换层。当多模态融合完成,交换过程停止。为实现这一过程,引入两个超参数 μ \mu μ 和 η \eta η 分别控制信息交换的起始层和终止层。在每个交换层上,用最小注意力得分的比例选择其中一个模态的 tokens 到 cls 上,而用另一个模态的所有 tokens 的平均 embedding 向量来代替。
具体来说,给定文本和图像编码器输出的 embeddings T e \mathbf{T}_{\mathbf{e}} Te 和 I e \mathbf{I}_{\mathbf{e}} Ie,首先添加 cls 到这些 embedding 的开头位置,于是获得 CrossTransformer 的输入:
T e ( 0 ) = C o n c a t ( v c l s ( t 0 ) , T e ) I e ( 0 ) = C o n c a t ( v c l s ( i 0 ) , I e ) \begin{aligned}\mathbf{T}_e(0)&=\mathsf{Concat}\left(\mathbf{v}_{cls}(t_0),\mathbf{T}_e\right)\\\mathbf{I}_e(0)&=\mathsf{Concat}\left(\mathbf{v}_{cls}(i_0),\mathbf{I}_e\right)\end{aligned} Te(0)Ie(0)=Concat(vcls(t0),Te)=Concat(vcls(i0),Ie)其中 v c l s ( t 0 ) \mathbf{v}_{cls}(t_0) vcls(t0) 和 v c l s ( i 0 ) \mathbf{v}_{cls}(i_0) vcls(i0) 表示 cls 初始的 embedding。其中 n n n 为输入的文本长度, d d d 是 embedding 的维度。在 μ \mu μ 个 Transformer 编码器层后,获得更新后的 embedding T e ( μ ) \mathbf{T}_{\mathbf{e}}(\mu) Te(μ) 和 I e ( μ ) \mathbf{I}_{\mathbf{e}}(\mu) Ie(μ)。在第 μ + 1 \mu+1 μ+1 层,进入交换层,由三个子模块组成,第一个子模块计算多头自注意力,生成中间层 embedding T ~ e ( μ + 1 ) \tilde{\mathbf{T}}_e(\mu+1) T~e(μ+1) 和 I ~ e ( μ + 1 ) \tilde{\mathbf{I}}_e(\mu+1) I~e(μ+1);对于所有模态,第二个子模块选择 θ \theta θ 比例的最小注意力分数的 tokens 到 cls 中执行信息交换。假设对应于第 k k k 行的 T ~ e ( μ + 1 ) \tilde{\mathbf{T}}_e(\mu+1) T~e(μ+1) 被选择,其 embedding 向量更新如下:
T ~ e ( μ + 1 ) [ k , : ] = 1 n ∑ j = 1 n I ~ e ( μ + 1 ) [ j , : ] + T ~ e ( μ + 1 ) [ k , : ] \tilde{\mathbf{T}}_e(\mu+1)[k,:]=\frac{1}{n}\sum_{j=1}^n\tilde{\mathbf{I}}_e(\mu+1)[j,:]+\tilde{\mathbf{T}}_e(\mu+1)[k,:] T~e(μ+1)[k,:]=n1j=1∑nI~e(μ+1)[j,:]+T~e(μ+1)[k,:]其中应用残差连接来可以减少由于代替引起的信息丢失。类似的,更新 I ~ e ( μ + 1 ) \tilde{\mathbf{I}}_e(\mu+1) I~e(μ+1) 如下:
I ~ e ( μ + 1 ) [ k , : ] = 1 n ∑ j = 1 n T ~ e ( μ + 1 ) [ j , : ] + I ~ e ( μ + 1 ) [ k , : ] \tilde{\mathbf{I}}_{e}(\mu+1)[k,:] \begin{aligned}&=\frac{1}{n}\sum_{j=1}^n\tilde{\mathbf{T}}_e(\mu+1)[j,:]\end{aligned} +\tilde{\mathbf{I}}_{e}(\mu+1)[k,:] I~e(μ+1)[k,:]=n1j=1∑nT~e(μ+1)[j,:]+I~e(μ+1)[k,:]在信息交换后,第三个子模块将更新后的 embedding 矩阵输入到带有层归一化的 FFN 中来得到第 μ + 1 \mu+1 μ+1 层的输出 embedding:
T e ( μ + 1 ) = FFN ( T ~ e ( μ + 1 ) ) I e ( μ + 1 ) = FFN ( I ~ e ( μ + 1 ) ) \begin{aligned}\mathbf{T}_e(\mu+1)&=\text{FFN}(\tilde{\mathbf{T}}_e(\mu+1))\\\mathbf{I}_e(\mu+1)&=\text{FFN}(\tilde{\mathbf{I}}_e(\mu+1))\end{aligned} Te(μ+1)Ie(μ+1)=FFN(T~e(μ+1))=FFN(I~e(μ+1))交换过程一直持续到第 η \eta η 层结束。
最后拼接两个 Transformer 对的输出 embedding,将其送入全连接网络来得到最后的融合 embedding 矩阵 F e \mathbf{F}_e Fe。
4.3 训练目标
整体的优化目标函数为:
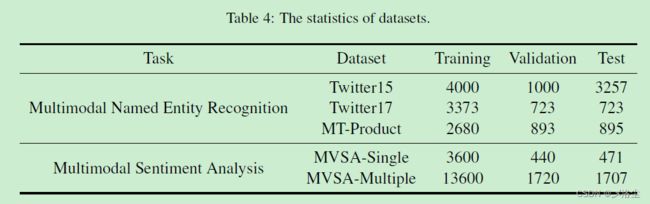
L = L t a s k + α L i t + β L t i \mathcal{L}=\mathcal{L}_{task}+\alpha\mathcal{L}_{it}+\beta\mathcal{L}_{ti} L=Ltask+αLit+βLti其中 L t a s k \mathcal{L}_{task} Ltask、 L i t \mathcal{L}_{it} Lit、 L t i \mathcal{L}_{ti} Lti 分别为主任务 (MNER/MSA),图像字幕任务、文本-图像生成任务的损失。 α \alpha α、 β \beta β 为两个平衡损失的权重超参数。所使用的数据集如下:
五、实验
两个任务:多模态命名实体识别 Multimodal Named Entity Recognition (MNER),给定输入图文对 T T T、 I I I,MNER 旨在从 T T T 中提取一组实体集合,并将每个实体分类到一个预定义的类别上;多模态情感分析 Multimodal Sentiment Analysis (MSA),将每个图文对分类到预定义的情感类型上。
ResNet、BERT、PixelCNN++、NIC-Att 分别用于图像编码器、文本编码器、图像解码器、文本解码器。Batch_size 40、学习率在 [ 1 e − 4 , 5 e − 5 , 1 e − 5 ] [1e-4,5e-5,1e-5] [1e−4,5e−5,1e−5] 中通过网格搜索得到最佳性能的学习率。图像编码器的输入图像尺寸 224 × 224 224\times224 224×224,被编码的图像尺寸为 [ 8 , 8 ] [8,8] [8,8],图像解码器的输入尺寸为 32 × 32 32\times32 32×32。在 CrossTransformer 中,保持与 Transformer 编码器设置相同,除了 dropout rate 在 [0.1,0.2,0.3,0.4] 中搜索。对于损失函数的选择,使用 CrossEntropy 用于 MNER 预测,MSA 预测图像字幕,使用混合的 logistic 损失,用于文本-图像生成,例如 PixelCNN++。对于 cls 的初始化,使用 Kaiming 初始化。实验在 6 张 V100 卡。
5.1 多模态命名实体识别部署
实施
将生成的融合 embedding F e \mathbf{F}_{e} Fe 送入 CRF 层用于 MNER 的预测。CRF 的学习率和 dropout rate 分别设置为 0.0001 和 0.5。
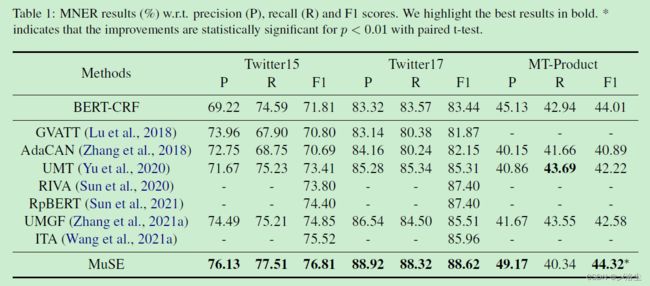
结果

5.2 多模态情感分析
实施
应用单层的 MLP 在融合的 cls token embedding 上来分类 MSA 中的情感,MLP 的 dropout rate 设为 0.5。
结果
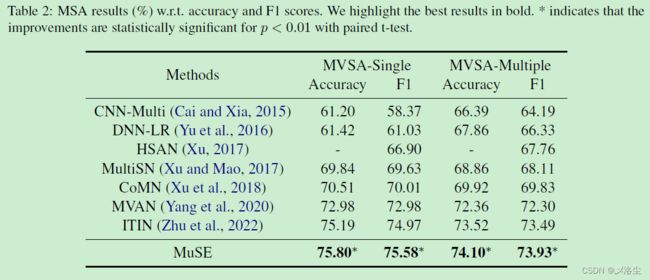
5.3 消融研究
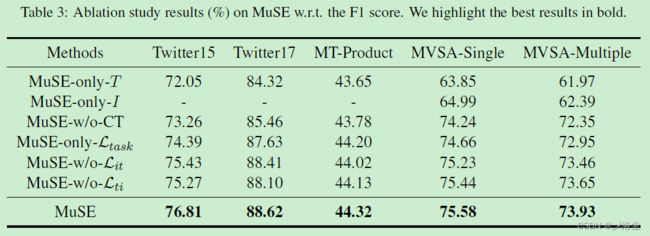
5.4 超参数敏感分析
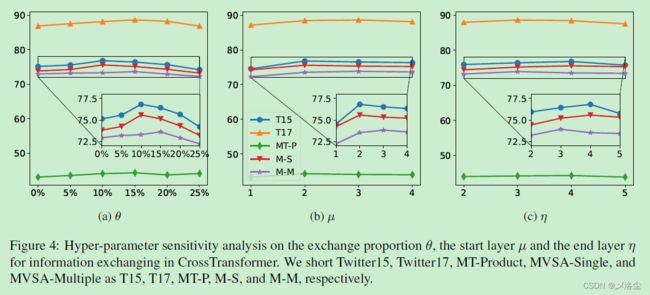
交换率 θ \theta θ
如图 4(a)。
初始层 μ \mu μ
如图 4(b)。
终止层 η \eta η
如图 4©。
六、结论
本文提出基于交换的模型 MuSE 用于多模态融合。MuSE 首先使用两个编码器将输入的文本和图像投影到低维空间,然后归一化 embedding,并用两个生成性解码器将其推送到同一空间上。通过两个任务捕捉图像文本间的关联:图像字幕和文本-图像生成。之后,基于归一化的 embedding,提出 CrossTransformer,通过交换不同模态的 token embedding 用于多模态融合。在 MNER 和 MSA 任务上表现很好,达到了 SOTA。
写在后面
这篇文章的写作好像有点问题,重复啰嗦了点。创新点还是可以的,多模态通道进行交互。接下来看看代码,看看有没有什么可取之处。跑是跑不了,6块 V100 的卡,租服务器也有点小贵了。