python导入导出文件
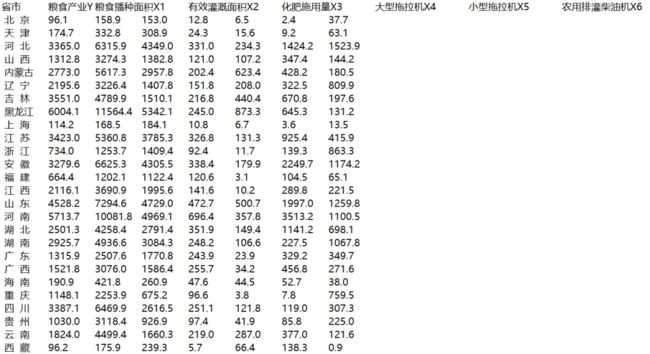
Ⅰ.原始数据(部分)

Ⅱ.调用pandas模块导入导出
ii.i.调用pandas模块导入
import pandas as pd
data1=pd.read_excel('数据.xlsx')
data2=pd.read_csv('数据.csv')
data3=pd.read_table('数据.txt')
data4=pd.read_csv('数据.txt',sep='\t')
data5=pd.read_table('数据.txt',sep='\t')结果均为:

ii.ii.调用pandas模块导出
import pandas as pd
data1=pd.read_excel('数据.xlsx')
file1=data1.to_excel('数据-副本.xlsx')结果为:

import pandas as pd
data1=pd.read_excel('数据.xlsx')
file2=data1.to_excel('数据-副本.xlsx',index=False)结果为:

import pandas as pd
data1=pd.read_excel('数据.xlsx')
file3=data1.to_csv('数据-副本.csv',encoding='gbk',index=False)结果为:

import pandas as pd
data1=pd.read_excel('数据.xlsx')
file4=data1.to_csv('数据-副本.txt',index=False)结果为:

import pandas as pd
data1=pd.read_excel('数据.xlsx')
file5=data1.to_csv('数据-副本.txt',sep='\t',index=False)结果为:
Ⅲ.调用numpy模块导入导出
iii.i.调用numpy模块导入
import numpy as np
data=np.loadtxt('数据.csv',delimiter=',',skiprows=0,dtype=str,encoding='utf-8-sig')
print(data)
import numpy as np
data=np.loadtxt('数据.txt',delimiter='\t',skiprows=0,dtype=str,encoding='utf-8-sig')
print(data)结果均为:

iii.ii.调用numpy模块导出
import numpy as np
data=np.loadtxt('数据.csv',delimiter=',',skiprows=0,dtype=str,encoding='utf-8-sig')
data2=np.asarray(data[1:,1:])
data3=np.array(data2,dtype='float64')
print(data3)
np.set_printoptions(suppress=True)
np.set_printoptions(precision=4)
file=np.savetxt('数据-副本.csv',data3,delimiter=',',fmt='%.04f')结果为:

Ⅳ.调用xlrd模块导入,调用xlwt模块导出
iv.i.调用xlrd模块导入
import xlrd
data1=xlrd.open_workbook('数据.xls')
sheet=data1.sheet_by_index(0)
for i in range(sheet.nrows):
print(sheet.row(i))结果为:

import xlrd
data2=xlrd.open_workbook('数据.xls')
sheet=data2.sheet_by_index(0)
nrows=sheet.nrows
for i in range(nrows):
print(sheet.row_values(i))
import xlrd
data3=xlrd.open_workbook('数据.xls')
sheet=data3.sheet_by_name(u'数据')
nrows=sheet.nrows
for i in range(nrows):
print(sheet.row_values(i))结果均为:

iv.ii.调用xlwt模块导出
import xlrd
import xlwt
data4=xlrd.open_workbook('数据.xls')
sheet=data4.sheets()[0]
rows=sheet.nrows
sheet_list=[]
for i in range(rows):
sheet_list+=[sheet.row_values(i)]
print(sheet_list)
workbook=xlwt.Workbook()
worksheet=workbook.add_sheet(u'数据')
for i in range(len(sheet_list)):
for j in range(len(sheet_list[i])):
worksheet.write(i,j,sheet_list[i][j])
workbook.save('数据-副本.xls')结果为:

Ⅴ.调用open模块导入导出
v.i.调用open模块导入
with open('数据.txt','r',encoding='utf-8') as f:
data1=f.read()
print(data1)
f=open('数据.txt','r',encoding='utf-8')
data2=f.read()
print(data2)
f.close()
f=open('数据.txt','r',encoding='utf-8')
while True:
data3=f.readline()
if not data3:
break
print(data3)
f.close()结果均为:

f=open('数据.txt','r',encoding='utf-8')
data4=f.readlines()
display(data4)
f.close()结果为:

with open('数据.csv','r',encoding='utf-8') as f:
data5=f.read()
print(data5)结果为:

v.ii.调用open模块导出
with open('数据.txt','r',encoding='utf-8') as f1:
data=f1.read()
with open('数据-副本.txt','w',encoding='utf-8') as f2:
f2.write(data)
f1=open('数据.txt','r',encoding='utf-8')
f2=open('数据-副本.txt','w',encoding='utf-8')
data=f1.read()
f2.write(data)
f1.close()
f2.close()结果均为:

Ⅵ.调用openpyxl模块导入导出
vi.i.调用openpyxl模块导入
from openpyxl import load_workbook
workbook=load_workbook('数据.xlsx')
sheet=workbook['Sheet1']
for rows in sheet['A1':'H32']:
for cells in rows:
print(cells.coordinate,cells.value)结果为:

vi.ii.调用openpyxl模块导出
from openpyxl.workbook import Workbook
# 资料为2014年中国粮食生产与相关投入,来源:《中国统计年鉴》(2014),其中港澳台数据未收录
data=[['省市', '粮食产业Y', '粮食播种面积X1', '有效灌溉面积X2', '化肥施用量X3', '大型拖拉机X4', '小型拖拉机X5', '农用排灌柴油机X6'],
[' 北 京', 96.1, 158.9, 153.0, 12.8, 6.5, 2.4, 37.7],
[' 天 津', 174.7, 332.8, 308.9, 24.3, 15.6, 9.2, 63.1],
[' 河 北', 3365.0, 6315.9, 4349.0, 331.0, 234.3, 1424.2, 1523.9],
[' 山 西', 1312.8, 3274.3, 1382.8, 121.0, 107.2, 347.4, 144.2],
[' 内蒙古', 2773.0, 5617.3, 2957.8, 202.4, 623.4, 428.2, 180.5],
[' 辽 宁', 2195.6, 3226.4, 1407.8, 151.8, 208.0, 322.5, 809.9],
[' 吉 林', 3551.0, 4789.9, 1510.1, 216.8, 440.4, 670.8, 197.6],
[' 黑龙江', 6004.1, 11564.4, 5342.1, 245.0, 873.3, 645.3, 131.2],
[' 上 海', 114.2, 168.5, 184.1, 10.8, 6.7, 3.6, 13.5],
[' 江 苏', 3423.0, 5360.8, 3785.3, 326.8, 131.3, 925.4, 415.9],
[' 浙 江', 734.0, 1253.7, 1409.4, 92.4, 11.7, 139.3, 863.3],
[' 安 徽', 3279.6, 6625.3, 4305.5, 338.4, 179.9, 2249.7, 1174.2],
[' 福 建', 664.4, 1202.1, 1122.4, 120.6, 3.1, 104.5, 65.1],
[' 江 西', 2116.1, 3690.9, 1995.6, 141.6, 10.2, 289.8, 221.5],
[' 山 东', 4528.2, 7294.6, 4729.0, 472.7, 500.7, 1997.0, 1259.8],
[' 河 南', 5713.7, 10081.8, 4969.1, 696.4, 357.8, 3513.2, 1100.5],
[' 湖 北', 2501.3, 4258.4, 2791.4, 351.9, 149.4, 1141.2, 698.1],
[' 湖 南', 2925.7, 4936.6, 3084.3, 248.2, 106.6, 227.5, 1067.8],
[' 广 东', 1315.9, 2507.6, 1770.8, 243.9, 23.9, 329.2, 349.7],
[' 广 西', 1521.8, 3076.0, 1586.4, 255.7, 34.2, 456.8, 271.6],
[' 海 南', 190.9, 421.8, 260.9, 47.6, 44.5, 52.7, 38.0],
[' 重 庆', 1148.1, 2253.9, 675.2, 96.6, 3.8, 7.8, 759.5],
[' 四 川', 3387.1, 6469.9, 2616.5, 251.1, 121.8, 119.0, 307.3],
[' 贵 州', 1030.0, 3118.4, 926.9, 97.4, 41.9, 85.8, 225.0],
[' 云 南', 1824.0, 4499.4, 1660.3, 219.0, 287.0, 377.0, 121.6],
[' 西 藏', 96.2, 175.9, 239.3, 5.7, 66.4, 138.3, 0.9],
[' 陕 西', 1215.8, 3105.1, 1209.9, 241.7, 99.3, 198.7, 322.6],
[' 甘 肃', 1138.9, 2858.7, 1284.1, 94.7, 130.4, 575.6, 130.7],
[' 青 海', 102.4, 280.0, 186.9, 9.8, 11.1, 243.9, 2.5],
[' 宁 夏', 373.4, 801.6, 498.6, 40.4, 42.6, 179.8, 27.0],
[' 新 疆', 1377.0, 2234.8, 4769.9, 203.2, 397.2, 316.9, 69.8]]
workbook=Workbook()
worksheet=workbook.active
worksheet.title=u'数据'
i,j=1,1
for row in data:
for col in range(1,len(row)+1):
ncol=j
worksheet.cell(row=j,column=col).value=row[col-1]
i+=1;j+=1
workbook.save('数据-副本.xlsx')结果为:
