记一次前端项目构建发布优化--GitLab CICD篇
最近接了给前端项目构建发布做优化的任务,本次优化分为两个部分,一个部分是Gitlab CI/CD 的发布流程优化,另外一个部分是Webpack的打包优化。这篇文章先来讲讲Gitlab CI/CD方面的优化。
首先,我们先来过一遍Gitlab 执行CI/CD 的流程,以及Gitlab CI/CD一些重要的知识点。
什么是Gitlab CI/CD
CICD 是持续集成(Continuous Integration)、持续交付(Continuous Delivery)与持续部署(Continuous Deployment)的简称,意思是通过一系列自动化的脚本执行,实现开发过程中的代码的交付和部署。简单点说就是当程序员将代码上传到远程仓库以后,通过提前写好的脚本,可以自动地对项目进行打包构建、测试和部署上线。
由于公司的代码是托管在自建的 Gitlab 服务器上,而且GitLab也提供了免费的CI/CD,所以公司选择了Gitlab CI/CD 来作为公司项目的持续集成和持续交付工具。
在Gitlab CI/CD 中,一次完整的项目构建发布流程称为一个 Pipeline 。
而一个 Pipeline 由好几个 Stage 组成。这些 Stage 串行执行,只有当所有 Stage 完成后,该构建任务 ( Pipeline ) 才会成功。如果任何一个 Stage 失败,那么后面的 Stage 不会执行,该构建任务 ( Pipeline ) 失败。
在单个 Stage 中又可以定义多个 Job 。同一个 Stage 中的 Job 并行执行,相同 Stage 中的 Job 都执行成功时,该 Stage 才会成功,如果任何一个 Job 失败,那么该 Stage 失败,即该构建任务 ( Pipeline ) 失败。
所以 Pipeline 、 Stage 和 Job 的关系如下图所示:

而每一个 Job 在执行过程中都要经历如下过程:
1.Preparing the “docker” executor:配置docker执行环境,包含取得docker镜像
2.Preparing environment:启动docker
3.Get source from Git repository:从Git仓库取得源码
4.Restoring cache:如有配置缓存则重置回来
5.Download artifacts:如有工作成品则下载并且解压缩
6.Executing before script:执行前置脚本
7.Executing script:执行主要脚本
8.Executing after script:执行后置脚本
9.Saving cache:储存缓存
10.Uploading artifacts:上传工作成品
11.Cleaning up file base variables:清理基于文件的变量
流程分析
在我司前端项目的的CI/CD中目前定义了4个 stage ,每个 stage 中有一个 job :
1.build stage, build_prod job:构建静态文件,并且将文件复制到 home 机器上
- 根据lockfile文件安装依赖(耗时73.26秒)
- 打包代码生成build文件夹(耗时318.94秒)
- 将build文件夹内容发送到远程服务器

2.pre-deploy, stage copy_html job:将 HTML 模版文件复制到 gate 机器上

3.deploy stage, deploy_prod job:触发后台发布脚本的 web hooks,将模版文件部署到业务服务器上
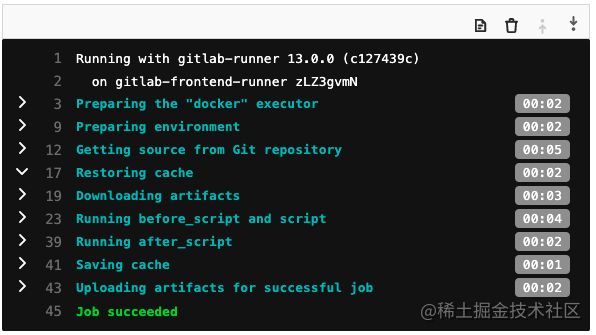
4.post-deploy stage, ding_success job:在上述任务成功/失败后,发送消息
从上面的流程分析中可以看出来,在时间上占大头的是项目的打包和项目依赖的缓存,这些关于webpack和node_modules的优化会在后面的文章详细说明。
CI/CD方面的优化主要聚焦于如何提高并行处理任务的能力,以及如何缩短单次任务的花费时间上。
优化方案
设置淘宝源
未设置淘宝源时安装某项依赖耗时86.23s:
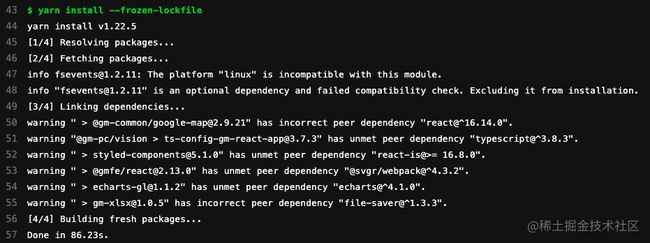
如果设置了 yarn config set registry 'https://registry.npm.taobao.org' 本身这个过程耗时0.15s

然后安装相同依赖耗时72.06s:
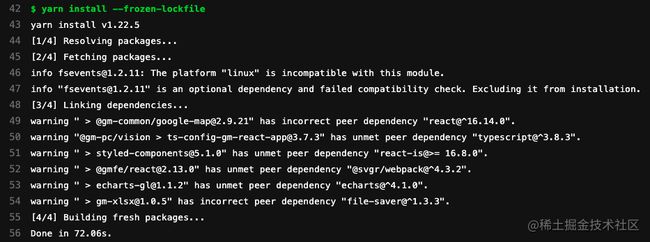
由此可见,通过设置淘宝源确实可以缩短安装依赖的时间。不过在我司定义的CI/CD流程中,会对node_modules进行缓存,每次项目跑CI/CD时都会优先使用缓存的node_modules,只有当依赖有更新时,才会安装新的依赖。对于一个已经成熟的老项目来说,很少有机会需要安装新的依赖,所以这种方式的优化效果并不明显。
并行处理pipeline
偶然发现,公司前端项目的单个开发分支在跑CI/CD时,其他分支的CI/CD会进入waitting状态。问了之前维护公司CI/CD的同事,他是通过 resource_group 关键字,对前端项目的CI/CD做了限制。
当在 .gitlab-ci.yml 文件中为job定义了 resource_group 关键字时,job执行在同一项目的不同pipeline中是互斥的。如果属于同一resource_group的多个job同时入队,则运行程序只会选择其中一个作业。其他job一直等到 resource_group 空闲。
之前的同事把所有的job都放入了同一个resource_group中。这样做的原因是他担心如果某个开发分支的CI/CD还没有跑完,有人又向该分支push了新的代码,那么该分支就会有两个pipeline同时在跑,这样就不知道项目最后运行的是哪次pipeline构建的代码了。
虽然这样做可以限制单个开发分支的pipeline串行执行,但是当某个开发分支的某个job在运行时,不仅该开发分支的其他job会进入waitting状态,其他开发分支的job也会进入waitting状态,也就是说整个项目的job都是串行执行。对于某个开发分支来说,其他开发分支在跑的CI/CD对它一点影响都没有。这种做法限制了Gitlab CI/CD并行处理任务的能力。
其实,如果单纯想限制单个开发分支的pipeline串行执行,可以在CI/CD配置文件加上 interruptible: true 。
interruptible启用后当新管道在同一分支上启动时,可以取消具有 interruptible: true 的正在运行的作业。
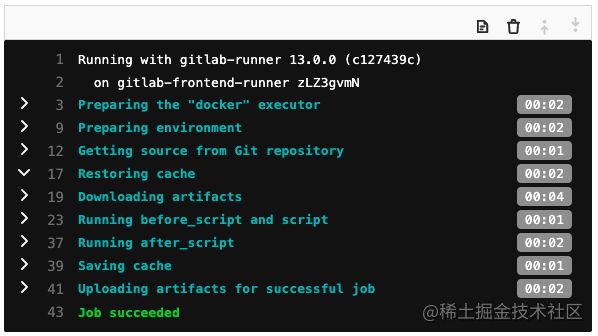
现在,可以同时运行多个pipeline的打包任务,而且同一分支旧的pipeline会自动取消:
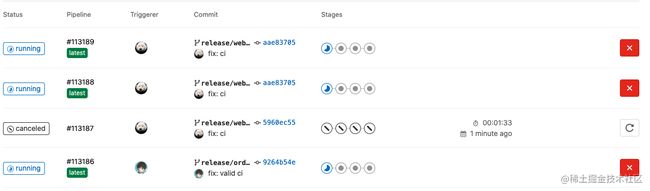
并行处理不相关的操作
通过之前的流程分析可以发现,在单次的pipeline中,有两个跟后端相关的stage,这两个stage的任务都是把前端打包好的文件复制到不同的服务器上。于是我向后端的同事询问了能否让这两个stage的任务放在同一个stage的不同job去并行执行,后端同事的答复是这两次stage存在依赖关系必须串行执行。所以并行处理后端相关任务的优化不可行。
合并需要同步执行的job
GitLab的runner在执行单个job的时候都需要一些时间去准备执行环境、缓存执行结果等等。既然两个跟后端相关的操作必须串行执行,那是否可以把两次任务合并成一个job,这样可以省去一些时间。不过后端的同事觉得把所有的操作都放在一个job里不方便debug,所以合并job的优化也不可行。